第一次个人编程作业
Github
PSP Table
| PSP2.1 | Personal Software Process Stages | Estimated time(minutes) | The actual time consuming(minutes) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| ·Estimate | ·估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 2090 | 2330 |
| · Analysis | · 需求分析 (包括学习新技术) | 960 | 1080 |
| · Design Spec | · 生成设计文档 | 40 | 50 |
| · Design Review | · 设计复审 | 20 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 35 |
| · Coding | · 具体编码 | 800 | 900 |
| · Code Review | · 代码复审 | 30 | 25 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 220 |
| Reporting | 报告 | 70 | 70 |
| · Test Repor | · 测试报告 | 30 | 25 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 25 |
| · 合计 | 2175 | 2415 |
计算模块接口的设计与实现过程
计算模块接口设计
编程语言:Python
思想:总体上采用的是分而治之的思想。将地址逐级分离出来,然后再对每一级地址进行单独处理。每分离出一级地址就把该部分从字符串中删除,以缩短字符串长度。下面是具体的流程。
流程图(工具:processon):
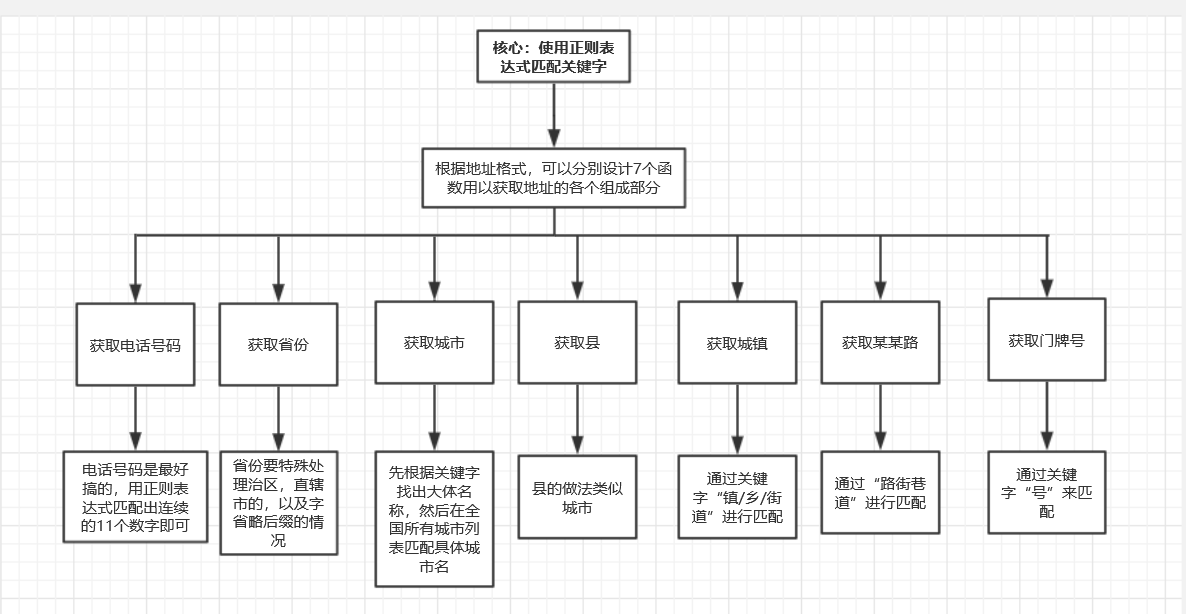
实现过程
按照上面的思路来做,大方向是没有错的。 但是具体实现时还是有遇到很多问题。要处理各种细节,比如缺失后缀,缺失某级地址等情况。
关键代码
获取电话号码:
def gettelnum(is_eg): #获得电话号码
find = re.search(r'\d{11}', is_eg) #\d{11}表\d匹配11次
if find == None:
return ""
return find.group(0)
注:电话号码肯定是要第一个处理的,因为其特征性最强,就是11个连续的数字,最好找。找出来之后就将其从字符串中删除,缩短字符长度,也方便后面的工作,因为有些地址中电话号码会将某些名字分割开,例如:1!小陈,广东省东莞市凤岗13965231525镇凤平路13号.
这里凤岗镇就被电话号码隔开了。
获取省份:
def getprovince(is_eg): ##获得省
find = re.search(("(.*?省)|(.*?自治区)|上海市|北京市|天津市|重庆市"), is_eg)
if find != None:
length = len(find.group(0))
if find == None or length > 5: #处理第一级地址没写全的情况
if is_eg[0:3] == "黑龙江":
return "黑龙江"
if is_eg[0:3] == "内蒙古":
return "内蒙古"
return is_eg[0:2]
return find.group(0)
注:使用正则表达式进行匹配,分别匹配省,直辖市,自治区。if find == None or length > 5:这部分处理的是第一级地址没写全和例如“宁夏回族自治区”这样地址长度>5的情况。没写全的情况分两种,一种是黑龙江、内蒙古这种只写三个字的,还有一种是像福建,江西,宁夏,西藏只写两个字的。最后if里面的都返回没有“省、自治区、市”的地址,后面统一加上相关字眼。if外面的返回完整首级地址。
计算模块接口部分的性能改进
代码质量分析
工具:Pycharm的插件Pylint
结果:
修改一:把warning都去除之后
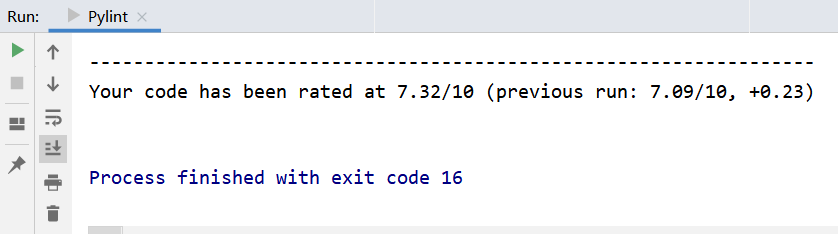
修改二:查看了一下提示,提示参数没有用蛇形命名法。修改了一下参数的命名,分数又提高了一点点
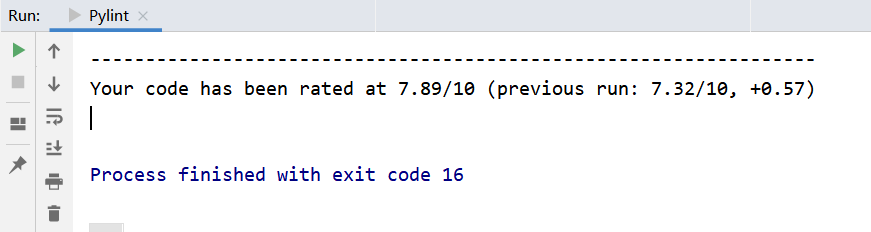
修改三:又是命名不规范,变量没有使用UPPER_CASE命名,再次修改

修改四:差不多了
性能改进
工具:Pycharm专业版的profile
开始:这里选择的是难度2,分割为七级地址的一个输入
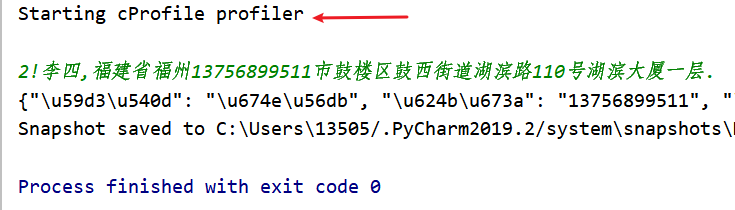
statistics:这是统计出来的情况,图一是几个调用的最多的模块,但是主要耗时都不在这。图二是时间消耗的情况,可以看出主要是那个什么“.input”最耗时间,不过咱也不知道这是个什么东西,看上去是什么输入的意思,算了,不管它,咱也不想知道。
图一: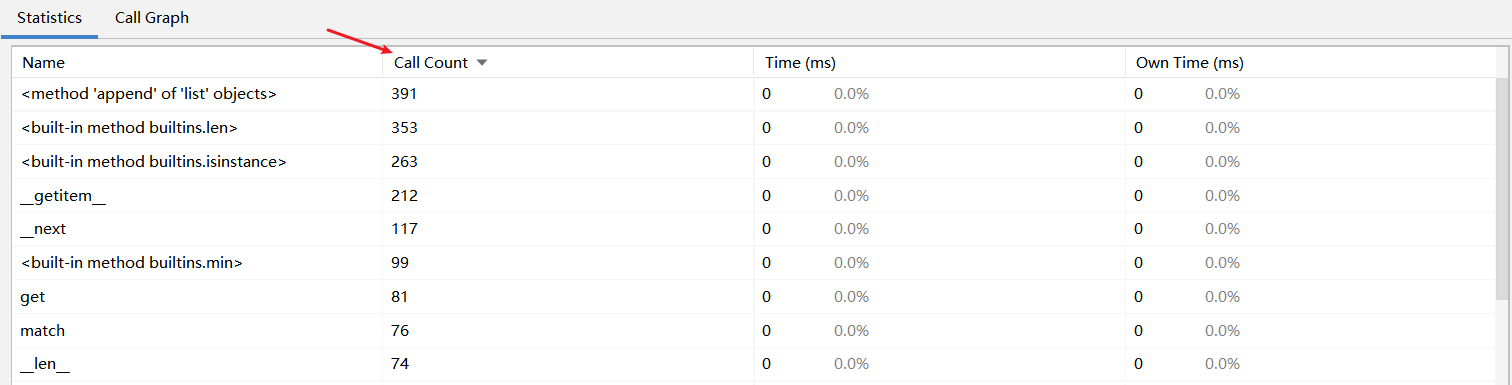
图二: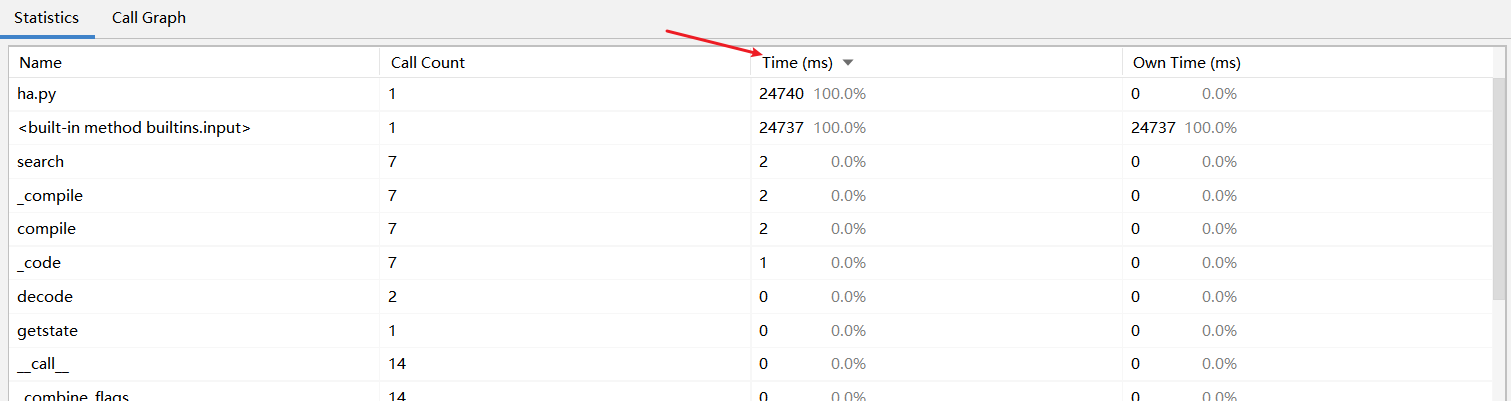
Call Graph:这是调用关系图,可以看到刚刚上面说的那个调用最多的东西变红了,基本上所有的消耗都在那个地方。

改进:根据上面的调用图,主要的时间都耗在<built-in method builtins.input>这个模块上。但是这个东西到底是什么,根据名字应该是输入的意思,所以我进行了以下的几个尝试。
- 运行profile后,这里会等待输入测试数据,如图:
- 等待一会儿后第一次输入测试数据,如图:
- 进行profile查看结果,如图:

可以看到这次那个模块的耗时是1005ms。
- 同样的数据,再次进行profile,多等待一会再输入测试数据,如图:

由于等了好久才输入数据,可以看到那个模块的耗时大了很多,为39856ms。
总结:通过上面的测试可以发现,<built-in method builtins.input>这个模块的耗时是运行代码后,终端等待输入的时间。所以代码的性能与其没有关系,除去这个部分,主要的时间是花在search函数 上,由于其调用的次数也不多,改进的空间不大,就不进行改进了。以上的测试表明,代码的性能还可以。
计算模块部分单元测试展示
工具:coverage
说明:由于并不会编写单元测试函数,所以此处单元测试使用的主函数来测试。分别选择1! 2! 3! 级的数据各一条来测,测试结果如下:
1!数据:1!家按犯,西藏自治区昌都卡若区城关镇214国道城关镇嘎东街社区居民委员15347650776会.
结果:覆盖率是67%

2!数据:2!薄鹿,内13790487373蒙古自治区锡林郭勒盟二连浩特市差马大街2222号内蒙古格伊古勒生态发展有限公司.
结果:覆盖率是72%

3!数据:3!汲茶,海西蒙古族藏族自治州乌兰县茶18958237812卡镇交通街6-2号扎布寺村村委会.
结果:覆盖率也是72%
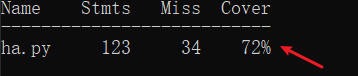
代码测试覆盖图:
总结:以上三个数据是随机找的,可以看到结果都是60%以上,由于测试的样例比较少,后面也有可能会出现覆盖率较低的情况。
异常处理
-
异常:这里选择了网站上的一条二级难度的数据进行测试,可以看到
东大街这个地方出现了一个异常,输出变成了口东大街

-
处理:找到
交道这一级地址的分离函数,如下:
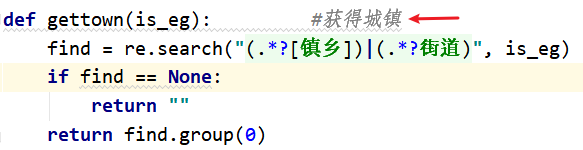
由于上面出现的异常是由于
交道口的口被分到了下一级,所以在镇乡这边增加一个口,再跑一遍,结果如下:

可以看到这下分割就对了,不过这个异常的处理只是耍了个小聪明而已。
心路历程
说实话,第一眼看到这个作业我是很崩溃的,看着作业里面的各种名词,什么“Code Quality Analysis”、“Studio Profiling Tools”、“单元测试”、“测试分支覆盖率”的一个都不懂,听都没听说过。以及作业的要求,简直看都看不懂,对我来说这真的好难啊!这是面对题目时受到的第一层打击。接着就是就是听一些大佬讲怎么实现,什么正则表达式啊,blablabla的。听的我是云里雾里。后面又在想要用什么语言去实现,听大家讲python实现起来比较简单,可是我只会C、C++,而且又是很菜的那种。慌了,是真的慌,千言万语一句话“书到用时方恨少”。于是我决定也用python写,因为我估摸着自己用C++写八成是写不出来的,更何况字符串处理这一块我又很薄弱。这是受到的第二层打击。可是有些事确实是感觉“冥冥之中自有安排”,要开始学习python,我正好之前暑假的时候买了一本python的书,二话不说就开启了“速成模式”,疯狂看书,看语法,花了三天时间把基本的语法过了一下,起码是知道了如果我需要实现什么功能该去哪里找,有什么东西能用的上的。“工欲善其事必先利其器”,没错,接着就是解决工具问题了。说来也巧,上Linux课时看到同学在装Pycharm,问了一下是拿来写Python的,我寻思着要不我也装一个,于是我一边问一边装了Pycharm。装这个软件的时候我是还不知道后面要要用Python写。说来也真是幸运,在迷茫中把工具,相关知识都铺垫了一下,为后面扫清了一部分障碍。整个过程给我的一个感觉就是一步步拨开迷雾的过程,越往后越知道要做什么。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号