用Python+百度云ocr 复刻复旦大学博士关于核酸检测的功能
1事情背景

2、用百度ocr识别(百度智能云,通用文字识别(标准版)https://cloud.baidu.com/doc/OCR/s/zk3h7xz52)
[百度ocr文字识别](https://cloud.baidu.com/)
看了很多篇用百度OCR进行文字识别的文章,以及百度的官方文档
新建AipOcr
from aip import AipOcr
""" 你的 APPID AK SK """
# 此处填入在百度云控制台处获得的appId, apiKey, secretKey的实际值
appId, apiKey, secretKey = ['*****', '*****', '*******'] #在百度al官网创建完后获得
# 创建ocr对象
ocr = AipOcr(appId, apiKey, secretKey)
读取图片
path = diropenbox('请选择需要处理的文件夹')
filelist = os.listdir(path)
#diropenbox 功能:选择本地文件 返回值 是文件夹的绝对路径
#os.listdir(path)path路径下的文件和文件夹列表
调用百度ocr的代码:
res = ocr.basicGeneral(img)
3、解析返回的数据

在最刚开始我是准备用正则表达式式来提取关键信息的,但是当我看到 调用百度ocr apl 返回的内容后,我又改变了我的想法,真的没有想到百度ocr会这么牛,识别率高 而且返回的内容还是以词组的形式存放在字典中
然后我就想到可以找到关键字然后在找到相应的内容 比如:名字在 “姓名两字后面”。
4、将数据写入表格
with open('核算检测报告统计结果.csv', 'w', newline='') as f:
writer = csv.writer(f)
for row in result:
writer.writerow(row)
全部代码:
点击查看代码
# 测试百度在线图片文本识别包
# 导入百度的OCR包
#姓名、检测结果、联系电话、采样时间、接收时间。
import csv
import os
from aip import AipOcr
from easygui import diropenbox
""" 获得关键词组的下一个词组"""
def get_keyword(key):
f = 0
for word in w:
if f == 1:
return word
f = 0
if word == key:
f = 1
""" 调整日期时间的格式"""
def separate(st):
st = list(st)
st.insert(10, ' ')
stt=''
for i in st:
stt=stt+i
return stt
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
if __name__ == "__main__":
# 此处填入在百度云控制台处获得的appId, apiKey, secretKey的实际值
appId, apiKey, secretKey = ['*****', '*****', '*******'] #在百度al官网创建完后获得
# 创建ocr对象
ocr = AipOcr(appId, apiKey, secretKey)
path = diropenbox('请选择需要处理的文件夹') #选择文件对话框 设定图片目录路径
filelist = os.listdir(path) # 该方法列出path路径下的文件和文件夹列表
print('正在识别,进度如下(若软件中途出错闪退,请重新运行):')
try:
result = [['姓名', '联系电话', '检测结果', '采样时间', '接收时间']]
for file in filelist:
file_path = f'{path}\\{file}' # 图片文件绝对路径 少了这个,加入新图片会报错
print(file_path)
with open(file_path, 'rb') as fin:
img = fin.read()
res = ocr.basicGeneral(img)
x=[words for words in res.values()]
w=[]
for i in x[0]:
w=w+list(i.values())
name = get_keyword("姓名")
tel = get_keyword('联系电话')
r = get_keyword('实时PCR法') # 核酸 结果
collection_time = get_keyword('采样时间')
get_time = get_keyword('接收时间')
collection_time = separate(collection_time)
get_time = separate(get_time)
a = [name, tel, r, collection_time, get_time]
result.append(a)
with open('核算检测报告统计结果.csv', 'w', newline='') as f:
writer = csv.writer(f)
for row in result:
writer.writerow(row)
print('程序运行完成')
print('已在本程序所在目录生成csv统计表')
except BaseException as e:
print('OCR识别异常中断,请重试! Error:'+str(e))
finally:
input('按任意键退出程序...')
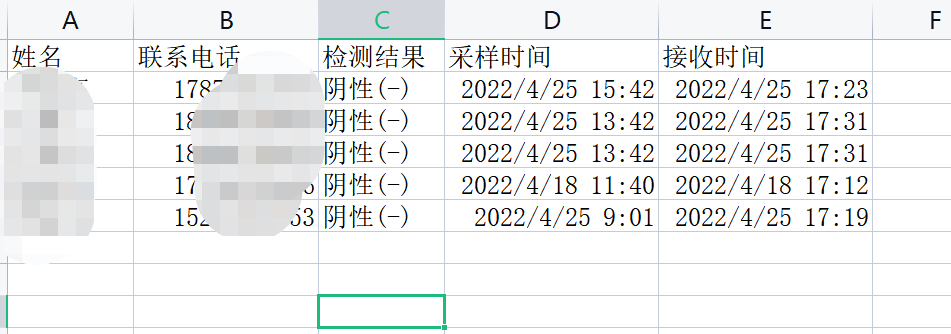
csv文档中的结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号