第四次数据采集与融合实验
作业①:
-
作业①:
1. 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法; Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
2. 候选网站:http://www.dangdang.com/
3. 关键词:学生自由选择
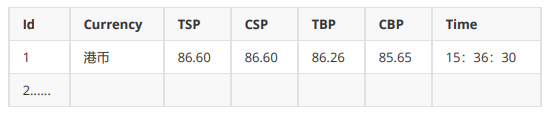
4. 输出信息:MySQL数据库存储和输出格式如下:![]()
(1)利用scrapy爬取当当网网页内容
实验过程:
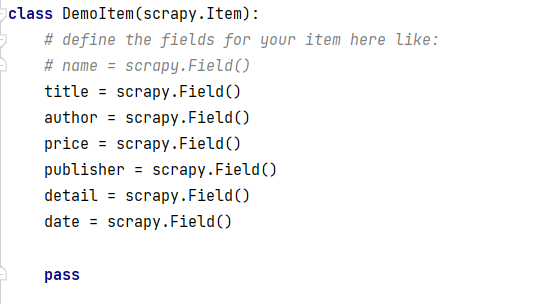
1.根据实验要求需要爬取的项目有书本的title,author,publisher,date,price,detail,据此应用scrapy框架,在item类中创建相应的项目![]()
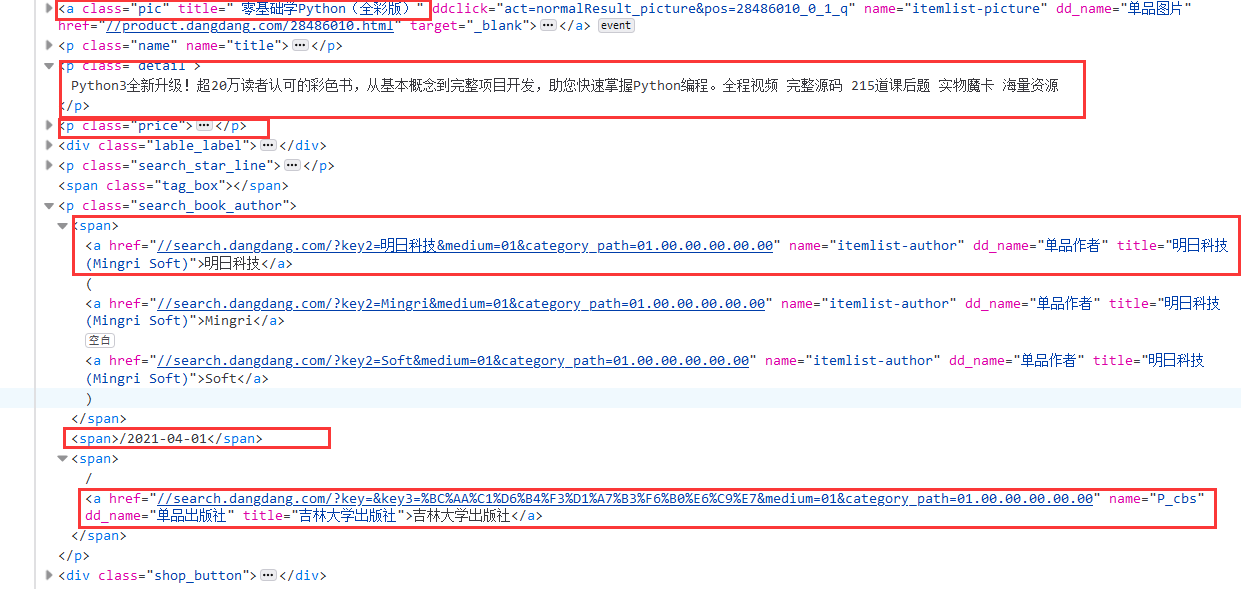
2.编写主爬虫函数myspiders,主要考虑到当前页面的爬取,以及翻页处理,F12观察页面找到主要部分
![]()
利用xpath方法实现定位
![]()
翻页处理:
# 找到下一页的跳转链接 link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first() if link: url = response.urljoin(link) yield scrapy.Request(url=url, callback=self.parse)3.在pipelines设置相关的输出,创建mysql数据库
# 连接mysql数据库 try: self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="chen961122",db="test",charset="utf8") self.cursor=self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from dangdang") self.opened=True except Exception as err: print(err) self.opened=False插入数据到数据表中:
# 插入数据 self.cursor.execute("insert into dangdang (Dtitle,Ddetail,Dprice,Dauthor,Dpublisher,Ddate) values (%s,%s,%s,%s,%s,%s)", (item["title"], item["detail"], item["price"], item["author"], item["publisher"], item["date"]))4.最后设定settings:
ROBOTSTXT_OBEY = False,
ITEM_PIPELINES = {
'demo.pipelines.DemoPipeline': 300,
}
使爬虫可以顺利进行
运行结果![]()
心得体会:
通过本次实验是对之前实验的复现,主要是加深巩固了scrapy框架的使用方法,以及xpath元素定位方法的复习与加强,翻页的处理可以说得心应手,爬虫与数据库的结合也得到了巩固。
作业②:
- 作业②
1. 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
2. 候选网站:招商银行网:http://fx.cmbchina.com/hq/
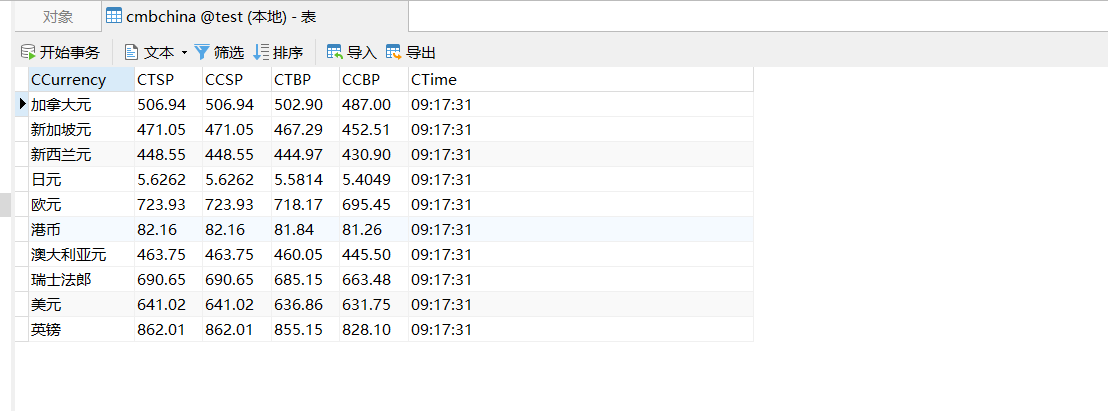
3. 输出信息:MYSQL数据库存储和输出格式![]()
(2)利用scrapy爬取招商银行网相关信息
实验过程:
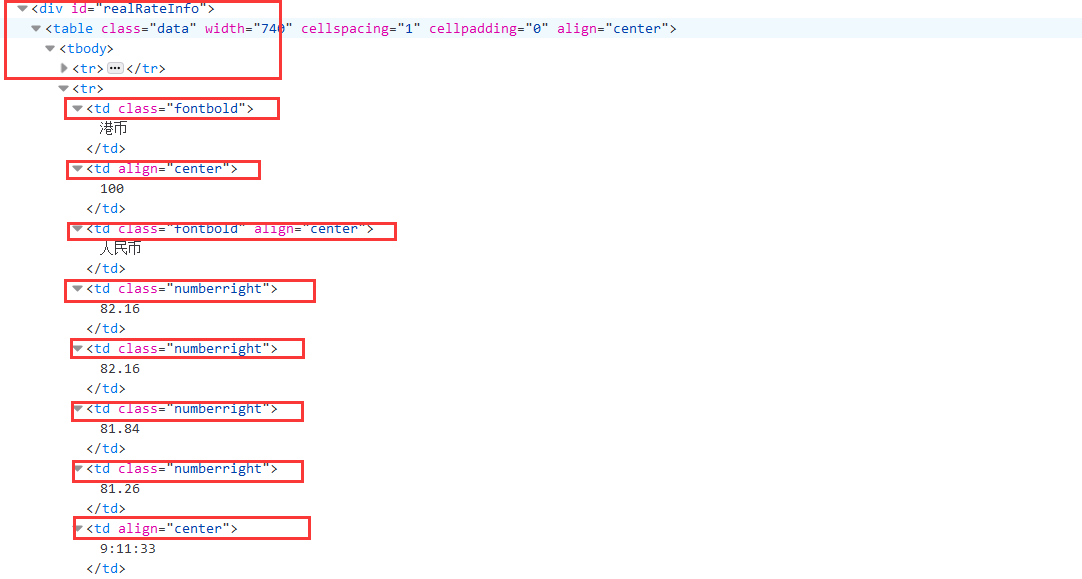
1.根据实验要求需要爬取的项目有外汇实时汇率的Currency,TSP,CSP,TBP,CBP,Time,据此应用scrapy框架,在item类中创建相应的项目# 定义类 Currency = scrapy.Field() TSP = scrapy.Field() CSP = scrapy.Field() TBP = scrapy.Field() CBP = scrapy.Field() Time = scrapy.Field()2.编写主爬虫函数myspiders,主要考虑到当前页面的爬取,F12观察页面找到主要部分
![]()
利用xpath方法实现定位
![]()
3.在pipelines设置相关的输出,创建mysql数据库
# 连接mysql try: self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="chen961122",db="test",charset="utf8") self.cursor=self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from cmbchina") self.opened=True except Exception as err: print(err) self.opened=False插入数据到数据表中:
# 插入数据 self.cursor.execute( "insert into cmbchina (CCurrency,CTSP,CCSP,CTBP,CCBP,CTime) values (%s,%s,%s,%s,%s,%s)", (item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))4.最后设定settings:
ROBOTSTXT_OBEY = False,
ITEM_PIPELINES = {
'demo.pipelines.DemoPipeline': 300,
}
使爬虫可以顺利进行
运行结果![]()
心得体会
该页面的结构为table类型,第一次在利用xpath定位元素的时候由于嵌入了tbody标签,导致定位失败,后续baidu得知xpath定位需要忽略tbody,但是第三题的selenium的定位方法可以带tbody,其余地方也是用scrapy框架,与第一题类似
作业③:
- 作业③:
1.要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容; 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
2.候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3.输出信息:
MySQL数据库存储和输出格式如下,
表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2...... (3)利用selenium爬取股票相关信息
实验过程:
1.创建class myspiders类
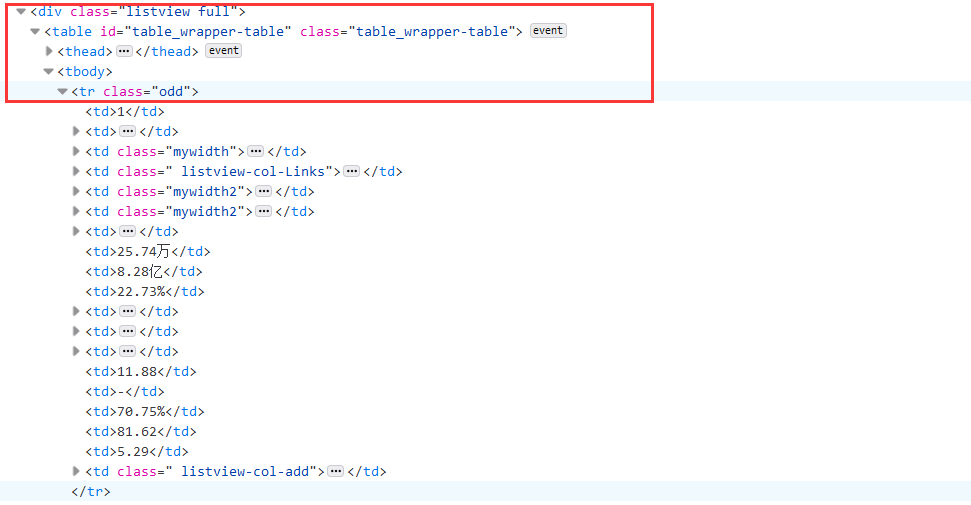
首先开启mysql数据库:# 连接mysql数据库 print("opened") try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="chen961122", db="test", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.opened = True # flag = False except Exception as err: print(err) self.opened = False2.F12观察网页结构:
![]()
3.利用selenium的查找方法find_elements_by_xpath进行数据元素定位:
# 使用find_elements_by_xpath方法进行查找 lis =driver.find_elements_by_xpath("//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr") # print(lis) for li in lis: if count >112: break; id = li.find_element_by_xpath(".//td[position()=1]").text # 序号 code = li.find_element_by_xpath(".//td[position()=2]/a").text # 代码 name = li.find_element_by_xpath(".//td[position()=3]/a").text # 名称 zxj = li.find_element_by_xpath(".//td[position()=5]/span").text # 最新价 zdf = li.find_element_by_xpath(".//td[position()=6]/span").text # 涨跌幅 zde = li.find_element_by_xpath(".//td[position()=7]/span").text # 涨跌额 cjl = li.find_element_by_xpath(".//td[position()=8]").text # 成交量 cje = li.find_element_by_xpath(".//td[position()=9]").text # 成交额 zf = li.find_element_by_xpath(".//td[position()=10]").text # 振幅 zg = li.find_element_by_xpath(".//td[position()=11]/span").text # 最高 zd = li.find_element_by_xpath(".//td[position()=12]/span").text # 最低 jk = li.find_element_by_xpath(".//td[position()=13]/span").text # 今开 zs = li.find_element_by_xpath(".//td[position()=14]").text # 昨收 time.sleep(1)4.先打印至控制台检查输出:
print(id, code, name, zxj, zdf, zde, cjl, cje, zf,zg, zd, jk, zs)5.检擦无误后插入mysql数据库,插入完毕后关闭数据库:
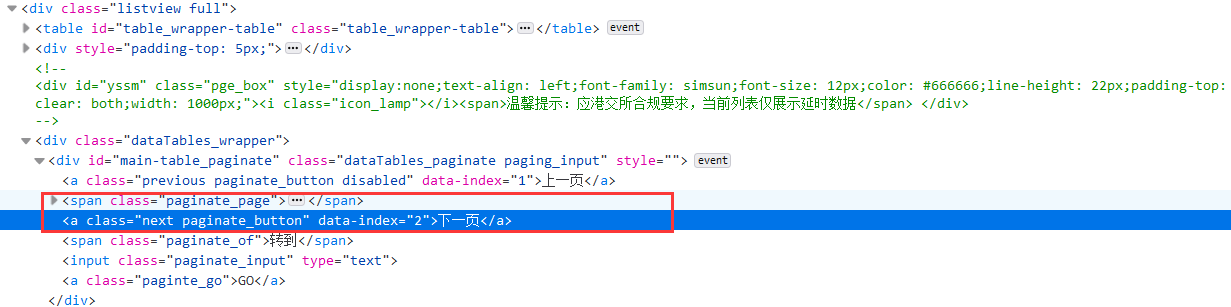
self.cursor.execute( "insert into gupiao3 (Gindex,GSymbollist, Gnamelist, GLastTradelist, GChglist, GChangelist, GVolume, GTurnover, Gslist, Ghelist, Glelist, GOpenlist, GPrevCloselist) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (id, code, name, zxj, zdf, zde, cjl, cje, zf, zg, zd, jk, zs)) if self.opened: self.con.commit() self.con.close() self.opened = False print("closed")6.利用selenium进行翻页处理(这里考虑到总共要爬取的信息条数,设定每个板块的股票爬取一页),找到页面底部的下一页标签:
![]()
利用selenium的查找方法find_elements_by_xpath进行定位,利用click()方法模拟用户点击,这里需要注意设置time.sleep进行睡眠,让新页面完成加载
if i == 1: i+=1 try: # 找到标签位置 nextPage = driver.find_element_by_xpath("//div[@class='listview full']/div[@class='dataTables_wrapper']/div[@class='dataTables_paginate paging_input']/a[@class='next paginate_button']") # 模拟用户点击 nextPage.click() time.sleep(5) self.processSpider() except: print()7.完成一个股票板块的爬取后,进行板块的切换,开一个数组 board ,创建myspiders对象,进行循环:
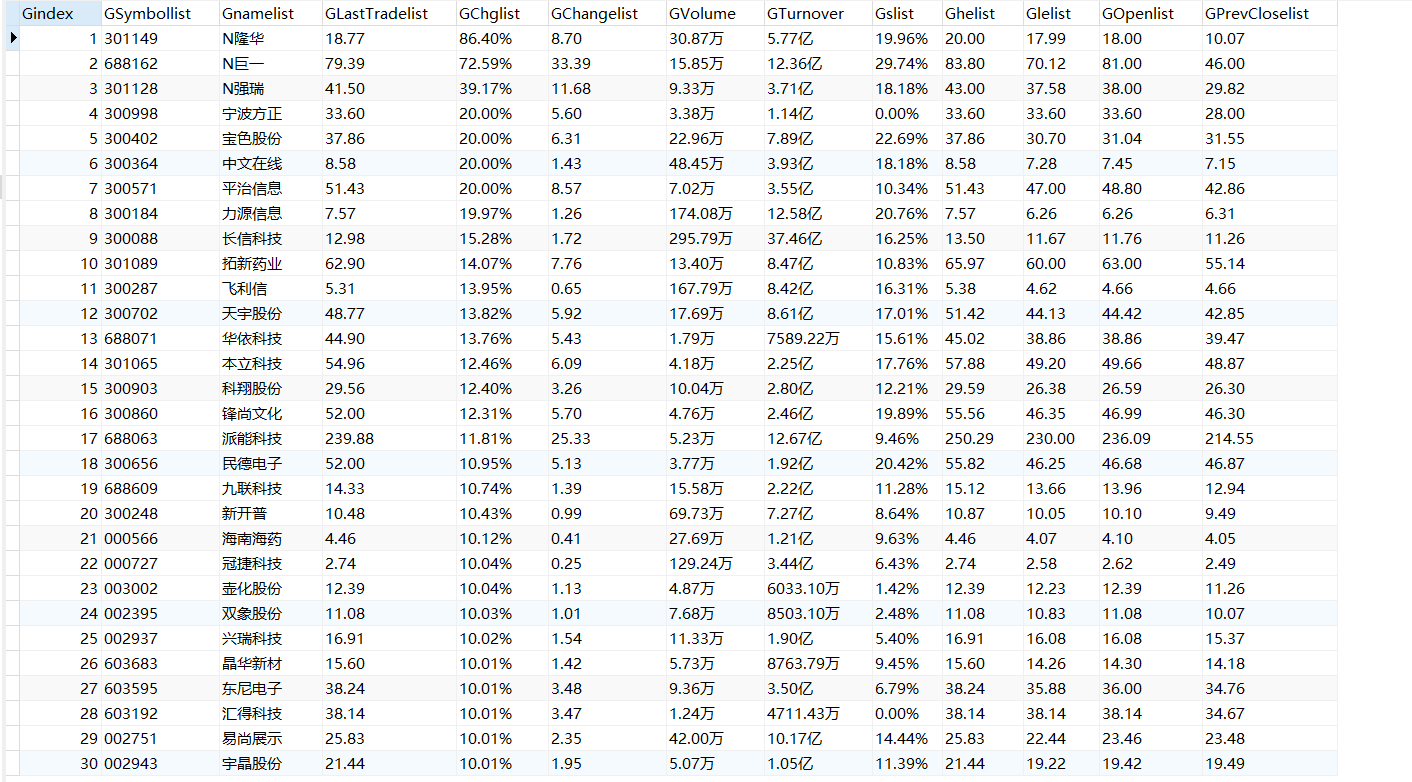
board = ['hs_a_board','sh_a_board','sz_a_board'] count = 1 # 创建对象 myspider = myspiders() for boards in board: i = 1 url = "http://quote.eastmoney.com/center/gridlist.html#"+boards driver.get(url) time.sleep(2) html = driver.page_source soup = BeautifulSoup(html, "html.parser") # 调用爬虫函数 myspider.processSpider()注意这里每次driver.get后也要设置time.sleep防止页面加载不及时。
运行结果![]()
心得体会
第一次完成selenium的实验,感觉selenium的功能特别强大,这次试验还只是运用了他的查找元素方法和翻页处理时的点击操作,实验整体较为简单,只是需要注意用selenium进行爬取的过程中,在执行用户操作或者访问url,必须注意设置等待时间,否则会出现找不到页面的问题,后续我还使用selenium对验证码问题,滑动验证码问题,以及反监听问题都进行了处理,感觉收获很大。
我的Gitee - 作业③:
我的Gitee - 作业②
我的Gitee





 浙公网安备 33010602011771号
浙公网安备 33010602011771号