

Redis实现延迟队列方法介绍
延迟队列,顾名思义它是一种带有延迟功能的消息队列。那么,是在什么场景下我才需要这样的队列呢?
1. 背景
我们先看看以下业务场景:
- 当订单一直处于未支付状态时,如何及时的关闭订单
- 如何定期检查处于退款状态的订单是否已经退款成功
- 在订单长时间没有收到下游系统的状态通知的时候,如何实现阶梯式的同步订单状态的策略
- 在系统通知上游系统支付成功终态时,上游系统返回通知失败,如何进行异步通知实行分频率发送:15s 3m 10m 30m 30m 1h 2h 6h 15h
1.1 解决方案
- 最简单的方式,定时扫表。例如对于订单支付失效要求比较高的,每2S扫表一次检查过期的订单进行主动关单操作。优点是简单,缺点是每分钟全局扫表,浪费资源,如果遇到表数据订单量即将过期的订单量很大,会造成关单延迟。
- 使用RabbitMq或者其他MQ改造实现延迟队列,优点是,开源,现成的稳定的实现方案,缺点是:MQ是一个消息中间件,如果团队技术栈本来就有MQ,那还好,如果不是,那为了延迟队列而去部署一套MQ成本有点大
- 使用Redis的zset、list的特性,我们可以利用redis来实现一个延迟队列RedisDelayQueue
2. 设计目标
- 实时性:允许存在一定时间的秒级误差
- 高可用性:支持单机、支持集群
- 支持消息删除:业务会随时删除指定消息
- 消息可靠性:保证至少被消费一次
- 消息持久化:基于Redis自身的持久化特性,如果Redis数据丢失,意味着延迟消息的丢失,不过可以做主备和集群保证。这个可以考虑后续优化将消息持久化到MangoDB中
3. 设计方案
设计主要包含以下几点:
- 将整个Redis当做消息池,以KV形式存储消息
- 使用ZSET做优先队列,按照Score维持优先级
- 使用LIST结构,以先进先出的方式消费
- ZSET和LIST存储消息地址(对应消息池的每个KEY)
- 自定义路由对象,存储ZSET和LIST名称,以点对点的方式将消息从ZSET路由到正确的LIST
- 使用定时器维护路由
- 根据TTL规则实现消息延迟
3.1 设计图
还是基于有赞的延迟队列设计,进行优化改造及代码实现。有赞设计
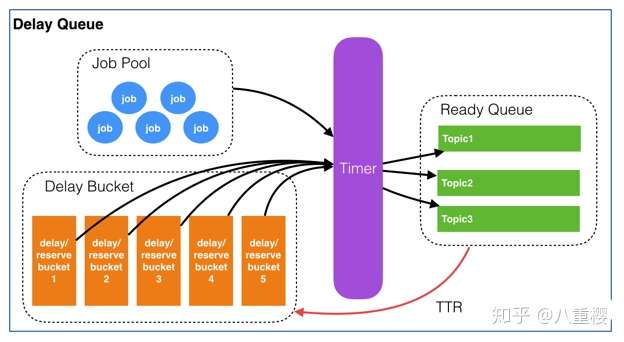
3.2 数据结构
ZING:DELAY_QUEUE:JOB_POOL是一个Hash_Table结构,里面存储了所有延迟队列的信息。KV结构:K=prefix+projectName field = topic+jobId V=CONENT;V由客户端传入的数据,消费的时候回传ZING:DELAY_QUEUE:BUCKET延迟队列的有序集合ZSET,存放K=ID和需要的执行时间戳,根据时间戳排序ZING:DELAY_QUEUE:QUEUELIST结构,每个Topic一个LIST,list存放的都是当前需要被消费的JOB

图片仅供参考,基本可以描述整个流程的执行过程
3.3 任务的生命周期
- 新增一个JOB,会在
ZING:DELAY_QUEUE:JOB_POOL中插入一条数据,记录了业务方消费方。ZING:DELAY_QUEUE:BUCKET也会插入一条记录,记录执行的时间戳 - 搬运线程会去
ZING:DELAY_QUEUE:BUCKET中查找哪些执行时间戳的RunTimeMillis比现在的时间小,将这些记录全部删除;同时会解析出每个任务的Topic是什么,然后将这些任务PUSH到TOPIC对应的列表ZING:DELAY_QUEUE:QUEUE中 - 每个TOPIC的LIST都会有一个监听线程去批量获取LIST中的待消费数据,获取到的数据全部扔给这个TOPIC的消费线程池
- 消费线程池执行会去
ZING:DELAY_QUEUE:JOB_POOL查找数据结构,返回给回调结构,执行回调方法。
3.4 设计要点
3.4.1 基本概念
- JOB:需要异步处理的任务,是延迟队列里的基本单元
- Topic:一组相同类型Job的集合(队列)。供消费者来订阅
3.4.2 消息结构
每个JOB必须包含以下几个属性
- jobId:Job的唯一标识。用来检索和删除指定的Job信息
- topic:Job类型。可以理解成具体的业务名称
- delay:Job需要延迟的时间。单位:秒。(服务端会将其转换为绝对时间)
- body:Job的内容,供消费者做具体的业务处理,以json格式存储
- retry:失败重试次数
- url:通知URL
3.5 设计细节
3.5.1 如何快速消费ZING:DELAY_QUEUE:QUEUE
最简单的实现方式就是使用定时器进行秒级扫描,为了保证消息执行的时效性,可以设置每1S请求Redis一次,判断队列中是否有待消费的JOB。但是这样会存在一个问题,如果queue中一直没有可消费的JOB,那频繁的扫描就失去了意义,也浪费了资源,幸好LIST中有一个BLPOP阻塞原语,如果list中有数据就会立马返回,如果没有数据就会一直阻塞在那里,直到有数据返回,可以设置阻塞的超时时间,超时会返回NULL;具体的实现方式及策略会在代码中进行具体的实现介绍
3.5.2 避免定时导致的消息重复搬运及消费
- 使用Redis的分布式锁来控制消息的搬运,从而避免消息被重复搬运导致的问题
- 使用分布式锁来保证定时器的执行频率
4. 核心代码实现
4.1 技术说明
技术栈:SpringBoot,Redisson,Redis,分布式锁,定时器
注意:本项目没有实现设计方案中的多Queue消费,只开启了一个QUEUE,这个待以后优化
4.2 核心实体
4.2.1 Job新增对象
/**
* 消息结构
*
* @author 睁眼看世界
* @date 2020年1月15日
*/
@Data
public class Job implements Serializable {
private static final long serialVersionUID = 1L;
/**
* Job的唯一标识。用来检索和删除指定的Job信息
*/
@NotBlank
private String jobId;
/**
* Job类型。可以理解成具体的业务名称
*/
@NotBlank
private String topic;
/**
* Job需要延迟的时间。单位:秒。(服务端会将其转换为绝对时间)
*/
private Long delay;
/**
* Job的内容,供消费者做具体的业务处理,以json格式存储
*/
@NotBlank
private String body;
/**
* 失败重试次数
*/
private int retry = 0;
/**
* 通知URL
*/
@NotBlank
private String url;
}
4.2.2 Job删除对象
/**
* 消息结构
*
* @author 睁眼看世界
* @date 2020年1月15日
*/
@Data
public class JobDie implements Serializable {
private static final long serialVersionUID = 1L;
/**
* Job的唯一标识。用来检索和删除指定的Job信息
*/
@NotBlank
private String jobId;
/**
* Job类型。可以理解成具体的业务名称
*/
@NotBlank
private String topic;
}4.3 搬运线程
/**
* 搬运线程
*
* @author 睁眼看世界
* @date 2020年1月17日
*/
@Slf4j
@Component
public class CarryJobScheduled {
@Autowired
private RedissonClient redissonClient;
/**
* 启动定时开启搬运JOB信息
*/
@Scheduled(cron = "*/1 * * * * *")
public void carryJobToQueue() {
System.out.println("carryJobToQueue --->");
RLock lock = redissonClient.getLock(RedisQueueKey.CARRY_THREAD_LOCK);
try {
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL);
}
RScoredSortedSet<Object> bucketSet = redissonClient.getScoredSortedSet(RD_ZSET_BUCKET_PRE);
long now = System.currentTimeMillis();
Collection<Object> jobCollection = bucketSet.valueRange(0, false, now, true);
List<String> jobList = jobCollection.stream().map(String::valueOf).collect(Collectors.toList());
RList<String> readyQueue = redissonClient.getList(RD_LIST_TOPIC_PRE);
readyQueue.addAll(jobList);
bucketSet.removeAllAsync(jobList);
} catch (InterruptedException e) {
log.error("carryJobToQueue error", e);
} finally {
if (lock != null) {
lock.unlock();
}
}
}
}4.4 消费线程
@Slf4j
@Component
public class ReadyQueueContext {
@Autowired
private RedissonClient redissonClient;
@Autowired
private ConsumerService consumerService;
/**
* TOPIC消费线程
*/
@PostConstruct
public void startTopicConsumer() {
TaskManager.doTask(this::runTopicThreads, "开启TOPIC消费线程");
}
/**
* 开启TOPIC消费线程
* 将所有可能出现的异常全部catch住,确保While(true)能够不中断
*/
@SuppressWarnings("InfiniteLoopStatement")
private void runTopicThreads() {
while (true) {
RLock lock = null;
try {
lock = redissonClient.getLock(CONSUMER_TOPIC_LOCK);
} catch (Exception e) {
log.error("runTopicThreads getLock error", e);
}
try {
if (lock == null) {
continue;
}
// 分布式锁时间比Blpop阻塞时间多1S,避免出现释放锁的时候,锁已经超时释放,unlock报错
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
continue;
}
// 1. 获取ReadyQueue中待消费的数据
RBlockingQueue<String> queue = redissonClient.getBlockingQueue(RD_LIST_TOPIC_PRE);
String topicId = queue.poll(60, TimeUnit.SECONDS);
if (StringUtils.isEmpty(topicId)) {
continue;
}
// 2. 获取job元信息内容
RMap<String, Job> jobPoolMap = redissonClient.getMap(JOB_POOL_KEY);
Job job = jobPoolMap.get(topicId);
// 3. 消费
FutureTask<Boolean> taskResult = TaskManager.doFutureTask(() -> consumerService.consumerMessage(job.getUrl(), job.getBody()), job.getTopic() + "-->消费JobId-->" + job.getJobId());
if (taskResult.get()) {
// 3.1 消费成功,删除JobPool和DelayBucket的job信息
jobPoolMap.remove(topicId);
} else {
int retrySum = job.getRetry() + 1;
// 3.2 消费失败,则根据策略重新加入Bucket
// 如果重试次数大于5,则将jobPool中的数据删除,持久化到DB
if (retrySum > RetryStrategyEnum.RETRY_FIVE.getRetry()) {
jobPoolMap.remove(topicId);
continue;
}
job.setRetry(retrySum);
long nextTime = job.getDelay() + RetryStrategyEnum.getDelayTime(job.getRetry()) * 1000;
log.info("next retryTime is [{}]", DateUtil.long2Str(nextTime));
RScoredSortedSet<Object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.add(nextTime, topicId);
// 3.3 更新元信息失败次数
jobPoolMap.put(topicId, job);
}
} catch (Exception e) {
log.error("runTopicThreads error", e);
} finally {
if (lock != null) {
try {
lock.unlock();
} catch (Exception e) {
log.error("runTopicThreads unlock error", e);
}
}
}
}
}
}4.5 添加及删除JOB
/**
* 提供给外部服务的操作接口
*
* @author why
* @date 2020年1月15日
*/
@Slf4j
@Service
public class RedisDelayQueueServiceImpl implements RedisDelayQueueService {
@Autowired
private RedissonClient redissonClient;
/**
* 添加job元信息
*
* @param job 元信息
*/
@Override
public void addJob(Job job) {
RLock lock = redissonClient.getLock(ADD_JOB_LOCK + job.getJobId());
try {
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL);
}
String topicId = RedisQueueKey.getTopicId(job.getTopic(), job.getJobId());
// 1. 将job添加到 JobPool中
RMap<String, Job> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY);
if (jobPool.get(topicId) != null) {
throw new BusinessException(ErrorMessageEnum.JOB_ALREADY_EXIST);
}
jobPool.put(topicId, job);
// 2. 将job添加到 DelayBucket中
RScoredSortedSet<Object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.add(job.getDelay(), topicId);
} catch (InterruptedException e) {
log.error("addJob error", e);
} finally {
if (lock != null) {
lock.unlock();
}
}
}
/**
* 删除job信息
*
* @param job 元信息
*/
@Override
public void deleteJob(JobDie jobDie) {
RLock lock = redissonClient.getLock(DELETE_JOB_LOCK + jobDie.getJobId());
try {
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL);
}
String topicId = RedisQueueKey.getTopicId(jobDie.getTopic(), jobDie.getJobId());
RMap<String, Job> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY);
jobPool.remove(topicId);
RScoredSortedSet<Object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.remove(topicId);
} catch (InterruptedException e) {
log.error("addJob error", e);
} finally {
if (lock != null) {
lock.unlock();
}
}
}
}5. 待优化的内容
- 目前只有一个Queue队列存放消息,当需要消费的消息大量堆积后,会影响消息通知的时效。改进的办法是,开启多个Queue,进行消息路由,再开启多个消费线程进行消费,提供吞吐量
- 消息没有进行持久化,存在风险,后续会将消息持久化到MangoDB中
6. 源码
更多详细源码请在下面地址中获取
RedisDelayQueue实现zing-delay-queue(https://gitee.com/whyCodeData/zing-project/tree/master/zing-delay-queue)RedissonStarterredisson-spring-boot-starter(https://gitee.com/whyCodeData/zing-project/tree/master/zing-starter/redisson-spring-boot-starter)项目应用zing-pay(https://gitee.com/whyCodeData/zing-pay)
7. 参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号