第一次个人编程作业
一、PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 60 | 40 |
| 估计这个任务需要多少时间 | 300 | 200 |
| 开发 | 600 | 720 |
| 需求分析 (包括学习新技术) | 30 | 60 |
| 生成设计文档 | 10 | 10 |
| 设计复审 | 60 | 40 |
| 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| 具体设计 | 120 | 60 |
| 具体编码 | 600 | 1200 |
| 代码复审 | 60 | 30 |
| 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| 报告 | 30 | 40 |
| 测试报告 | 30 | 30 |
| 计算工作量 | 10 | 20 |
| 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 2020 | 2540 |
二、计算模块的接口
(2.1)计算模块接口的设计与实现过程。
- 1.思想起源:刚刚拿到这个题思考了一下,发现没有什么清晰的思路,百度一下后发现网上大多数都是使用DFA算法和AC自动机进行敏感词检测,初看代码觉得太复杂就放弃了,之后上数据分析的时候吴伶老师提到了正则表达式,让我对此产生了思考。
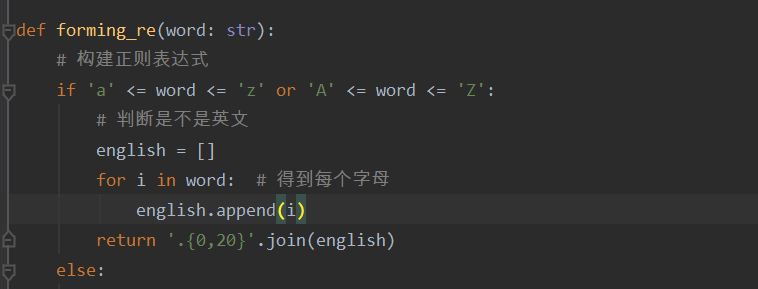
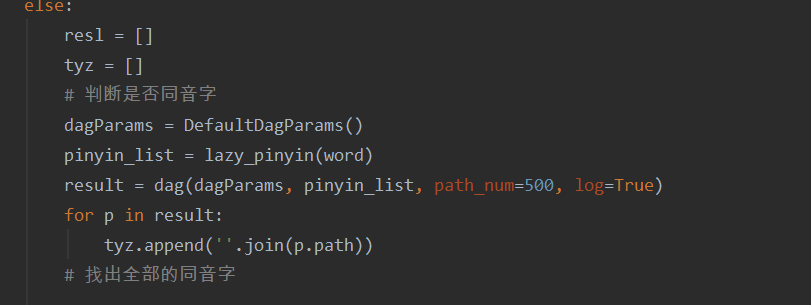
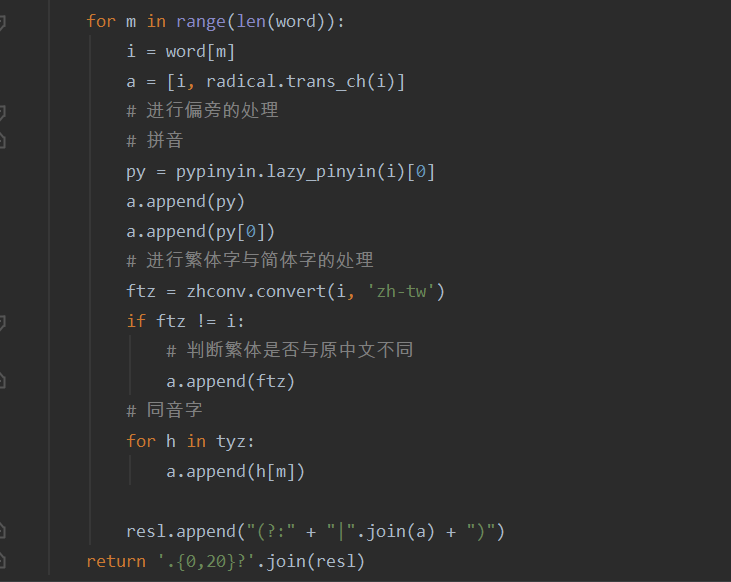
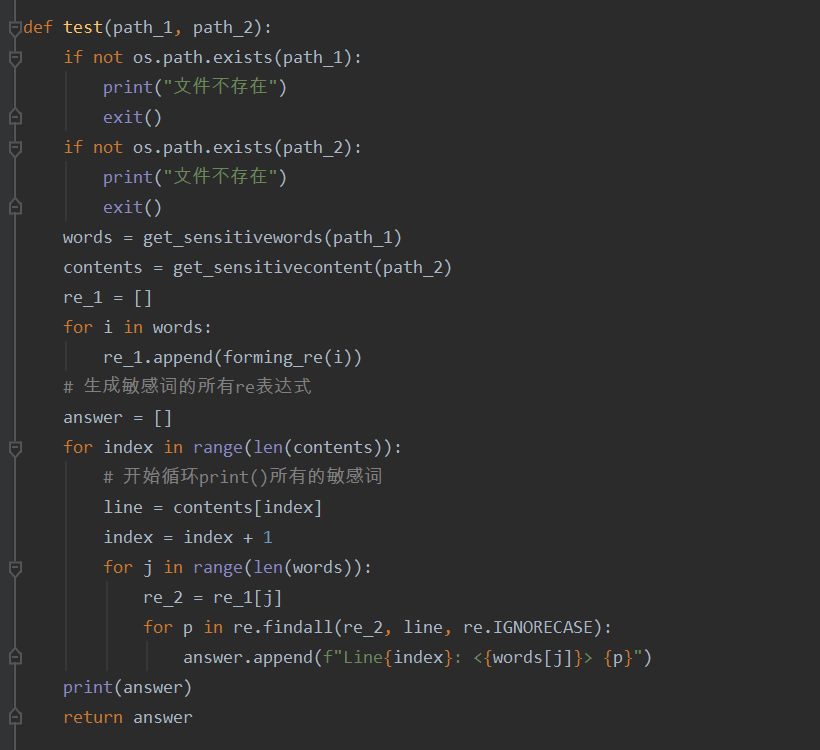
- 2.实现过程:处不勾选构建几个函数分别是get_sensitiveword(获取敏感词库的函数),get_sensitivecontent(获取待检测文本的函数)以上函数均将文本内容转化为字符串,储存在列表之中。接着就开始构造本次作业的核心部分g构建符合要求的正则表达式,考虑到这次作业要实现的功能,主要包括(特殊字符的插入,拼音,同音字,偏旁的拆分所以正则的构建如下forming_re)紧接着的主函数先对文件是否存在的问题进行判断,然后在调用前面的函数,对待检测文本进行敏感词的循环匹配(感觉这部分算法很low,可能导致代码的性能不高)
![]()
![]()
![]()
最后就是关于敏感词的循环检测,代码见github
(2.2)计算模块接口部分的性能改进。
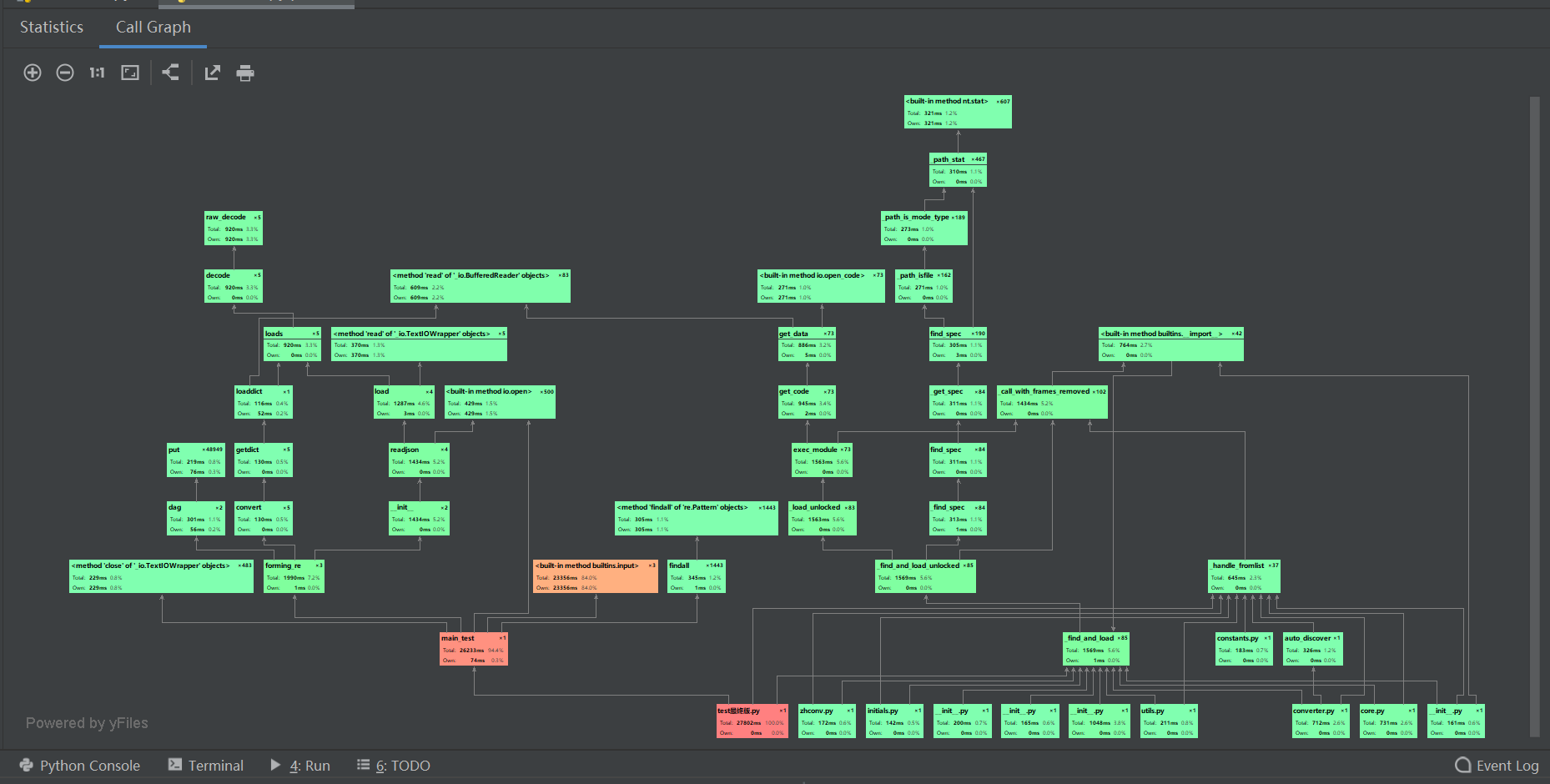
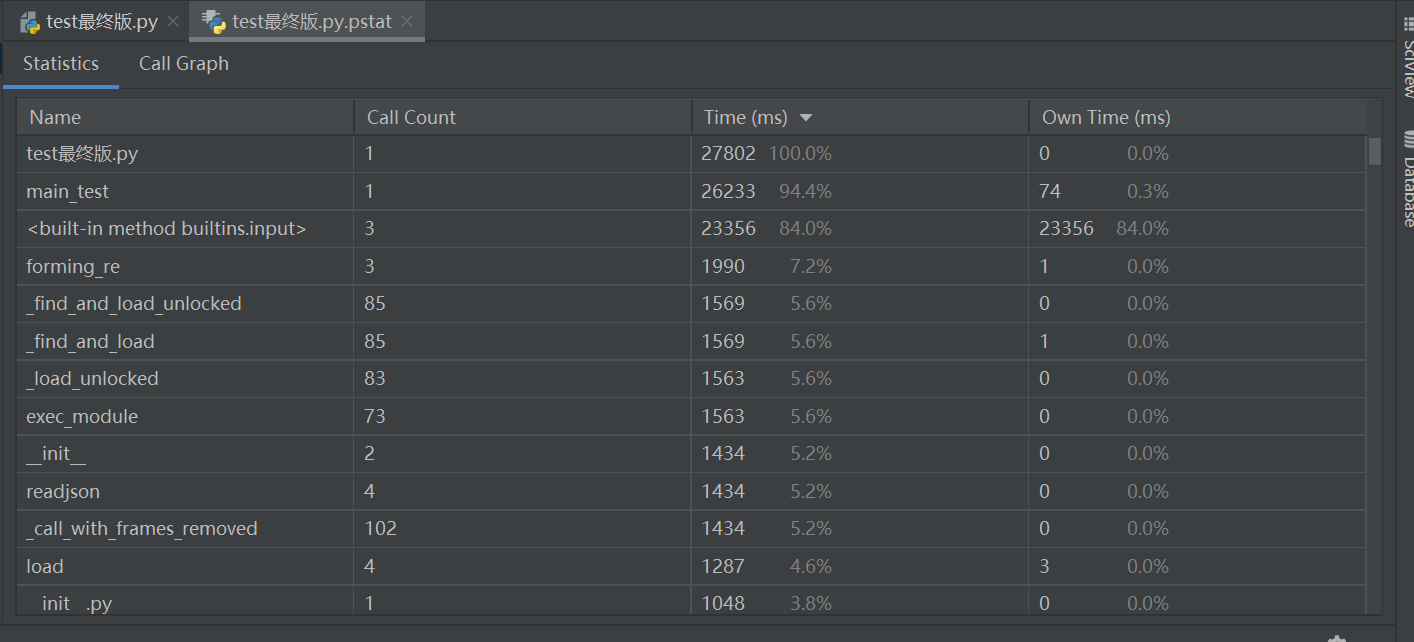
- 性能分析截图如下
![]()
![]()
可以发现主要的功能实现在主函数里的循环检测部分,本代码使用了较多的内置方法,可见built -in method占比较大
改进思路:我想出了单纯用循环一个个检测花时较大,如果用递归的思想,可能可以节省大部分的时间。
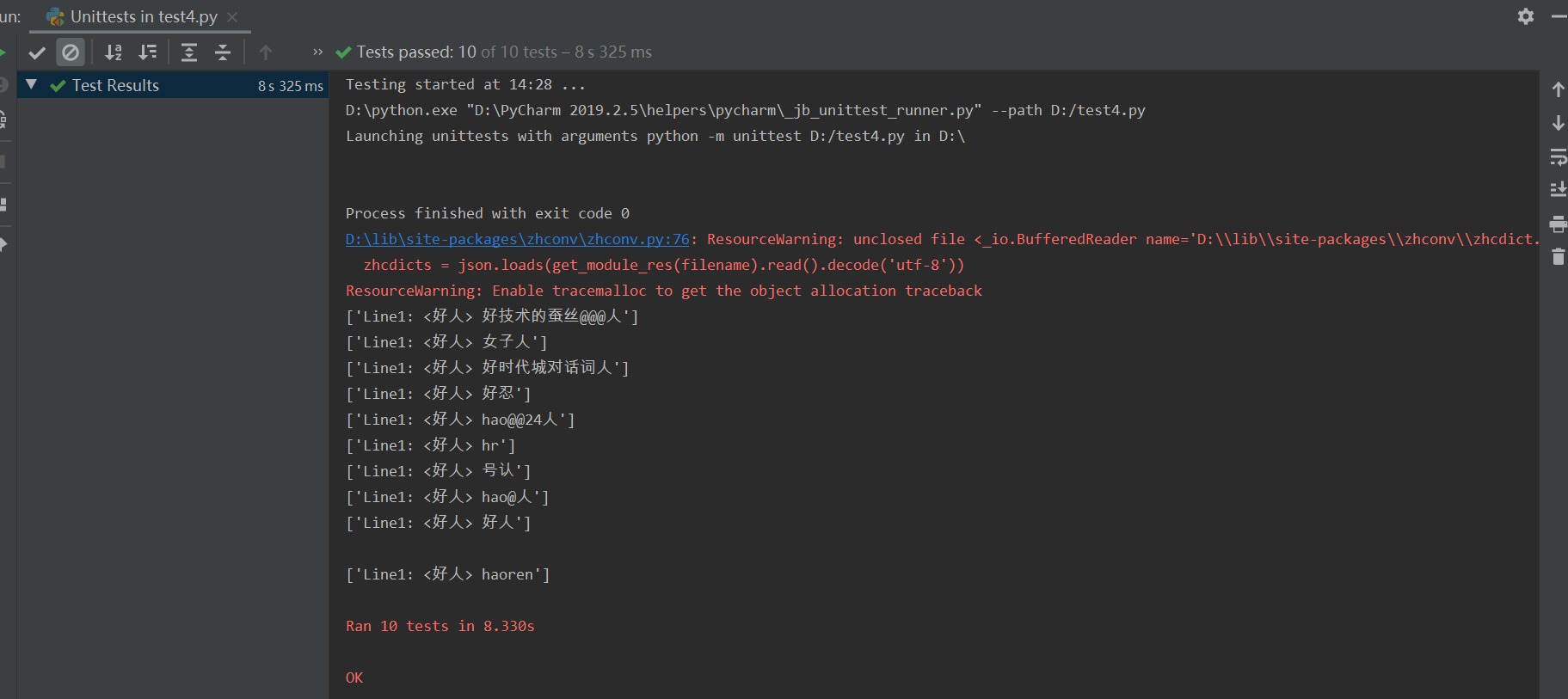
(2.3)计算模块部分单元测试展示。
- 在main.py中写入新函数def_test
![]()
然后运用构造一个类,引入self对象运用assertEquals函数对代码执行结果与预计结果进行对比,下列测试了10个点,依次通过,函数主要是
import unittest
from main import test
class MyTestCase(unittest.TestCase):
def test1(self):
self.assertEqual(test("./words1.txt", "./org1.txt")[0], "Line1: <好人> 好技术的蚕丝@@@人")
![]()
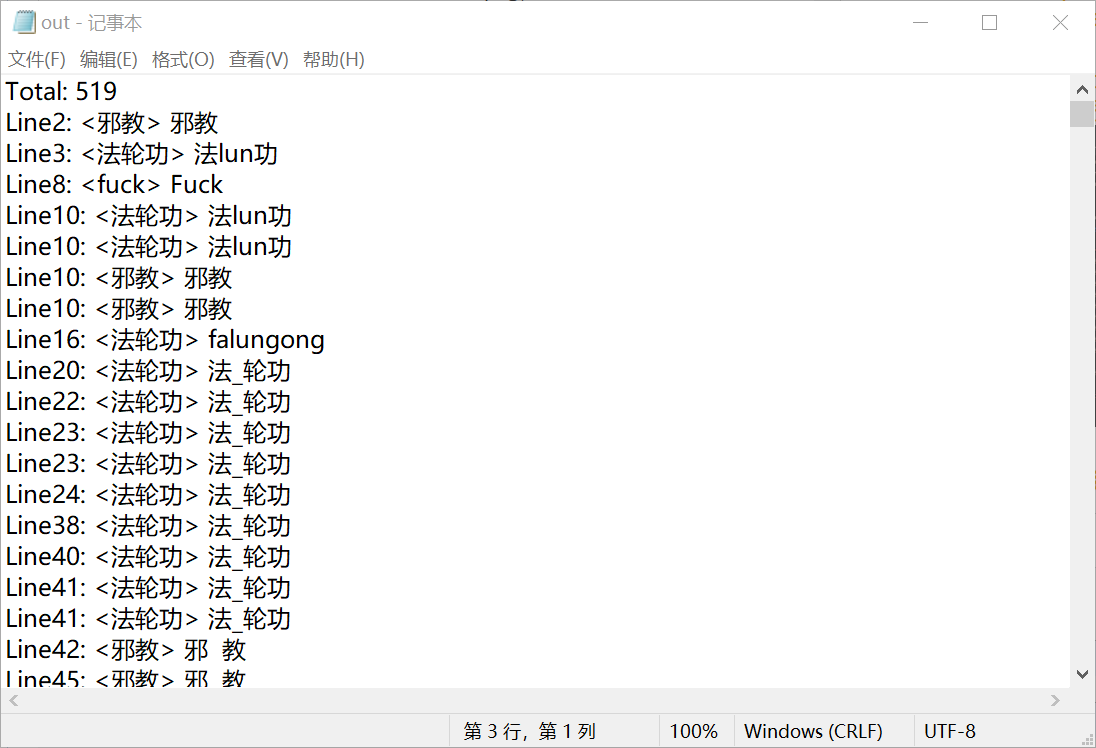
测试组给的数据测试截图
![]()
(2.4)计算模块部分异常处理说明。
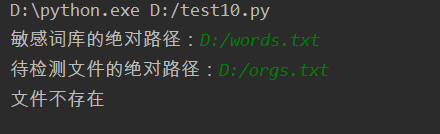
做到这里的时候心态已经快崩了,只做了文件不存在时的异常处理
当文件不存在时,跑出文件不存在的提醒,使用os库进行处理
三、心得
(3.1)在完成本次作业过程的心得体会。
超级无敌有成就感,虽然感觉分数不高,刚开始看到题目的时候就觉得对我来说这题基本做不出来,深深地爱上了柯逍老师,真的好爱,说实话只想着做个最基本的然后摆烂。
消耗了很多时间和精力,但是也学到了很多,Github的使用越发娴熟,第三方库的使用也更加得心应手,程序不知道写的怎么样,不过也是尽力了,学到了很多算法比如DFA AC虽然我不是这么做的,但是也稍微学了下,深刻的意识到了正则表达式的强大,真的好爱。对python代码的运用也更加熟练,也体会到了很多之前感受不到的难度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号