张宵 20200917-2-词频统计
此作业的要求参见:[https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206]
一、代码以及版本控制
github地址:https://github.com/ZigHello/learngit.git
coding.net地址:https://e.coding.net/nenuteamwork/spec/nenu_project.git
使用语言:python
二、功能实现及重难点分析
功能1 小文件输入。
实现效果图:

重难点分析:
(1)文件读取
python中有一个文件读取方法:open(filename,mode,buffering,encoding),其中filename为文件全称,mode为文件的读取模式,buffering为寄存区的缓冲大小,encoding为文件的编码方式。同时文章中会存在大小写等问题,在这里统一将读入的文章的字母转换为小写字母,便于之后分词处理。
1 #文件读取 open(filename,mode,buffering,encoding)方法 2 f = open(text, 'r', -1, 'utf-8') 3 # 读取文本内容并将字母全部转换为小写形式 4 after_txt = f.read().lower()
(2)杂项处理
对于英文文章的分词,比较容易处理。一般用空格作为一个词的划分标志,但是也注意到文章中有一些标点符或者换行符或者数字等杂项,这里就需要对这些杂项进行处理。可以用正则表达式或者直接用python中的replace(),我只对英文常见的标点符用空格进行替换,做了一个较简单的杂项处理,这里还存在许多瑕疵,可以进一步优化,暂且先实现功能。替换后的文章,用split()就可以很容易的将文章切割成一个个单词。
1 strl_list = str.replace('\n', ' ').replace('.', ' ').replace(',', ' ').\ 2 replace('!', ' ').replace('\\', ' ').replace('#', ' ').\ 3 replace('[', ' ').replace(']', ' ').replace(':', ' ').\ 4 replace('?', ' ').replace('-', ' ').replace('\'', ' ').\ 5 replace('\"', ' ').replace('(', ' ').replace(')', ' ').\ 6 replace('—', ' ').replace(';', ' ').lower().split()
(3)词频统计
功能要求对词频计数,同时要求在总计数中相同的单词不重复计数。创建一个空字典,字典的好处在于记录了键值对,便于之后取值。将分割的单词列表循环,如果字典中有该单词,则对于单词的value值+1,否则添加入字典并将改单词的value值置1。最后进行排序,python中有几种排序函数,这里区分一下sort()和sorted()。
sort 是应用在 list 上的方法sorted 可以对所有可迭代的对象进行排序操作。list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。由于词频统计用字典存储,字典是一个可迭代对象,所以选择了sorted()函数。
1 # 如果字典里有该单词则加1,否则添加入字典 2 for str in strl_list: 3 if str in count_dict.keys(): 4 count_dict[str] = count_dict[str] + 1 5 else: 6 count_dict[str] = 1 7 # 按照词频从高到低排列 8 count_list = sorted(count_dict.items(), key=lambda x: x[1], reverse=True)
(3)命令行参数
Python 中可以用 sys 的 sys.argv 来获取命令行参数:
- sys.argv 是命令行参数列表。
-
len(sys.argv) 是命令行参数个数。
还提供了getopt模块是专门处理命令行参数的模块,用于获取命令行选项和参数,提供了两种方法,具体使用方法参见:https://www.runoob.com/python3/python3-command-line-arguments.html
1 try: 2 list = read_text(argv[-1]) 3 opts, args = getopt.getopt(argv, "sh", ["ifile", "ofile"]) # 设置命令行参数 4 except getopt.GetoptError: 5 print("test.py -i <inputfile> -o <outputfile>") 6 sys.exit(2) 7 for opt, arg in opts: 8 if opt == "-s": # 命令行参数为-s时执行的操作 9 num = len(list) 10 print('total', num) 11 print('\n') 12 for word in list: 13 print('{:20s}{:>5d}{}'.format(word[0], word[1], '\n')) 14 elif opt == "-h": # 命令行参数为-h时执行的操作 15 print("please input the parameter")
(4)将py文件转换为exe文件
参照上一届同学的博文:https://www.cnblogs.com/hanhao970620/p/11537088.html
功能2 支持命令行输入英文作品的文件名。
实现效果图:

重难点分析:
(1)命令行参数
功能一中的命令行参数有2个,在功能二中的命令行参数只有1个,这里就需要进行分支处理。当len(argv)==2时,进入功能一模块;当len(argv)==1时,进入功能二模块。具体代码请见功能三
1 if len(argv) == 1: 2 #功能一 3 4 else: 5 #功能二
(2)数据量
题目指出文件大小最大为40M,这一点我没有测试,纯文本文件40M是一个相对较大的数据量,没有做压力测试,难以评估程序的健壮性。
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。

重难点分析:
(1)区分输入的参数是文件夹名还是文件名
参考了往届同学的做法,有同学指定了文件夹名,有同学用正则表达式匹配.txt,有同学遍历文件夹。我在这里参照采取了匹配方式,功能二中输入的是文件名.txt,功能三输入的是文件夹名,通过传入参数与正则匹配.txt进行匹配,如果匹配成功,则传入的是文件名,否则是文件夹名。
1 pattern = re.compile('.+\.txt') #匹配.txt结尾的正则表达式 2 folder_name = argv[-1] #argv[-1] 输入参数的最后一个 3 m = re.findall(pattern,folder_name) #寻找匹配项 4 if len(m) != 0: #如果匹配则列表存在元素,为文件名,执行功能二 5 ... 6 else #如果不匹配则列表不存在元素,为文件夹名,执行功能三 7 ...
(2)文件夹的处理
python中的os.chdir(path) 方法用于改变当前工作目录到指定的路径。path -- 要切换到的新路径。这里path直接指定为同目录下的文件夹名。os.listdir(path) 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。path -- 需要列出的目录路径,这里不用设置。
1 os.chdir(folder_name) #切换至folder_name文件夹目录 2 filename_list = os.listdir() #将文件夹下的文件返回
(3)只列出前10个高频单词
功能一、二均把所有词频列出,功能三要求只列前10,所以可以设置标志位,如果flag == 0,实现功能一、功能二,将所有内容列出;如果flag == 1,实现功能三,如果本身词频不足10个,全部输出,如果大于10个,输出前10。
1 def argv_2(argv, flag): #功能二 命令行参数为2 2 pattern = re.compile('.+\.txt') 3 folder_name = argv[-1] 4 m = re.findall(pattern, folder_name) 5 if len(m) != 0: # 功能二,参数以.txt结尾的文件名,直接执行词频操作 6 arry = read_text(argv[-1]) 7 if flag == 0: # 标志位为0,把所有单词都列出来 8 print('total', len(arry), 'words') 9 print('\n') 10 out(arry) 11 else: # 标志位不为0,只列出前十 12 print('total', len(arry), 'words') 13 print('\n') 14 if len(arry) > 10: 15 for i in range(10): 16 print('{:20s}{:>5d}'.format(arry[i][0], arry[i][1])) 17 else: # 如果本身不超过10个单词量,则列出所有单词即可 18 out(arry) 19 else: # 功能三,有多个文件,打开文件夹 20 os.chdir(folder_name) # 文件夹操作 21 filename_list = os.listdir() 22 for file_name in filename_list: 23 print(file_name[:-4] + '\n') 24 file_list = [file_name] 25 argv_2(file_list, 1) # 得到文件名,进行递归操作,标志位置1,说明要取前10 26 print('----\n')
功能4 支持重定向输入

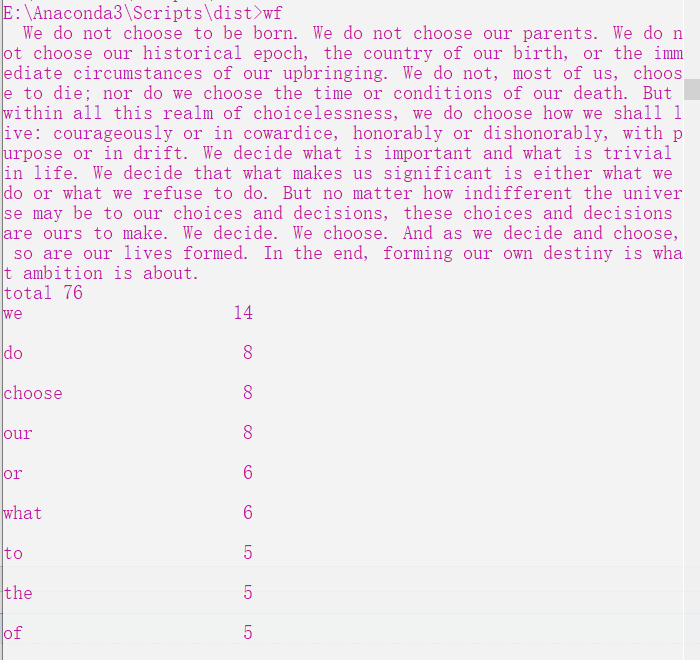
重难点分析:
(1)python中的重定向
在重定向中'<'符号是标准输入,'>'是标准输出,python可以使用input()方法即可捕捉到输入的文件内容。代码如下:
1 redirect_words = input().lower() #获取重定向文本信息并把单词转换为小写
(2)区分功能一和重定向参数
需要先理解功能一和重定向的参数个数,功能一后面直接接文件名: wf -s text.txt 参数个数为3,重定向:wf -s < text.txt 参数个数为2,所以基于此可以进行分支。随着功能点越多,越发发现抽取函数的重要性,按之前的逻辑,输入-判断-输出全在一块判断,并由大量重复代码。
1 if sys.argv[1] == "-s": 2 #功能一 3 if( len(sys.argv) == 3 ): 4 argv_3(argv, 0) 5 else: 6 #重定向获取文件名 7 redirect()
1 def redirect():#功能四 重定向输入 2 redirect_words = input().lower() # 获取重定向文本信息并把单词转换为小写 3 count_list = words_split(redirect_words) # 调用分词逻辑方法 4 print('total', len(count_list)) # 打印结果 5 out(count_list)
(3)获取输入数据
命令行参数只有一个,直接调用input()方法获取输入文本,其他于之前一致。
1 def argv_1(argv, flag): #功能四 命令行输入文本 2 text_contents = input() # 获取输入数据 3 count_list = words_split(text_contents) # 调用分词逻辑方法 4 print('total', len(count_list)) # 打印结果 5 out(count_list)
三、PSP
功能实现及测试PSP
| PSP阶段 | 预计花费时间(min) | 实际花费时间(min) | 时间花费差距原因 |
| 功能一 | 180 | 320 |
1.命令行参数设置,对这里完全不知道,花费了很长时间理解 2.对python的不熟悉,排序sorted(),文件读取open() 3.py文件转exe文件,这里查看了前辈的博客,节省了很多精力 |
| 功能二 | 90 | 120 |
1.未想到通过命令行参数长度来控制 |
| 功能三 | 150 | 300 |
1.区分功能二和功能三,无法判断输入的是文件名还是文件夹名 2.文件夹操作,获取文件夹里的所有文件 3.控制输出词频的两种方式输出前10个词频 |
| 功能四(重定向) | 90 | 70 |
1.python中重定向的方法使用 2.区分功能一和重定向的输入 |
| 功能四(控制台输入) | 90 | 40 | 1.从控制台获取输入数据 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号