
爬取芒果TV的《我是大侦探》节目评论数据,并进行情感分析
爬取芒果TV的《我是大侦探》节目评论数据,并进行情感分析
一,选题的背景
对节目爬取回来的数据进行情感分析,看看广大观众朋友们到底对于明侦的姊妹篇《我是大侦探》是怎么看的,以及对于这个节目里的每个嘉宾的表现是否满意,四期以来评论是否有好转的趋势等。
二,设计方案
1,爬虫名称:爬取芒果TV的《我是大侦探》节目评论数据,并进行情感分析
2,爬虫的内容与数据特征分析
-
数据处理和分析基于pandas,数据可视化基于matplotlib和seaborn
-
情感倾向分析基于snow_nlp、百度AI以及腾讯文智,分词基于jieba
-
Python运行环境为3.6
3,设计方案概述
使用scrapy爬取的数据是储存在MongoDB数据库中的,所以首先需要把数据从数据库中提取出来,转换为pandas DataFrame。提取数据需要用到pymongo包来操作MongoDB数据库
三,页面的结构特征分析
四,爬虫程序设计
1. 从MongoDB中提取数据
使用scrapy爬取的数据是储存在MongoDB数据库中的,所以首先需要把数据从数据库中提取出来,转换为pandas DataFrame。提取数据需要用到pymongo包来操作MongoDB数据库:
- 首先实例化一个MongoClient,host为'127.0.0.1',默认端口是27017,数据库为mongotv
- 我把四期的评论数据分别保存在mongotv数据库下的四个集合里面,分别是mongotv1,mongotv2,mongotv3,mongotv4,需要分别提取到data1, data2, data3, data4这四个pandas DataFrame里面
- 使用.find()方法可以查询到集合里面的每一条数据,通过遍历便可以得到这些数据
- 由于MongoDB中的数据是非结构化的JSON数据,可以使用pandas.io.json中的json_normalize方法,把JSON数据扁平化、规整化成为pandas的DataFrame,这里由于只需要评论数据,所以只提取了“comments”下面的数据
1 import pandas as pd
2 import numpy as np
3 from pymongo import MongoClient
4 from pandas.io.json import json_normalize
5
6 conn = MongoClient(host='127.0.0.1', port=27017) # 实例化MongoClient
7 db = conn.get_database('mongotv3') # 连接到mongotv数据库
8
9 mongotv1 = db.get_collection('mongotv1') # 连接到集合mongotv1
10 mon_data = mongotv1.find() # 查询这个集合下的所有记录
11
12 # 遍历mon_data,获取每一条记录下的’comments‘数据,组装成一个列表
13 # 使用json_normalize把JSON数据扁平化成一个DataFrame,就成功地把第1期节目的评论数据成功地从MongoDB中提取出来并转换为pandas的DataFrame格式了
14 data1 = json_normalize([j['comments'] for j in mon_data], sep='_')
15
16 # 下面接着使用同样的方法提取第2、3、4期节目评论数据
17 data2 = json_normalize([j['comments'] for j in db.get_collection('mongotv2').find()], sep='_')
18 data3 = json_normalize([j['comments'] for j in db.get_collection('mongotv3').find()], sep='_')
19 data4 = json_normalize([j['comments'] for j in db.get_collection('mongotv4').find()], sep='_')
2. 基本的数据处理
我们需要把四期的数据放在一个DataFrame里做分析,所以首先给每期的数据标记上期数(episode),再把四期评论数据一起concat起来,然后把这次分析上用不到的字段去除掉。
2.1 每期评论数据处理
可见,第1、2、3、4期节目分别有9779、4246、3030、2089条评论
1 print(data1.shape, data2.shape, data3.shape, data4.shape)

为每期数据增添新的一列“episode”,用来标记期数,再把四期的数据concat起来保存到data中
1 data1['episode'] = 1
2 data2['episode'] = 2
3 data3['episode'] = 3
4 data4['episode'] = 4
5
6 data = pd.concat([data1, data2, data3, data4])
2.2 数据基本信息
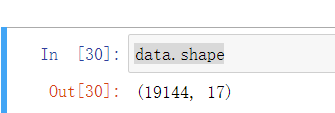
- 发现数据总共有19144条,17列
- “comment_id”字段起到唯一标识每条评论的作用,由于爬取的时候已经基于该字段做了去重,所以并不需要再去重
- “content”就是评论的主要内容,也是我们主要分析的内容
- 所有以“origin_comment”开头的都是有回复的评论相关信息,例子如下,“有明显bug,邓有味不是亲生的怎么和他爷爷长的一样??邓有味那套衣服他爷爷又是怎么得到的??”就是“origin_comment_content”:

- “videoId”是每个视频的ID,其实这个也可以用来标示哪一期,不过我刚刚有了更明显更加具有代表性的“episode”字段,所以这个字段可以不要了
- “user_nickname”是评论者的名字,“up_num”是评论获得的点赞数
1 data.shape
1 data.sample(3)

1 data.info()

2.3 字段选取
- 这里只选取comment_id,content,origin_comment_content,origin_comment_up_num,origin_comment_user,up_num,user_nickname,episode这8个字段进行后续分析
1 data = data[['comment_id', 'content', 'origin_comment_content', 'origin_comment_up_num',
2 'origin_comment_user', 'up_num', 'user_nickname', 'episode']]
1 data.sample(5)
3. 情感倾向获取
情感倾向也就是对包含主观观点信息的文本进行情感极性类别(积极、消极、中性)的判断,例如:
我们需要对爬取下来的每一条评论进行情感倾向分析,获取情感倾向值。该值可以以0-1之间的数字表示,越接近0代表评论越消极,越接近1代表评论越积极,越接近0.5代表评论越偏向于中性。这里,我们需要快速获取情感倾向值,便不涉及到数据打标和建模的过程,目前可以使用的工具有:
- Python的中文文本分析库SnowNLP:它是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,目前实现了中文分词、词性标注、情感分析、文本关键词提取等功能
- 百度AI的情感倾向分析:它是百度AI开放平台的语言处理基础技术产品,提供了API接口以及SDK Python包,可以用来获取情感倾向.
- 腾讯文智的情感分析API:它是腾讯文智自然语言处理的产品,同样提供了API和SDK调用来获取情感倾向,总共可以免费调用5万次,也足够我们的分析了。传送门:http://nlp.qq.com/index.cgi
3种工具的调用方法分别如下:
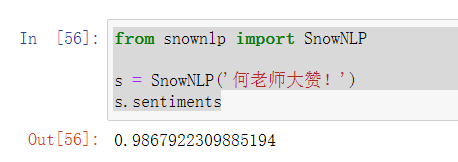
- SnowNLP: 很简单,只要实例化一个SnowNLP类,传入需要分析的文本,再调用sentiments方法便可获取情感倾向值,比如:
1 from snownlp import SnowNLP
2
3 s = SnowNLP('何老师大赞!')
4 s.sentiments
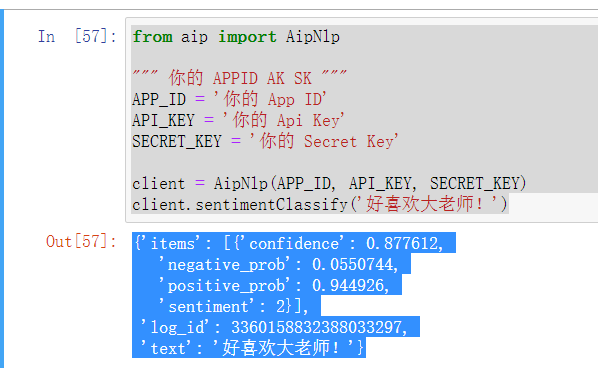
- 百度AI: 先pip install baidu-aip安装SDK,然后注册账号,获取到APP_ID、API_KEY和SECRET_KEY,根据这个实例化一个AipNlp类,然后调用sentimentClassify方法传入文本,便可以返回情感倾向分析的相关内容,比如:
1 from aip import AipNlp
2
3 """ 你的 APPID AK SK """
4 APP_ID = '你的 App ID'
5 API_KEY = '你的 Api Key'
6 SECRET_KEY = '你的 Secret Key'
7
8 client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
9 client.sentimentClassify('好喜欢大老师!')
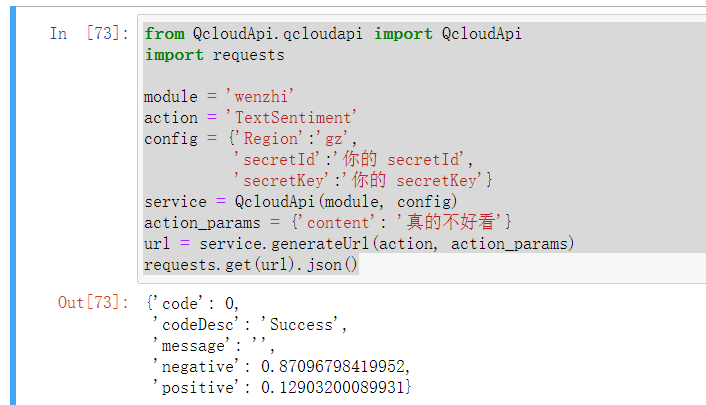
- 腾讯文智: 腾讯文智稍微有些麻烦,而且说明文档组织地不是很好。先pip install qcloudapi-sdk-python安装SDK,然后注册账号,获取secretId和secretKey,还有一串儿的参数配置,如下:
1 from QcloudApi.qcloudapi import QcloudApi
2 import requests
3
4 module = 'wenzhi'
5 action = 'TextSentiment'
6 config = {'Region':'gz',
7 'secretId':'你的 secretId',
8 'secretKey':'你的 secretKey'}
9 service = QcloudApi(module, config)
10 action_params = {'content': '真的不好看'}
11 url = service.generateUrl(action, action_params)
12 requests.get(url).json()
1 同样,返回一个字典,其中“positive_prob”便是我需要的情感倾向值。
2
3 由于评论数据在data['content']里,这里可以定义三个函数,用来分别获取SnowNLP、百度AI、腾讯文智的情感倾向值。然后使用data['content'].apply(func)便可以直接把数据获取到“sent_snownlp”、“sent_baidu”、“sent_tencent”字段里,具体如下:
1 import pandas as pd
2 import requests
3 from snownlp import SnowNLP
4 from aip import AipNlp
5 from QcloudApi.qcloudapi import QcloudApi
6
7
8 # SnowNLP API
9
10
11 def get_sent_snownlp(data):
12 s = SnowNLP(data)
13 return s.sentiments
14
15
16 data['sent_snownlp'] = data['content'].apply(get_sent_snownlp)
17
18 # 百度API
19 APP_ID = '11128642'
20 API_KEY = 'odAzooF9AuFhKTFScWGnleTZ'
21 SECRET_KEY = 'mHWaMrh5EXPhb5tkdKode5uxVemhtf13'
22
23 client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
24
25
26 def get_sent_baidu(data):
27 return_data = client.sentimentClassify(data)
28 items = return_data.get('items')
29 if items:
30 return items[0]['positive_prob']
31
32
33 data['sent_baidu'] = data['content'].apply(get_sent_baidu)
34
35
36 # 腾讯API
37 module = 'wenzhi'
38 action = 'TextSentiment'
39 config = {'Region':'gz',
40 'secretId':'AKID6JQM5c813zkNvNuomifcMxPIA2mLitrs',
41 'secretKey':'GRQGzWs8D5kDUYR8e2KQK3f5TitsfKo6'}
42 service = QcloudApi(module, config)
43
44
45 def get_sent_tc(data):
46
47 action_params = {'content': data}
48 url = service.generateUrl(action, action_params)
49 response = requests.get(url).json()
50 positive = response.get('positive')
51 if positive is not None:
52 return positive
53
54
55 data['sent_tencent'] = data['content'].apply(get_sent_tc)
56
57 data.to_csv('/Users/apple/Desktop/data.csv', index=False)
获取完情感倾向值的数据长这样:
1 data.sample(3)
4. 具体分析
接下来便可以进行具体的分析了。
随机抽取数据发现,snownlp在这个数据集上面的表现并不是很好(可能因为snownlp主要的训练数据是商品评论数据),所以本次分析主要综合一下百度AI和腾讯文智的分值。
1 data[['content', 'sent_snownlp', 'sent_baidu', 'sent_tencent']].sample(5)
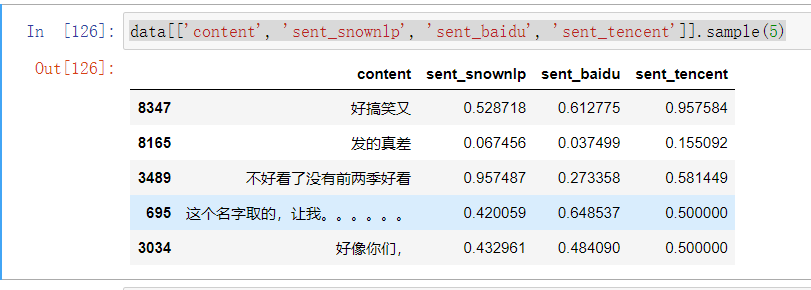
data['sent_average'] = data[['sent_baidu', 'sent_tencent']].mean(axis=1)
对百度AI和腾讯文智的分值求平均,保存到“sent_average”中,后续的分析基于“sent_average”展开。
其实我的问题主要有以下几个:
- 这部综艺评论的情感倾向总体如何?
- 四期以来的情感倾向分布如何,趋势如何?
- 评论区的观众们对于《我是大侦探》中的每个嘉宾评价如何,趋势如何?
- 评论区对于《明星大侦探》的原班嘉宾鬼鬼、撒撒、白敬亭、王鸥等人的呼唤声有多大?
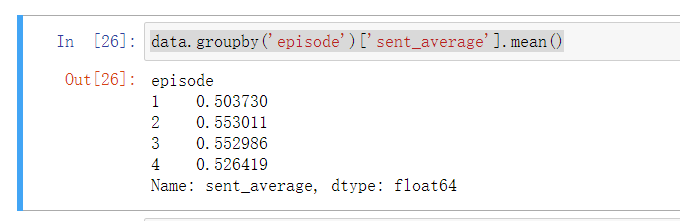
1 data.groupby('episode')['sent_average'].mean()
4.1 这部综艺评论的情感倾向总体如何?
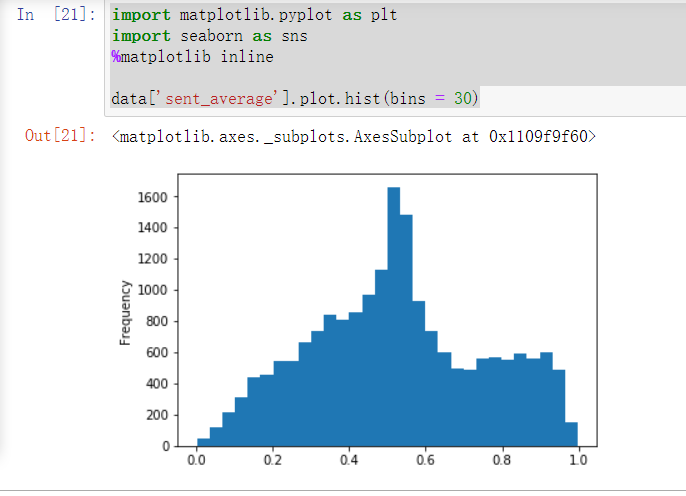
- 情感倾向值的平均分为0.52(0-1分值),查了一下豆瓣的评分,与豆瓣的5.6分(0-10分值)还是挺接近的,与《明星大侦探》的评分相比相差甚远啊(第一季:8.9,第二季:9.0,第三季:9.2)
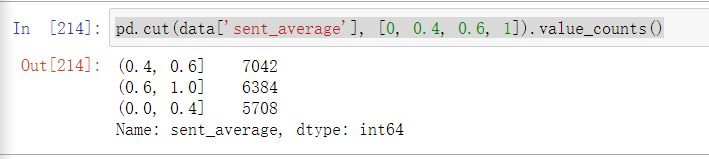
- 由情感倾向值的分布图可以看到,这部综艺的评论可谓是毁誉参半。除了中间峰值的中性评论之外,如果我们以小于0.4为消极评论,大于0.6为积极评论来算的话,那么消极评论条数为5708条,积极评论为6384条,相差无几
- 看来很多老粉对于这部综艺是失望的,对于不同于《明星大侦探》的新嘉宾的表现不甚满意,怀念以前的老嘉宾,也有很多老粉一如既往地支持这个姊妹篇,希望以后越来越好,当然还有新嘉宾的铁粉过来摇旗呐喊
1 data['sent_average'].mean()
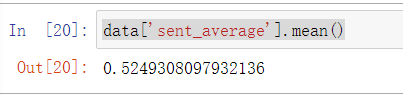
1 import matplotlib.pyplot as plt
2 import seaborn as sns
3 %matplotlib inline
4
5 data['sent_average'].plot.hist(bins = 30)
1 pd.cut(data['sent_average'], [0, 0.4, 0.6, 1]).value_counts()
随机抽取消极和积极倾向的评论,可以看到大家失望和喜欢的点都在哪里
data.loc[data['sent_average'] < 0.2, ['content', 'sent_average']].sample(5)

1 data.loc[data['sent_average'] > 0.8, ['content', 'sent_average']].sample(5)

4.2 四期以来的情感倾向分布如何,趋势如何?
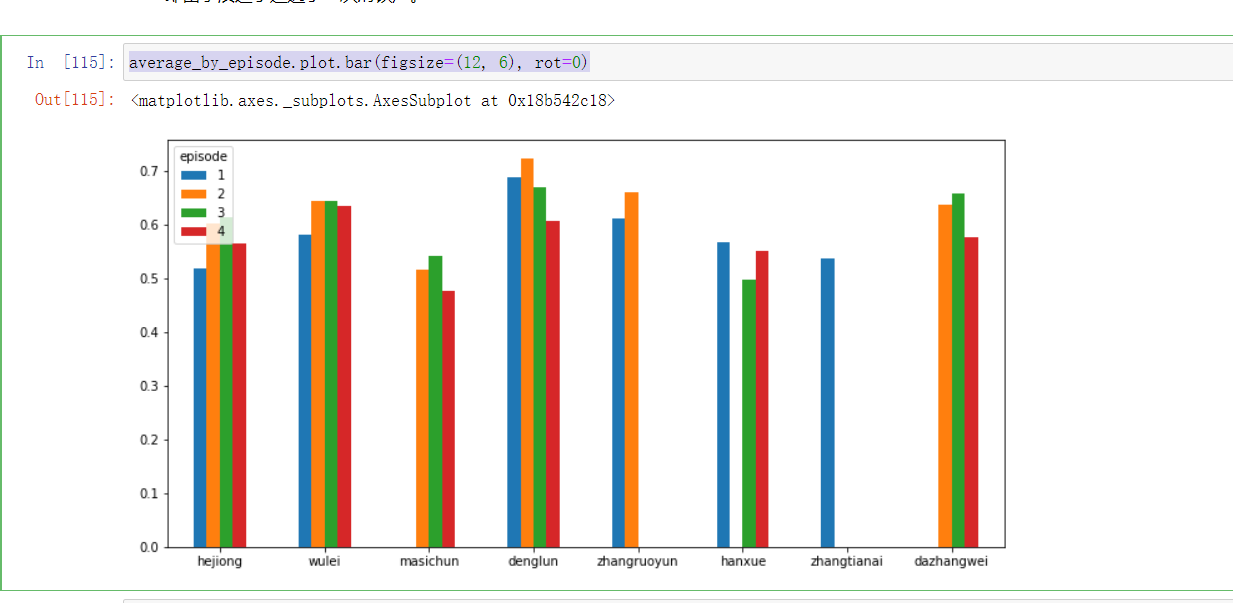
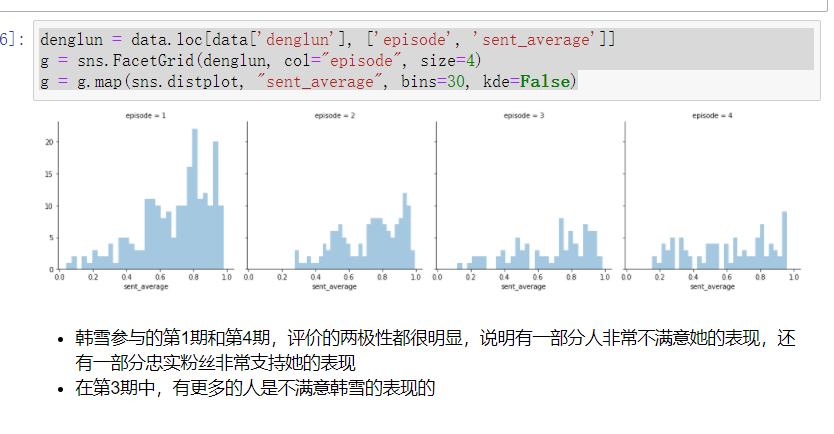
- 可以看到,大家对于第01期的评价是最低的,平均值为0.5,可以算是严格意义上的毁誉参半,这也解释了为什么我当时看到第01期的时候心中有种说不出道不明的感觉
- 后续第02、03期,评价有所回升,看来大家对于这两期的内容认可度有上升,但是第04期又降下去了
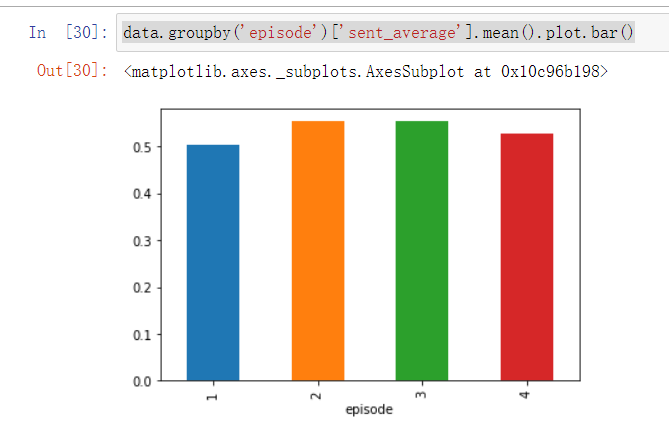
- 由分布图可以明显看出,第01期、04期消极和积极两端都有比较明显的小峰值,而第02、03期积极一端有明显峰值
data.groupby('episode')['sent_average'].mean().plot.bar()
g = sns.FacetGrid(data, col="episode")
g = g.map(sns.distplot, "sent_average")
4.3 评论区的观众们对于《我是大侦探》中的每个嘉宾评价如何,趋势如何?
我们由每一条评论里面提及到的嘉宾名字为统计依据,把涉及到各个嘉宾的评论进行标记并分别按列保存,这样可以方便我们计算关于各个嘉宾的评价平均值
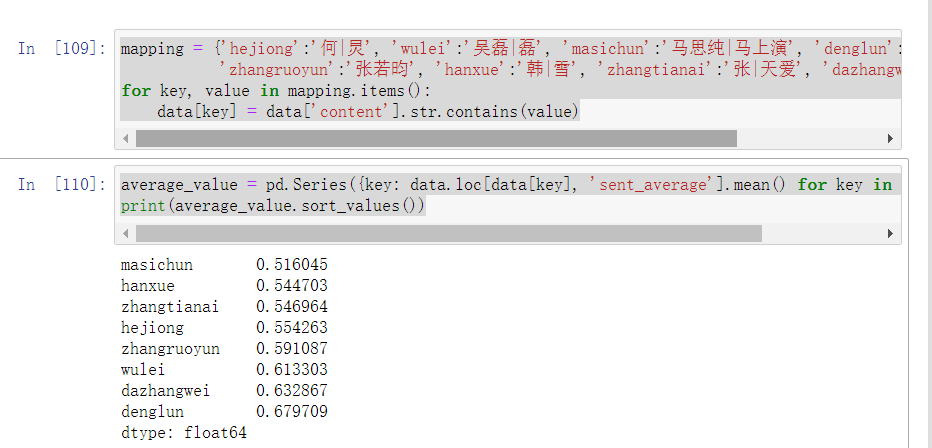
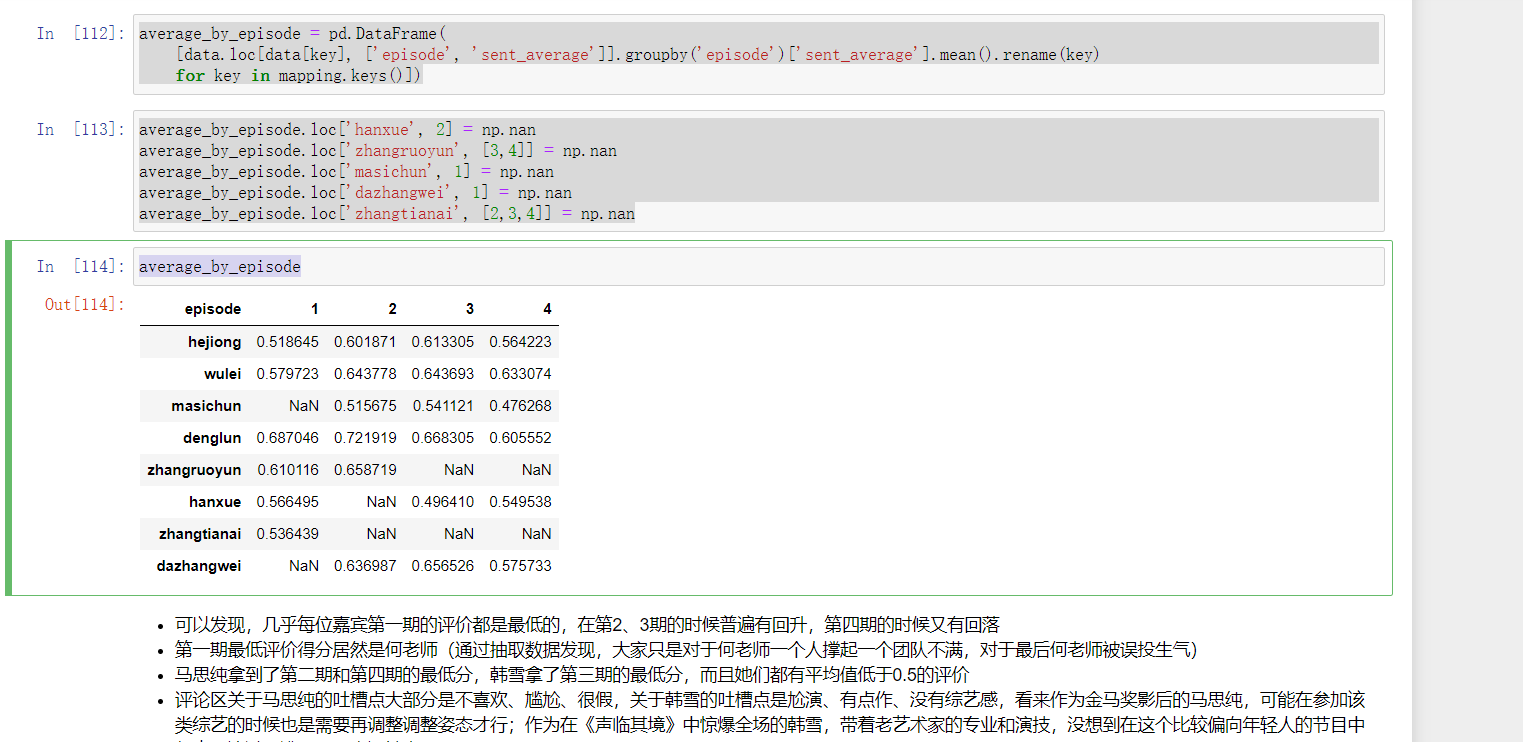
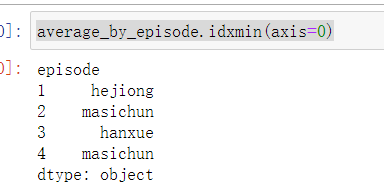
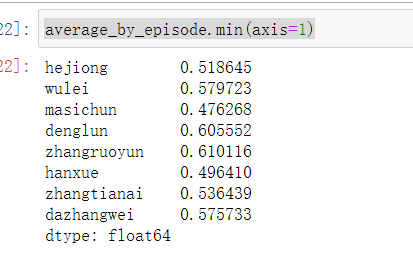
- 由图可以看到,四期以来的评论区对于马思纯的评价是最低的,只有0.52,对于邓伦的评价是最高的,有0.68
- 最受欢迎的三位嘉宾是:邓伦、大张伟和吴磊小哥哥,最受diss的三位嘉宾是:马思纯、韩雪和张天爱
1 mapping = {'hejiong':'何|炅', 'wulei':'吴磊|磊', 'masichun':'马思纯|马上演', 'denglun':'邓|邓伦',
2 'zhangruoyun':'张若昀', 'hanxue':'韩|雪', 'zhangtianai':'张|天爱', 'dazhangwei':'大老师|大张伟'}
3 for key, value in mapping.items():
4 data[key] = data['content'].str.contains(value)
1 average_value = pd.Series({key: data.loc[data[key], 'sent_average'].mean() for key in mapping.keys()})
2 print(average_value.sort_values())
average_value.sort_values().plot.barh()

再以每集分组,看每位嘉宾的评价趋势如何,四期以来好评是否有回升?
- 由于某些嘉宾并没有四期都参加,所以把没有参加的对应数据设置为缺失值
1 average_by_episode = pd.DataFrame(
2 [data.loc[data[key], ['episode', 'sent_average']].groupby('episode')['sent_average'].mean().rename(key)
3 for key in mapping.keys()])
4
5 average_by_episode.loc['hanxue', 2] = np.nan
6 average_by_episode.loc['zhangruoyun', [3,4]] = np.nan
7 average_by_episode.loc['masichun', 1] = np.nan
8 average_by_episode.loc['dazhangwei', 1] = np.nan
9 average_by_episode.loc['zhangtianai', [2,3,4]] = np.nan
10
11 average_by_episode
1 average_by_episode.plot.bar(figsize=(12, 6), rot=0)
average_by_episode.idxmin(axis=0)
average_by_episode.min(axis=1)
data.loc[data['hejiong']&data['episode'] == 1, 'content'].sample(5)
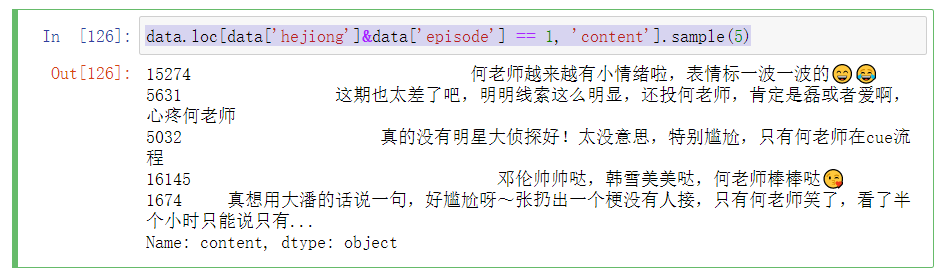
data.loc[data['masichun'], 'content'].sample(5)

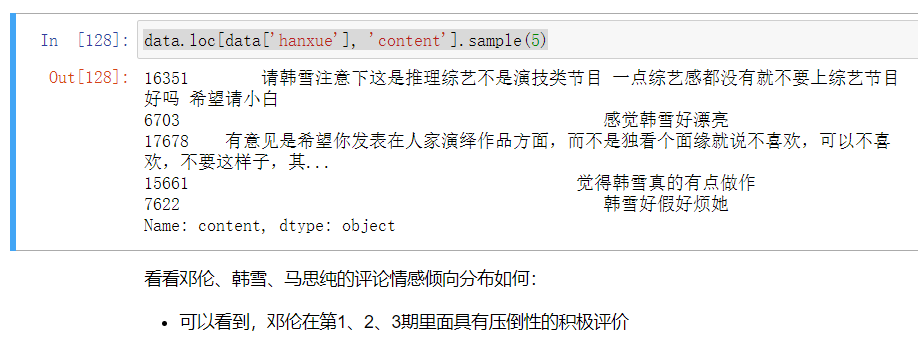
data.loc[data['hanxue'], 'content'].sample(5)
denglun = data.loc[data['denglun'], ['episode', 'sent_average']]
g = sns.FacetGrid(denglun, col="episode", size=4)
g = g.map(sns.distplot, "sent_average", bins=30, kde=False)
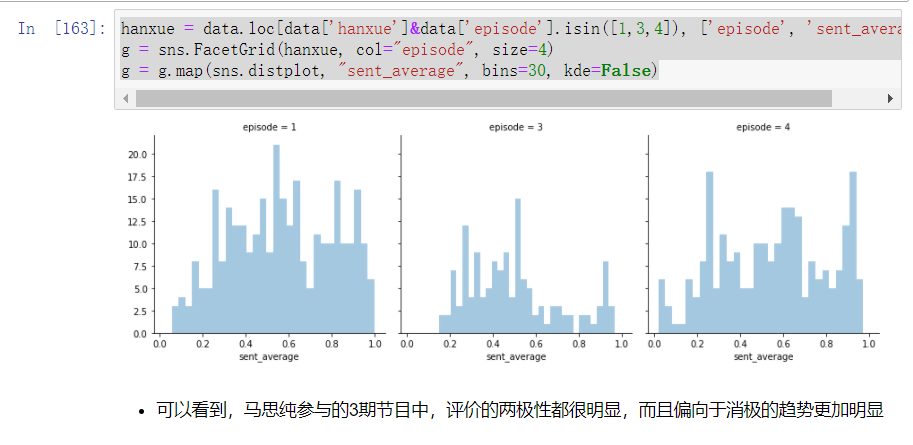
1 hanxue = data.loc[data['hanxue']&data['episode'].isin([1,3,4]), ['episode', 'sent_average']]
2 g = sns.FacetGrid(hanxue, col="episode", size=4)
3 g = g.map(sns.distplot, "sent_average", bins=30, kde=False)
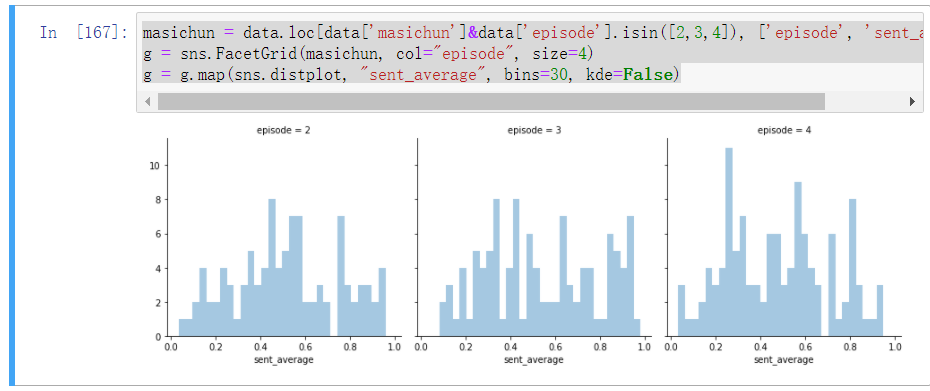
masichun = data.loc[data['masichun']&data['episode'].isin([2,3,4]), ['episode', 'sent_average']]
g = sns.FacetGrid(masichun, col="episode", size=4)
g = g.map(sns.distplot, "sent_average", bins=30, kde=False)
4.4 评论区对于《明星大侦探》的原班嘉宾鬼鬼、撒撒、白敬亭、王鸥等人的呼唤声有多大?
可以看到评论区时不时就在抱怨为什么不是原班人马来录制的,还有很多对于原班人马鬼鬼、撒撒、白敬亭、王鸥等人的呼唤。那么到底这个呼唤声多大才能让导演听见呢?评论区又是对于原班人马谁的呼唤声最大呢?
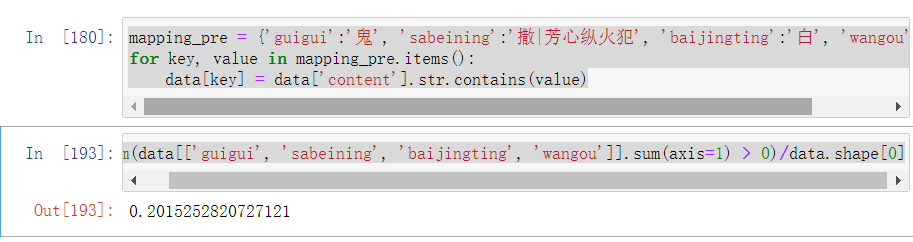
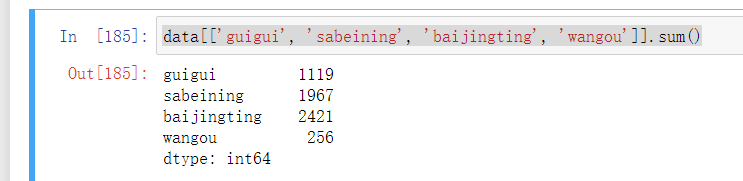
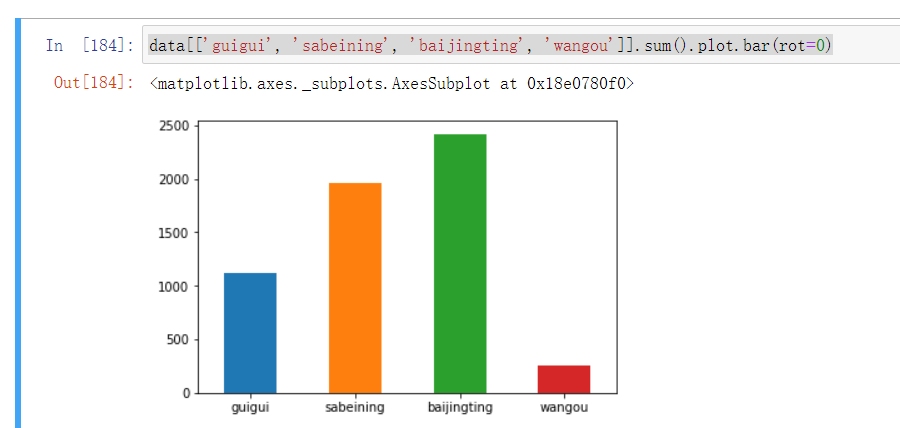
- 可以看到, 有超过20%的评论都在呼唤原班人马鬼鬼、撒撒、白敬亭、王鸥等人,也就是说,5条评论中就有1条评论是在呼唤原班人马的
- 而评论区中对于小白白敬亭的呼声是最大的,达到了2400多条,其次是芳心纵火犯撒撒撒贝宁,也接近两千条,希望可以在后面几期的节目中看到他们吧
mapping_pre = {'guigui':'鬼', 'sabeining':'撒|芳心纵火犯', 'baijingting':'白', 'wangou':'王|鸥'}
for key, value in mapping_pre.items():
data[key] = data['content'].str.contains(value)
sum(data[['guigui', 'sabeining', 'baijingting', 'wangou']].sum(axis=1) > 0)/data.shape[0]
data[['guigui', 'sabeining', 'baijingting', 'wangou']].sum()
data[['guigui', 'sabeining', 'baijingting', 'wangou']].sum().plot.bar(rot=0)
5. 词云图
由于篇幅太长,这次的分析没有涉及到词频统计、词性分析等内容。老师说,一千个人的眼中有一千个哈姆雷特,每个人对于一部剧的理解都各不相同,那就来生成一张词云图吧,大家都可以从中看到自己想看的内容,喜欢该综艺的人可以看到“好看”、“喜欢”、“搞笑”、“不错”等字眼,不喜欢该综艺的人可以看到“不喜欢”、“尴尬”、“无聊”、“不好”等字眼。
1 import jieba
2 from collections import Counter
3
4 data['content'] = data['content'].astype('str')
5 text = ''.join(data['content'])
6
7 jieba.add_word('明星大侦探')
8 jieba.add_word('我是大侦探')
9 jieba.add_word('何老师')
10 jieba.add_word('大老师')
11 jieba.add_word('雪笑笑')
12 jieba.add_word('撒撒')
13 jieba.add_word('撒老师')
14 jieba.add_word('没有明星大侦探好看')
15 jieba.add_word('不适合')
16 jieba.add_word('不喜欢')
17 jieba.add_word('飙演技')
18
19 words = list(jieba.cut(text))
20 swords = [x.strip() for x in open ('/Users/apple/Desktop/stopwords.txt')]
21
22 ex_sw_words = []
23 for word in words:
24 if len(word)>1 and (word not in swords):
25 ex_sw_words.append(word)
26
27
28 import numpy as np
29 import matplotlib.pyplot as plt
30 from wordcloud import WordCloud, ImageColorGenerator
31 import PIL.Image as Image
32
33 coloring = np.array(Image.open("/Users/apple/Desktop/mongo.jpeg"))
34 image_colors = ImageColorGenerator(coloring)
35 my_wordcloud = WordCloud(background_color="white", max_words=200,
36 mask=coloring, max_font_size=60, random_state=42, scale=2,
37 font_path="/Library/Fonts/Microsoft/SimHei.ttf").generate(' '.join(ex_sw_words))
38 plt.figure(figsize=(10,10))
39 plt.axis("off")
40 plt.imshow(my_wordcloud.recolor(color_func=image_colors))

完整代码:
1 import pandas as pd
2 import numpy as np
3 from pymongo import MongoClient
4 from pandas.io.json import json_normalize
5
6 conn = MongoClient(host='127.0.0.1', port=27017) # 实例化MongoClient
7 db = conn.get_database('mongotv3') # 连接到mongotv数据库
8
9 mongotv1 = db.get_collection('mongotv1') # 连接到集合mongotv1
10 mon_data = mongotv1.find() # 查询这个集合下的所有记录
11
12 # 遍历mon_data,获取每一条记录下的’comments‘数据,组装成一个列表
13 # 使用json_normalize把JSON数据扁平化成一个DataFrame,就成功地把第1期节目的评论数据成功地从MongoDB中提取出来并转换为pandas的DataFrame格式了
14 data1 = json_normalize([j['comments'] for j in mon_data], sep='_')
15
16 # 下面接着使用同样的方法提取第2、3、4期节目评论数据
17 data2 = json_normalize([j['comments'] for j in db.get_collection('mongotv2').find()], sep='_')
18 data3 = json_normalize([j['comments'] for j in db.get_collection('mongotv3').find()], sep='_')
19 data4 = json_normalize([j['comments'] for j in db.get_collection('mongotv4').find()], sep='_')
20
21
22 print(data1.shape, data2.shape, data3.shape, data4.shape)
23
24
25 data1['episode'] = 1
26 data2['episode'] = 2
27 data3['episode'] = 3
28 data4['episode'] = 4
29
30 data = pd.concat([data1, data2, data3, data4])
31
32
33 data.shape
34
35 data.sample(3)
36
37 data.info()
38
39 data = data[['comment_id', 'content', 'origin_comment_content', 'origin_comment_up_num',
40 'origin_comment_user', 'up_num', 'user_nickname', 'episode']]
41
42 data.sample(5)
43
44
45 from snownlp import SnowNLP
46
47 s = SnowNLP('何老师大赞!')
48 s.sentiments
49
50
51
52 from aip import AipNlp
53
54 """ 你的 APPID AK SK """
55 APP_ID = '你的 App ID'
56 API_KEY = '你的 Api Key'
57 SECRET_KEY = '你的 Secret Key'
58
59 client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
60 client.sentimentClassify('好喜欢大老师!')
61
62
63
64 from QcloudApi.qcloudapi import QcloudApi
65 import requests
66
67 module = 'wenzhi'
68 action = 'TextSentiment'
69 config = {'Region':'gz',
70 'secretId':'你的 secretId',
71 'secretKey':'你的 secretKey'}
72 service = QcloudApi(module, config)
73 action_params = {'content': '真的不好看'}
74 url = service.generateUrl(action, action_params)
75 requests.get(url).json()
76
77
78
79 import pandas as pd
80 import requests
81 from snownlp import SnowNLP
82 from aip import AipNlp
83 from QcloudApi.qcloudapi import QcloudApi
84
85
86 # SnowNLP API
87
88
89 def get_sent_snownlp(data):
90 s = SnowNLP(data)
91 return s.sentiments
92
93
94 data['sent_snownlp'] = data['content'].apply(get_sent_snownlp)
95
96 # 百度API
97 APP_ID = '11128642'
98 API_KEY = 'odAzooF9AuFhKTFScWGnleTZ'
99 SECRET_KEY = 'mHWaMrh5EXPhb5tkdKode5uxVemhtf13'
100
101 client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
102
103
104 def get_sent_baidu(data):
105 return_data = client.sentimentClassify(data)
106 items = return_data.get('items')
107 if items:
108 return items[0]['positive_prob']
109
110
111 data['sent_baidu'] = data['content'].apply(get_sent_baidu)
112
113
114 # 腾讯API
115 module = 'wenzhi'
116 action = 'TextSentiment'
117 config = {'Region':'gz',
118 'secretId':'AKID6JQM5c813zkNvNuomifcMxPIA2mLitrs',
119 'secretKey':'GRQGzWs8D5kDUYR8e2KQK3f5TitsfKo6'}
120 service = QcloudApi(module, config)
121
122
123 def get_sent_tc(data):
124
125 action_params = {'content': data}
126 url = service.generateUrl(action, action_params)
127 response = requests.get(url).json()
128 positive = response.get('positive')
129 if positive is not None:
130 return positive
131
132
133 data['sent_tencent'] = data['content'].apply(get_sent_tc)
134
135 data.to_csv('/Users/apple/Desktop/data.csv', index=False)
136
137
138 data.sample(3)
139
140
141 data[['content', 'sent_snownlp', 'sent_baidu', 'sent_tencent']].sample(5)
142
143
144
145 data['sent_average'] = data[['sent_baidu', 'sent_tencent']].mean(axis=1)
146
147
148 data['sent_average'].mean()
149
150
151 import matplotlib.pyplot as plt
152 import seaborn as sns
153 %matplotlib inline
154
155 data['sent_average'].plot.hist(bins = 30)
156
157
158 pd.cut(data['sent_average'], [0, 0.4, 0.6, 1]).value_counts()
159
160
161 data.loc[data['sent_average'] < 0.2, ['content', 'sent_average']].sample(5)
162
163
164 data.loc[data['sent_average'] > 0.8, ['content', 'sent_average']].sample(5)
165
166
167
168 data.groupby('episode')['sent_average'].mean()
169
170
171 data.groupby('episode')['sent_average'].mean().plot.bar()
172
173
174 g = sns.FacetGrid(data, col="episode")
175 g = g.map(sns.distplot, "sent_average")
176
177 mapping = {'hejiong':'何|炅', 'wulei':'吴磊|磊', 'masichun':'马思纯|马上演', 'denglun':'邓|邓伦',
178 'zhangruoyun':'张若昀', 'hanxue':'韩|雪', 'zhangtianai':'张|天爱', 'dazhangwei':'大老师|大张伟'}
179 for key, value in mapping.items():
180 data[key] = data['content'].str.contains(value)
181
182 average_value = pd.Series({key: data.loc[data[key], 'sent_average'].mean() for key in mapping.keys()})
183 print(average_value.sort_values())
184
185
186 average_value.sort_values().plot.barh()
187
188 average_by_episode = pd.DataFrame(
189 [data.loc[data[key], ['episode', 'sent_average']].groupby('episode')['sent_average'].mean().rename(key)
190 for key in mapping.keys()])
191
192
193 average_by_episode.loc['hanxue', 2] = np.nan
194 average_by_episode.loc['zhangruoyun', [3,4]] = np.nan
195 average_by_episode.loc['masichun', 1] = np.nan
196 average_by_episode.loc['dazhangwei', 1] = np.nan
197 average_by_episode.loc['zhangtianai', [2,3,4]] = np.nan
198
199
200 average_by_episode
201
202
203 average_by_episode.plot.bar(figsize=(12, 6), rot=0)
204
205
206 average_by_episode.idxmin(axis=0)
207
208 average_by_episode.min(axis=1)
209
210 data.loc[data['hejiong']&data['episode'] == 1, 'content'].sample(5)
211
212 data.loc[data['masichun'], 'content'].sample(5)
213
214 data.loc[data['hanxue'], 'content'].sample(5)
215
216 denglun = data.loc[data['denglun'], ['episode', 'sent_average']]
217 g = sns.FacetGrid(denglun, col="episode", size=4)
218 g = g.map(sns.distplot, "sent_average", bins=30, kde=False)
219
220
221 hanxue = data.loc[data['hanxue']&data['episode'].isin([1,3,4]), ['episode', 'sent_average']]
222 g = sns.FacetGrid(hanxue, col="episode", size=4)
223 g = g.map(sns.distplot, "sent_average", bins=30, kde=False)
224
225
226 masichun = data.loc[data['masichun']&data['episode'].isin([2,3,4]), ['episode', 'sent_average']]
227 g = sns.FacetGrid(masichun, col="episode", size=4)
228 g = g.map(sns.distplot, "sent_average", bins=30, kde=False)
229
230
231 mapping_pre = {'guigui':'鬼', 'sabeining':'撒|芳心纵火犯', 'baijingting':'白', 'wangou':'王|鸥'}
232 for key, value in mapping_pre.items():
233 data[key] = data['content'].str.contains(value)
234
235
236 sum(data[['guigui', 'sabeining', 'baijingting', 'wangou']].sum(axis=1) > 0)/data.shape[0]
237
238
239 data[['guigui', 'sabeining', 'baijingting', 'wangou']].sum()
240
241 data[['guigui', 'sabeining', 'baijingting', 'wangou']].sum().plot.bar(rot=0)
242
243 import jieba
244 from collections import Counter
245
246 data['content'] = data['content'].astype('str')
247 text = ''.join(data['content'])
248
249 jieba.add_word('明星大侦探')
250 jieba.add_word('我是大侦探')
251 jieba.add_word('何老师')
252 jieba.add_word('大老师')
253 jieba.add_word('雪笑笑')
254 jieba.add_word('撒撒')
255 jieba.add_word('撒老师')
256 jieba.add_word('没有明星大侦探好看')
257 jieba.add_word('不适合')
258 jieba.add_word('不喜欢')
259 jieba.add_word('飙演技')
260
261 words = list(jieba.cut(text))
262 swords = [x.strip() for x in open ('/Users/apple/Desktop/stopwords.txt')]
263
264 ex_sw_words = []
265 for word in words:
266 if len(word)>1 and (word not in swords):
267 ex_sw_words.append(word)
268
269
270 import numpy as np
271 import matplotlib.pyplot as plt
272 from wordcloud import WordCloud, ImageColorGenerator
273 import PIL.Image as Image
274
275 coloring = np.array(Image.open("/Users/apple/Desktop/mongo.jpeg"))
276 image_colors = ImageColorGenerator(coloring)
277 my_wordcloud = WordCloud(background_color="white", max_words=200,
278 mask=coloring, max_font_size=60, random_state=42, scale=2,
279 font_path="/Library/Fonts/Microsoft/SimHei.ttf").generate(' '.join(ex_sw_words))
280 plt.figure(figsize=(10,10))
281 plt.axis("off")
282 plt.imshow(my_wordcloud.recolor(color_func=image_colors))
五,总结
- 总的来说,这个数据还是挺好玩的
- 后续可以对该数据进行打标,然后尝试各种方法来自行建模分类预测,这便是自然语言处理的内容了

