


valgrind和Kcachegrind性能分析工具详解
作者: zhuyong
一、valgrind介绍
valgrind是运行在Linux上的一套基于仿真技术的程序调试和分析工具,用于构建动态分析工具的装备性框架。它包括一个工具集,每个工具执行某种类型的调试、分析或类似的任务,以帮助完善你的程序。Valgrind的架构是模块化的,所以可以容易的创建新的工具而又不会扰乱现有的结构。
valgrind主要包含以下工具:
1、memcheck:检查程序中的内存问题,如泄漏、越界、非法指针等。
2、callgrind:检测程序代码的运行时间和调用过程,以及分析程序性能。
3、cachegrind:分析CPU的cache命中率、丢失率,用于进行代码优化。
4、helgrind:用于检查多线程程序的竞态条件。
5、massif:堆栈分析器,指示程序中使用了多少堆内存等信息。
另外,也有一些大多数用户不会用到的小工具: Lackey是一个示例工具,用于演示一些装备的基础性内容;Nulgrind是一个最小化的Valgrind工具,不做分析或者操作,仅用于测试目的。
二、valgrind安装及使用
安装
建议从valgrind官网下载安装,目前官网的最新包是3.16.1
$ mkdir valgrind-inst
$ cd valgrind-inst/
$ wget https://sourceware.org/pub/valgrind/valgrind-3.16.1.tar.bz2
$ ls
valgrind-3.16.1.tar.bz2
解压后进行安装,可以指定安装目录,这样的话记得设置环境变量
$ tar -xvf valgrind-3.16.1.tar.bz2
$ cd valgrind-3.16.1
$ ./configure --prefix=/usr/local/valgrind
$ make
$ make install
查看是否安装成功
$ valgrind --version
valgrind-3.16.1
工具集的使用
基本使用格式如下:
usage: valgrind [options] prog-and-args
其支持众多选项,我们可以通过valgrind --help来进行查看。
这里我们只介绍几个较为常用的选项
--tool: 是最常用的选项,用于选择使用valgrind工具集中的哪一个工具。默认值为memcheck。
--version: 用于打印valgrind的版本号
-q/--quiet: 安静的运行,只打印错误消息;
-v/--verbose: 打印更详细的信息;
--trace-children: 是否跟踪子进程,默认值为no;
--track-fds: 是否追踪打开的文件描述符,默认为no
--time-stamp=no|yes: 是否在打印出的每条消息之前加上时间戳信息。默认值为no
--log-file=<file>: 指定将消息打印到某个文件
--default-suppressions: 加载默认的抑制参数。
--alignment: 指定malloc分配内存时的最小对齐字节数;
如下的一些选项用于Memcheck工具:
--leak-check=no|summary|full: 在退出时是否查找内存泄露。默认值为summary
--show-leak-kinds=kind1,kind2,..: 显示哪一种类型的内存泄露。默认显示definite和possible这两种;
三、 Valgrind 工具详解
1) memcheck
最常用的工具,用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc、free、new、delete的调用都会被捕获。所以,它能检测以下问题:
1、使用未初始化的内存。如果在定义一个变量时没有赋初始值,后边即使赋值了,使用这个变量的时候Memcheck也会报"uninitialised value"错误。使用中会发现,valgrind提示很多这个错误,由于关注的是内存泄漏问题,所以可以用--undef-value-errors=选项把这个错误提示屏蔽掉,具体可以看后面的选项解释。
2、读/写释放后的内存块;
3、内存读写越界(数组访问越界/访问已经释放的内存),读/写超出malloc分配的内存块;
4、读/写不适当的栈中内存块;
5、内存泄漏,指向一块内存的指针永远丢失;
6、不正确的malloc/free或new/delete匹配(重复释放/使用不匹配的分配和释放函数);
7、内存覆盖,memcpy()相关函数中的dst和src指针重叠。
用法:
将程序编译生成可执行文件后执行:valgrind –leak-check=full ./程序名
注意:下面讨论的所有测试代码在编译时最好都加上-g选项(用来在memcheck的输出中生成行号)进行编译。
测试程序验证:
编写测试程序
#include <stdlib.h>
void func() {
char *p = new char[10];
}
int main() {
func();
return 0;
}
编译后,用valgrind检测程序。
如果设置了--leak-check=full,Memcheck会给出详细的每个块是在哪里分配,并且给出分配时函数调用堆栈(编译的时候使用-g选项和去掉-o优化选项,就可以得到更详细的函数信息,可以精确到代码的某一行)。可以通过--show-leak-kinds选项来选择要详细报告哪几种类型的错误。Memcheck会把函数调用堆栈相同或相似的内存块信息,放到同一个条目来显示,可以通过--leak-resolution来控制这个"相似"判断的力度。
$ g++ -g -o test leak.cpp
$ valgrind --tool=memcheck --leak-check=full ./test
检测结果如下:
==6018== Memcheck, a memory error detector
==6018== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==6018== Using Valgrind-3.16.1 and LibVEX; rerun with -h for copyright info
==6018== Command: ./test
==6018==
==6018==
==6018== HEAP SUMMARY:
==6018== in use at exit: 10 bytes in 1 blocks
==6018== total heap usage: 1 allocs, 0 frees, 10 bytes allocated
==6018==
==6018== 10 bytes in 1 blocks are definitely lost in loss record 1 of 1
==6018== at 0x4C2AC58: operator new[](unsigned long) (vg_replace_malloc.c:431)
==6018== by 0x40062E: func() (leak.cpp:4)
==6018== by 0x40063D: main (leak.cpp:8)
==6018==
==6018== LEAK SUMMARY:
==6018== definitely lost: 10 bytes in 1 blocks
==6018== indirectly lost: 0 bytes in 0 blocks
==6018== possibly lost: 0 bytes in 0 blocks
==6018== still reachable: 0 bytes in 0 blocks
==6018== suppressed: 0 bytes in 0 blocks
==6018==
==6018== For lists of detected and suppressed errors, rerun with: -s
==6018== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 0 from 0)
结果说明:
先看看输出信息中的HEAP SUMMARY,它表示程序在堆上分配内存的情况,其中的1 allocs
表示程序分配了 1 次内存,0 frees表示程序释放了 0 次内存,10 bytes allocated表示分配了 10 个字节的内存。
另外,Valgrind 也会报告程序是在哪个位置发生内存泄漏。
上面LEAK SUMMARY会打印5种不同的类型,这里我们简单介绍一下:
definitely lost: 明确丢失的内存。程序中存在内存泄露,应尽快修复。当程序结束时如果一块动态分配的内存没有被释放并且通过程序内的指针变量均无法访问这块内存则会报这个错误;
indirectly lost: 间接丢失。当使用了含有指针成员的类或结构体时可能会报这个错误。这类错误无需直接修复,它们总是与definitely lost一起出现,只要修复definitely lost即可。
possibly lost: 可能丢失。大多数情况下应视为与definitely lost一样需要尽快修复,除非你的程序让一个指针指向一块动态分配的内存(但不是这块内存的起始地址),然后通过运算得到这块内存的起始地址,再释放它。当程序结束时如果一块动态分配的内存没有被释放并且通过程序内的指针变量均无法访问这块内存的起始地址,但可以访问其中的某一部分数据,则会报这个错误。
stil reachable: 可以访问,未丢失但也未释放。如果程序是正常结束的,那么它可能不会造成程序崩溃,但长时间运行有可能耗尽系统资源。
其他几种情况,写一个综合的测试程序进行验证。
// mixed.cpp
void func() {
char *ptr = new char[10];
ptr[10] = 'a'; // 内存越界
memcpy(ptr + 1, ptr, 5); // 踩内存
delete []ptr;
delete []ptr; // 重复释放
char *p;
*p = 1; // 非法指针
}
int main() {
func();
return 0;
}
编译后,用valgrind检测程序。
$ g++ -g -o test mixed.cpp
$ valgrind --tool=memcheck --leak-check=full ./test
检测结果
==22786== Memcheck, a memory error detector
==22786== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==22786== Using Valgrind-3.16.1 and LibVEX; rerun with -h for copyright info
==22786== Command: ./test
==22786==
==22786== Invalid write of size 1 // 内存越界
==22786== at 0x4007FB: func() (mixed.cpp:6)
==22786== by 0x400851: main (mixed.cpp:18)
==22786== Address 0x5a2404a is 0 bytes after a block of size 10 alloc'd
==22786== at 0x4C2AC58: operator new[](unsigned long) (vg_replace_malloc.c:431)
==22786== by 0x4007EE: func() (mixed.cpp:5)
==22786== by 0x400851: main (mixed.cpp:18)
==22786==
==22786== Source and destination overlap in memcpy(0x5a24041, 0x5a24040, 5) // 踩内存
==22786== at 0x4C2E83D: memcpy@@GLIBC_2.14 (vg_replace_strmem.c:1033)
==22786== by 0x400819: func() (mixed.cpp:8)
==22786== by 0x400851: main (mixed.cpp:18)
==22786==
==22786== Invalid free() / delete / delete[] / realloc() // 重复释放
==22786== at 0x4C2BBAF: operator delete[](void*) (vg_replace_malloc.c:649)
==22786== by 0x40083F: func() (mixed.cpp:11)
==22786== by 0x400851: main (mixed.cpp:18)
==22786== Address 0x5a24040 is 0 bytes inside a block of size 10 free'd
==22786== at 0x4C2BBAF: operator delete[](void*) (vg_replace_malloc.c:649)
==22786== by 0x40082C: func() (mixed.cpp:10)
==22786== by 0x400851: main (mixed.cpp:18)
==22786== Block was alloc'd at
==22786== at 0x4C2AC58: operator new[](unsigned long) (vg_replace_malloc.c:431)
==22786== by 0x4007EE: func() (mixed.cpp:5)
==22786== by 0x400851: main (mixed.cpp:18)
==22786==
==22786== Use of uninitialised value of size 8 // 非法指针
==22786== at 0x400844: func() (mixed.cpp:14)
==22786== by 0x400851: main (mixed.cpp:18)
==22786==
==22786==
==22786== Process terminating with default action of signal 11 (SIGSEGV): dumping core
==22786== Bad permissions for mapped region at address 0x4008B0
==22786== at 0x400844: func() (mixed.cpp:14)
==22786== by 0x400851: main (mixed.cpp:18)
==22786==
==22786== HEAP SUMMARY:
==22786== in use at exit: 0 bytes in 0 blocks
==22786== total heap usage: 1 allocs, 2 frees, 10 bytes allocated
==22786==
==22786== All heap blocks were freed -- no leaks are possible
==22786==
==22786== Use --track-origins=yes to see where uninitialised values come from
==22786== For lists of detected and suppressed errors, rerun with: -s
==22786== ERROR SUMMARY: 4 errors from 4 contexts (suppressed: 0 from 0)
Segmentation fault (core dumped)
可见valgrind将上述几种情况都检测出来了。
2) Callgrind
和gprof类似的分析工具,但它对程序的运行观察更为入微,能给我们提供更多的信息。和gprof不同的是,它不需要在编译源代码时附加特殊选项,但还是推荐加上调试选项。Callgrind收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件。callgrind_annotate可以把这个文件的内容转化成可读的形式。
测试程序
#include <stdio.h>
#include <unistd.h>
void test() {
sleep(1);
}
void func() {
for(int i = 0; i < 10; i++) {
test();
}
}
int main() {
func();
printf("process is over!\n");
return 0;
}
编译后,用valgrind检测程序。
$ g++ -g -o test callgrind.cpp
$ valgrind --tool=callgrind ./test
$ ls
callgrind.cpp callgrind.out.3490 test
callgrind.out.3490就是callgrind生成的文件。
这里介绍一个图形化性能分析工具Kcachegrind
下载安装后可以用来分析callgrind生成的文件。
用Kcachegrind打开callgrind.out.3490这个文件,如下图:
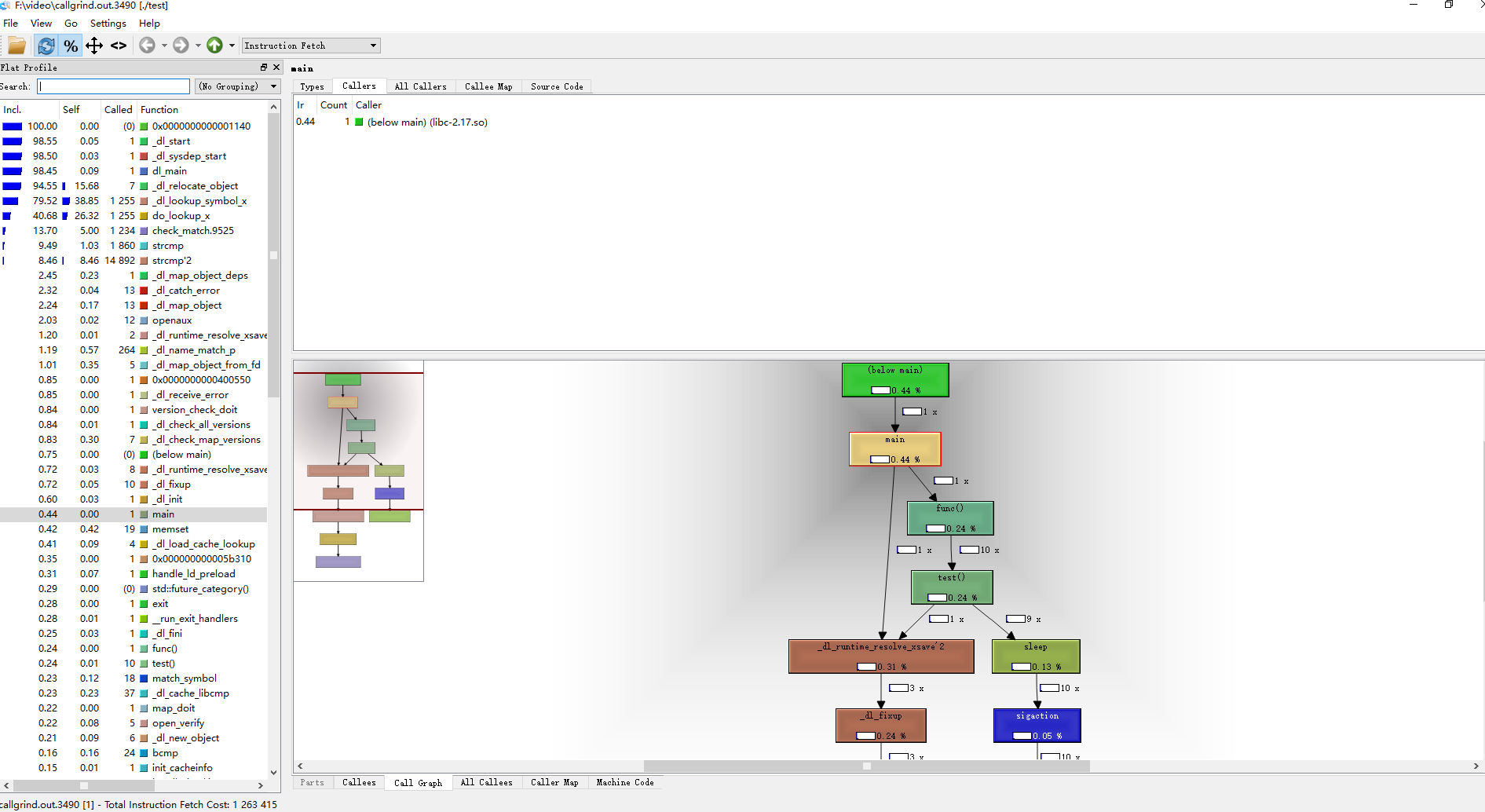
通过图形化,我们可以很直观的知道哪段程序执行慢,并且了解相关调用关系。
3) Cachegrind
Cache分析器,它模拟CPU中的一级缓存和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助。
它的使用方法也是:valgrind –tool=cachegrind ./程序名
4) Helgrind
它主要用来检查多线程程序中出现的竞争问题。Helgrind寻找内存中被多个线程访问,而又没有一贯加锁的区域,这些区域往往是线程之间失去同步的地方,而且会导致难以发觉的错误。Helgrind实现了名为Eraser的竞争检测算法,并做了进一步改进,减少了报告错误的次数。不过,Helgrind仍然处于实验状态。
测试代码:
#include <stdio.h>
#include <pthread.h>
#define NUM 10
int counter = 0;
void *threadfunc(void*) {
for (int i = 0; i < NUM; i++) {
counter += i;
}
}
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, &threadfunc, NULL);
pthread_create(&tid2, NULL, &threadfunc, NULL);
// wait for thread to terminate
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("counter = %d\n", counter);
return 0;
}
编译后,用valgrind检测程序。
$ g++ -g -o test helgrind.cpp -lpthread
$ valgrind --tool=helgrind ./test
检测结果:
==27722== Helgrind, a thread error detector
==27722== Copyright (C) 2007-2017, and GNU GPL'd, by OpenWorks LLP et al.
==27722== Using Valgrind-3.16.1 and LibVEX; rerun with -h for copyright info
==27722== Command: ./test
==27722==
==27722== ---Thread-Announcement------------------------------------------
==27722==
==27722== Thread #3 was created
==27722== at 0x597589E: clone (in /usr/lib64/libc-2.17.so)
==27722== by 0x4E43059: do_clone.constprop.4 (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x4E44569: pthread_create@@GLIBC_2.2.5 (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x4C30CFA: pthread_create_WRK (hg_intercepts.c:425)
==27722== by 0x4C31DD8: pthread_create@* (hg_intercepts.c:458)
==27722== by 0x400728: main (helgrind.cpp:17)
==27722==
==27722== ---Thread-Announcement------------------------------------------
==27722==
==27722== Thread #2 was created
==27722== at 0x597589E: clone (in /usr/lib64/libc-2.17.so)
==27722== by 0x4E43059: do_clone.constprop.4 (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x4E44569: pthread_create@@GLIBC_2.2.5 (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x4C30CFA: pthread_create_WRK (hg_intercepts.c:425)
==27722== by 0x4C31DD8: pthread_create@* (hg_intercepts.c:458)
==27722== by 0x40070D: main (helgrind.cpp:16)
==27722==
==27722== ----------------------------------------------------------------
==27722==
==27722== Possible data race during read of size 4 at 0x601048 by thread #3
==27722== Locks held: none
==27722== at 0x4006CE: threadfunc(void*) (helgrind.cpp:9)
==27722== by 0x4C30EEE: mythread_wrapper (hg_intercepts.c:387)
==27722== by 0x4E43EA4: start_thread (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x59758DC: clone (in /usr/lib64/libc-2.17.so)
==27722==
==27722== This conflicts with a previous write of size 4 by thread #2
==27722== Locks held: none
==27722== at 0x4006D9: threadfunc(void*) (helgrind.cpp:9)
==27722== by 0x4C30EEE: mythread_wrapper (hg_intercepts.c:387)
==27722== by 0x4E43EA4: start_thread (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x59758DC: clone (in /usr/lib64/libc-2.17.so)
==27722== Address 0x601048 is 0 bytes inside data symbol "counter"
==27722==
==27722== ----------------------------------------------------------------
==27722==
==27722== Possible data race during write of size 4 at 0x601048 by thread #3
==27722== Locks held: none
==27722== at 0x4006D9: threadfunc(void*) (helgrind.cpp:9)
==27722== by 0x4C30EEE: mythread_wrapper (hg_intercepts.c:387)
==27722== by 0x4E43EA4: start_thread (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x59758DC: clone (in /usr/lib64/libc-2.17.so)
==27722==
==27722== This conflicts with a previous write of size 4 by thread #2
==27722== Locks held: none
==27722== at 0x4006D9: threadfunc(void*) (helgrind.cpp:9)
==27722== by 0x4C30EEE: mythread_wrapper (hg_intercepts.c:387)
==27722== by 0x4E43EA4: start_thread (in /usr/lib64/libpthread-2.17.so)
==27722== by 0x59758DC: clone (in /usr/lib64/libc-2.17.so)
==27722== Address 0x601048 is 0 bytes inside data symbol "counter"
==27722==
counter = 90
==27722==
==27722== Use --history-level=approx or =none to gain increased speed, at
==27722== the cost of reduced accuracy of conflicting-access information
==27722== For lists of detected and suppressed errors, rerun with: -s
==27722== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 0 from 0)
从上述结果知道,valgrind分析出了竞态的情况。
5) Massif
堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。Massif能帮助我们减少内存的使用,在带有虚拟内存的现代系统中,它还能够加速我们程序的运行,减少程序停留在交换区中的几率。
Massif对内存的分配和释放做profile。程序开发者通过它可以深入了解程序的内存使用行为,从而对内存使用进行优化。这个功能对C++尤其有用,因为C++有很多隐藏的内存分配和释放。
此外,lackey 和 nulgrind 也会提供。Lackey 是小型工具,很少用到;Nulgrind 只是为开发者展示如何创建一个工具。我们就不做介绍了。
参考列表:
Linux 下利用 valgrind工具进行内存泄露检测和性能分析
利用性能分析工具valgrind+KCachegrind分析

|
本文作者:zhuyong 原文链接:https://zhuyongchn.github.io 关于博主:欢迎关注左侧公众号,获取更多干货。 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处! |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号