Python数据分析与展示(学习笔记)
1.Python语言开发工具选择
①IPython
-
IPython是一个功能强大的交互式she11适合进行交互式数据可视化和GUI相关应用
-
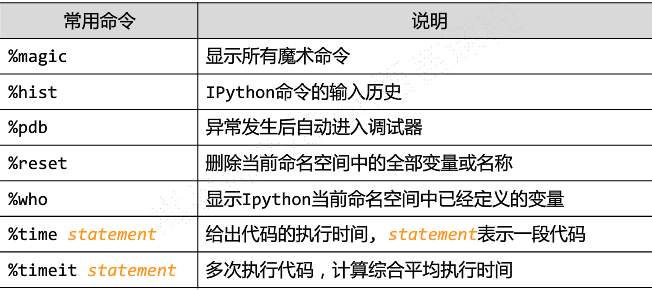
IPython的%魔术命令
a = np.random.randn(1000, 1000)
%timeit np.dot(a, a)
10 loops, best of 3: 85.7 ms per loop
%who
a np
%hist
%who
import numpy as np
a = np.arrange(10)
print(a)
IPython前台解释脚本 Python解释器对程序进行执行
2.Numpy库入门
①数据维度
-
一维数据
- 一维数据由对等关系的有序或无序数据构成,采用线性方式组织
- 对应列表、数组和集合等概念

-
列表与数组(一组数据的有序结构)
- 区别
- 列表:数据类型可以不同
- 数组:数据类型相同
- 区别
-
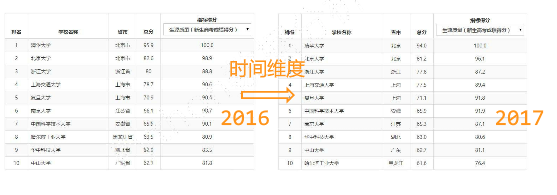
二维数据
- 二维数据由多个—维数据构成,是一维数据的组合形式
- 表格是典型的二维数据其中,表头是二维数据的一部分
-
多维数据
- 多维数据由一维或二维数据在新维度上扩展形成
-
高维数据
- 高维数据仅利用最基本的二元关系展示数据间的复杂结构

②数据维度的 Python表示
-
一维数据:列表和集合类型
-
二维数据:列表类型
-
多维数据:列表类型
-
高维数据:字典类型或数据表示格式, JSON、XML和YAML格式



③NumPy的数据对象:ndarray
(1)NumPy介绍
-
NumPy是一个开源的 Python科学计算基础库,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合C/C++/ Fortran代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
-
NumPy是 SciPy、 Pandas等数据处理或科学计算库的基础
(2)NumPy的引用
import numpy as np
(3)N维数组对象:ndarray
-
Python已有列表类型,为什么需要一个数组对象(类型)?
- 数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据
- 设置专门的数组对象,经过优化,可以提升这类应用的运算速度
-
科学计算中,一个维度所有数据的类型往往相同
- 数组对象采用相同的数据类型,有助于节省运算和存储空间
-
🔴 ndarray是一个多维数组对象,由两部分构成:
- 实际的数据
- 描述这些数据的元数据(数据维度、数据类型等)
-
ndarray数组一般要求所有元素类型相同(同质),数组下标从开始
(4)ndarray实例
#ndarray在程序中的别名是:array
a = np.array([[0, 1, 2, 3, 4],
[9, 8, 7, 6, 5]]) #np.array()生成一个ndarray数组
a
"""out:array([0, 1, 2, 3, 4],
[9, 8, 7, 6, 5]) """
print(a) #np.array()输出成[]形式,元素由空格分割
"""([0, 1, 2, 3, 4],
[9, 8, 7, 6, 5]) """
(5)ndarray对象的属性
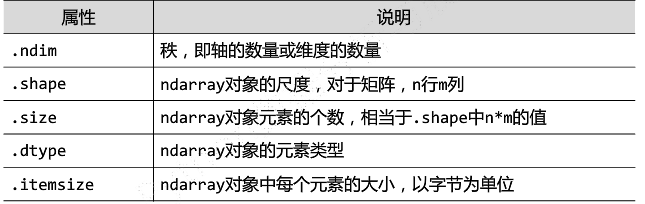
#ndarray实例
a = np.array([[0, 1, 2, 3, 4],
[9, 8, 7, 6, 5]])
a.ndim
#2
a.shape
#(2, 5)
a.size
#10
a.dtype
#dtype('int32')
a.itemsize
#4
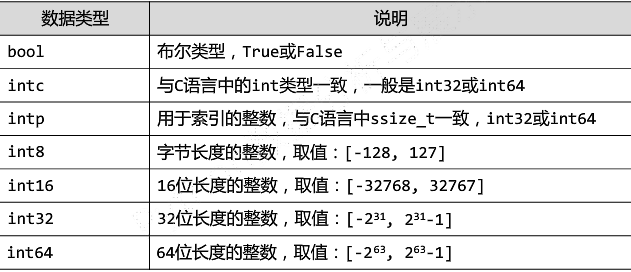
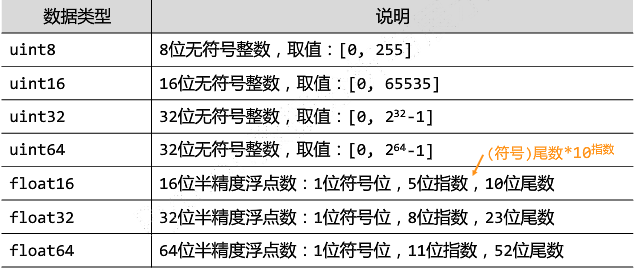
(6)ndarray的元素类型
-
整数
-
浮点数
-
复数

(7)非同质的 ndarray对象
- ndarray数组可以由非同质对象构成
- 非同质 ndarray对象无法有效发挥 NumPy优势,尽量避免使用
(8)ndarray数组的创建方法
-
从 Python中的列表、元组等类型创建 ndarray数组
#语法 x = np.array(list/tuptle) x = np.array(list/tuptle, dtype = np.float32) #np.array()不指定dtype时, NumPy将根据数据情况进行关联一个dtype类型#示例 x = np.array([0, 1, 2, 3]) #从列表类型创建 print(x) #[0 1 2 3] x = np.array((4, 5, 6, 7)) #从元组类型创建 print(x) #[4 5 6 7] x = np.array([[1, 2], [9, 8], (0.1, 0.2)]) #从列表和元组混合类型创建 print(x) """[[1. 2.] [9. 8.] [0.1 0.2]]""" -
使用 NumPy中函数创建 ndarray数组,如:arange, ones, zeros等


np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- 使用 NumPy中其他函数创建 ndarray数组

<!--linsapce默认生成浮点数-->

##### (9)ndarray数组的变换
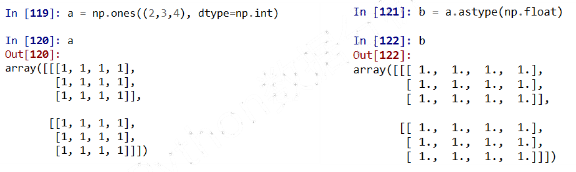
- 对于创建后的 ndarray数组,可以对其进行维度变换和元素类型变换
a = np.ones((2, 3, 4), dtype = np.int32)
- ndarray数组的维度变换
- 
- 
- 
- ndarray数组的类型变换
new_a = a.astype(new_type)
- astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型—致
- 
- ndarray数组向列表的转换
ls = a.tolist()

##### (10)ndarray数组的操作
- 索引:获取数组中特定位置元素的过程
- 切片:获取数组元素子集的过程
- 一维数组的索引和切片:与 Python的列表类似

- 多维数组的索引
- 
- 多维数组的切片
- 
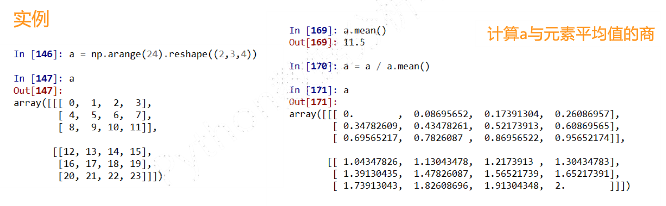
##### (11)数组与标量之间的运算
- 数组与标量之间的运算作用于数组的每一个元素
##### (12)NumPy一元函数
- 对 ndarray中的数据执行元素级运算的函数


- NumPy一元函数实例

- NumPy二元函数实例

### 3.数据存取与函数
#### ①数据的CSV文件存取
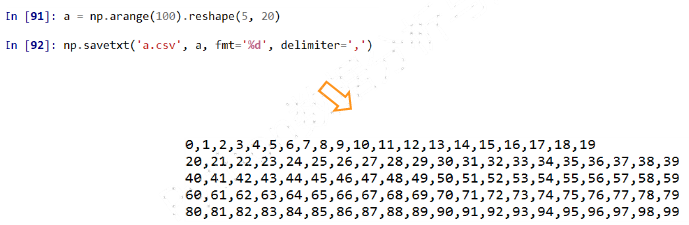
##### (1)CSV文件
- CSV是一种常见的文件格式,用来存储批量数据
```python
np.savetxt(frame, array, fmt= '%.18e', delimiter=None)
#frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
#array:存入文件的数组
#fmt:写入文件的格式,例如: %d %.2f %.18e
#delimiter:分割字符串,默认是任何空格
np.loadtxt(frame, dtype=np.float, delimiter=None, uppack=False)
#frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
#dtype:数据类型,可选
#delimiter:分割字符串,默认是任何空格
#unpack:如果True,读入属性将分别写入不同变量
- 示例
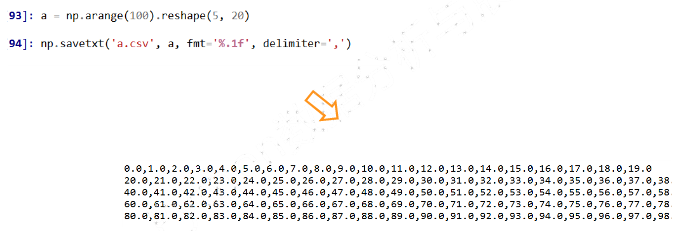

(2)CSV文件的局限性
- CSV只能有效存储一维和二维数组
- np. savetxt()np. loadtxt()只能有效存取一维和二维数组
(3)多维数据的存取
-
任意维度数据如何存取
a.tofile(frame, sep='', format='%s') #frame:文件、字符串 #sep:数据分割字符串,如果是空串,写入文件为二进制 #format:写入数据的格式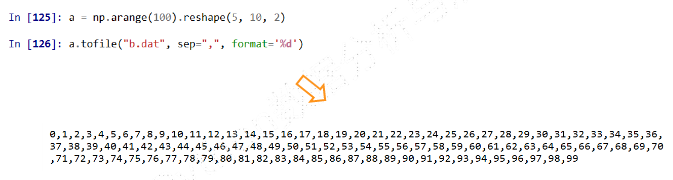

np.fromfile(frame, dtype=float, count=-1, sep='')
#frame:文件、字符串
#dtype:读取的数据类型
#count:读入元素个数,-1表示读入整个文件
#sep:数据分割字符串,如果是空串,写入文件为二进制

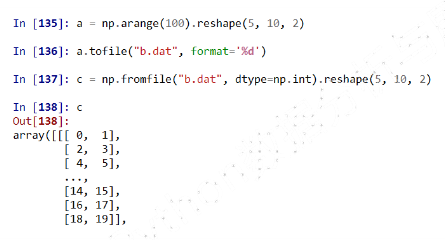
②NumPy的便捷文件存取
np.save(frame, array) 或 np.savez(fname, array)
#frame:文件名,以.npy为扩展名,压缩扩展名为npz
#array:数组变量
np.load(frame)
#fname:文件名,以.npy为扩展名,压缩扩展名为.npz
③NumPy的随机数函数
(1)NumPy的随机数函数子库
-
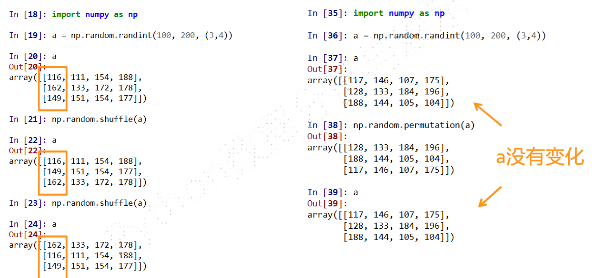
NumPy的 random子库
np.random.* np.random.rand np.random.randn()
-
示例


-
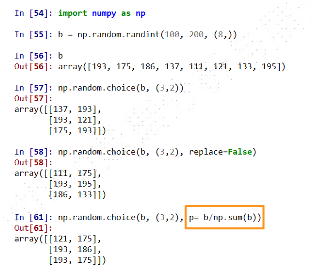
np. random的随机数函数(2)

-
示例
-
-
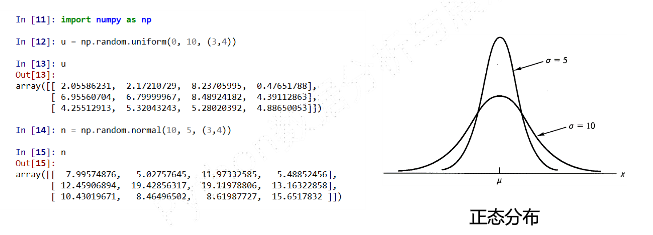
np. random的随机数函数(3)

-
示例
-
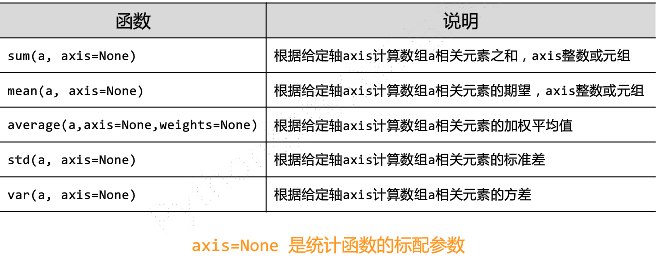
④NumPy的统计函数
#NumPy直接提供的统计类函数
np.*
np.std()
np.var()
np.average()
-
NumPy的统计函数(1)
-
示例

-
-
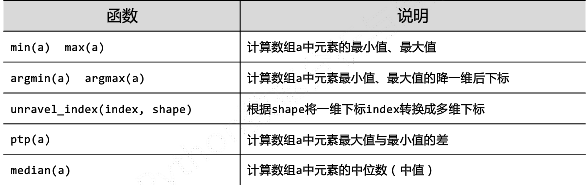
NumPy的统计函数(2)
-
示例

-
⑤NumPy的梯度函数
-

- 梯度:连续值之间的变化率,即斜率
- XY坐标轴连续三个X坐标对应的γ轴值:a, b, c,其中,b的梯度是:(c-a)/2
-
示例


4.Matplotlib库入门
①简介
-
matplotlib. pyplot是绘制各类可视化图形的命令子库,相当于快捷方式import matplotlib.pyplot as plt() #引入模块的别名 -
示例
-
plt.plot()只有一个输入列表或数组时,参数被当作Y轴,X轴以索引自动生成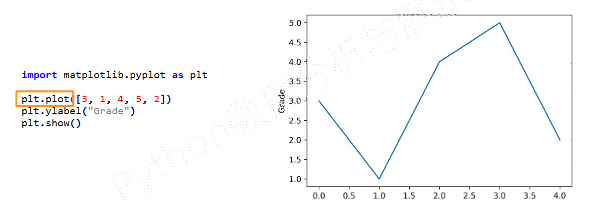
-
plt. savefig()将输出图形存储为文件,默认PNG格式,可以通过dpi修改输出质量
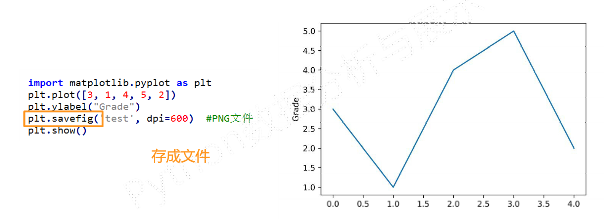
-
plt.plot(x, y)当有两个以上参数时,按照X轴和Y轴顺序绘制数据点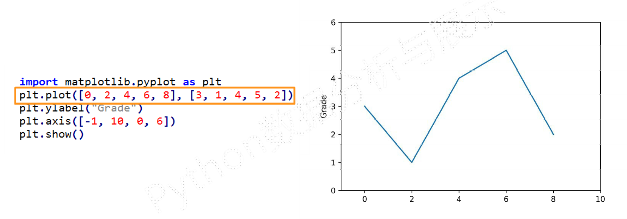
-
-
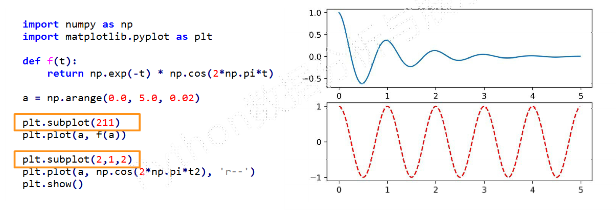
pyplot的绘图区域#在全局绘图区域中创建一个分区体系,并定位到一个子绘图区域 plt.subplot(nrow, ncols, plot_number) plt.subplot(3, 2, 4) plt.subplot(324)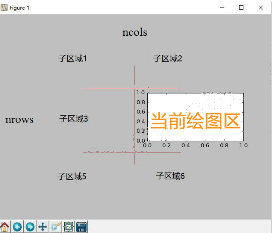
②pyplot的 plot函数
-
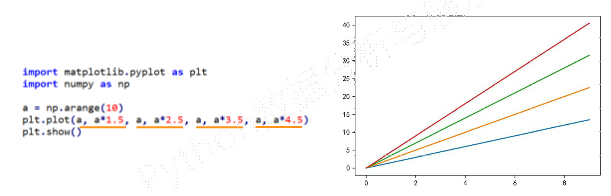
plt.plot(x, y, format_string, **kwargs) #x:X轴数据,列表或数组,可选 #y:Y轴数据,列表或数组 #format_string:控制曲线的格式字符串,可选 #**kwargs:第二组或更多(x,y, format string)-
-
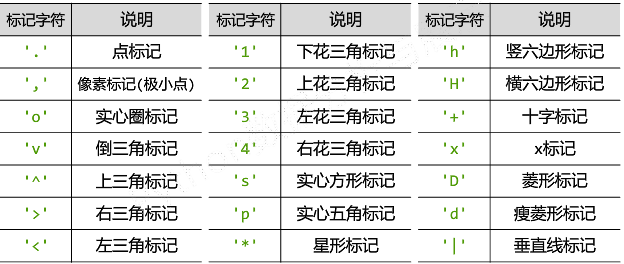
format_string:控制曲线的格式字符串,可选。由颜色字符、风格字符和标记字符组成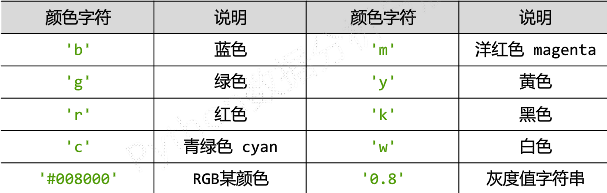
<img src="https://img2020.cnblogs.com/blog/2266693/202101/2266693-20210112191342615-354107141.png" alt="image-20200915212822056" style="zoom: 80%;" />
-
-
颜色字符、风格字符和标记字符可以组合使用
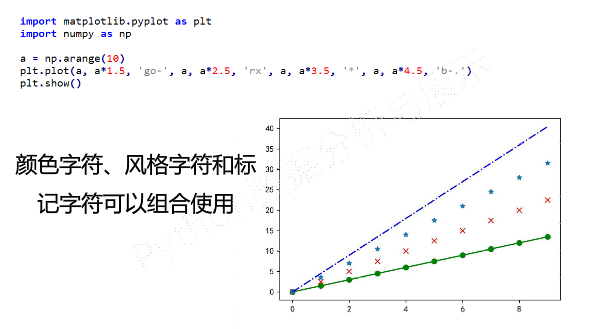
-
**kwargs:第二组或更多(x,y, format string)

③pyplot的中文显示
(1)第一种方法
-
pyplot并不默认支持中文显示,需要 paRams修改字体实现
-
示例
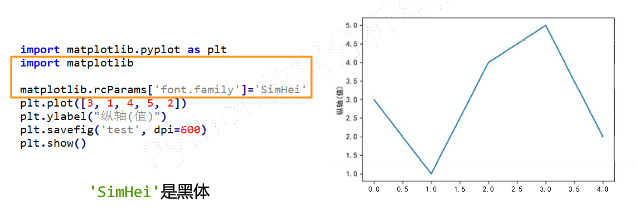
-
rcParams的属性
-
中文字体的种类
reParams['font.family']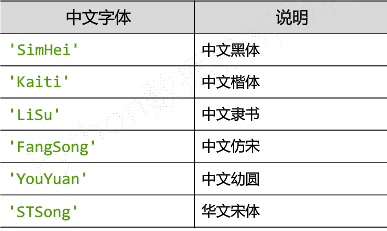
-
示例
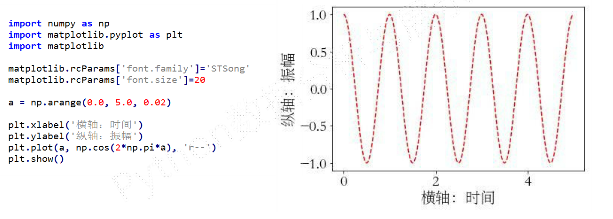
-
-
(2)第二种方法
-
在有中文输出的地方,增加一个属性:
fontproperties -
示例

④pyplot的文本显示
(1)pyplot的文本显示函数
-
函数
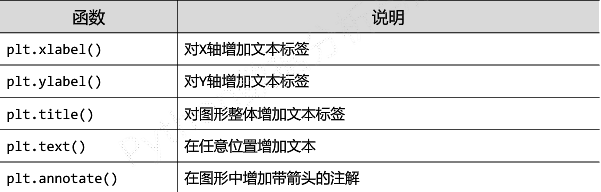
-
示例
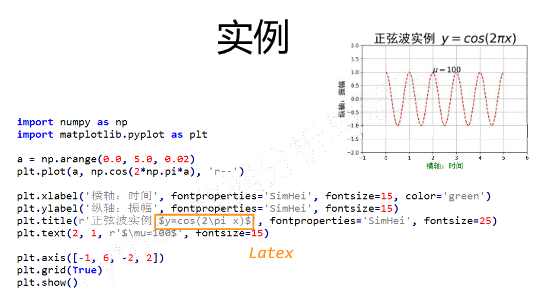
-
plt.annotate(s, xy=arrow_crd, xytext=text_crd, arrowprops=dict)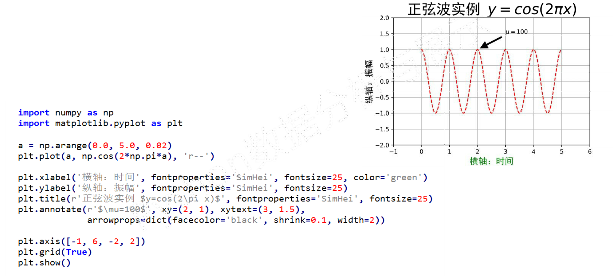
5.Matolotlib基础绘图函数
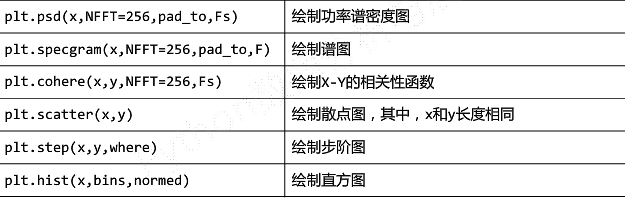
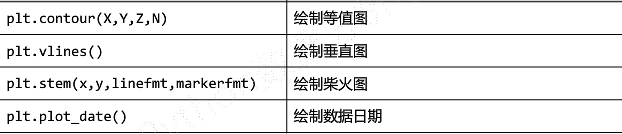
①基础图标函数
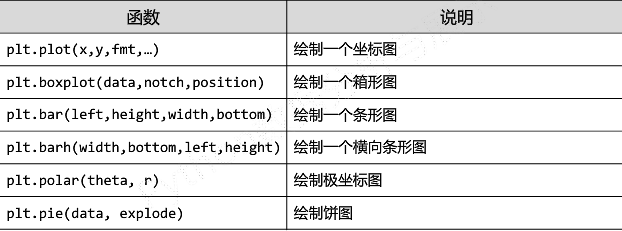
②pyplot饼图的绘制
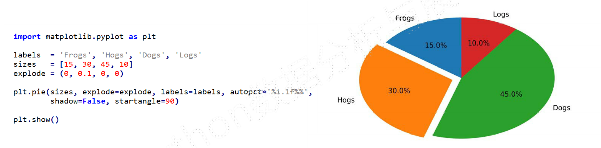
plt.pie()

③pyplot直方图的绘制
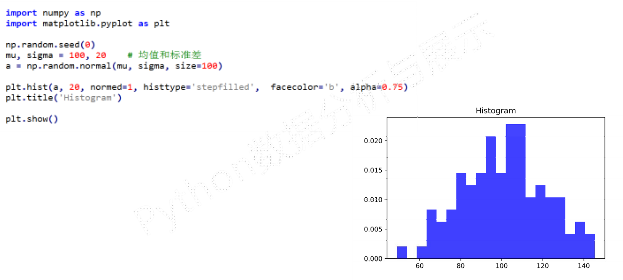
plt.hist()
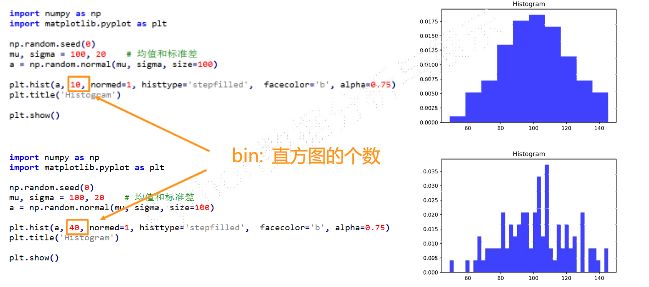
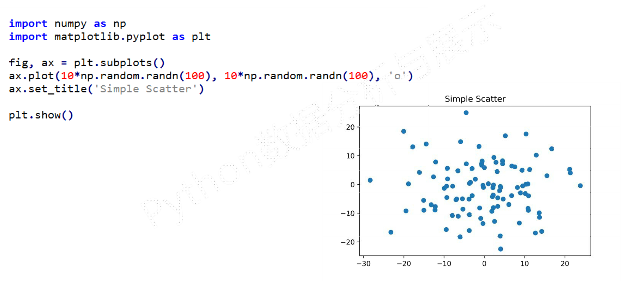
④pyplot散点图的绘制
-
面向对象绘制散点图
6.Pandas库入门
①简介
-
Pandas是Python第三方库,提供高性能易用数据类型和分析工具 -
引入
-
import pandas as pd
-
-
Pandas基于NumPy实现,常与NumPy和Matplot1ib一同使用
②Pandas库的理解
- 两个数据类型:
Series, DataFrame
| Numpy | Pandas |
|---|---|
| 基础数据类型 | 扩展数据类型 |
| 关注数据的结构表达 | 关注数据的应用表达 |
| 维度:数据间关系 | 数据与索引间关系 |
③Pandas库的Series类型
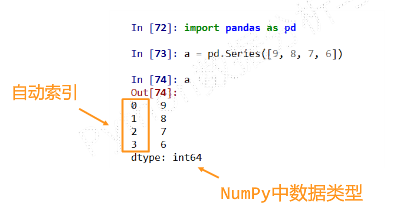
(1)Series类型
-
Series类型由一组数据及与之相关的数据索引组成 -
Series是一维带“标签”数组 -
Series基本操作类似ndarray和字典,根据索引对齐-

-
自动索引
-
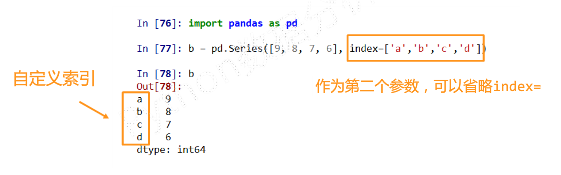
自定义索引
-
-
Series类型的创建Python列表Python列表,index与列表元素个数一致
- 标量值
- 标量值,
index表达Series类型的尺寸 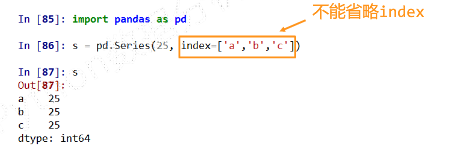
- 标量值,
- 从
Python字典类型创建Python字典,键值对中的“键”是索引,index从字典中进行选择操作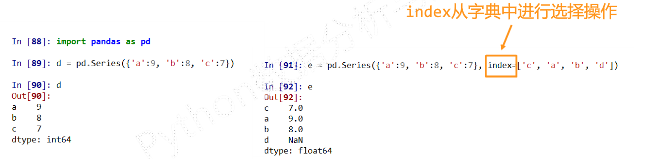
- 从
ndarray类型创建ndarray,索引和数据都可以通过ndarray类型创建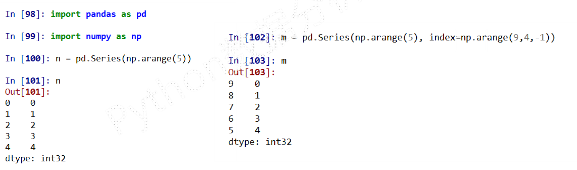
- 其他函数
- 其他函数,
range()函数等
- 其他函数,
(2)Series类型的基本操作
-
示例
-
-
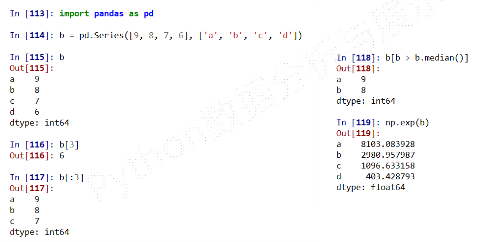
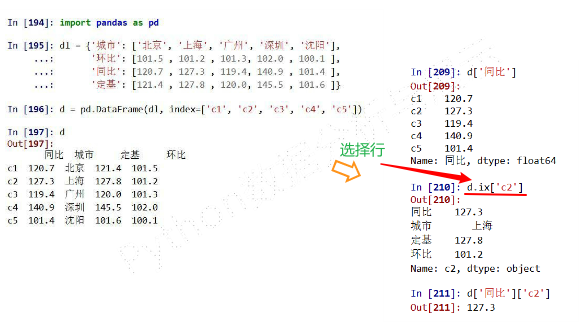
Series类型的操作类似ndarray类型:- 索引方法相同,采用【】
- NumPy中运算和操作可用于 Series类型
- 可以通过自定义索引的列表进行切片
- 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
-
Series类型的操作类似Python字典类型: -
通过自定义索引访问
-
保留字
in操作 -
使用
get()方法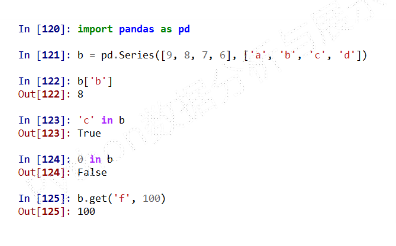
-
Series类型对齐操作


Series + Series
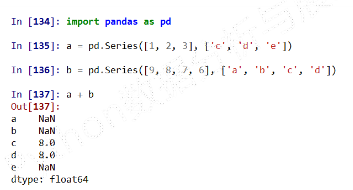
Series类型在运算中会自动对齐不同索引的数据
-
Series类型的name属性-
Series对象和索引都可以有一个名字,存储在属性.name中-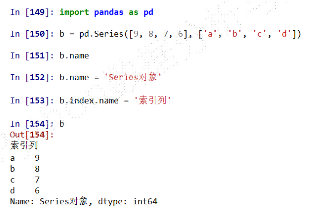
-
-
Series类型的修改-
Series对象可以随时修改并即刻生效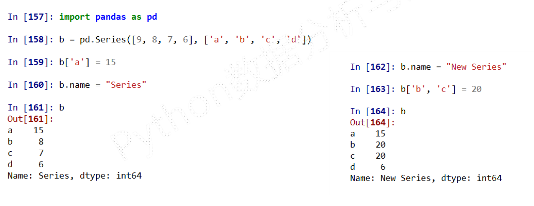
-
④Pandas库的 Dataframe类型
(1)DataFrame类型
-
DataFrame类型由共用相同索引的一组列组成
-
DataFrame是一个表格型的数据类型,每列值类型可以不同 -
DataFrame既有行索引、也有列索引 -
DataFrame常用于表达二维数据,但可以表达多维数据 -

-
Dataframe类型创建-
二维
ndarray对象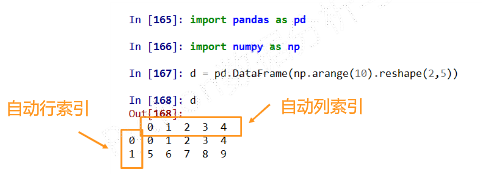
-
由一维
ndarray、列表、字典、元组或Series构成的字典-
从一维
ndarray对象字典创建
-
从列表类型的字典创建
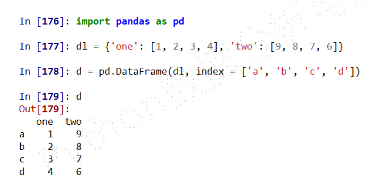
-
-
Series类型 -
其他的
DataFrame类型
-
-
DataFrame是二维带“标签”数组
DataFrame基本操作类似Series,依据行列索引
⑤数据类型操作
(1)增加或重排:重新索引
-
.reindex()能够改变或重排Series和Data frame索引
-
.reindex( index=None, columns=None,……)的参数

(2)删除:drop
-
.drop()能够删除Series和DataFrame指定行或列索引
(3)索引类型
-
Series和Dataframe的索引是Index类型 -
Index对象是不可修改类型
(4)索引类型的常用方法


(5)Pandas库的数据类型运算
-
算术运算法则
- 算术运算根据行列索引,补齐后运算,运算默认产生浮点数
- 补齐时缺项填充
NaN(空值) - 采用
+-*/符号进行的二元运算产生新的对象
-
示例

-

fill value参数替代NaN,替代后参与运算

- 不同维度间为广播运算,一维 Series默认在轴1参与运算

-
使用运算方法可以令一维 Series参与轴0运算

-
比较运算法则
-
比较运算只能比较相同索引的元素,不进行补齐
-
二维和一维、一维和零维间为广播运算
-
采
> < >= <= == !=等符号进行的二元运算产生布尔对象

-
7.Pandas数据特征分析
①Pandas库的数据排序
-
.sort_index()方法在指定轴上根据索引进行排序,默认升序.sort_index(axis = 0, ascending=True)

-
.sort_values()方法在指定轴上根据数值进行排序,默认升序Series.sort_values(axis=0, ascending=True) DataFrame.sort_values(by, axis=0, ascending=True) #by:axis轴上的某个索引或索引列表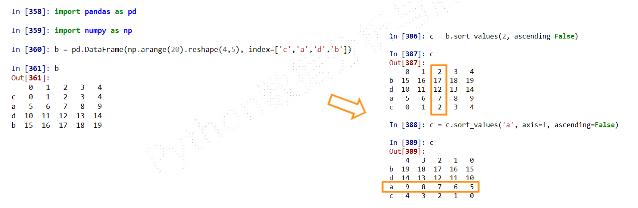
-
NaN统一放到排序末尾
-
②数据的基本统计分析
-
适用于
Series和DataFrame类型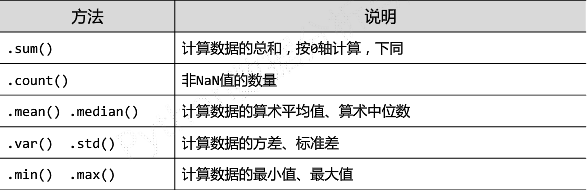

-
适用于
Series类型
-
示例


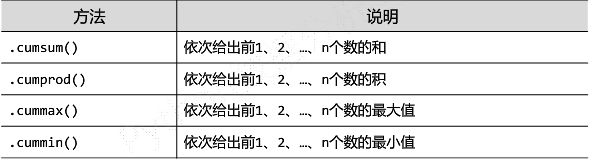
③数据的累计统计分析
-
适用于Series和DataFrame类型,累计计算
- 函数
- 实例
- 函数
-
适用于
Series和DataFrame类型,滚动计算(窗口计算)- 函数
- 实例
- 函数



④数据的相关分析
-
相关性
- x增大,Y增大,两个变量正相关
- x增大,Y减小,两个变量负相关
- X增大,Y无视,两个变量不相关
-
协方差
- 两个事物,表示为X和Y,如何判断它们之间的存在相关性?
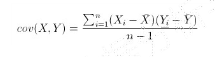
- 协方差 > 0,X和Y正相关
- 协方差 < 0,X和Y负相关
- 协方差=0,X和Y独立无关
- 两个事物,表示为X和Y,如何判断它们之间的存在相关性?
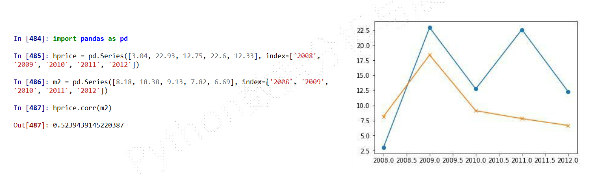
-
Pearson相关系数 -
相关分析函数
- 适用于
Series和Dataframe类型 
- 适用于


 浙公网安备 33010602011771号
浙公网安备 33010602011771号