Mysql-笔记
| MYISAM | INNODB | |
|---|---|---|
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 支持 |
| 表空间大小 | 较小 | 较大,约为2倍 |
常规使用操作:
-
MYISAM : 节约空间,速度快
-
INNODB : 安全性高,事务的处理,多表多用户操作
在物理空间存在的位置区别:
所有的数据库文件都存在data目录下,-一个文件夹就对应-个数据库本质还是文件的存储!
MySQL引擎在物理文件上的区别:
-
InnoDB在数据库表文件中只有一个*.frm,以及上级目录的ibdata1文件
-
MYISAM对应文件
-
*.frm 表结构的定义文件
-
*.MYD 数据文件(data)
-
*.MYI 索引文件(index)
-
设置数据库的字符集编码:
1 charset=utf8
不设置的话,会是mysql默认字符集编码~ (不支持中文)
Mysql的默认编码是Latin1,不支持中文
可以在my.ini中配置默认的编码(不推荐)
1 character-set-server=utf8
2、外键(不建议用数据库实现,建议用程序实现)
最佳实践
-
数据库就是单纯的表,只用来存数据,只有行 (数据) 和列 (字段)
-
我们想使用多张表的数据,想使用外键(程序去实现)
3、select额外查询
1 select version() -- 查询系统版本 2 select 100*3-1 as 计算结果 -- 用来计算 3 select @@auto_increment_increment -- 查询自增的步长
数据库中表达式:文本值,列,Null,函数,计算表达式,系统变量
4、多表个查询解题思路
-
我要查询哪些数据select ... 从那几个表中查 FROM 表 XXX Join 连接的表 on 交叉条件
-
假设存在“种多张表在询,慢慢来,先查询两张表然后再慢慢增加
5、自连接(了解即可)
自己的表和主键的表连接,核心:一张表拆为两张一样的表即可
父类:
| pid(顶级id) | categoryid(自己种类id) | categoryName(种类名) |
|---|---|---|
| 1 | 2 | 信息技术 |
| 1 | 3 | 软件开发 |
| 1 | 5 | 美术设计 |
子类:
| pid(父类id) | categoryid(自己种类id) | categoryName(种类名) |
|---|---|---|
| 3 | 4 | 数据库 |
| 2 | 8 | 办公信息 |
| 3 | 6 | web开发 |
| 5 | 7 | ps技术 |
子类、父类对应的结果:
| 软件开发 | 数据库 |
|---|---|
| 信息技术 | 办公信息 |
| 软件开发 | web开发 |
| 美术设计 | ps技术 |
查询该表的sql为:
1 --查询父子信息 2 SELECT a.、categoryName、AS父栏目', b.、categoryName、AS '子栏目' 3 FROM、category’ AS a, 、category’AS b
Mysql常用函数
8、聚合函数
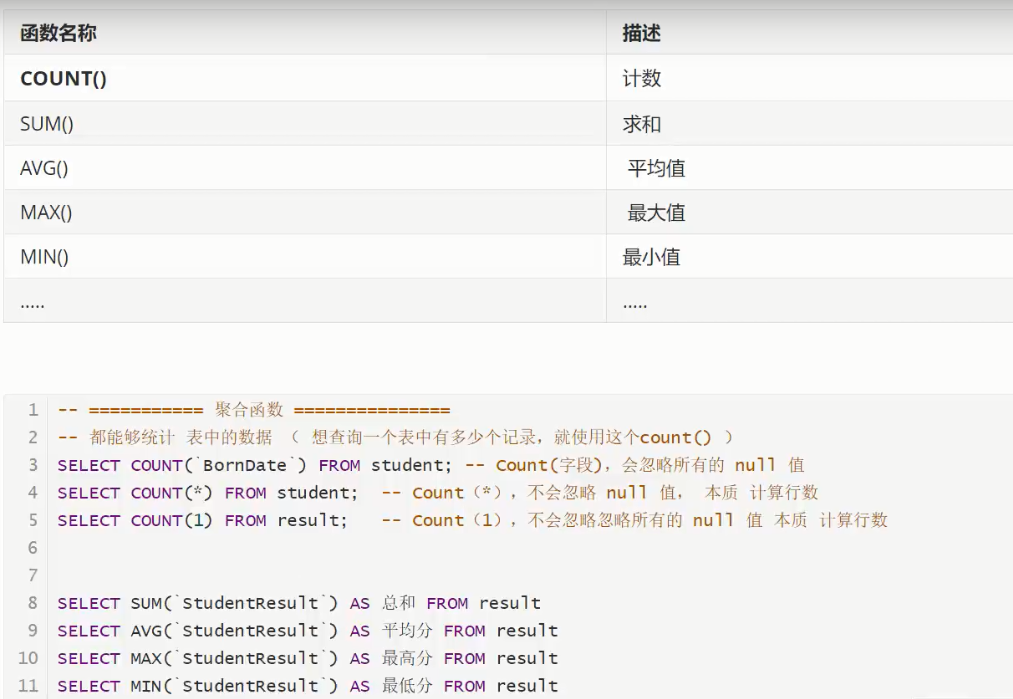
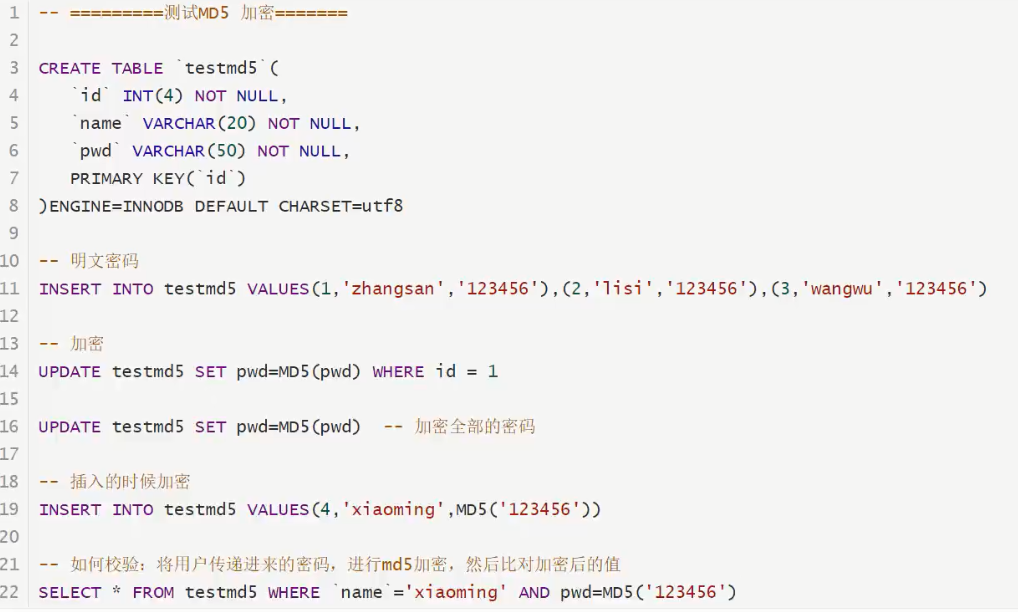
9、数据库md5级加密
什么是MD5?
主要增强算法复杂度和不可逆性。
MD5不可逆,具体的值的md5是一样的
MD5破解网站的原理,背后有一个字典,MD5加密后的值 ,加密的前值
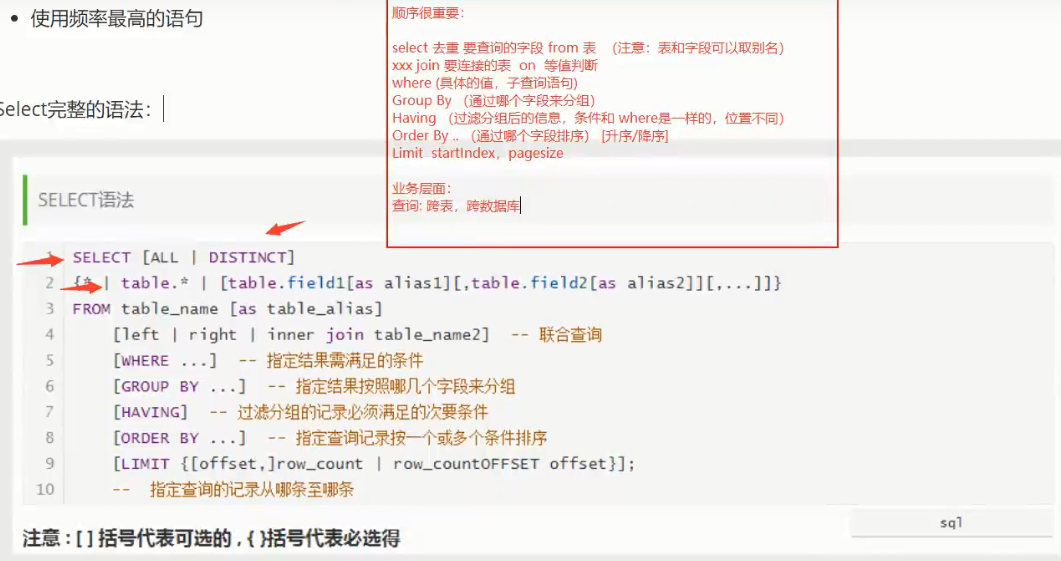
10、selest小结
11、事务
11.1、什么是事务:要么都成功,要么都失败

11.2、事务原则
参考博客链接:https://blog.csdn.net/dengjili/article/details/82468576
ACID原则:
-
原子性(Atomicity):
-
要么都成功,要么都失败。
-
-
一致性 (Consistency):
-
事务前后的数据完整性要保证一致,比如转账,转账前后双方账户钱总数相同。
-
-
持久性(Durability) 事务提交:
-
事务一旦提交则不可逆,被持久化到数据库中!
-
-
隔离性(Isolation):
-
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
-
隔离导致的问题:
-
脏读:指一个事务读取了另外一个事务未提交的数据。
-
不可重复读:在一个事务内读取表中的数据,重复读取表数据发生改变。(这个不一定是错误,只是某些场合不对)
-
虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。(一般是行影响,多了一行)
-
-
使用事务的关键字:

使用事务:

12、索引
提取句子主干,就可以得到索引的本质:索引是数据结构。
12.1、索引的分类

基础语法:

12.2、测试索引:
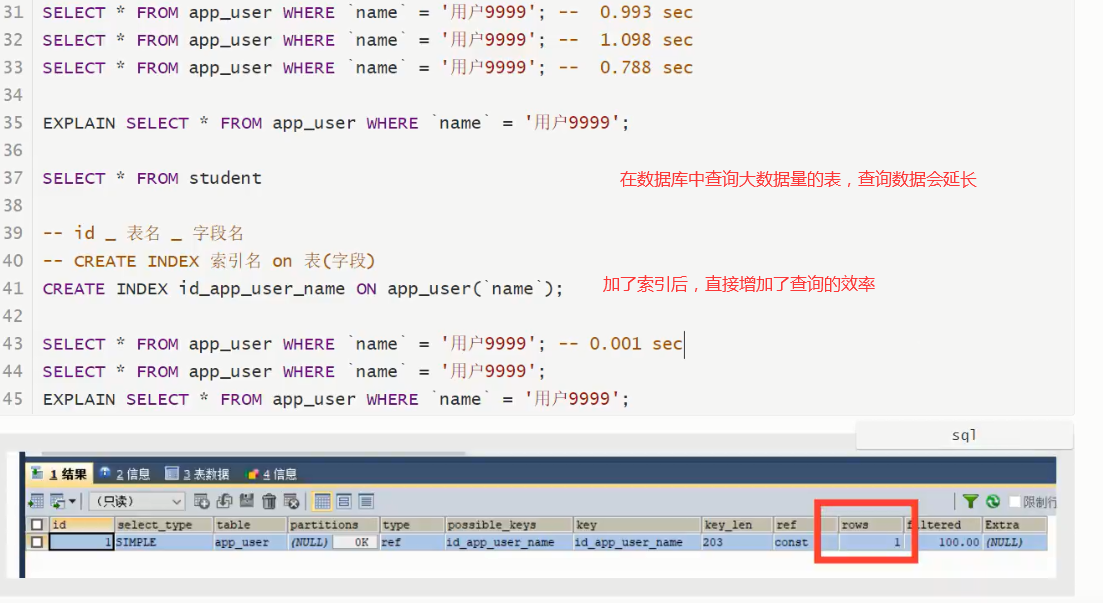
索引在小数据量的时候,用处不大,但是在大数据的时候,区别十分明显~
12.3、索引原则
-
-
不要对进程变动数据加索引
-
小数据量的表不需要加索引
-
索引一般加在常用来查询的字段上!
索引数据结构:hash类型的索引
Btree :InnoDB的默认数据结构~
阅读: http://blog.codiglabs.org/articles/theory-of-mysql-index.html
13、权限管理与备份
13.1、用户管理
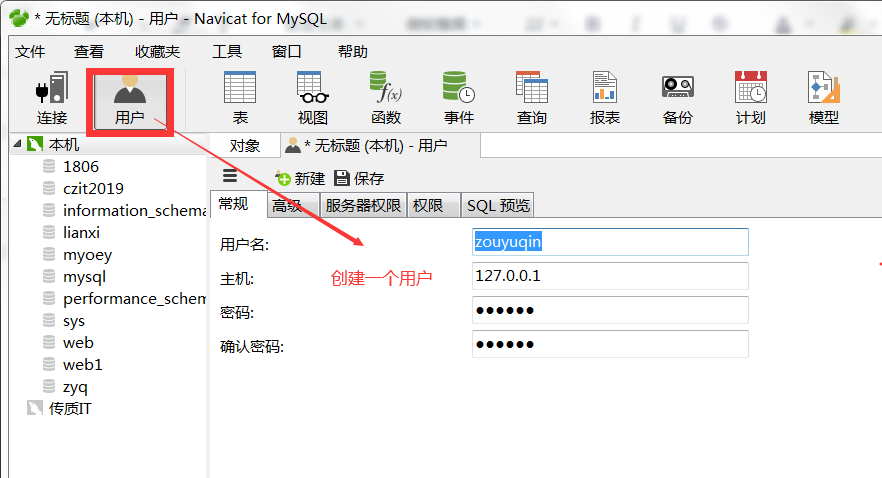
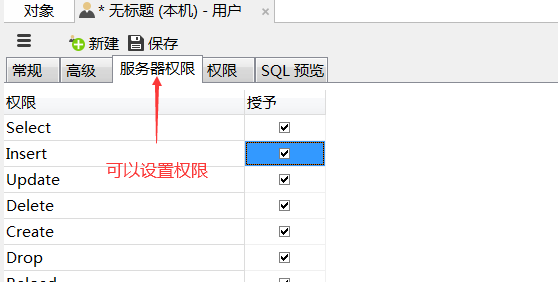
13.2、用户管理使用的sql语句
用户表在mysql数据库中:mysql.user
本质对用户表进行增删改查。
13.3、mysql备份
为什么要备份:
-
保证重要的数据不丢失
-
数据转移
MySQL数据库备份的方式
-
直接拷贝物理文件
-
在Sqlyog 这种可视化工具中手动导出
-
在想要导出的表或者库中,右键,选择备份或导出
![]()
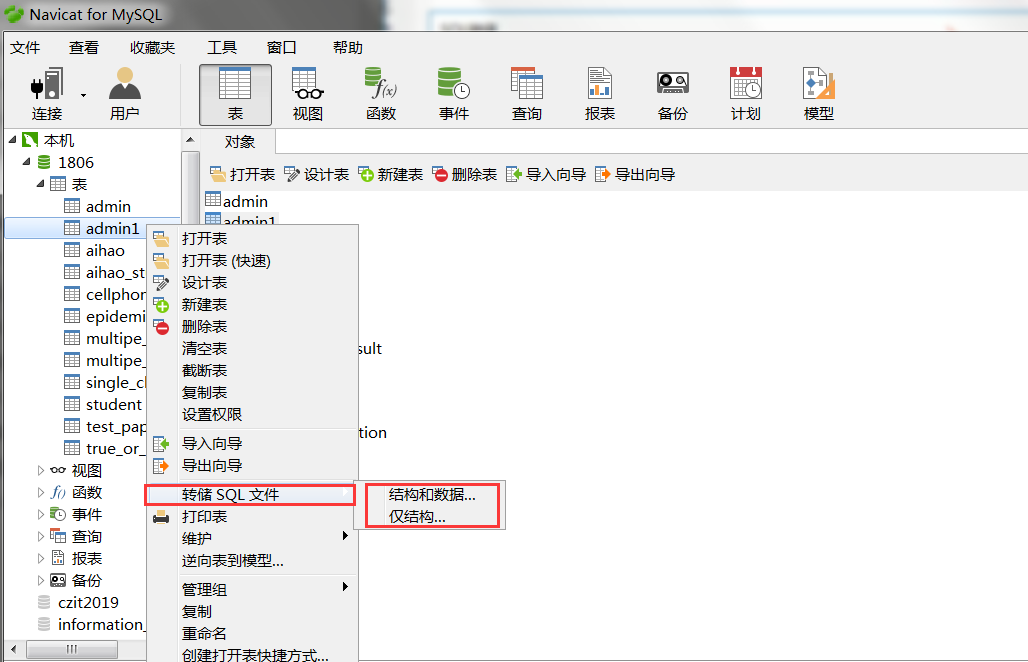
-
使用命令行导出mysqldump 命令行使用
-
![]()
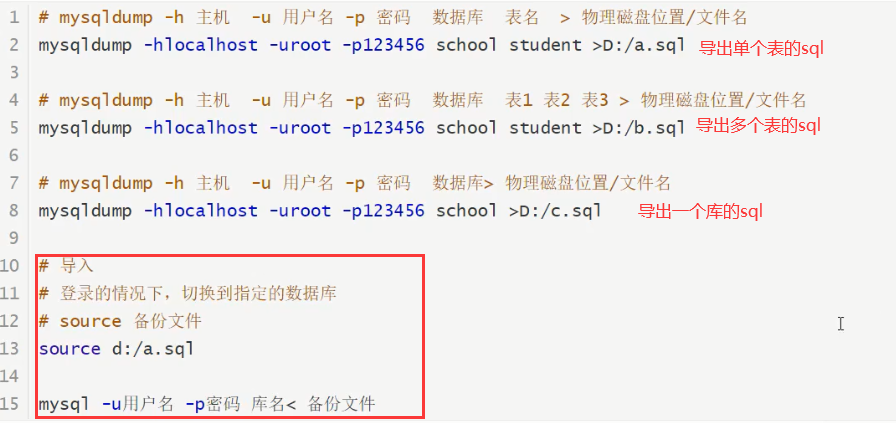
一般用在,要备份数据库,防止数据丢失。
把数据库发给朋友,sql发给别人。
14、规范的数据库设计
14.1、为什么需要设计:当数据库比较复杂时就需要设计
-
槽糕的数据库设计
-
数据冗余,浪费空间
-
数据库插入和删除都会麻烦、异常[ 屏蔽使用物理外键]
-
程序的性能差
-
-
良好的数据库设计
-
节省内存空间
-
保证数据库的完整性
-
方便我们开发系统
-
14.2、如何设计一个数据库
-
分析需求:分析业务和需要处理的数据库的需求
-
概要设计:设计关系图E-R图
设计的步骤:
-
收集信息,分析需求
-
用户表(用户登录注销,用户的个人信息,写博客,创建分类)
-
分类表(文章分类, 谁创建的)
-
文章表(文章的信息)
-
友链表(友链信息)
-
自定义表(系统信息, 某个关键的字,或者-些主字段) key : value
-
-
标识实体(把需求落实到每一个字段上)
-
梳理 标识实体 之间 的(表)关系
14.3、三大范式
为什么需要数据规范化?
-
信息重复
-
更新异常
-
插入异常
-
无法正常显示信息
-
删除异常
-
丢失有效的信息
三大范式:
-
第一范式(1NF)
-
原子性:保证表中每一字段的数据不可再分
-
-
第二范式(2NF)
-
前提:满足第一范式
-
每张表只描述一件事情
-
-
第三范式(3NF)
-
前提:满足一二范式
-
需要确保表中每一字段的数据和主键有直接关系,而不是间接关系
-
三大方式参考资料:https://www.cnblogs.com/wsg25/p/9615100.html

15、JDBC
另一种方式连接数据库:
1.创建配置文件:设置属性
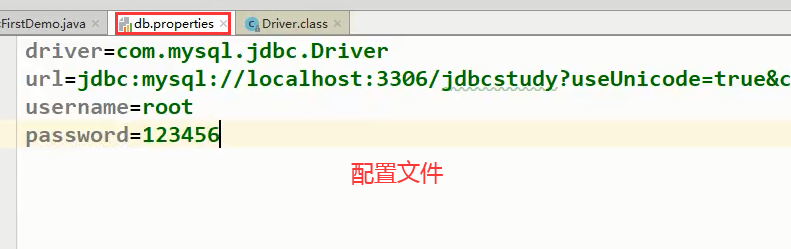
2.工具类读取配置文件的属性
获取到配置文件的资源流:

在用Properties来获取配置文件的信息:
propertiese参考资源: https://blog.csdn.net/amosjob/article/details/82747733

15.1、连接数据库中的url
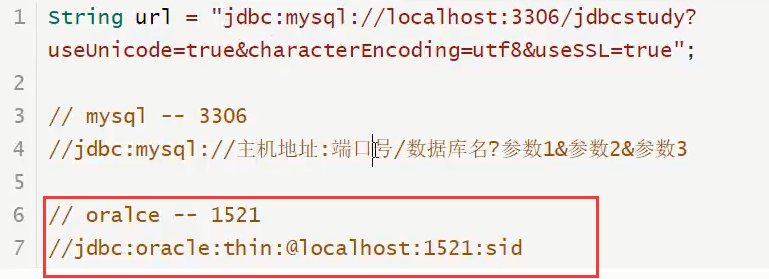
15.2、获取结果集中的方法

16、使用IDEAl连接数据库
1、打开数据库连接窗口
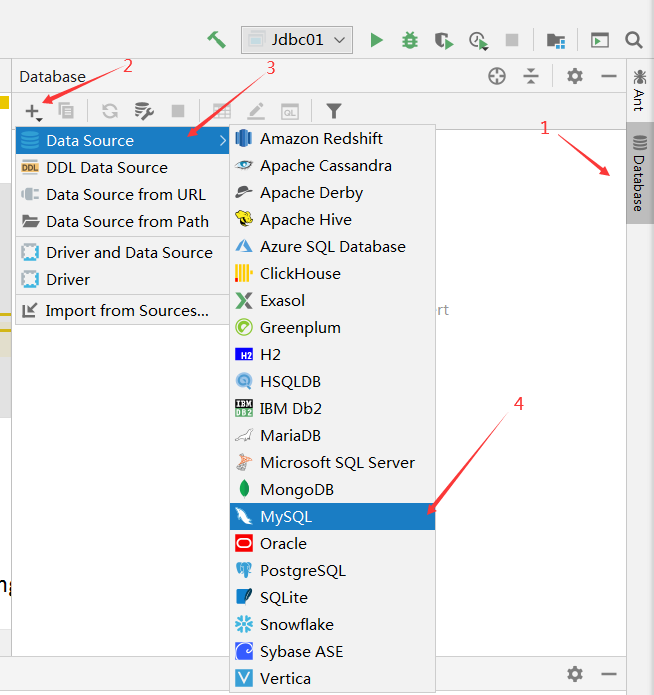
2、输入用户、密码连接数据库
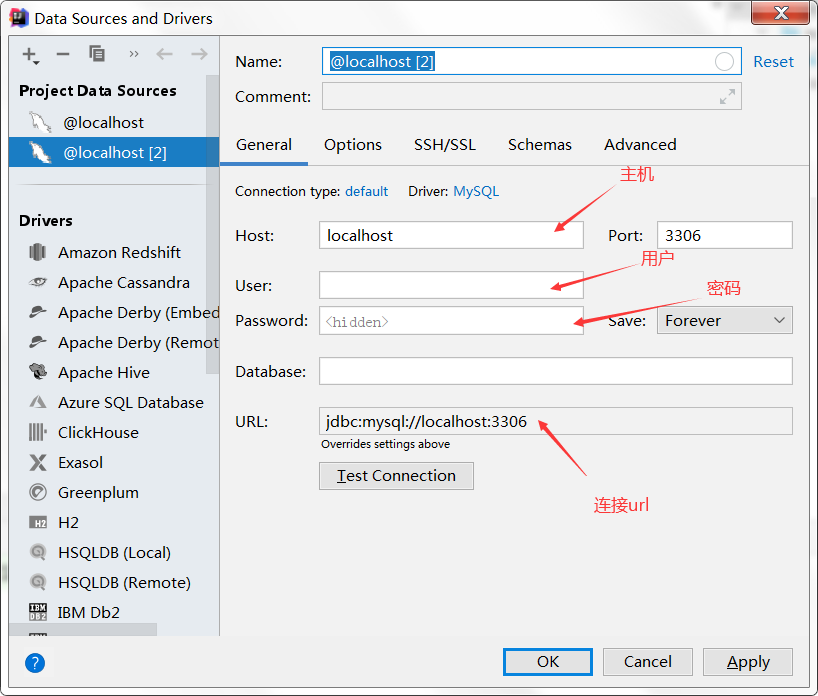
3、选择数据库
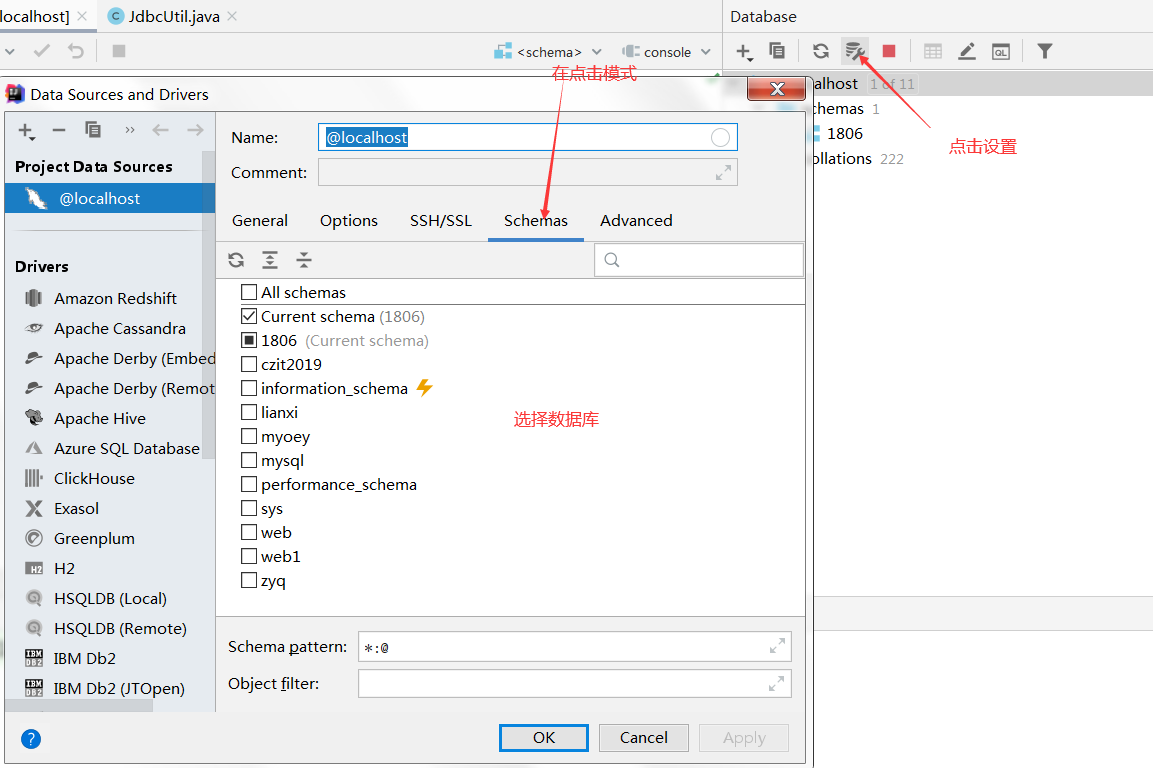
4、操作
-
双击表就可以查看表
-
更改表数据
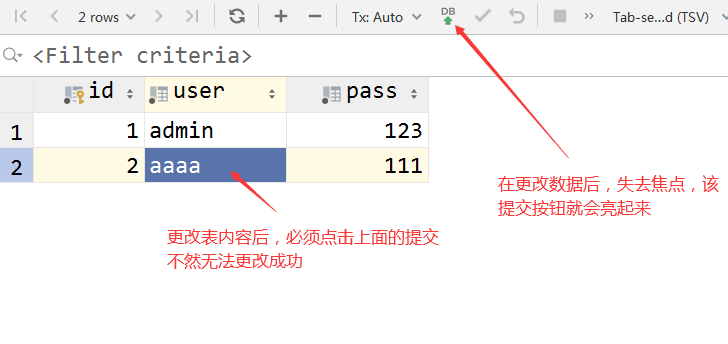
-
控制台操作sql
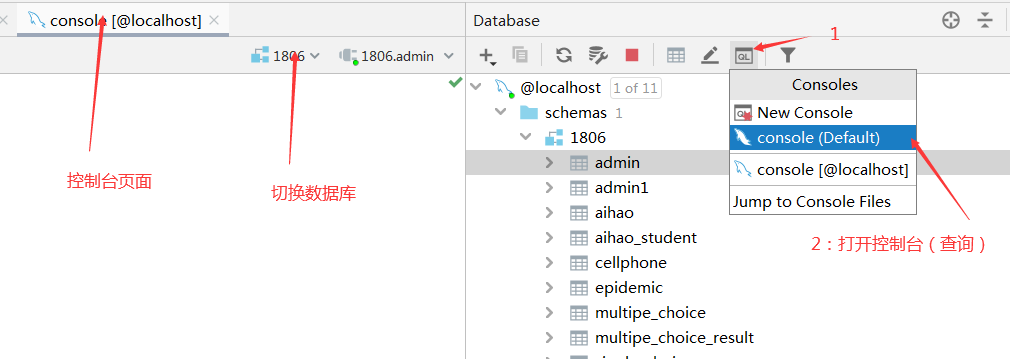
-
JDBC操作事务
-
开启事务con . setAutoCommit(false);
-
一组业务执行完毕,提交事务
-
可以在catch语句中显示的定义回滚语句,但默认失败就会回滚
1 public class Jdbc02 { 2 public static void main(String[] args) { 3 Connection con=null; 4 PreparedStatement pr=null; 5 6 try{ 7 con= JdbcUtil.con(); 8 con.setAutoCommit(false);//关闭数据库自动提交,会自动开启事务 9 10 11 String sql1 = "update amount set money=money-100 where id='A'"; 12 pr=con.prepareStatement(sql1); 13 pr.executeUpdate(); 14 15 String sql2 = "update amount set money=money+100 where id='B'"; 16 pr=con.prepareStatement(sql2); 17 pr.executeUpdate(); 18 19 con.commit();//提交事务 20 System.out.println("成功"); 21 22 } catch (Exception e) { 23 //即使报错不写回滚,程序也会默认回滚 24 try{ 25 con.rollback();//显示是在回滚操作 26 }catch(Exception e1){ 27 e1.printStackTrace(); 28 } 29 e.printStackTrace(); 30 }finally{ 31 JdbcUtil.close(pr,con,null); 32 } 33 } 34 }
17、数据库连接池
17.1、理解连接池
jdbc执行过程:数据库连接---执行完毕---释放。
连接-释放十分浪费系统资源。
池化技术:准备一些预先的资源,过来就连接预先准备好的,使用完,在放回去
比如:开门--业务员:等待-服务--
常用连接数10个
最小连接数: 10 最小连接数为常用连接数
最大连接数: 15 业务最高承载上限
排队等待, . 超出最高上限等待
等待超时: 超过指定时间,手动报错将其踢出
17.2、编写连接池,实现DataSource接口
开源数据源实现:DBCP、C3P0、Druid:阿里巴巴。使用这些数据库连接池之后,就不需要编写连接数据库的操作了
DBCP:
需要jar包下载地址:
-
commons-dbcp-1.4.jar
-
commons-pool-1.6.jar
-
创建dbcp的配置文件(properties)
#连接设置 driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://127.0.0.1:3306/1806?useSSL=false username=root password=root #<!-- 初始化连接 --> initialSize=10 #最大连接数量 maxActive=50 #<!-- 最大空闲连接 --> maxIdle=20 #<!-- 最小空闲连接 --> minIdle=5 #<!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 --> maxWait=60000 #JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:[属性名=property;] #注意:"user" 与 "password" 两个属性会被明确地传递,因此这里不需要包含他们。 connectionProperties=useUnicode=true;characterEncoding=gbk #指定由连接池所创建的连接的自动提交(auto-commit)状态。 defaultAutoCommit=true #driver default 指定由连接池所创建的连接的只读(read-only)状态。 #如果没有设置该值,则“setReadOnly”方法将不被调用。(某些驱动并不支持只读模式,如:Informix) defaultReadOnly= #driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。 #可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE defaultTransactionIsolation=READ_UNCOMMITTED
-
编写数据源工具类
1 public class DbcpUtil { 2 private static DataSource dataSource=null; 3 static{ 4 try { 5 InputStream in=DbcpUtil.class.getClassLoader().getResourceAsStream("dbcpconfig.properties"); 6 Properties properties =new Properties(); 7 properties.load(in); 8 //创建数据源工厂,工厂模式--》创建对象 9 dataSource= BasicDataSourceFactory.createDataSource(properties); 10 } catch (Exception e) { 11 e.printStackTrace(); 12 } 13 } 14 public static Connection con() throws SQLException { 15 return dataSource.getConnection();//从数据源获取连接 16 } 17 public static void close(PreparedStatement pr, Connection con, ResultSet re){ 18 try { 19 if(pr!=null){ 20 pr.close(); 21 } 22 if(con!=null){ 23 con.close(); 24 } 25 if(re!=null){ 26 re.close(); 27 } 28 }catch (Exception e){ 29 e.printStackTrace(); 30 } 31 } 32 }
C3P0:
需要的jar包:c3p0-0.9.5.2.jar和mchange-commons-java-0.2.12.jar
-
创建c3p0的配置文件(xml)
1 <?xml version="1.0" encoding="UTF-8"?> 2 3 <c3p0-config> 4 <default-config> 5 <property name="driverClass">com.mysql.jdbc.Driver</property> 6 <property name="jdbcUrl">jdbc:mysql://localhost:3306/1806?useSSL=false</property> 7 <property name="user">root</property> 8 <property name="password">root</property> 9 </default-config> 10 <!-- This app is massive! --> 11 <named-config name="MySql"> 12 <property name="driverClass">com.mysql.jdbc.Driver</property> 13 <property name="jdbcUrl">jdbc:mysql://localhost:3306/1806?useSSL=false</property> 14 <property name="user">root</property> 15 <property name="password">root</property> 16 </named-config> 17 </c3p0-config>
-
编写数据源工具类
1 public class C3p0Util { 2 private static DataSource dataSource=null; 3 static{ 4 try { 5 //获取c3p0配置文件中name为MySql的配置,不加参数,就会加载获取到默认的配置 6 dataSource= new ComboPooledDataSource("MySql"); 7 } catch (Exception e) { 8 e.printStackTrace(); 9 } 10 } 11 public static Connection con() throws SQLException { 12 return dataSource.getConnection();//从数据源获取连接 13 } 14 public static void close(PreparedStatement pr, Connection con, ResultSet re){ 15 try { 16 if(pr!=null){ 17 pr.close(); 18 } 19 if(con!=null){ 20 con.close(); 21 } 22 if(re!=null){ 23 re.close(); 24 } 25 }catch (Exception e){ 26 e.printStackTrace(); 27 } 28 } 29 }
连接池总结:无论使用什么数据源,本质还是一样的,DataSource接口不会变,方法就不会变

 浙公网安备 33010602011771号
浙公网安备 33010602011771号