
clickHouse 基本概念与用法
官方文档链接 : https://clickhouse.tech/docs/en/
https://clickhouse.tech/docs/zh/engines/table-engines/mergetree-family/versionedcollapsingmergetree/
1. clickhouse简介
1.1 概念
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),是一个完全的列式数据库管理软件,支持线性扩展,简单方便,高可靠性,容错。
全称是Click Stream,Data WareHouse。ClickHouse非常适用于商业智能领域,除此之外,它也能够被广泛应用于广告流量、Web、App流量、电信、金融、电子商务、信息安全、网络游戏、物联网等众多其他领域。
相对于传统的关系型数据库mysql,Clickhouse 在处理大数据量的时候,在查询检索数据量上亿条时,其查询性能有非常强的优势,在数据量比较小的时候,优势不明显。
1.2 优点
-
灵活的MPP架构,支持线性扩展,简单方便,高可靠
-
多服务器分布式处理数据,完备的DBMS系统
-
底层数据列式存储,支持压缩,优化数据存储,优化索引数据
-
容错率高,跑分快。比 Vertica 快 5 倍,比Hive 快 279倍,比Mysql 快800 倍,其可处理的数据级别可达到 10 亿级别
-
功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署,海量数据存储,分布式运算,快速闪电的性能,实时数据分析,出色的函数支持
1.3 缺点
-
不支持事务,不支持真正的删除/更新
-
单节点不支持高并发,一台机器官方建议qps为100 ,但可以通过修改配置文件增加连接数
-
不支持二级索引
-
虽然支持多表join查询,但不擅长多表join查询 。 因此在创建表结构的时候,优先考虑创建一张较大较宽的表,将所有的数据放在一张表中
-
元数据管理需要人为干预
-
尽量做到1000条以上的批量数据写入,避免逐行的insert 或者小批量的insert ,update ,delete 操作,因为写入一条记录和1000条记录所需要的资源和时间相差无几。
1.4. 应用场景
-
查询业务远远超过增删改的业务。
-
要求实时返回查询结果
-
数据需要以大批次(大于1000行)更新,而不是单行更新,或者根本没有更新操作
-
读取数据时,会从数据库中提取出大量的行,但只用到一小部分
-
表很宽,即表中含有大量的字段,列。每次查询中只会查询一个大宽表,除了一个大宽表,其余都是小表
-
列的值是比较小的数值和短字符串,而不是较长的文本
-
查询频率相对较低,通常每台服务器每秒查询数百次或更少
-
对于简单查询,允许大于50ms的延迟
-
在处理单个查询时需要提高吞吐量,每台服务器每秒高达数十亿行
-
不需要事务
-
数据一致性要求较低( 原子性 持久性 一致性 隔离性 )
-
查询结果显著小于数据源,即数据有过滤或者聚合,但查询返回的结果不超过单个服务器内存的大小
2. 核心概念
2.1 数据分片
数据分片 是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现,Clickhouse支持分片而分片则依赖集群,每个集群由1到多个分片组成,每个分片对应了Clickhouse的一个服务节点。分片的数量上限取决于节点数量,一个分片只能对应1个服务节点。Clickhouse并不向其他分布式系统那样,拥有高度自动化的分片功能。Clickhouse的提供了本地表和分布式表的概念,一张本地表等同于一份数据的分片,而分布式表本身并不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询,这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据并不需要多个分片,所以使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长,数据量增大的时候,再通过新增数据分片的方式分流数据,并通过分布式表实现分布式查询。
2.2 列式存储
列式存储是相对于传统关系型数据库的行式存储来说的。简单来说两者的区别就是如何组织表
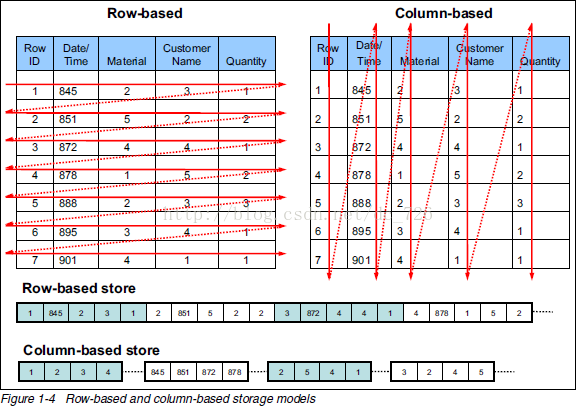
从上图可以很清楚地看到,行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。将不同的行相同的列存储再一起,这些数据具有相同的结构和长度,重复率更高,可以压缩比例更高,降低IO次数,提高查询效率。
-
在实际的应用场景中,往往需要读大量行,但是少数几个列,在行存储模式下,数据按行连续存储,所有列的数据都存储再一个bloCK中,不参与计算的列在IO时也要全部读出,读取操作被严重放大,在列存储模式下,值需要读取参与计算的列即可,极大的降低的IO cast ,加快了查询效率。
-
更高的压缩比意味着更小的data size ,从磁盘中读取相应数据耗时更短。
-
自由的压缩算法选择,不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同,可以针对不同列类型,选择最合适的压缩算法
-
高压缩比,意味着同样大小的内存能够存放更多的数据,系统cache 效果更好
官方显示,通过适用列式存储,在某些分析场景中,能后获得100倍甚至更高的加速效应。
2.3 分区
Clickhouse 支持 PARTITION BY 子句,在建表的时候可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM() 将数据按月进行分区,toMonday() 将数据按照星期进行分区,对Enum 类型的列直接每种取值作为一个分区等,数据以分区的形式统一管理和维护一批数据。
2.4 副本
数据存储副本,在集群模式下可实现高可用,在CK中通过复制集,实现了数据可靠性,也通过多副本的方式,增加了CK查询的并发能力。
一般有2种方式:(1)基于ZooKeeper的表复制方式,(2)基于Cluster的复制方式
由于推荐的数据写入方式为本地表写入,禁止分布式表写入,因此复制表主要考虑ZooKeeper的表复制方案。
3. 数据类型
3.1 数字类型
-
IntX和UIntX
-
Int8— [-128 : 127] -
Int16— [-32768 : 32767] -
Int32— [-2147483648 : 2147483647] -
Int64— [-9223372036854775808 : 9223372036854775807] -
Int128— [-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727] -
UInt8— [0 : 255] -
UInt16— [0 : 65535] -
UInt32— [0 : 4294967295] -
UInt64— [0 : 18446744073709551615]
-
FloatX
-
Float32—float. -
Float64—double.
-
Decimal
Decimal32(S) - ( -1 * 10^(9 - S), 1 * 10^(9 - S) )
Decimal64(S) - ( -1 * 10^(18 - S), 1 * 10^(18 - S) )
Decimal128(S) - ( -1 * 10^(38 - S), 1 * 10^(38 - S) )
Decimal256(S) - ( -1 * 10^(76 - S), 1 * 10^(76 - S) )
-
bool
0 或者 1
3.2 字符串类型
-
String
-
FixedString
-
UUID
3.3 时间类型
-
Date
-
DateTime
-
3.4 枚举
3.5 数组
3.6 Map
CREATE TABLE table_map (a Map(String, UInt64)) ENGINE=Memory;
INSERT INTO table_map VALUES ({'key1':1, 'key2':10}), ({'key1':2,'key2':20}), ({'key1':3,'key2':30});
4. Clickhouse基本操作
4.1 数据库操作
show databases; // 展示当前有的数据库
create database if not exists test1 ;//创建数据库
use test1; // 选择test1数据库
select currentDatabase() ;查看当前使用的数据库
drop database test1; // 删除数据库
创建数据库语法:
CREATE database if not exists “数据库名称”;
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]
示例:CREATE database if not exists test_for_szp ;
默认情况下,ClickHouse使用的是原生的数据库引擎Ordinary(在此数据库下可以使用任意类型的表引擎,在绝大多数情况下都只需使用默认的数据库引擎)。当然也可以使用Lazy引擎和MySQL引擎,比如使用MySQL引擎,可以直接在ClickHouse中操作MySQL对应数据库中的表。假设MySQL中存在一个名为clickhouse的数据库,可以使用下面的方式连接MySQL数据库。
-- --------------------------语法-----------------------------------
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
-- --------------------------示例------------------------------------
CREATE DATABASE mysql_db ENGINE = MySQL('192.168.200.241:3306', 'clickhouse', 'root', '123qwe');
删除数据库
语法:DROP database “数据库名称”;
示例:DROP database test_for_szp;
4.2 数据表操作
ck创建数据表的时候,一定要指定引擎,否则会报错
create table tb_test1(
id int,
name String
)engine=Memory;
CREATE TABLE product_id
(
factory_goods_id UInt32 COMMENT '工厂商品ID',
goods_name String COMMENT '商品名称',
shop_id UInt32 COMMENT '店铺ID',
shop_name String COMMENT '店铺名称',
create_time DateTime COMMENT '创建时间',
update_time DateTime COMMENT '更新时间'
) ENGINE = MergeTree()
PRIMARY KEY factory_goods_id
ORDER BY factory_goods_id
CREATE TABLE wenl1.wenl_tmp_fact_general_report_windspeed (
data_time Date,
avg_of_wind_speed Float32
) ENGINE = MergeTree()
ORDER BY data_time;
删除表
DROP table if exists product_detail;
DROP table if exists product_id;
在集群上部署的Clickhouse ,删除表也应该带集群的名称
DROP TABLE wenl1.wenl_tmp_fact_general_report_substation on CLUSTER elune;
删除数据表的时候会遇到一个问题:
// 删除数据表
DROP TABLE if exists wenl1.wenl_tmp_fact_general_report_substation on CLUSTER elune;
// 重建数据表
CREATE TABLE if not exists wenl1.wenl_tmp_fact_general_report_production on cluster elune(
date_time DATE,
active_power_sum FLOAT(32),
wtg_id String,
site_id String
)
ENGINE =ReplicatedReplacingMergeTree('/clickhouse/wenl1/tables/{layer}-{shard}/wenl_tmp_fact_general_report_production', '{replica}')
order by (date_time)
settings index_granularity = 8192;
会出现以下报错:
SQL 错误 [253]: ClickHouse exception, code: 253, host: 10.65.19.56, port: 8123; Code: 253, e.displayText() = DB::Exception: There was an error on [clickhouse0006.eniot.io:9000]: Code: 253, e.displayText() = DB::Exception: Replica /clickhouse/wenl1/tables/01-01/wenl_tmp_fact_general_report_production/replicas/elune-01-2 already exists. (version 21.4.3.21-edh-3.1.4) (version 21.4.3.21-edh-3.1.4)
在我们删除本地表和分布式表后,立即重建是没有问题的。唯一有问题的就是复制表,因为复制表需要在zookeeper上建立一个路径,存放相关数据。clickhouse默认的库引擎是原子数据库引擎,删除Atomic数据库中的表后,它不会立即删除,而是会在480秒后删除。由下面这个参数控制:
我们可以使用以下办法来解决这个问题:
-
使用普通数据库而不是原子数据库。 create database … Engine=Ordinary.
-
使用uniq ZK路径。{uuid}/clickhouse/tables/{layer}-{shard}-{uuid}/
-
减少database_atomic_delay_before_drop_table_sec = 0 & drop table … sync
4.3 插入数据
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
INSERT into wenl_wtg_production_day
( wtg_id, date_time ,positive_energy_p1 ,positive_energy_point ,positive_energy)
values
('wtg_id1', '2021-01-01 00:00:00' ,1.0 ,1.0 ,1.0 );
INSERT into wenl_wtg_production_day
( wtg_id, date_time ,positive_energy_p1 ,positive_energy_point ,positive_energy)
values
('04m1sTS5', '2021-01-06' ,1.0 ,1.0 ,1.0 ),
('04s4109D', '2021-01-06' ,1.0 ,1.0 ,1.0 ),
('0C04iY2k', '2021-01-06' ,1.0 ,1.0 ,1.0 ),
('0Mx32xyS', '2021-01-06' ,1.0 ,1.0 ,1.0 ),
('0QRgFwFQ', '2021-01-06' ,1.0 ,1.0 ,1.0 ),
('0ZbfFyQR', '2021-01-06' ,1.0 ,1.0 ,1.0 ),
('0bVTxmOo', '2021-01-06' ,1.0 ,1.0 ,1.0 ),
('0rP1oCJY', '2021-01-06' ,1.0 ,1.0 ,1.0 );
INSERT into wenl_dm_fact_daily_report_10m_detail_tmp
(org_id, site_id, wtg_id,data_time, update_time,wind_speed,read_wind_speed,tem_out, active_power,theory_power,production_loss )
values
('org_id4', 'site_id4' ,'wtg_id4', '2021-01-04:00:00:00', '2021-01-04:00:00:00',40.0, 40.0, 40.0, 40.0