jvm运行过程
把文件编译成字节码文件的叫编译器的前端,
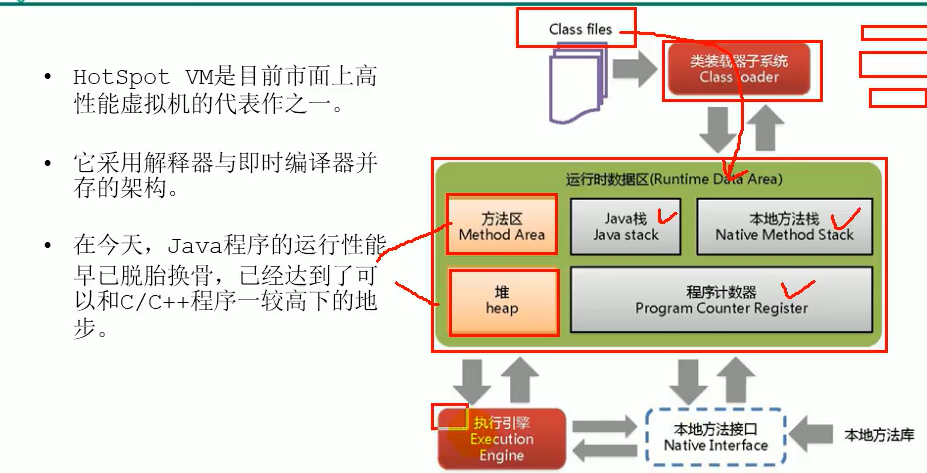
线程共享的方法去和堆,非线程共享的:java虚拟机栈,本地方法栈,还有程序计数器 都是每个线程独有一份的
执行引擎叫做编译器的后端
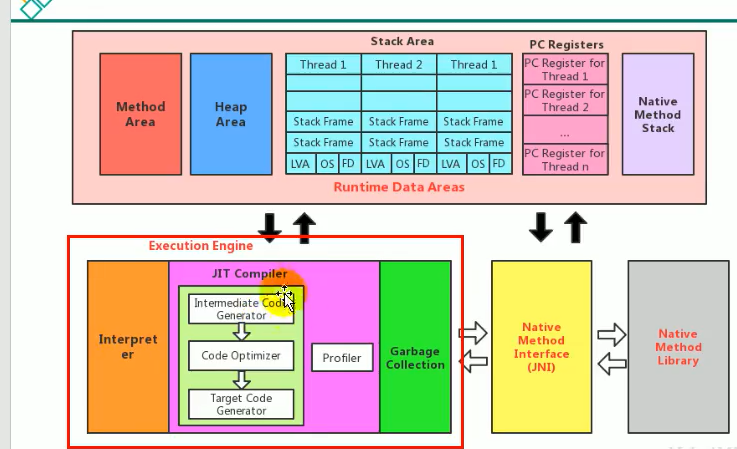
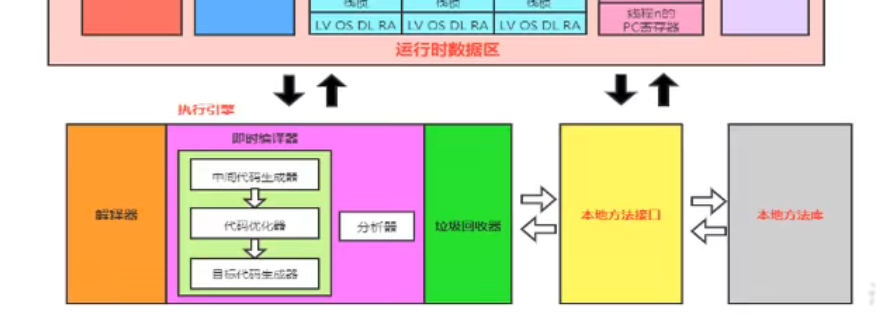
执行引擎,分为解释器,jit即时编译器,以及垃圾回收器这三部分包含在执行引擎当中
当字节码文件加载到内存中下一步要开始解释运行了,解释运行用到的就是解释器
当存在反复执行的热点代码的时候就用到jit的即时编译器
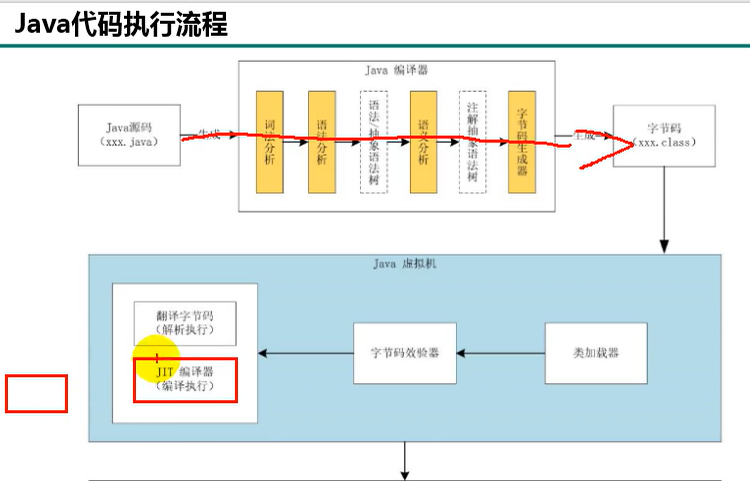
两次编译,第一次编译成字节码文件,第二次编译的时候把反复执行的热点代码通过jit编译器编译成机器指令,同时缓存起来放在方法区,提高虚拟机性能
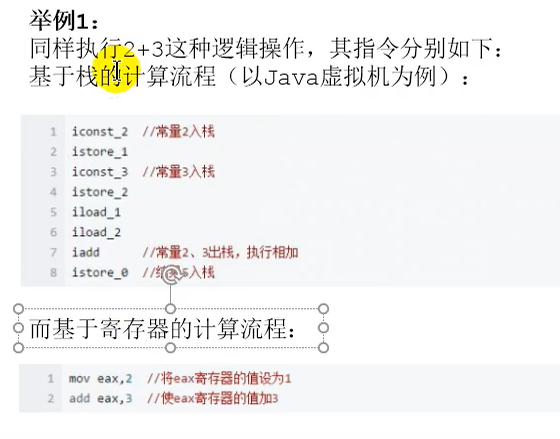
根据栈的方式和寄存器的方式
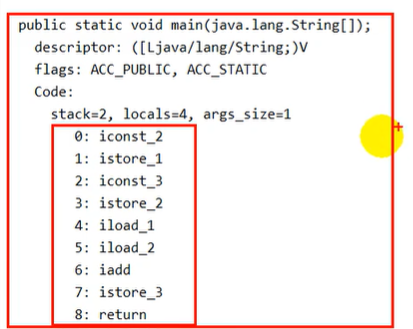
int i = 2+3; 编译之后直接2+3

int i =2;
int j =3;
int z = i + j;
字节码文件如下 定义了一个常量2 , istore_1 就是操作数栈的索引位置 ,保存到1的操作数栈当中,
定义3,保存到索引2当中,
然后把i和j加载进来,进行求和的操作


类的加载器分为引导类加载器,扩展类加载器,系统类加载器

运行中输入jps可以查看运行中的程序的进程号
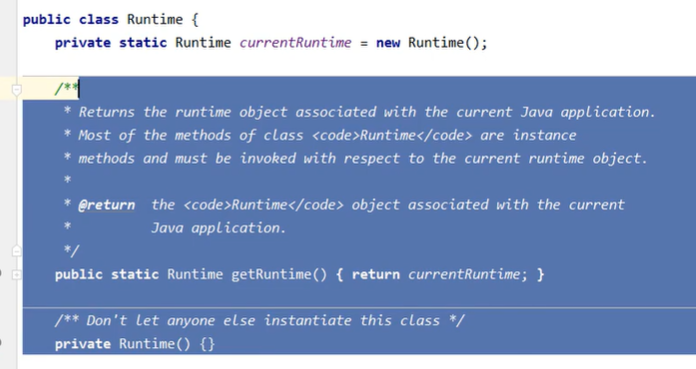
runntime 运行时类 ,饿汉式 单例

获取到当前的唯一的实例,将当前的进程结束掉
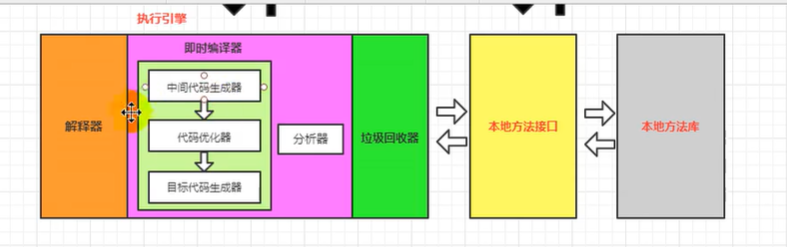
主流的解释器和即时编译器都需要有
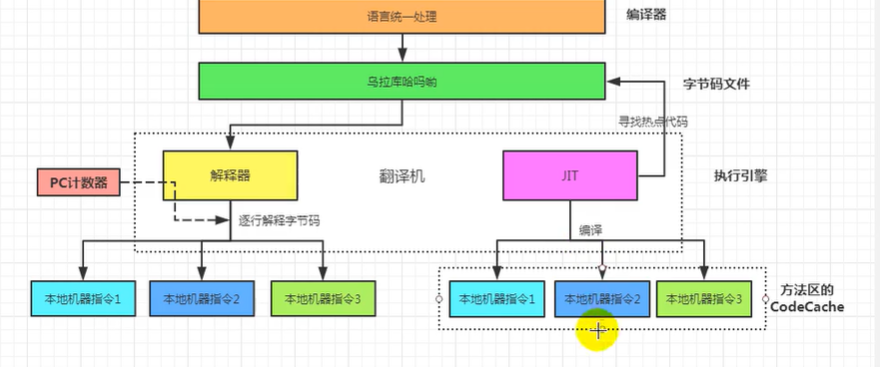
for循环如果没有jit即使编译器每次循环都要逐行解释,而有了jit即时编译器可以把热点代码即时编译


栈可知内存地址,减少开销

最重要的虚拟机,hotspot
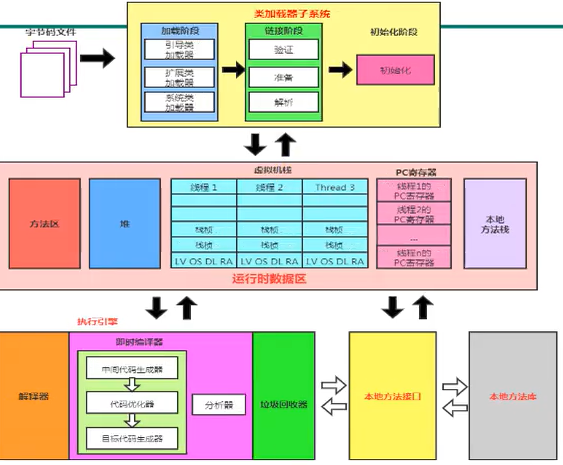
类加载子系统 加载->链接->初始化 同时加载需要用到的加载器,引导类加载器,扩展类加载器,还有系统类加载器,
linking 分为 验证,准备,解析
初始化,涉及到静态变量的现实初始化

每一个字节码文件,对应的在内存中哦用到的类和接口就加载进来
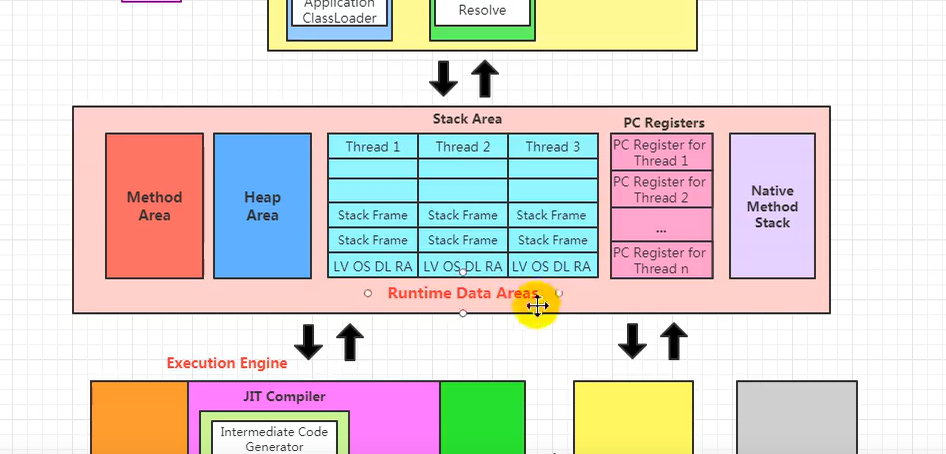
运行时数据区 每一个线程一份程序计数器
栈就是虚拟机栈 每一个线程一份 stack frame 栈帧; LV局部变量表, OS操作数栈 DL动态链接 RA方法返回地址(栈帧具体的细节)
本地方法栈 本地api相关的调用
堆区 ,放置对象(共享的) 被多个线程所共享的
方法区 类的信息,常量,域信息,方法信息
执行引擎 解释器,即时编译器,垃圾回收器, 将我们的指令翻译成机器指令供cpu执行,便于和操作系统打交道
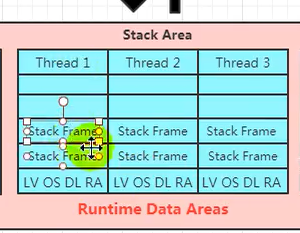 栈就是虚拟机栈 stack frame 栈帧; LV局部变量表, OS操作数栈 DL动态链接 RA方法返回地址(栈帧具体的细节)
栈就是虚拟机栈 stack frame 栈帧; LV局部变量表, OS操作数栈 DL动态链接 RA方法返回地址(栈帧具体的细节)
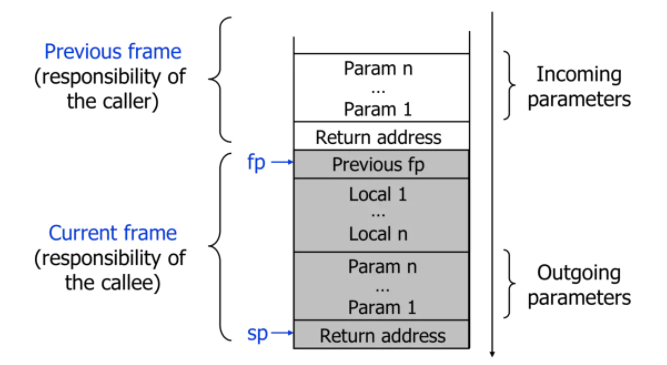
而什么是栈帧(Stack Frame)呢?
每一次函数的调用,都会在调用栈(call stack)上维护一个独立的栈帧(stack frame).每个独立的栈帧一般包括:
- 函数的返回地址和参数
- 临时变量: 包括函数的非静态局部变量以及编译器自动生成的其他临时变量
- 函数调用的上下文
栈是从高地址向低地址延伸,一个函数的栈帧用ebp 和 esp 这两个寄存器来划定范围.ebp 指向当前的栈帧的底部,esp 始终指向栈帧的顶部;
ebp 寄存器又被称为帧指针(Frame Pointer);
esp 寄存器又被称为栈指针(Stack Pointer);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号