
爬取百度热搜榜及数据分析与可视化处理
一.主题式网络爬虫设计方案
1.主题式 网络爬虫名称:爬取百度热搜排行榜及数据分析与可视化处理
2.主题式网络爬虫爬取的内容:爬取百度热搜排名,标题,热度值
3.方案设计:访问分析百度热搜网页,得到网页源代码,写出查找所需标签的代码,对数据进行相应的分析。提取标签保存到csv文件中,读取文件进行数据清洗和数据可视化,绘制图形进行数据分析。接下来分析排行和热度的拟合方程并绘制拟合曲线。
技术难点:爬取信息时对标签的寻找,数据可视化处理时绘制图形不够熟练,绘制图形时运行一直出错,回归方程不太理解。
二.页面结构特征分析
1.找对应的标签,通过观察可以发现在tbody中,在tr中找到对应标签,即排名 在td class=''first'中,标题在第二个td class = 'keyword'中,热度在最后一个td class = 'last'中。
2.页面解析


三.1.获取html网页
import requests
import re
import pandas as pd
#请求网页
headers = { 'User-Agent': '5498'}
response = requests.get('https://tophub.today/n/Jb0vmloB1G',headers=headers)
html=response.text
#print(html)
#解析网页与抓取信息
urls = re.findall('<a href=.*? target="_blank" .*?>(.*?)</a>',html)[3:13]
redu = re.findall('<td>(.*?)</td>',html)[0:10]
a = []#创建空列表
for i in range(10):
a.append([i+1,urls[i],redu[i][:-1]])
#完成创建
#使用pandans保存数据
from pandas.core.frame import DataFrame
dict = pd.DataFrame(a,columns = ['排名','标题','热度(单位:万)'])
data = pd.DataFrame(dict)
print(data)
#生成CSV文件
filename="百度热搜榜.csv"
data.to_csv(filename,index=False)

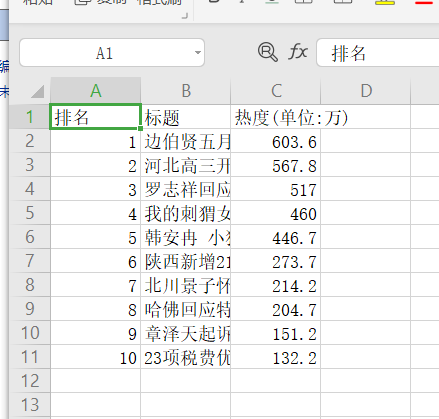
2.数据清洗
#读取csv文件
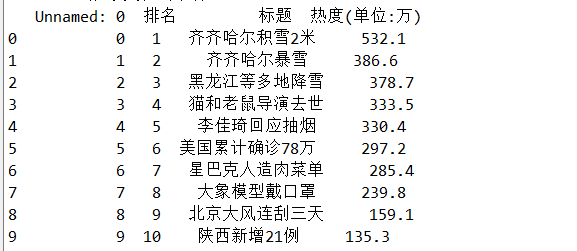
df=pd.DataFrame(pd.read_csv('redian.csv'))
print(df)
#删除无效列与行
#df.drop('标题', axis=1, inplace = True)
#df.head()

#重复值处理
print(df.duplicated())

#检查是否有空值
print(df['热度'].isnull().value_counts())

#异常值处理
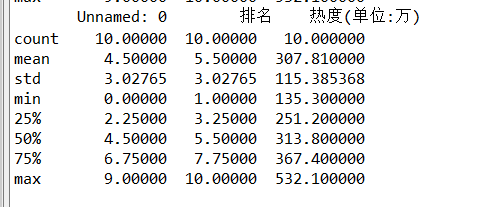
print(df.describe())
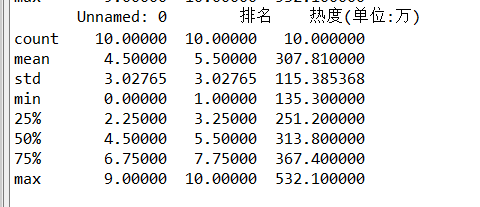
# 将数据统计信息打印出来
print(df.describe())
3.数据分析与可视化
(1) from sklearn.linear_model import LinearRegression
X = df.drop("标题",axis=1)
predict_model = LinearRegression()
predict_model.fit(X,df['热度'])
print("回归系数为:",predict_model.coef_)
#绘制排名与热度的回归图
import seaborn as sns
sns.regplot(df.排名,df.热度)
(2)#绘制图形
#绘制条形图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Arial Unicode Ms']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False#用来正确显示负号
data=np.array([532.1,386.6,378.7,333.5,330.4,297.2,285.4,239.8,159.1,135.3])
index=['1','2','3','4','5','6','7','8','9','10']
s = pd.Series(data,index)
s.name='百度热搜条形图'
s.plot(kind='bar',title='百度热搜条形图')
plt.show()

#绘制散点图
def scatter():
plt.scatter(df.排名, df.热度, color='green', s=10, marker="o")
plt.xlabel("排名")
plt.ylabel("热度")
plt.title("排名与热度散点图")
plt.show()
scatter()
#绘制盒图
def box_diagram():
plt.title('绘制排名与热度-箱体图')
sns.boxplot(x='排名',y='热度', data=df)
box_diagram()
#绘制折线图
def line_diagram():
x = df['排名']
y = df['热度']
plt.xlabel('排名')
plt.ylabel('热度')
plt.plot(x,y)
plt.scatter(x,y)
plt.title("排名与热度折线图")
plt.show()
line_diagram()
(3)#绘制分布图
sns.jointplot(x="排名",y='热度',data = df)
sns.jointplot(x="排名",y='热度',data = df, kind='reg')
sns.jointplot(x="排名",y='热度',data = df, kind='hex')
sns.jointplot(x="排名",y='热度',data = df, kind='kde', color='r')
sns.kdeplot(df['排名'], df['热度'])
(4)#选择排名和热度两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线
colnames=[" ","排名","标题","热度"]
df = pd.read_csv('百度热搜榜.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.热度
Z = df.标题
def A():
plt.scatter(X,Y,color="red",linewidth=2)
plt.title("RM scatter",color="red")
plt.grid()
plt.show()
def B():
plt.scatter(X,Y,color="green",linewidth=2)
plt.title("redu",color="red")
plt.grid()
plt.show()
def func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error(p,x,y):
return func(p,x)-y
def main():
plt.figure(figsize=(10,6))
p0=[0,0,0]
Para = leastsq(error,p0,args=(X,Y))
a,b,c=Para[0]
print("a=",a,"b=",b,"c=",c)
plt.scatter(X,Y,color="red",linewidth=2)
x=np.linspace(0,10,10)
y=a*x*x+b*x+c
plt.plot(x,y,color="red",linewidth=2,)
plt.title("热度值分布")
plt.grid()
plt.show()
print(A())
print(B())
print(main())
四.完整代码
import requests import re import pandas as pd #请求网页 headers = { 'User-Agent': '5498'} response = requests.get('https://tophub.today/n/Jb0vmloB1G',headers=headers) html=response.text #print(html) #解析网页与抓取信息 urls = re.findall('<a href=.*? target="_blank" .*?>(.*?)</a>',html)[3:13] redu = re.findall('<td>(.*?)</td>',html)[0:10] a = []#创建空列表 for i in range(10): a.append([i+1,urls[i],redu[i][:-1]]) #完成创建 #使用pandans保存数据 from pandas.core.frame import DataFrame dict = pd.DataFrame(a,columns = ['排名','标题','热度(单位:万)']) data = pd.DataFrame(dict) print(data) #生成CSV文件 filename="百度热搜榜.csv" data.to_csv(filename,index=False)
#删除无效列与行
#df.drop('标题', axis=1, inplace = True)
#df.head()
#重复值处理
print(df.duplicated())
#检查是否有空值
print(df['热度'].isnull().value_counts())
#异常值处理
print(df.describe())
# 将数据统计信息打印出来
print(df.describe())
(1) from sklearn.linear_model import LinearRegression
X = df.drop("标题",axis=1)
predict_model = LinearRegression()
predict_model.fit(X,df['热度'])
print("回归系数为:",predict_model.coef_)
#绘制排名与热度的回归图
import seaborn as sns
sns.regplot(df.排名,df.热度)
(2)#绘制图形
#绘制条形图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Arial Unicode Ms']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False#用来正确显示负号
data=np.array([532.1,386.6,378.7,333.5,330.4,297.2,285.4,239.8,159.1,135.3])
index=['1','2','3','4','5','6','7','8','9','10']
s = pd.Series(data,index)
s.name='百度热搜条形图'
s.plot(kind='bar',title='百度热搜条形图')
plt.show()
#绘制散点图
def scatter():
plt.scatter(df.排名, df.热度, color='green', s=10, marker="o")
plt.xlabel("排名")
plt.ylabel("热度")
plt.title("排名与热度散点图")
plt.show()
scatter()
#绘制盒图
def box_diagram():
plt.title('绘制排名与热度-箱体图')
sns.boxplot(x='排名',y='热度', data=df)
box_diagram()
#绘制折线图
def line_diagram():
x = df['排名']
y = df['热度']
plt.xlabel('排名')
plt.ylabel('热度')
plt.plot(x,y)
plt.scatter(x,y)
plt.title("排名与热度折线图")
plt.show()
line_diagram()
#绘制分布图
sns.jointplot(x="排名",y='热度',data = df)
sns.jointplot(x="排名",y='热度',data = df, kind='reg')
sns.jointplot(x="排名",y='热度',data = df, kind='hex')
sns.jointplot(x="排名",y='热度',data = df, kind='kde', color='r')
sns.kdeplot(df['排名'], df['热度'])
#选择排名和热度两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线
colnames=[" ","排名","标题","热度"]
df = pd.read_excel('rank.xlsx',skiprows=1,names=colnames)
X = df.排名
Y = df.热度
Z = df.标题
def A():
plt.scatter(X,Y,color="blue",linewidth=2)
plt.title("RM scatter",color="blue")
plt.grid()
plt.show()
def B():
plt.scatter(X,Y,color="green",linewidth=2)
plt.title("redu",color="blue")
plt.grid()
plt.show()
def func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error(p,x,y):
return func(p,x)-y
def main():
plt.figure(figsize=(10,6))
p0=[0,0,0]
Para = leastsq(error,p0,args=(X,Y))
a,b,c=Para[0]
print("a=",a,"b=",b,"c=",c)
plt.scatter(X,Y,color="blue",linewidth=2)
x=np.linspace(0,10,10)
y=a*x*x+b*x+c
plt.plot(x,y,color="blue",linewidth=2,)
plt.title("热度值分布")
plt.grid()
plt.show()
print(A())
print(B())
print(main())
五.总结
1.经过数据的分析和可视化的回归曲线可以看出热度和排名呈正相关,热度会随排名的降低呈现下降,图表可以更为直观的表现出排名与热度的关系以及它们的变化范围与程度。
2.小结:在这次的程序设计中我遇到了许多困难,首先在爬取信息时对标签的寻找,无法从标签中找到有效信息,在对数据进行清理时不能熟练的掌握各个信息库,很多方法不会使用,经常借助百度等工具,不会的问题也有求助同学。对代码的表达上不够流畅,速度慢,准确度低,也认识到了自身的不足,也能够加深对Python这门课程的理解。也因为经常性的代码出错,导致我以后能更加认真的检查,也加深了对语法函数的理解,对以后的学习提高更好的能力,掌握更深的知识。

