【论文阅读】综述:深度学习库中Fuzzing技术的调研
! https://zhuanlan.zhihu.com/p/704012821
论文基本信息
标题:Survey on Fuzzing Techniques in Deep Learning Libraries
会议:International Conference on Data Science in Cyberspace
时间:2023-8-18
摘要
为具有深度学习( DL )能力的行业赋权的不可逆转的趋势正在引发新的安全挑战。如果利用底层DL库( e.g. Tensorflow、PyTorch)的漏洞,基于DL的系统将容易受到严重的攻击。为了弥合安全需求和部署紧迫性之间的差距,对DL库进行测试至关重要。本文对模糊测试技术在深度学习( Deep Learning,DL )库中的应用进行了全面的综述。它阐述了这些技术的演变,讨论了各种方法,包括CARDLE、Audee、LEMON、Muffin、DocTer、FreeFuzz、DeepREL、IvySyn和最近的TitanFuzz。虽然这些方法显著地提高了DL库的可靠性,但仍然存在一些挑战。最值得注意的是,需要更多样化的API序列和改进对链式API序列的处理,这通常会导致错误。我们还讨论了大型语言模型在为模糊测试DL库生成输入程序方面的潜力,同时指出需要进一步研究以充分探索它们的可推广性和有效性。文章最后强调了推进Fuzzing技术以增强DL库鲁棒性的重要性,这是推动人工智能和深度学习下一波进展的关键因素。
当前研究进度
模糊测试技术
在工业界,超过80 %的领先服务设备提供商,包括微软[ 21 ]和谷歌[ 45 ],已经采用或准备采用模糊测试技术对自己的产品进行质量和安全检查。凭借模糊测试技术强大的技术优势,该技术已经成为安全公司和相关研究人员用于漏洞发现的主要方法之一
深度学习库赋能
深度学习系统的构建涉及几个组成部分,包括数据集、学习程序和深度学习库。
一个系统越复杂,就越有可能存在潜在的安全隐患。
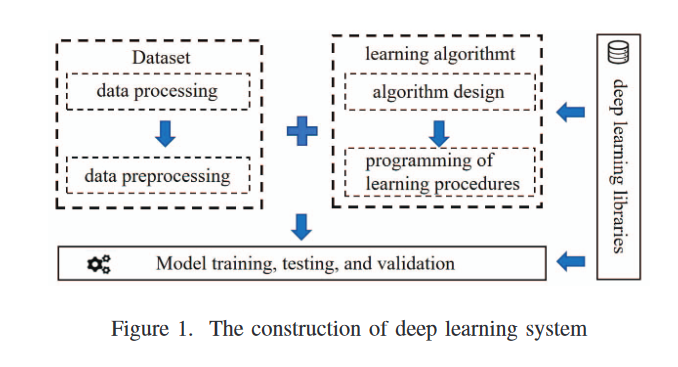
掌握深度学习库中缺陷的特征是质量保证任务的必要前提,这种理解有助于开发缺陷检测和调试过程的有效方法。2018年,Xiao等[ 53 ]和Zhang等[ 57 ]深入研究了Caffe [ 27 ]、Tensorflow和Torch三个深度学习库,揭示了流行的深度学习库的依赖关系复杂性,并证明了这些框架中存在多个漏洞。
CRADLE的限制
a )依赖现有的模型来触发库缺陷的能力是有限的。公开的模型通常只关注流行的任务,并且只调用库代码的有限部分,这往往会得到很好的测试。
b )由于来自真实缺陷的不一致程度可能与不确定影响的不一致程度相似
FreeFuzz‘2022
在2022年,Wei等人[ 51 ]提出了FreeFuzz,这是第一个通过挖掘实际模型和API执行来模糊DL库的方法。FreeFuzz在运行所有收集到的代码/模型的同时,实时记录每次调用API的所有输入参数的动态信息。
动态信息包括论元的类型、值以及张量的形状。然后,跟踪的信息可以形成每个API的值空间,以及一个参数值空间,其中的值可以在测试期间跨相似API的参数共享。最后,FreeFuzz利用追踪到的信息,基于不同的策略(即类型变异、随机值变异和数据库值变异)进行突变型模糊测试,在不同的后端使用差分测试和蜕变测试来检测bug。
FreeFuzz缺点
FreeFuzz目前只专注于测试单个API的正确性,仍然可能会漏掉只能通过调用一系列API才能触发的bug。
DeepREL'22 from FreeFuzz
2022年,Deng等人[ 17 ]为了测试关系API以进一步克服FreeFuzz的局限性,在FreeFuzz的基础上构建DeepREL来自动推断关系API,并利用它们来模糊DL库。DeepREL首先根据API的语法和语义信息自动推断所有可能的候选匹配API对。然后,DeepREL为那些潜在的关系型API合成具体的测试程序。
然后,DeepREL利用一组具有代表性的有效输入(在正常的API执行过程中自动跟踪)来检查推断的API关系是否成立。最后,DeepREL使用经过验证的API对,并利用突变型模糊测试来生成一组多样性和广泛性的测试输入,以检测关系API之间的潜在不一致性。
IvySyn’22
2022年,赫里斯图等人[ 15 ]提出了IvySyn,IvySyn首先识别DL内核代码实现,并添加fuzz hooks,以便执行具有类型感知突变的突变型fuzz。其次,给定一组崩溃内核,它通过高级API合成传播冒犯输入的高级代码片段,从而崩溃原生内核。这样的代码片段作为漏洞的证明,可以帮助开发人员复制、分析并最终修复相应的bug
IvySyn在模糊测试DL框架中与之前工作的主要区别在于设计和实现了一种自底向上的双重方法。IvySyn有三个关键的好处:
a )它是完全自动化的,不需要人工干预,例如手动构建模糊测试驱动或添加领域专家注释;
b )它直接挂钩于强类型的原生API,并且可以执行类型感知的变异,从而有针对性地测试DL框架API;
c )它利用固有的DL框架映射和低级崩溃输入来无缝地合成涉及各自高级API的代码片段。
本文主要内容
当前针对DL库的测试主要分为API和model级别的深度学习库模糊测试。LLMs是在数十亿代码片段上训练的巨型模型,可以自回归地生成类人代码片段。
现代LLMs还可以在其训练语料中包含调用DL库API的大量代码片段,从而可以隐式地学习语言语法/语义和复杂的DL API约束,以生成有效的DL程序。更具体地说,使用生成式和填充式LLMs (例如Codex /加密)来生成和变异有效的/多样的输入DL程序进行模糊测试。
titanfuzz
TitanFuzz首先使用生成式LLM生成用于模糊测试的高质量种子程序列表。这是通过向模型提供一个逐步提示来生成直接使用目标API的代码片段来完成的。对于生成的种子,进一步应用进化fuzzing算法迭代生成新的代码片段。在每次迭代中,通过从种子库中选择适应度得分高的种子程序开始。
使用不同的变异算子,用掩蔽令牌替换所选种子的部分,以产生掩蔽输入。变异算子的选择使用多臂赌博机算法,目的是最大化产生的有效和唯一变异的数量。利用掩码输入,利用填充LLMs的能力进行代码填充,生成新的代码替换掩码令牌。对于每个生成的变异体,首先过滤掉任何执行失败,并使用适应度函数对每个变异体进行评分。
然后将所有生成的变异体放入种子库中,并且对于未来的变异轮次,优先选择得分较高的种子,使得我们能够生成更加多样化的高质量代码片段集合用于模糊测试。最后,在不同的后端( CPU和GPU)上使用差分测试oracle执行所有生成的程序,以识别潜在的bug。
针对DL库fuzz存在的挑战
缺乏多样化的API序列。
API级别的模糊测试专注于单独的深度学习库API模糊处理。它们旨在使用简单的修改规则为特定的API生成大量不同的输入。然而,这些输入通常由奇异代码行形成(至多涉及一个库输入创建API,例如,具有一定数据类型和形状的随机张量初始化),不能暴露由链式API序列引起的bug。虽然模型级模糊测试技术具有测试API序列的潜力,但其变异规则往往受到严格的约束。
例如,LEMON中的层添加规则不能适用于具有不同输入和输出形状的层,而Muffin则需要手动标注所考虑的DL API的输入/输出限制,并采用额外的整形操作来确保有效的连接。
模型级别的模糊测试只能覆盖有限数量模式中的一组受限API,从而无法捕获可能导致bug的一系列不同API序列
结论
模糊深度学习库领域是一个新兴领域,对于增强这些关键计算工具的鲁棒性和可靠性具有重要潜力。当前的技术现状展示了各种创新方法,包括API级别和模型级别的模糊测试技术。然而,尽管取得了重大进展,一些挑战依然存在。需要有效地处理链式API的序列,这是bug的常见来源,这也是目前模型和API级别模糊测试的一个局限性。此外,模糊测试对种类繁多的深度学习库的适用性往往受到特定变异规则施加的约束或需要人工标注的限制。
- END -
::: block-2
一个只记录最真实学习网络安全历程的小木屋,最新文章会在公众号更新,欢迎各位师傅关注!
公众号名称:网安小木屋

博客园主页:
博客园-我记得https://www.cnblogs.com/Zyecho/
:::

 浙公网安备 33010602011771号
浙公网安备 33010602011771号