MIT6.824 Lab1 MapReduce
MapReduce分布式计算框架
MapReduce是谷歌开发的分布式计算框架。MapReduce需用户指定Map和Reduce两个函数具体操作内容。现实世界大多数计算操作都可以基于该操作完成。
Map&&Reduce操作
- Map
MapReduce按照记录读取文件,针对每条记录执行Map操作,将记录转化为KeyValues形式保存到中间文件中(根据Key的哈希值映射到指定文件中,文件如何分割根据partition函数) - Reduce
Reduce 读取中间文件,将相同Key的多个Values合并成到一个Value中。
MapReduce计算框架结构:
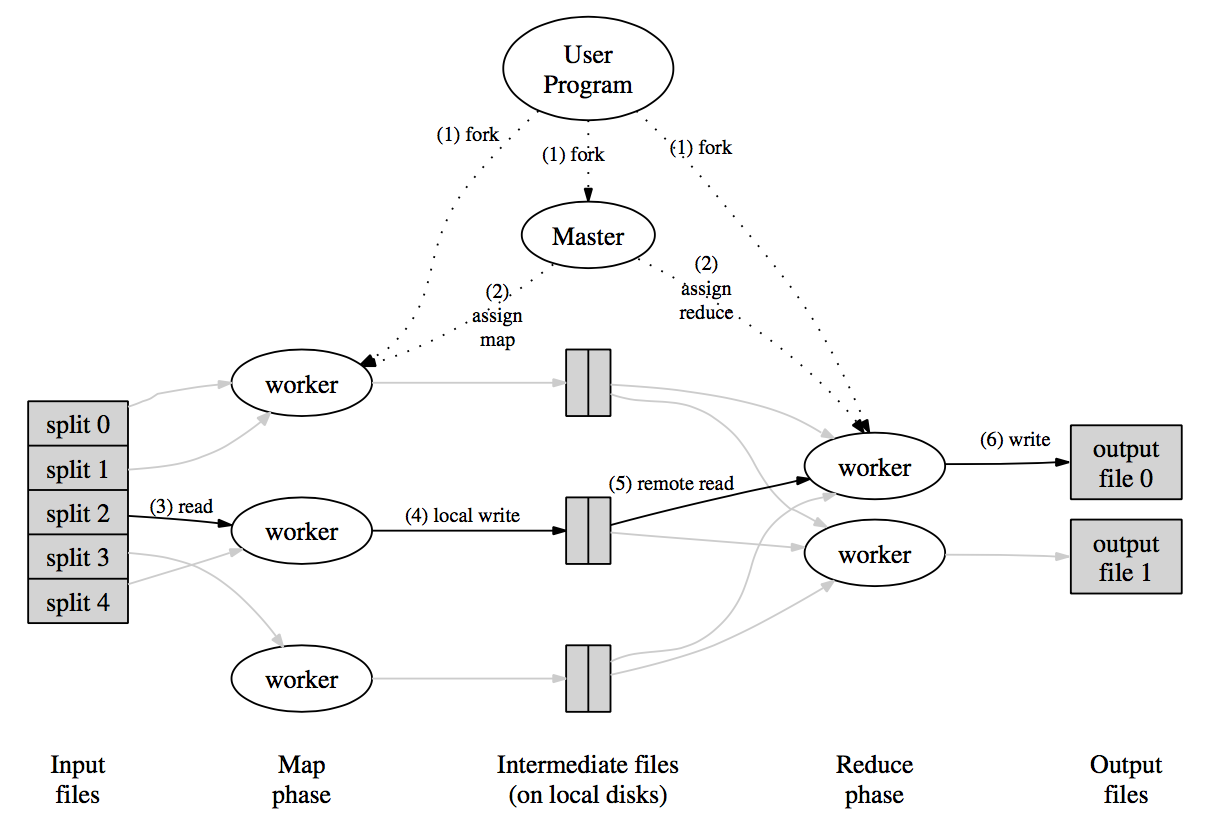
- MapReduce 首先将输入文件划分成M份放入到worker中,每个worker中都有一份代码的副本
- 其中一份副本作为master,其他worker被master分配工作。设定M个map任务以及R个reduce任务。master选择空闲的worker分配map任务或者reduce任务
- 分配map任务的worker,将输入文件的内容利用map函数将其解析为key-value,放入到内存中。
- 与此同时,内存中key-value pair分为R个文件写入到磁盘中。将文件地址传给master。
- reduce worker收到文件地址后,利用远程过程调用(RPC)读取所有中间文件,根据key值对文件排序(相同key的pair组成一起)
- 将key及具有该相同key的一组value传递到reduce函数中,处理结果追加到输出文件中。
- 所有map任务和reduce任务完成后, mapreduce返回结果,唤醒用户程序。
MapReduce操作实例
统计文本中各单词个数简略
- 将文件划分为若干份。
- map tasks:读取文件内容,
利用Map函数将文件中每条记录转化为KeyValues格式{key:"word",value:"count"},内容保存到中间文件中 - reduce task:读取中间文件,
按照单词字典序排序,**利用reduce函数将单词相同的Keyvalues中value求和,得到单词个数,写入输出文件 - 将多个输出文件合并
Q&A
-
What will likely limit the performance?
通常限制系统系性能,参考的因素包括通用的CPU、内存、磁盘读写、网络带宽、straggle五个方面。straggle和网络带宽是限制系统的两个主要因素。对于straggle,他的硬件各项性能可能比较低,或者说该机器已经被安排了其他很多任务,这时候map task或者reduce task分配的CPU资源较少,导致整个任务进度慢。那么在任务快要完成的时候,可以采用备份任务的机制,将未完成的子任务备份到其他机器上执行,不管主备那个完成了都代表整个任务完成了。从而提高了任务的完成进度。第二个则是网络带宽。平均每台机器的网络带宽远远小于本地的磁盘读写速度和内存读写速度。 -
How does detailed design reduce effect of slow network?
在MR中,map task需要获取输入数据,处理之后的中间文件传输到reduce task的机器中。reduce task处理后的数据写入磁盘。MR采用本地计算的原理,文件在网络中只传输一次,map task的输入文件存在本地,本质是master会将map 任务放在文件所在的机器上,进行本地读取。reduce的输出文件也是写入本地地盘。以此减少网络带宽的消耗。
为什么不用流式处理方式,map处理后的记录通过消息队列方式传送到reduce task的机器上? -
How do they get good load balance?
考虑不同机器的性能,分配不同数量的任务,性能较低的机器,分配较少的任务。 -
What about fault tolerance?
Part1 Map/Reduce input and output
完成common_map和common_reduce文件的内容。doMap函数用于读取输入文件,将文件按记录读取,对每条记录调用MapF函数,最后将结果映射到不同的文件中。doReduce函数读取中间文件,相同key的values合并。
common_map.go文件
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,) {// 为reduce提供键值对的切片,函数作为参数传递
//
// doMap manages one map task: it should read one of the input files
// (inFile), call the user-defined map function (mapF) for that file's
// contents, and partition mapF's output into nReduce intermediate files.
//
// There is one intermediate file per reduce task. The file name
// includes both the map task number and the reduce task number. Use
// the filename generated by reduceName(jobName, mapTask, r)
// as the intermediate file for reduce task r. Call ihash() (see
// below) on each key, mod nReduce, to pick r for a key/value pair.
//
// mapF() is the map function provided by the application. The first
// argument should be the input file name, though the map function
// typically ignores it. The second argument should be the entire
// input file contents. mapF() returns a slice containing the
// key/value pairs for reduce; see common.go for the definition of
//
// Look at Go's ioutil and os packages for functions to read
// and write files.
//
// Coming up with a scheme for how to format the key/value pairs on
// disk can be tricky, especially when taking into account that both
// keys and values could contain newlines, quotes, and any other
// character you can think of.
//
// One format often used for serializing data to a byte stream that the
// other end can correctly reconstruct is JSON. You are not required to
// use JSON, but as the output of the reduce tasks *must* be JSON,
// familiarizing yourself with it here may prove useful. You can write
// out a data structure as a JSON string to a file using the commented
// code below. The corresponding decoding functions can be found in
// common_reduce.go.
//
// enc := json.NewEncoder(file)
// for _, kv := ... {
// err := enc.Encode(&kv)
//
// Remember to close the file after you have written all the values!
//
// Your code here (Part I).
//
// 查看参数
fmt.Printf("jobname %s, MapTask %d inFile %s , nReduce %d\n",jobName,mapTask,inFile,nReduce)
buf,err := ioutil.ReadFile(inFile) //利用os打开文件,一般返回文件句柄
if err != nil{
fmt.Println("error")
}
slice := mapF(inFile,string(buf)) //mapF已经写好,返回keyvalue格式的切片
//fmt.Println(slice)
filename := make([]*json.Encoder,nReduce) //创建json.Encoder 切片
var file *os.File;
for k :=0 ; k < nReduce; k++ {
file , _ = os.OpenFile(reduceName(jobName,mapTask,k), os.O_WRONLY|os.O_CREATE,0666)
fmt.Println(reduceName(jobName,mapTask,k))
defer file.Close()
filename[k] = json.NewEncoder(file)
}
var n int
for _,kv := range slice{ //根据ihash映射到不同文件里,实现分割
n = ihash(kv.Key)%nReduce
err:=filename[n].Encode(kv)
if err!= nil{
fmt.Println("eeee")
}
}
}
common_reduce 文件
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTaskNumber int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
//
// You will need to write this function.
//
// You'll need to read one intermediate file from each map task;
// reduceName(jobName, m, reduceTaskNumber) yields the file
// name from map task m.
//
// Your doMap() encoded the key/value pairs in the intermediate
// files, so you will need to decode them. If you used JSON, you can
// read and decode by creating a decoder and repeatedly calling
// .Decode(&kv) on it until it returns an error.
// 解码
// You may find the first example in the golang sort package
// documentation useful.
// 排序
// reduceF() is the application's reduce function. You should
// call it once per distinct key, with a slice of all the values
// for that keys. reduceF() returns the reduced value for that key.
// 对每个key调用reduceF()
// You should write the reduce output as JSON encoded KeyValue
// objects to the file named outFile. We require you to use JSON
// because that is what the merger than combines the output
// from all the reduce tasks expects. There is nothing special about
// JSON -- it is just the marshalling format we chose to use. Your
// output code will look something like this:
//
// enc := json.NewEncoder(file)
// for key := ... {
// enc.Encode(KeyValue{key, reduceF(...)})
// }
// file.Close()
//
// Read all mrtmp.xxx-m-reduceTaskNumber and write to outFile
outputFile,err := os.OpenFile(outFile,os.O_WRONLY|os.O_CREATE,0666) //读入中间文件
defer outputFile.Close()
if err != nil {
fmt.Println("err")
return
}
res :=make(map[string] []string)
for i := 0;i<nMap;i++{
inputFile,err := os.Open(reduceName(jobName,i,reduceTaskNumber))
defer inputFile.Close()
if err != nil{
fmt.Println("error")
return
}
dec := json.NewDecoder(inputFile)
for{
var kv KeyValue
err := dec.Decode(&kv) //读取文件中kv值
if err!=nil {
break
}
res[kv.Key] = append(res[kv.Key],kv.Value) //向切片中追加数据 //相同key的kv合并,res结构:map[string] []string
}
}
keys := make([]string,0)
for k,_ :=range res{
keys = append(keys,k)
}
sort.Strings(keys)
enc := json.NewEncoder(outputFile)
for _,key := range keys{
enc.Encode(KeyValue{key,reduceF(key,res[key])}) //对key的次数进行计数
}
//file , _ := ioutil.ReadFile(outFile)
//fmt.Println(string(file))
}
Part2 Single-worker word count
单词计数,这次需要对mapF和reduceF函数进行修改。FieldsFunc就是对字符串根据非字母的字符进行分割,再转化为kv格式放入到切片中。然后就是一些pkg的使用,strings,unicode,strconv等。
func mapF(filename string, contents string) []mapreduce.KeyValue {
// Your code here (Part II).
f := func(c rune) bool {
return !unicode.IsLetter(c)
}
slice := make([]mapreduce.KeyValue,0)
res := strings.FieldsFunc(contents,f)
for _,str := range res{ //
slice = append(slice,mapreduce.KeyValue{str,"1"})
}
return slice
}
func reduceF(key string, values []string) string {
// Your code here (Part II).
count := 0
for _,val := range values{
s,_ := strconv.Atoi(val)
count += s
}
return strconv.Itoa(count)
}
Part3 Distributing MapReduce tasks
这次利用多线程来模拟分布式系统中每个计算机,每个线程(worker)被分配map或者reduce 任务。这里注意schedule函数需要等待所有线程完成才能结束,其次任务调度问题。
- 线程问题,使用sync中的WaitGroup变量实现,用于收集正在运行线程,当有线程没运行结束时,wg.Wait()处于阻塞状态,线程结束时,defer wg.Done(),开启线程时,wg.Add(1)。
- 其次,构造任务结构体,利用call函数将任务发送给worker,worker地址存放在通道中。
package mapreduce
import(
"fmt"
"sync"
)
//
// schedule() starts and waits for all tasks in the given phase (mapPhase
// or reducePhase). the mapFiles argument holds the names of the files that
// are the inputs to the map phase, one per map task. nReduce is the
// number of reduce tasks. the registerChan argument yields a stream
// of registered workers; each item is the worker's RPC address,
// suitable for passing to call(). registerChan will yield all
// existing registered workers (if any) and new ones as they register.
//
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {
var ntasks int
var n_other int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
// All ntasks tasks have to be scheduled on workers. Once all tasks
// have completed successfully, schedule() should return.
//
// Your code here (Part III, Part IV).
//
//构造任务
var wg sync.WaitGroup
for i:= 0;i<ntasks;i++{
var taskArgs DoTaskArgs
taskArgs.JobName = jobName
taskArgs.Phase = phase
taskArgs.NumOtherPhase = n_other
taskArgs.TaskNumber = i
if (phase == mapPhase) {
taskArgs.File = mapFiles[i]
}
wg.Add(1)
go func(taskArgs DoTaskArgs){
worker_address := <- registerChan
defer wg.Done()//当函数运行结束,减去一个进程数
ok := call(worker_address,"Worker.DoTask",taskArgs,nil)
if ok {
go func(){
registerChan <- worker_address
}()
}
}(taskArgs)
}
wg.Wait() //当还有进程没有结束,堵塞状态
fmt.Printf("Schedule: %v done\n", phase)
}
Part4 Handling worker failures
当有worker出问题时(未及时返回计算结果),这时就处于超时状态,需要设定最大延迟时间,判定是否worker超时,超时的话任务从新分配。这里是线程间通信问题。利用select语句获取线程worker状态以及超时状态。现在要多看下go里面多线程东西
package mapreduce
import(
"fmt"
"sync"
"time"
)
//
// schedule() starts and waits for all tasks in the given phase (mapPhase
// or reducePhase). the mapFiles argument holds the names of the files that
// are the inputs to the map phase, one per map task. nReduce is the
// number of reduce tasks. the registerChan argument yields a stream
// of registered workers; each item is the worker's RPC address,
// suitable for passing to call(). registerChan will yield all
// existing registered workers (if any) and new ones as they register.
//
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {
var ntasks int
var n_other int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
// All ntasks tasks have to be scheduled on workers. Once all tasks
// have completed successfully, schedule() should return.
//
// Your code here (Part III, Part IV).
//
//构造任务
var wg sync.WaitGroup
for i:= 0;i<ntasks;i++{
var taskArgs DoTaskArgs
taskArgs.JobName = jobName
taskArgs.Phase = phase
taskArgs.NumOtherPhase = n_other
taskArgs.TaskNumber = i
if (phase == mapPhase) {
taskArgs.File = mapFiles[i]
}
wg.Add(1)
go func(taskArgs DoTaskArgs,in int){
defer wg.Done()//当函数运行结束,减去一个进程数
ok := false
for;ok==false;{
c1 := make(chan bool)
worker_address := <- registerChan
go func(){
ok = call(worker_address,"Worker.DoTask",taskArgs,nil)
c1 <- true
}()
select{
case <-c1:{
if ok {
go func(){
registerChan <- worker_address
fmt.Println(in)
}()
}
}
case <-time.After(time.Millisecond*3000):{
registerChan <- worker_address
return
}
}
}
}(taskArgs,i)
}
wg.Wait() //当还有进程没有结束,堵塞状态
fmt.Printf("Schedule: %v done\n", phase)
}
Part5 Inverted index generation
最后一个实验,前面的单词计数中key为单词,value为 数量,现在改为key为单词,value为单词数量以及所在的文件,需要在mapF中修改kv的值,reduceF中,处理多个value 时候不再是求和,而是求和加去重。
package main
import "fmt"
import "mapreduce"
import (
"os"
"unicode"
"strings"
"strconv"
"sort"
)
// The mapping function is called once for each piece of the input.
// In this framework, the key is the name of the file that is being processed,
// and the value is the file's contents. The return value should be a slice of
// key/value pairs, each represented by a mapreduce.KeyValue.
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// Your code here (Part V).
f := func(c rune) bool {
return !unicode.IsLetter(c)
}
slice := make([]mapreduce.KeyValue,0)
res1 := strings.FieldsFunc(value,f)
for _,str := range res1{ //
slice = append(slice,mapreduce.KeyValue{str,document})
}
return slice
}
// The reduce function is called once for each key generated by Map, with a
// list of that key's string value (merged across all inputs). The return value
// should be a single output value for that key.
func RemoveDuplicatesAndEmpty(a []string) (ret []string){
a_len := len(a)
for i:=0; i < a_len; i++{
if (i > 0 && a[i-1] == a[i]) || len(a[i])==0{
continue;
}
ret = append(ret, a[i])
}
return ret
}
func reduceF(key string, values []string) string {
// Your code here (Part V).
var document_name string
sort.Strings(values)
ret := RemoveDuplicatesAndEmpty(values)
for _,val := range ret{
document_name += val
document_name += ","
}
document_name = strings.TrimRight(document_name,",")
content := strconv.Itoa(len(ret))+" "
content += document_name
return content
}
// Can be run in 3 ways:
// 1) Sequential (e.g., go run wc.go master sequential x1.txt .. xN.txt)
// 2) Master (e.g., go run wc.go master localhost:7777 x1.txt .. xN.txt)
// 3) Worker (e.g., go run wc.go worker localhost:7777 localhost:7778 &)
func main() {
if len(os.Args) < 4 {
fmt.Printf("%s: see usage comments in file\n", os.Args[0])
} else if os.Args[1] == "master" {
var mr *mapreduce.Master
if os.Args[2] == "sequential" {
mr = mapreduce.Sequential("iiseq", os.Args[3:], 3, mapF, reduceF)
} else {
mr = mapreduce.Distributed("iiseq", os.Args[3:], 3, os.Args[2])
}
mr.Wait()
} else {
mapreduce.RunWorker(os.Args[2], os.Args[3], mapF, reduceF, 100, nil)
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号