
词法分析程序的设计与实现
此程序要逐个检查运行情况,并能当场补全代码。
词法分析程序(Lexical Analyzer)要求:
- 从左至右扫描构成源程序的字符流
- 识别出有词法意义的单词(Lexemes)
- 返回单词记录(单词类别,单词本身)
- 滤掉空格
- 跳过注释
- 发现词法错误
程序结构:
输入:字符流(什么输入方式,什么数据结构保存)
处理:
–遍历(什么遍历方式)
–词法规则
输出:单词流(什么输出形式)
–二元组
单词类别:
1.标识符(10)
2.无符号数(11)
3.保留字(一词一码)
4.运算符(一词一码)
5.界符(一词一码)
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<= |
21 |
|
do |
5 |
<> |
22 |
|
end |
6 |
> |
23 |
|
l(l|d)* |
10 |
>= |
24 |
|
dd* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
代码如下:
#include<conio.h>
#include<stdio.h>
#include<string.h>
#define Max 100
char duru[100];//存放输入字符串
char zuche[20];//存放构成单词符号的字符串
char ch; //存放当前读入字符
int p; //duru[]下标
int fg; //种别码
int num; //存放整形值
char index[35][10]={"begin","if","then","while","do","end","char","double","enum","float","int","long","short","signed",
"struct","union","unsigned","void","for","break","continue","else","goto","switch","case","default",
"return","auto","extern","register","static","const","sizeof","typedef","volatile"};
void panduan(){
int m=0;//zuche[]下标
int n;
//清空zuche[]
for(n=0;n<5;n++)
zuche[n]=NULL;
//获取第一个不为0字符
ch=duru[p++];
while(ch==' ')ch=duru[p++];
//关键字(标识符)处理流程
if((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A'))
{
while((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A')||(ch<='9'&&ch>='0'))
{
zuche[m++]=ch;
ch=duru[p++];
}
zuche[m++]='\0';
ch=duru[--p];
fg=10;
for(n=0;n<6;n++)
if(strcmp(zuche,index[n])==0)//strcmp()比较两个字符串,相等返回0
{
fg=n+1;
break;
}
}
//数字处理流程
else if((ch<='9'&&ch>='0'))
{
num=0;
while((ch<='9'&&ch>='0'))
{
num=num*10+ch-'0';//实现数字字符串到数字的转换
ch=duru[p++];//下一个字符赋给ch,以判断下一个字符的类型
}
ch=duru[--p];
fg=11;
}
//运算符界符处理流程
else
switch(ch)
{
case '<':
m=0;
zuche[m++]=ch;
ch=duru[p++];
if(ch=='>') //产生<>
{
fg=21;
zuche[m++]=ch;
}
else if(ch=='=') //产生<=
{
fg=22;
zuche[m++]=ch;
}
else
{
fg=20;
ch=duru[--p];
}
break;
case '>':
zuche[m++]=ch;
ch=duru[p++];
if(ch=='=') //产生>=
{
fg=24;
zuche[m++]=ch;
}
else //产生>
{
fg=23;
ch=duru[--p];
}
break;
case ':':
zuche[m++]=ch;
ch=duru[p++];
if(ch=='=') //产生:=
{
fg=18;
zuche[m++]=ch;
}
else //产生:
{
fg=17;
ch=duru[--p];
}
break;
case '+':fg=13;zuche[0]=ch;break;
case '-':fg=14;zuche[0]=ch;break;
case '*':fg=15;zuche[0]=ch;break;
case '/':fg=16;zuche[0]=ch;break;
case ':=':fg=18;zuche[0]=ch;break;
case '<>':fg=21;zuche[0]=ch;break;
case '<=':fg=22;zuche[0]=ch;break;
case '>=':fg=24;zuche[0]=ch;break;
case '=':fg=25;zuche[0]=ch;break;
case ';':fg=26;zuche[0]=ch;break;
case '(':fg=27;zuche[0]=ch;break;
case ')':fg=28;zuche[0]=ch;break;
case '#':fg=0;zuche[0]=ch;break;
default:fg=-1;
}
}
main()
{
p=0;
printf("please intput string(End with '#'):\n");
do
{
ch=getchar();
duru[p++]=ch;
}while(ch!='#');
p=0;
do
{
panduan();
switch(fg) //输出结果
{
case 11:printf("( %d,%d ) \n",fg,num);break;
case -1:printf("input error\n"); break;
default:printf("( %d,%s ) \n",fg,zuche);
}
}while(fg!=0);
getch(); //用于让程序停留在显示页面
}
当前只实现了在页面的输入的词法分析,后期可能会实现文本的读入(注意:是有可能!)
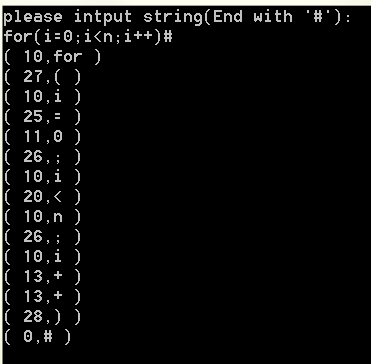
结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号