

python中基本的数据类型
在Python中,共有如下六种基本数据类型:
|
|||||
下面依次进行简单介绍:
数字
Python中包含的数字类型有如下几种:
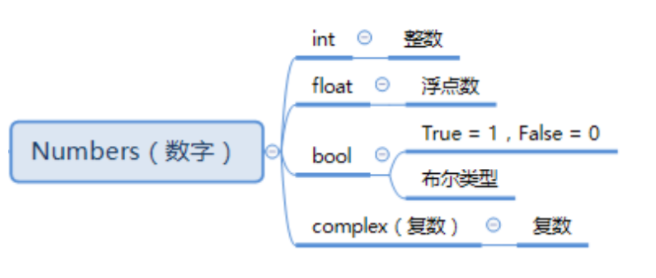
比如,我们可以输入下面几行代码:
a = 5b = 5.5c = 5 - 5jd = 1 == 2 print(type(a),type(b),type(c)) #a、b、c分别为整数、浮点数、复数print(d,type(b)) #d用来判断1与2是否相等,结果为假,则返回Falseprint(float(a),complex(a),int(b)) #函数int()、float()、comlex()可用于转化数据类型
结果如下:

一、整型数据
在Python 3.x 中,整型数据的值在计算机内的表 示不是固定长度的,只要内存许可,整数可以扩展到任意长度,整数的取值范围几乎包括了全部整数(无限大),这给大数据的计算带来便利。
Python 的整型常量有以下4 种表示形式。
(1)十进制整数
如120、0、−374 等。
(2)二进制整数
它以0b 或0B(数字0 加字母b 或B)开头,后接数字 0,1 的整数。
例:
>>> 0b1111
15
0b1111 表示一个二进制整数,其值等于十进制数15。
(3)八进制整数
它是以0o 或0O(数字0 加小写字母o 或大写字母 O)开头,后接数字0~7的整数。
例:
>>> 0o127
87
0o127 表示一个八进制整数,其值等于十进制数 87。
(4)十六进制整数
它是以0x 或0X 开头,后接0~9 和A~F(或用小 写字母)字符的整数。
例:
>>> 0xabc
2748
0xabc 表示一个十六进制整数,其值等于十进制数2748。
二、浮点型数据
浮点型数据表示一个实数,有以下两种表示形式。
(1)十进制小数形式
它由数字和小数点组成,如3.23、34.0、0.0 等。
浮点型数据允许小数点后面没有任何数字,表示小数部分为0,如34.表示34.0。
(2)指数形式
指数形式即用科学计数法表示的浮点数,用字母e(或E)表示以10 为底的指数,e 之前为数字部分,之后为指数部分,且两部分必须同时出现,指数必须为整数。
例:
>>> 45e-5
0.00045
>>> 45e-6
4.5e-05
>>> 9.34e2
934.0
45e-5、45e-6、9.34e2 是合法的浮点型常量,分别代表 45×10−5 、45×10−6 、9.34×102。
字母e(或E)前必有数, e(或E)后必为整数。
例:e4、3.4e4.5、34e 等是非法的浮点型常量。
对于浮点数,Python 3.x 默认提供17 位有效数字的精度,相当于C 语言中的双精度浮点数。
例:
>>> 1234567890123456.0
1234567890123456.0
>>> 1234567890123456789.0
1.2345678901234568e+18
>>> 1234567890123456789.0+1
1.2345678901234568e+18
>>> 1234567890123456789.0+1-1234567890123456789.0
0.0
>>> 1234567890123456789.0-1234567890123456789.0+1
1.0
在Python 中,为什么1234567890123456789.0+1- 1234567890123456789.0 的结果为0.0,而 1234567890123456789.0-1234567890123456789.0+1 的 结果为1.0,这就需要了解Python 浮点数的表示方法。
数学上1234567890123456789.0+1 等于 1234567890123456790.0,但由于浮点数受17 位有效 数字的限制,Python 中1234567890123456789.0+1 的结果等于1.2345678901234568e+18,其中加1的结果 被忽略了, 1234567890123456789.0+1 再减去 1234567890123456789.0 的结果为0 。
1234567890123456789.0- 1234567890123456789.0+1 先执行的是减法运算,得到0,然后再加上1,结果为1.0,所以计算机中的计算与数学上的计算是不同的,其原因是计算 机中的计算必须依赖于计算机的计算能力。
在进行问题求解时必须注意这种差别,这就是计算思维的思想。
例:
>>> 1.001*10
10.009999999999998
为什么Python 中1.001*10 结果是 10.009999999999998,而不是10.01,其原因在于十进制小数转换为二进制小数时可能出现无限小数问题,而Python 在存储小数时使用的是双精度 浮点数,这种数只可以保存一定位数的有效数字, 所以当遇到无限小数时就会出现损失精度的问题。
三、复数型数据
在科学计算问题中常会遇到复数运算问题。
例:数学中求方程的复根、电工学中交流电路的 计算、自动控制系统中传递函数的计算等都要用 到复数运算。
Python 提供了复数类型,这使得有关复数运算问 题变得方便容易。
复数类型数据的形式为:a+bJ 或 a+bj
其中,a 是复数的实部,b 是复数的虚部,J 表示 −1 的平方根(虚数单位)。
虚数单位既可以用大写字母J 也可以写成小写字母 j,注意不是数学上的i。
例:
>>> x=12+34J
>>> print(x)
(12+34j)
可以通过x.real 和x.imag 来分别获取复数x 的实部和虚部,结果都是浮点型。
例:接着上面的语句,继续执行以下语句:
>>> x.real
12.0
>>> x.imag
34.0
字符串
字符串是指一系列单个字符组成的数据结构,可以使用英文格式的单引号(')或双引号(")定义;当文本本身包含引号时,可以使用长注释(''')作为边界符。同时,字符串支持通过索引值查找和切片操作,用法如下:
#定义字符串str1 = 'abc'str2 = '''abc isn't abcd '''#字符串的索引print(str1[0]) #索引值为0的字符#字符串的切片print(str2[0:2]) #索引值为0-2的字符print(str2[-4:]) #倒数第四个字符至结尾print(str2[::]) #整个字符串
输出结果如下:

1) 字符串的定义方式
1. 单引号定义字符串 ‘ ’
2. 双引号定义字符串 “ ”
3. 三引号定义字符串 ‘’‘内容’‘’或者 “”“内容”“”
4. 字符串定义时,引号可以互相嵌套
2)转义字符
> 一个普通的字符出现在转义符 \ 的后面时,实现了另外一种意义
+ \ 转义符,续行符。
+ 作为转义符时,在\后面出现的字符可能会实现另外一种意义。
+ 作为续行符时,在行尾使用了\后,可以换行继续书写内容
+ \n 代表一个换行符
+ \r 代表光标位置(从\r出现的位置开始作为光标的起点)
+ \t 代表一个水平制表符(table 缩进)
+ \b 代表一个退格符
+ `\\` 反转义\,输出了\,取消\的转义效果
**把转义字符作为普通字符输出,在字符串的前面加 r' '**
示例:
```python
# \ 续行符
#续行符
# vars = '123' \
# '456'
# print(vars)
# \ 转义符,在字符出现的特定字符有着特定的意义
# \n 代表一个换行符
# vars = '岁月是把杀猪刀,\n\n但是它拿长得丑的人一点办法都没有。。。'
# \r 代表光标的位置(从\r出现的位置开始作为光标的起点)
# vars = '岁月是把杀猪刀,\r但是它拿长得丑的人一点办法都没有。。。'
# \t 水平制表符(table 缩进)
# vars = '岁月是把杀猪刀,\t但是它拿长得丑的人一点办法都没有。。。'
# \b 退格符
# vars = '岁月是把杀猪刀,\b但是它拿长得丑的人一点办法都没有。。。'
# \\ 一个\是转义符,在这个符号前在定义一个\ 就会取消转义。变成一个普通的\输出
# vars = '岁月是把杀猪刀,\\n但是它拿长得丑的人一点办法都没有。。。'
# 把转义字符作为普通字符输出,在字符串的前面加 r''
vars = r'岁月是把杀猪刀,\b但是它拿长得丑的人一点办法都没有。。。'
print(vars)
```
3)字符串相关的操作
+ 字符串 + 操作
+ 字符串 * 操作
+ 字符串 [] 切片操作
+ 字符串[开始值:结束值:步进值]
开始值:默认为0,结束值默认是最后一个下标,步进值默认为1
示例:
```python
# - 字符串 + 操作
vara = '君不见,黄河之水天上来,奔流到海不复回.'
varb = '君不见,高堂明镜悲白发,朝如青丝暮成雪'
# res = vara + varb
# print(res)
res = '将进酒 '+'李白'
# print(res)
# - 字符串 * 操作
# vars = '鸡你太美,' * 5
# print(vars)
# 鸡你太美鸡你太美鸡你太美鸡你太美鸡你太美
# - 字符串 [] 切片操作 ****
# 字符串的索引操作,字符串中只能使用[]下标 访问,不能修改
'''
0 1 2 3 4 5 6 7 8 9 10 ....
君不见,黄河之水天上来,奔流到海不复回
-4 -3 -2 -1
'''
vars = '君不见,黄河之水天上来,奔流到海不复回'
# print(vars[5])
# print(vars[-5])
'''
字符串的切片操作
str[开始值:结束值:步进值]
开始值:默认为0,结束值默认是最后一个下标,步进值默认为1
'''
# print(vars)
# print(vars[5]) # 写一个值就是获取指定下标的元素
# print(vars[2:5]) # 从2下标开始取值,一直到下标5之前,能取到2,取不到5
# print(vars[4:8:2]) # 黄河之水 ==> 黄之
# print(vars[::]) # 从头取到尾
# print(vars[::2]) # 从头取到尾,每隔一个取一个
# print(vars[::-1]) # 字符串倒转过来
# print(vars[::-2]) # 字符串倒转过来,每隔一个取一个
# print(vars[1::]) # 不见,黄河之水天上来,奔流到海不复回
# print(vars[1::2]) # 不,河水上,流海复
```
字符串格式化的方法
+ format
+ f
示例:
```python
1 format 普通方式
a = '李白'
# vars = '{}乘舟将欲行,互闻岸上踏歌声'.format(a)
# vars = '{}乘舟将欲行,互闻岸上{}'.format(a,'踏歌声')
2 format 通过索引传参 0 1 2
# vars = '{2}乘舟将欲行,互闻岸上{1}'.format('a','b','c')
3 format 关键字传参
# vars = '{a}乘舟将欲行,互闻岸上{b}'.format(a='李白',b='踏歌声')
4 format 容器类型数据传参
# vars = '豪放派:{0[0]},婉约派:{0[1]},蛋黄派:{0[2]}'.format(['李白','辛弃疾','达利园'])
data = {'a':'辛弃疾','b':'蛋黄派'}
vars = '{a}乘舟将欲行,互闻岸上{b}'.format(**data)
3.7中新增的 格式化方法 f方法
vars = f'{data["a"]}乘舟将欲行,互闻岸上{data["b"]}'
# print(vars)
# 限定小数的位数
# vars = '圆周率是多少:{:.2f}'.format(3.1415926)
# print(vars)
```
字符串相关函数
> 官方文档:内置类型:字符串
>
> https://docs.python.org/3.7/library/stdtypes.html#text-sequence-type-str
#### (一) 英文字符与字符检测相关函数
```python
# 字符串相关函数 (一) 英文字符与字符检测相关函数
vars = 'iloveyou'
返回字符串的副本,该字符串的首个字符大写,其余小写。
# str.capitalize()
res = vars.capitalize()
把字符串中的一个单词的首字母大写
res = vars.title()
把字符串全部改为 大写
res = vars.upper()
把字符串全部改为 小写
res = vars.lower()
字符串中的大小写字符转换,大写转小写,小写转大写
res = vars.swapcase()
检测字符串是否为全部大写字母组成
res = vars.isupper()
检测字符串是否为全部小写字母组成
res = vars.islower()
检测字符串是否符合标题title的要求
res = vars.istitle()
检测字符串是否由数字和字母组成,如果字符串中包含来非数字字母的其它字符,则返回False
res = vars.isalnum()
检测字符串是否全部由字符(包含英文字符和中文)组成
res = vars.isalpha()
检测字符串是否由纯数字字符组成
res = vars.isdigit()
检测当前字符串是否为 空格 字符组成 ' '
res = vars.isspace()
检测字符串是否以指定的字符开始的,也可以指定开始和结束的位置
res = vars.startswith('y')
# res = vars.startswith('y',5)
检测字符串是否以 指定的字符 结束的,也可以指定开始和结束的位置
# res = vars.endswith('y')
res = vars.endswith('e',1,5)
print(res)
```
(二)字符串 查找与操作相关函数
示例:
```python
** find() 方法 ,找到则返回字符中符合条件的第一个字符出现的索引位置。未找到返回 -1
res = vars.find('you')
# print(vars[res:res+3])
index() 方法
# res = vars.index('youe') # 找到则返回索引位置,未找到则报错 ValueError
# print(res)
vars = 'user_admin_id_123'
split() 方法 可以按照指定的分隔符,把字符串分隔成列表
# res = vars.split('_')
# ['user', 'admin', 'id', '123']
res = vars.split('_',2)
# ['user', 'admin', 'id_123']
# print(res)
rsplit() 方法是从右向左进行,从后向前
# res = vars.rsplit('_') # ['user', 'admin', 'id', '123']
res = vars.rsplit('_',2) # ['user_admin', 'id', '123']
# print(res)
join() 方法 ,使用指定的字符串,把一个容器中的元素链接成一个字符串
varlist = ['user', 'admin', 'id', '123']
res = '_'.join(varlist)
strip() 去除字符串左右两侧的指定字符
vars = ' zhangsan '
res = vars.strip(' ')
vars = '@admin'
res = vars.strip('@')
# print(vars)
# print(res)
rstrip() 去除字符串右侧的指定字符, lstrip() 去除字符串左侧的指定字符
len() 函数可以获取当前字符串的长度
# print(len(vars))
# print(len(res))
replace() 替换函数
vars = 'iloveyou'
# 找到 love 替换为 live
res = vars.replace('love','live')
vars = 'aabbccddeeabcdef'
# 可以限制替换的次数
res = vars.replace('b','B',2)
# print(res)
此外,字符串的使用还涉及到各类非常丰富的方法,这里列举其中的部分:
| 功能 | 方法 |
|---|---|
| 查看元素 | str.index() str.find() str.count() |
| 字母大小写转换 | str.capitalize() str.lower() str.casefold() str.upper() |
| 指定字符替换 | str.replace() str.translate() |
列表(list)
列表是由一系列按特定顺序排列的元素组成的有序集合,也是Python中使用最为频繁的数据类型之一。列表同样可以进行切片和索引,这里对其用法做简单展示:
#定义列表list1 = [2,5,'a',7] #列表可以容纳不同类型的元素list2 = [3,5,7,[9,11]] #列表中可以嵌套#访问列表print(list1[2]) # 索引print(list2[1:3]) #切片#更改元素list1[1] = 'b' #将索引值为1的元素修改为blist2[2:] = '' #将索引值为2的元素到列表的结尾修改为空print(list1)print(list2)
输出结果如下:

+ 可以使用 中括号进行定义 []
+ 也可以使用 list函数 定义
+ 在定义列表中的元素时,需要在每个元素之间使用逗号,进行分隔。[1,2,3,4]
+ 列表中的元素可以是任意类型的,通常用于存放同类项目的集合
列表的基本操作
+ 列表定义-[],list()
+ 列表相加-拼接
+ 列表相乘-重复
+ 列表的下标- 获取,更新
+ 列表元素的添加-append()
+ 列表元素的删除
+ del 列表[下标]
+ pop()函数 删除元素
列表中切片
> 语法==> 列表[开始索引:结束索引:步进值]
1。 列表[开始索引:] ==> 从开始索引到列表的最后
2。 列表[:结束值] ==> 从开始到指定的结束索引之前
3。 列表[开始索引:结束索引] ==> 从开始索引到指定结束索引之前
4。 列表[开始索引:结束索引:步进值] ==> 从指定索引开始到指定索引前结束,按照指定步进进行取值切片
5。 列表[:] 或 列表[::] ==> 所有列表元素的切片
6。 列表[::-1] ==> 倒着获取列表的元素
示例:
```python
varlist = ['刘德华','张学友','张国荣','黎明','郭富城','小沈阳','刘能','宋小宝','赵四']
# 从开始索引到列表的最后
res = varlist[2:] # ['张国荣','黎明','郭富城','小沈阳','刘能','宋小宝','赵四']
# 从开始到指定的结束索引之前
res = varlist[:2] # ['刘德华','张学友']
# 从开始索引到指定结束索引之前
res = varlist[2:6] # ['张国荣', '黎明', '郭富城', '小沈阳']
# 从指定索引开始到指定索引前结束,按照指定步进进行取值切片
res = varlist[2:6:2] # ['张国荣', '郭富城']
# 所有列表元素的切片
res = varlist[:]
res = varlist[::]
# 倒着输出列表的元素
res = varlist[::-1]
# 使用切片方法 对列表数据进行更新和删除
print(varlist)
# 从指定下标开始,到指定下标前结束,并替换为对应的数据(容器类型数据,会拆分成每个元素进行赋值)
# varlist[2:6] = ['a','b','c',1,2,3]
# varlist[2:6:2] = ['a','b'] # 需要与要更新的元素个数对应
# 切片删除
# del varlist[2:6]
del varlist[2:6:2]
```
## 列表相关函数
```python
varlist = ['刘德华','张学友','张国荣','张学友','黎明','郭富城','小沈阳','刘能','宋小宝','赵四']
# len() 检测当前列表的长度,列表中元素的个数
res = len(varlist)
# count() 检测当前列表中指定元素出现的次数
res = varlist.count('张学友')
# append() 向列表的尾部追加新的元素,返回值为 None
varlist.append('川哥')
# insert() 可以向列表中指定的索引位置添加新的元素,
varlist.insert(20,'aa')
# pop() 可以对指定索引位置上的元素做 出栈 操作,返回出栈的元素
res = varlist.pop() # 默认会把列表中的最后一个元素 出栈
res = varlist.pop(2) # 会在列表中把指定索引的元素进行 出栈
varlist = [1,2,3,4,11,22,33,44,1,2,3,4]
# remove() 可以指定列表中的元素 进行 删除,只删除第一个。如果没有找到,则报错
res = varlist.remove(1)
# index() 可以查找指定元素在列表中第一次出现的索引位置
# res = varlist.index(1)
# res = varlist.index(1,5,20) # 可以在指定索引范围内查找元素的索引位置
# extend() 接收一个容器类型的数据,把容器中的元素追加到原列表中
# varlist.extend('123')
# clear() # 清空列表内容
# varlist.clear()
# reverse() 列表翻转
varlist.reverse()
# sort() 对列表进行排序
res = varlist.sort() # 默认对元素进行从小到大的排序
res = varlist.sort(reverse=True) # 对元素进行从大到小的排序
res = varlist.sort(key=abs) # 可以传递一个函数,按照函数的处理结果进行排序
```
深拷贝与浅拷贝
浅拷贝
> 浅拷贝只能拷贝列表中的一维元素,**如果列表中存在二维元素或容器,则引用而不是拷贝**
>
> 使用cpoy函数或者copy模块中的copy函数拷贝的都是浅拷贝
```python
# 浅拷贝 只能拷贝当前列表,不能拷贝列表中的多维列表元素
varlist = [1,2,3]
# 简单的拷贝 就可以把列表复制一份
newlist = varlist.copy()
# 对新拷贝的列表进行操作,也是独立的
del newlist[1]
# print(varlist,id(varlist))
# print(newlist,id(newlist))
'''
[1, 2, 3] 4332224992
[1, 3] 4332227552
'''
# 多维列表
varlist = [1,2,3,['a','b','c']]
# 使用copy函数 拷贝一个多维列表
newlist = varlist.copy()
'''
print(newlist,id(newlist))
print(varlist,id(varlist))
[1, 2, 3, ['a', 'b', 'c']] 4361085408
[1, 2, 3, ['a', 'b', 'c']] 4361898496
'''
# 如果是一个被拷贝的列表,对它的多维列表元素进行操作时,会导致原列表中的多维列表也发生了变化
del newlist[3][1]
'''
通过id检测,发现列表中的多维列表是同一个元素(对象)
print(newlist[3],id(newlist[3]))
print(varlist[3],id(varlist[3]))
['a', 'c'] 4325397360
['a', 'c'] 4325397360
'''
```
深拷贝
> 深拷贝就是不光拷贝了当前的列表,**同时把列表中的多维元素或容器也拷贝了一份,而不是引用**
>
> 使用copy模块中的 deepcopy 函数可以完成深拷贝
```python
# 深拷贝 就是不光拷贝了当前的列表,同时把列表中的多维元素也拷贝了一份
import copy
varlist = [1,2,3,['a','b','c']]
# 使用 copy模块中 深拷贝方法 deepcopy
newlist = copy.deepcopy(varlist)
del newlist[3][1]
print(varlist)
print(newlist)
'''
print(newlist[3],id(newlist[3]))
print(varlist[3],id(varlist[3]))
['a', 'c'] 4483351248
['a', 'b', 'c'] 4483003568
'''
```
## 列表推到式
>List-Comprehensions
>
>列表推导式提供了一个更简单的创建列表的方法。
>
>常见的用法是把某种操作应用于序列或可迭代对象的每个元素上,然后使用其结果来创建列表,或者通过满足某些特定条件元素来创建子序列。
>
>采用一种表达式的当时,对数据进行过滤或处理,并且把结果组成一个新的列表
### 一,基本的列表推到式使用方式
> 结果变量 = [变量或变量的处理结果 for 变量 in 容器类型数据]
示例:
```python
# 1 假设我们想创建一个平方列表
# 使用普通方法完成
varlist = []
for i in range(10):
varlist.append(i**2)
# print(varlist) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 使用 map函数和list完成
varlist = list(map(lambda x: x**2, range(10)))
# print(varlist) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 使用列表推到式完成 下面这个列表推到式和第一种方式是一样的
varlist = [i**2 for i in range(10)]
# print(varlist) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 2。 '1234' ==> [2,4,6,8]
# 常规方法完成需求
varstr = '1234'
newlist = []
for i in varstr:
newlist.append(int(i)*2)
# print(newlist) # [2, 4, 6, 8]
# 使用列表推到式完成上面的需求
newlist = [int(i)*2 for i in varstr]
# print(newlist) # [2, 4, 6, 8]
# 使用列表推到式+位运算完成
newlist = [int(i) << 1 for i in varstr]
# print(newlist) # [2, 4, 6, 8]
```
### 二,带有判断条件的列表推到式
> 结果变量 = [变量或变量的处理结果 for i in 容器类型数据 条件表达式]
示例:
```python
# 0-9 求所有的偶数,==> [0, 2, 4, 6, 8]
# 常规方法完成
newlist = []
for i in range(10):
if i % 2 == 0:
newlist.append(i)
# print(newlist) # [0, 2, 4, 6, 8]
# 列表推到式完成
newlist = [i for i in range(10) if i % 2 == 0]
# print(newlist) # [0, 2, 4, 6, 8]
```
### 三,对于嵌套循环的列表推到式
```python
'''
# 下面这个 3x4的矩阵,它由3个长度为4的列表组成,交换其行和列
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
==>
[
[1, 5, 9],
[2, 6, 10],
[3, 7, 11],
[4, 8, 12]
]
'''
arr = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
# 常规方法完成
# newlist = []
# for i in range(4):
# res = []
# for row in arr:
# res.append(row[i])
# newlist.append(res)
# print(newlist)
# 使用列表推到式完成
newlist = [[row[i] for row in arr] for i in range(4)]
print(newlist)
同时,列表本身中内置了很多方法,可以简化我们的许多操作:
| 功能 | 方法 |
| 增加元素 | list.append() list.extend() list.insert() |
| 删除元素 | list.pop() list.remove() list.clear() |
| 查看元素 | list.index() list.count() |
| 元素排序 | list.reverse() list.sort() |
元祖(tuple)
元组是由括号与逗号创建的,它与列表的相似之处在于可以包含任意数据类型,可以进行索引和切片,我们可采用如下方式定义和访问:
#定义元组tuple1 = (1,'python',2,'home') #元素可以是任意类型tuple2 = (1,)
#元素只有一个时,后面要带有逗号“,”#访问元组print(tuple1[2]) #索引print(tuple2[0:2]) #切片
输出结果如下:

与列表不同的是,元祖是不可变对象,其中的元素是不可修改的,如下所示:
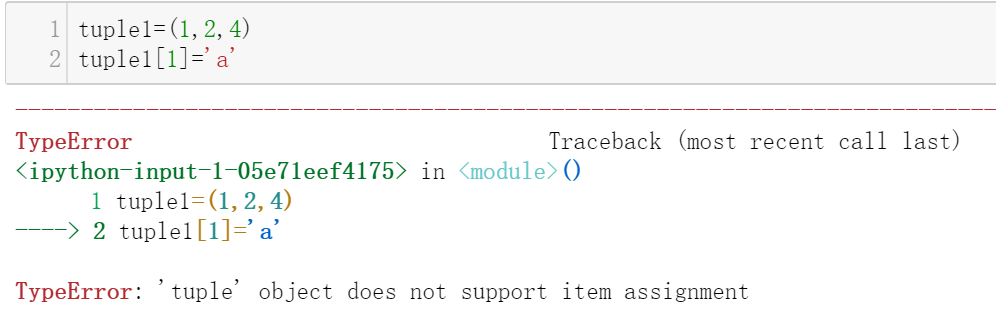
正是因为元祖不可变的特性,它不具备remove、append、extend等方法,不过,它仍然可查看元素的索引值和频次:

定义空元组 变量 = (),或者 变量=tuple()
+ 还可以使用 变量 = (1,2,3) 定义含有数据的元组
+ 注意:如果元组中只有一个元素时,必须加逗号 变量=(1,)
+ 特例:变量=1,2,3 这种方式也可以定义为一个元组
### 元组的相关操作
> 由于元组是不可变的数据类型,因次只能使用索引进行访问,不能进行其它操作
>
> 元组可以和列表一样使用切片方式获取元素
### 元组的切片操作
> 元组的切片操作 和列表是一样的
```python
vart = (1,2,3,4,5,5,4,3,2,1)
res = vart[:] # 获取全部
res = vart[::] # 获取全部
res = vart[1:] # 从索引1开始获取到最后
res = vart[1:3] # 从索引1开始到索引3之前
res = vart[:3] # 从索引 0 开始 到 索引 3之前
res = vart[1:5:2] # 从索引1开始到索引5之前,步进值为2
res = vart[::2] # 从索引 0 开始 到 最后 ,步进值为2
res = vart[5:1:-1] # 从索引5开始 到索引 1,步进值为-1 倒着输出
```
### 元组推导式 生成器
> 列表推导式结果返回了一个列表,元组推导式返回的是生成器
语法:
列表推导式 ==> [变量运算 for i in 容器] ==> 结果 是一个 列表
元组推导式 ==> (变量运算 for i in 容器) ==> 结果 是一个 生成器
#### 生成器是什么?
> 生成器是一个特殊的迭代器,生成器可以自定义,也可以使用元组推导式去定义
>
> 生成器是按照某种算法去推算下一个数据或结果,只需要往内存中存储一个生成器,节约内存消耗,提升性能
#### 语法:
1. 里面是推导式,外面是一个() 的结果就是一个生成器
2. 自定义生成器,含有yield关键字的函数就是生成器
> 含有yield关键字的函数,返回的结果是一个迭代器,换句话说,生成器函数就是一个返回迭代器的函数
#### 如何使用操作生成器?
生成器是迭代器的一种,因此可以使用迭代器的操作方法来操作生成器
示例代码:
```python
# 列表推导式
varlist = [1,2,3,4,5,6,7,8,9]
# newlist = [i**2 for i in varlist]
# print(newlist) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
# 元组推导式 生成器 generator
newt = (i**2 for i in varlist)
print(newt) # <generator object <genexpr> at 0x1104cd4d0>
# 使用next函数去调用
# print(next(newt))
# print(next(newt))
# 使用list或tuple函数进行操作
# print(list(newt))
# print(tuple(newt))
# 使用 for 进行遍历
# for i in newt:
# print(i)
字典(dict)
字典是除列表以外Python之中最灵活的内置数据结构类型,它也是一种可变容器模型,但是无序的。字典当中的元素是通过键来存取的,因而具有极快的查找速度。它用“{ }”标识,由索引(key)和它对应的值(value)组成。下面进行举例展示:
#定义字典dict = {'Jennie': 99, 'Bob': 65, 'Tom': 85}
#一个key只能对应一个value#访问字典dict #输出完整的字典dict.keys() #输出所有键dict.values()
#输出所有值dict['Jennie'] #输出“Jennie”的值#修改字典dict['Bob'] = 78 #更新"Bob"的值dict['Helen'] = 99 #添加信息"Helen"
输出结果为:

字典中的键值对具有两个特性:
1)键必须是唯一的,但值则不必;
2)键必须是不可变的,如字符串、数字或元组,但值可以取任何数据类型。
> 字典也是一种数据的集合,由键值对组成的数据集合,字典中的键不能重复
>
> 字典中的键必须是不可变的数据类型,常用的键主要是:字符串,整型。。。
+ 字典可以通过将以逗号分隔的 `键: 值` 对列表包含于花括号之内来创建字典
+ 也可以通过 [`dict`](https://docs.python.org/zh-cn/3.7/library/stdtypes.html#dict) 构造器来创建
`{'jack': 4098, 'sjoerd': 4127}` 或 `{4098: 'jack', 4127: 'sjoerd'}`
```python
# 1。 使用{}定义
vardict = {'a':1,'b':2,'c':2}
# 2。 使用 dict(key=value,key=value) 函数进行定义
vardict = dict(name='zhangsan',sex='男',age=22)
# 3。 数据类型的转换 dict(二级容器类型) 列表或元组,并且是二级容易才可以转换
vardict = dict([['a',1],['b',2],['c',3]]) # {'a': 1, 'b': 2, 'c': 3}
# 4。zip压缩函数,dict转类型
var1 = [1,2,3,4]
var2 = ['a','b','c','d']
# 转换的原理和上面的第三种 是一个原理
vardict = dict(zip(var1,var2)) # {1: 'a', 2: 'b', 3: 'c', 4: 'd'}
print(vardict)
```
### 字典的操作
```python
var1 = {'a': 1, 'b': 2, 'c': 3}
var2 = {1: 'a', 2: 'b', 3: 'c', 4: 'd'}
# res = var1 + var2 # XXXX TypeError
# res = var1 * 3 # xxxx TypeError
# 获取元素
res = var1['a']
# 修改元素
res = var1['a'] = 111
# 删除元素
del var1['a']
# 添加元素
var1['aa'] = 'AA'
# 如果字典中的key重复了,会被覆盖
# var1['aa'] = 'aa'
```
### 成员检测和获取
```python
# 三 成员检测和获取 ,只能检测key,不能检测value
res = 'AA' in var1
res = 'AA' not in var1
# 获取当前字典的长度 只能检测当前又多少个键值对
res = len(var1)
# 获取当前字典中的所有 key 键
res = var1.keys()
# 获取字典中所有的 value 值
res = var1.values()
# 获取当前字典中所有 键值对
res = var1.items()
```
### 字典的遍历
```python
# 四, 对字典进行遍历
# (1)在遍历当前的字典时,只能获取当前的key
for i in var1:
print(i) # 只能获取 key
print(var1[i]) # 通过字典的key获取对应value
#(2)遍历字典时,使用 items() 函数,可以在遍历中获取key和value
for k,v in var1.items():
print(k) # 遍历时的 key
print(v) # 遍历时的 value
print('===='*20)
# (3) 遍历字典的所有key
for k in var1.keys():
print(k)
print('===='*20)
# (4) 遍历字典的所有 value
for v in var1.values():
print(v)
```
### 字典的相关函数
```python
# 字典相关函数
# len(字典) #获取字典的键值对个数
# dict.keys() # 获取当前字典的所有key 键,组成的列表
# dict.values() # 获取当前字典的所有 value 值,组成的列表
# dict.items() # 返回由字典项 ((键, 值) 对) 组成的一个新视图
# iter(d) 返回以字典的键为元素的迭代器。
vardict = {'a':1,'b':2,'c':3}
# dict.pop(key) # 通过 key 从当前字典中弹出键值对 删除
# res = vardict.pop('a')
# dict.popitem() LIFO: Last in, First out.后进先出
# res = vardict.popitem() # 把最后加入到字典中的键值对删除并返回一个元组
# 使用key获取字典中不存在元素,会报错
# print(vardict['aa'])
# 可以使用get获取一个元素,存在则返回,不存在默认返回None
# res = vardict.get('aa')
# res = vardict.get('aa','abc')
# dict.update(),更新字典,如果key存在,则更新,对应的key不存在则添加
# vardict.update(a=11,b=22)
# vardict.update({'c':33,'d':44})
# dict.setdefault(key[,default])
# 如果字典存在键 key ,返回它的值。
# 如果不存在,插入值为 default 的键 key ,并返回 default 。
# default 默认为 None。
res = vardict.setdefault('aa','123')
print(res)
print(vardict)
```
### 字典推导式
```python
# 把字典中的键值对位置进行交换 {'a':1,'b':2,'c':3}
vardict = {'a':1,'b':2,'c':3}
# 普通方法实现 字典中的键值交换 {1: 'a', 2: 'b', 3: 'c'}
newdict = {}
for k,v in vardict.items():
newdict[v] = k
# print(newdict)
# 使用字典推导式完成 {1: 'a', 2: 'b', 3: 'c'}
newdict = {v:k for k,v in vardict.items()}
# print(newdict)
# 注意:以下推导式,返回的结果是一个集合,集合推导式
# newdict = {v for k,v in vardict.items()}
# print(newdict,type(newdict))
# 把以下字典中的是偶数的值,保留下来,并且交换键值对的位置
vardict = {'a':1,'b':2,'c':3,'d':4}
# 普通方式完成 {2: 'b', 4: 'd'}
# newdict = {}
# for k,v in vardict.items():
# if v % 2 == 0:
# newdict[v] = k
# print(newdict)
# 字典推导式完成 {2: 'b', 4: 'd'}
newdict = {v:k for k,v in vardict.items() if v % 2 == 0}
# print(newdict)
字典还具有其他几个内置函数和功能,如下所示:
| 功能 | 方法 |
| 访问字典的键值 | dict.keys() dict.values() |
| 判断键值是否存在 | dict.get() dict.setdefault() |
| 删除键值 | dict.pop() dict.popitem() |
| 清空字典 | dict.clear() |
| 把字典dict2更新到dict里 | dict.update(dict2) |
集合(set)
集合是一个无序的不重复元素序列,与dict类似,也是一组key的集合,但不存储value。需要注意,创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。集合最大的特点在于其元素的不可重复性,如下所示:

+ 可以直接使用 {} 来定义集合
+ 可以使用set()进行集合的定义和转换
+ 使用集合推导式完成集合的定义
**注意:集合中的元素不能重复,集合中存放的数据:Number,Strings,Tuple,冰冻集合**
### 集合的基本操作和常规函数
```python
# 定义集合
vars = {123,'abc',False,'love',True,(1,2,3),0,3.1415,'123'}
# 1。无序。
# 2。布尔类型 True 表示为 1,False 表示为 0,布尔和数字只存在一个
# 3。元素的值不能重复
# {0, 'abc', 'love', True, 3.1415, (1, 2, 3), 123}
# 检测集合中的值
res = '123' in vars
res = '123' not in vars
# 获取集合中元素的个数 len()
# res = len(vars)
# 集合的遍历
# for i in vars:
# print(i,type(i))
# 向集合中追加元素 add()
res = vars.add('def')
# 删除集合中的元素 随机删除一个元素并返回 abc False True 3.1415
# r1 = vars.pop()
# 指定删除集合中的元素 remove() 返回None,不存在则报错
# res = vars.remove('aaa')
# discard 指定删除集合中的元素,不存在也不会报错
# res = vars.discard('aaa')
# clear() 清空集合
# res = vars.clear()
# update(others) 更新集合,添加来自 others 中的所有元素。
res = vars.update({1,2,3,4,5})
# 当前集合中的浅拷贝并不存在 深拷贝的问题
res = vars.copy()
'''
当前集合中的浅拷贝并不存在 深拷贝的问题
因为集合中的元素都是不可变,包括元组和冰冻集合
不存在拷贝后,对集合中不可变的二级容器进行操作的问题
'''
```
### 冰冻集合(了解)
> 定义冰冻集合,只能使用 frozenset() 函数进行冰冻集合的定义
+ 冰冻集合一旦定义不能修改
+ 冰冻集合只能做集合相关的运算:求交集,差集,。。。
+ frozenset() 本身就是一个强制转换类的函数,可以把其它任何容器类型的数据转为冰冻集合
```python
# 定义
vars = frozenset({'love',666,'a',1,'b',2,'521'})
# vars = frozenset([1,2,3])
# 遍历
# for i in vars:
# print(i)
# 冰冻集合的推导式
res = frozenset({i<<1 for i in range(6)})
# 冰冻集合可以和普通集合一样,进行集合的运算 交集。。。
# copy()
res = res.copy()
# print(res)
```
### 集合的推导式
```python
# 集合推导式
varset = {1,2,3,4}
# (1) 普通推导式
newset = {i<<1 for i in varset }
# (2) 带有条件表达式的推导式
newset = {i<<1 for i in varset if i%2==0}
# (3) 多循环的集合推导式
vars1 = {1,2,3}
vars2 = {4,5,6}
# newset = set()
# for i in vars1:
# for j in vars2:
# print(i,j)
# newset.add(i+j)
# print(newset)
newset = {i+j for i in vars1 for j in vars2}
# print(newset)
# (4) 带条件表达式的多循环的集合推导式
newset = {i+j for i in vars1 for j in vars2 if i%2==0 and j%2==0}
print(newset)
```
### 集合的运算
#### 集合的主要运算
+ 交集 & set.intersection() set.intersection_update()
+ 并集 | union() update()
+ 差集 - difference(),difference_update()
+ 对称差集 ^ symmetric_difference() symmetric_difference_update()
```python
vars1 = {'郭富城','刘德华','张学友','黎明','都敏俊',1}
vars2 = {'尼古拉斯赵四','刘能','小沈阳','宋小宝','都敏俊',1}
# & 求两个集合相交的部分
res = vars1 & vars2
# | 求两个集合的并集,就是把集合中所有元素全部集中起来,(去除重复)
res = vars1 | vars2
# - 差集运算
res = vars1 - vars2 # vars1有,而,vars2 没有的
res = vars2 - vars1 # vars2有,而,vars1 没有的
# ^ 对称差集
res = vars1 ^ vars2
# 交集运算函数 intersection intersection_update
# set.intersection() # 返回交集的结果 新的集合
# res = vars1.intersection(vars2)
# set.intersection_update() # 没有返回值
# 计算两个集合的相交部分,把计算结果重新赋值给第一个集合
# res = vars1.intersection_update(vars2)
# 并集运算函数 | union() update()
# res = vars1.union(vars2) # 返回并集结果,新的集合
# 求并集运算,并且把结果赋值给第一个集合
# res = vars1.update(vars2) # 没有返回值
# print(vars1)
# 差集运算 函数 difference(),difference_update()
# res = vars1.difference(vars2) # 返回差集结果 新的集合
# 把差集的结果,重新赋值给第一个集合
# res = vars1.difference_update(vars2) # 没有返回值
# 求对称差集
# res = vars1.symmetric_difference(vars2) # 返回对称差集的结果 新的集合
# 把对称差集的运算结果,重新赋值给第一个集合
res = vars1.symmetric_difference_update(vars2)# 没有返回值
```
#### 集合检测
+ issuperset() 检测是否为超集
+ issubset() 检测是否为子集
+ isdisjoint() 检测是否不相交
```python
# 检测 超集 子集
vars1 = {1,2,3,4,5,6,7,8,9}
vars2 = {1,2,3}
# issuperset() 检测是否为超集
res = vars1.issuperset(vars2) # True vars1是vars2的超集
res = vars2.issuperset(vars1) # False
# issubset() 检测是否为子集
res = vars1.issubset(vars2) # False
res = vars2.issubset(vars1) # True vars2是vars1的子集
# 检测两个集合是否相交
vars1 = {1,2,3}
vars2 = {5,6,3}
# isdisjoint 检测是否不相交, 不相交返回True,相交则返回False
res = vars1.isdisjoint(vars2)
print(res)
在集合中也内嵌了很多方法,这里做简单整理:
| 功能 | 方法 |
| 集合的赋值 | S.add() S.update() S.copy() |
| 删除集合中的元素 | S.discard() S.pop() S.remove() S.clear() |
| 交集运算 | S.intersection() |
| 差集运算 | S.difference() S.difference_update() |
| 并集运算 | S.union() |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号