es 查询结果说明 聚合查询
{ "took": 36, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 13832623, "max_score": 1, "hits": [ { "_index": "csc-pacific-case-monitor", "_type": "case-monitor", "_id": "36501235", "_score": 1, "_source": { "caseId": "36501235", "addTime": 1537100536000, "caseTypeId": "407", "closerId": "20669", "closeTime": 1537100549000, "contactNumber": "[\"\",\"18151430301\"]", "content": "骑手问题:骑手来电就挂了\n骑手诉求:\n订单号:", "creatorId": "20669", "customerId": "3204563", "customerType": "3001", "deadline": 1537186936000, "feedbackTime": null, "businessId": "56", "businessName": null, "fourthCategoryId": null, "fifthCategoryId": null, "ownerId": "20669", "managerId": "20669", "questionId": "35183", "questionReasonId": null, "orderTypeId": "352", "source": "1", "statusId": "2", "subSource": "-1", "questionTypeId": "16084", "updateTime": 1537100549000, "startTime": 1537100536000, "priorityId": "5", "updaterId": "20669", "memo": null, "flowId": "334", "nodeId": "64453", "lifeCycle": "1", "latest_main_scn": 4900981072207, "latest_main_es_update_time": 1537100549583, "level_1": "1", "level_2": "3", "level_3": "6", "level_4": "13", "level_5": "45", "level_6": "589", "departmentId": 589 } },
hits编辑
返回结果中最重要的部分就是 hits,它包含的 total 字段来表示匹配到的文档总数,并且一个 hits 数组包含所查询结果的前十个文档(在未使用分页的情况下)。
在 hits 数组中每个结果包含文档的 _index 、 _type 、 _id ,加上 _source 字段。这意味着用户可以直接从返回的搜索结果中使用整个文档。
每个结果还有一个 _score ,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照 _score 降序排列的。
max_score 值是与查询所匹配文档的 _score 的最大值。
took编辑
took 值告诉我们执行整个搜索请求耗费了多少毫秒。
shards编辑
_shards 部分 告诉我们在查询中参与分片的总数,以及这些分片成功了多少个失败了多少个。正常情况下我们不希望分片失败,但是分片失败是可能发生的。如果我们遭遇到一种灾难级别的故障,在这个故障中丢失了相同分片的原始数据和副本,那么对这个分片将没有可用副本来对搜索请求作出响应。假若这样,Elasticsearch 将报告这个分片是失败的,但是会继续返回剩余分片的结果。
timeout编辑
timed_out 值告诉我们查询是否超时。默认情况下,搜索请求不会超时。 如果低响应时间比完成结果更重要,你可以指定 timeout 为 10 或者 10ms(10毫秒),或者 1s(1秒):
GET /_search?timeout=10ms
在请求超时之前,Elasticsearch 将会返回已经成功从每个分片获取的结果。
应当注意的是 timeout 不是停止执行查询,它仅仅是告知正在协调的节点返回到目前为止收集的结果并且关闭连接。在后台,其他的分片可能仍在执行查询即使是结果已经被发送了。
使用超时是因为 SLA(服务等级协议)对你是很重要的,而不是因为想去中止长时间运行的查询。
------------------------------------------------------------------------------------------------聚合查询--------------------------------------------------------------------------------------------
查询
1 GET /a_cj_terminal_cfppvalue/_search 2 { 3 "query": { 4 "match_all": {} 5 }, 6 "aggs":{ 7 "Group":{ 8 "terms":{ 9 "field":"paramorder" 10 } 11 } 12 } 13 }
1 "aggregations": { <----就是聚合的 2 "Group": { <----对哪个字段进行聚合.一般字段名_group 3 "doc_count_error_upper_bound": 12, 4 "sum_other_doc_count": 1233, 5 "buckets": [ 6 { 7 "key": "1", <---字段的key就是上面的查询的field字段 8 "doc_count": 130<---符合key为1的就有130个 9 }, 10 { 11 "key": "2", 12 "doc_count": 96 13 }, 14 { 15 "key": "3", 16 "doc_count": 59 17 }, 18 { 19 "key": "0", 20 "doc_count": 52 21 }, 22 { 23 "key": "4", 24 "doc_count": 40 25 }, 26 { 27 "key": "01", 28 "doc_count": 37 29 }, 30 { 31 "key": "02", 32 "doc_count": 37 33 }, 34 { 35 "key": "03", 36 "doc_count": 31 37 }, 38 { 39 "key": "10", 40 "doc_count": 30 41 }, 42 { 43 "key": "11", 44 "doc_count": 26 45 } 46 ] 47 } 48 }
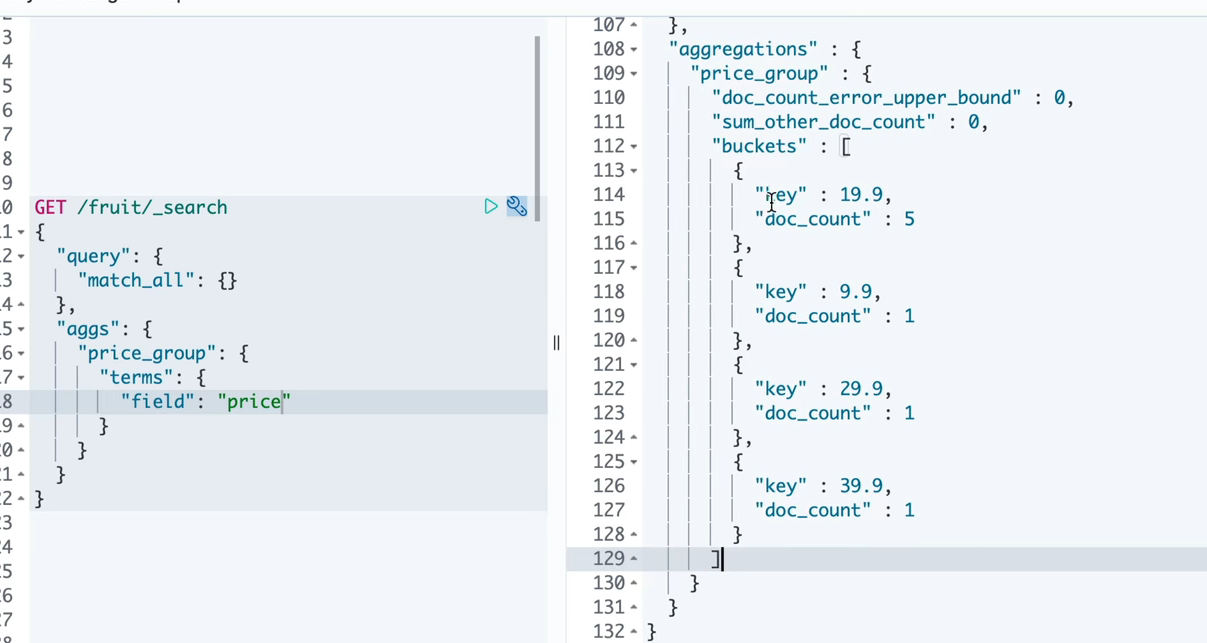
如果只想要聚合的结果,就只需要把查询的size为0即可
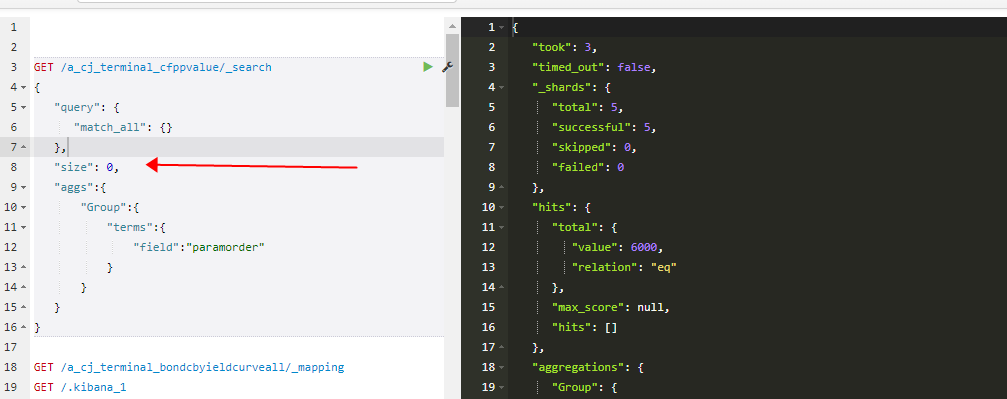
//聚合函数查询,返回的是map,需要强转成map再进行赋值
@Test void testSearch5() throws IOException { SearchRequest searchRequest = new SearchRequest("a_cj_terminal_cfppvalue"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //QueryBuilders.termQuery 精确匹配 BoolQueryBuilder boolQuery = QueryBuilders.boolQuery() .must(QueryBuilders.termQuery("nipmid", "100000000000227540")); sourceBuilder.query(boolQuery); sourceBuilder.size(0);//其中 name值自定义,id为需要分组的key aggs 结果存在桶里面 AggregationBuilder groupFieldNameAgg = AggregationBuilders.terms("Group").field("paramorder").size(10000); //top_hits指标聚合器跟踪正在聚合的最相关文档。 此聚合器旨在用作子聚合器,以便可以按桶聚合最匹配的文档。 //top_hits聚合器可以有效地用于通过桶聚合器按特定字段对结果集进行分组。 一个或多个存储桶聚合器确定结果集被切入的属性。 //from - 要获取的第一个结果的偏移量。 //size - 每个桶返回的最大匹配匹配数的最大数量。默认情况下,返回前三个匹配的匹配。 //sort - 如何对最匹配的匹配进行排序。默认情况下,命中按主查询的分数排序。 //指定返回的字段 //排除返回的字段 // 定义需要的返回值字段 paramorder分组 TopHitsAggregationBuilder top = AggregationBuilders.topHits("MaxEid").fetchSource( // String[] returnField = new String[]{"user_name","date","sum","nickname"}; new String[]{"paramchname","paramorder","nipmid"}, null).size(1).sort("eid", SortOrder.DESC); //// subagg 父聚合中的子聚合 根据所需要的字段分组 里面的参数是AggregationBuilder sourceBuilder.aggregation(groupFieldNameAgg.subAggregation(top)); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); searchRequest.source(sourceBuilder); SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT); if(null != search.getAggregations()){ //从桶中取出该字段分组后的内容 Terms terms = search.getAggregations().get("Group"); // Aggregations aggregations = search.getAggregations(); // ParsedDoubleTerms doubleTerms = aggregations.get("Group"); // List<? extends Terms.Bucket> buckets1 = doubleTerms.getBuckets(); // for (Terms.Bucket bucket : buckets1) { // System.out.println(bucket.getKey()+" "+bucket.getDocCount()); // } if(terms!=null){ System.out.println(JSON.toJSONString(terms)); } @SuppressWarnings("unchecked") Collection<Terms.Bucket> buckets = (Collection<Terms.Bucket>) terms.getBuckets(); if(buckets==null||buckets.size()<=0) { return; } System.out.println(JSON.toJSONString(buckets)); Map<Integer, Map<String, Object>> map = new HashMap<>(); for (Terms.Bucket bucket : buckets) { int key = Integer.valueOf(bucket.getKeyAsString()); Map<String, Object> valueMap = map.get(key); if(valueMap==null) { valueMap = new HashMap<>(); map.put(key, valueMap); } TopHits topHits = bucket.getAggregations().get("MaxEid"); SearchHits hits = topHits.getHits(); SearchHit[] hitArray = hits.getHits(); SearchHit hit = hitArray[0]; Map<String, Object> sourceAsMap = hit.getSourceAsMap(); valueMap.putAll(sourceAsMap); } System.out.println(JSON.toJSONString(map)); } // String s = JSON.toJSONString(search.getHits()); // System.out.println(s); }
聚合函数的max,min,avg之类的需要数据类型是double才可以使用,否则会报错,keyword类型错误
@Test void testSearch6() throws IOException { SearchRequest searchRequest = new SearchRequest("a_cj_terminal_cfppvalue"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //QueryBuilders.termQuery 精确匹配 BoolQueryBuilder boolQuery = QueryBuilders.boolQuery() .must(QueryBuilders.termQuery("nipmid", "100000000000227540")); sourceBuilder.query(boolQuery) .aggregation(AggregationBuilders.max("eid_max").field("eid_old")); sourceBuilder.size(0);//其中 name值自定义,id为需要分组的key aggs 结果存在桶里面 sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); searchRequest.source(sourceBuilder); SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT); if(null != search){ //从桶中取出该字段分组后的内容 Aggregations aggregations = search.getAggregations(); ParsedMax max = aggregations.get("eid_max"); System.out.println(max.getValue()); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号