DDR4
DDR工作原理
核心频率就是内存的工作频率;DDR1内存的核心频率是和时钟频率相同的,到了DDR2和DDR3时才有了时钟频率的概念,就是将核心频率通过倍频技术得到的一个频率。数据传输频率就是传输数据的频率。DDR1预读取是2位,DDR2预读取是4位,DDR3预读取是8位。
DDR1在传输数据的时候在时钟脉冲的上升沿和下降沿都传输一次,所以数据传输频率就是核心频率的2倍。DDR2内存将核心频率倍频2倍所以时钟频率就是核心频率的2倍了,同样还是上升边和下降边各传输一次数据,所以数据传输频率就是核心频率的4倍。
DDR3内存的时钟频率是核心频率的4倍,所以数据传输频率就是核心频率的8倍了。
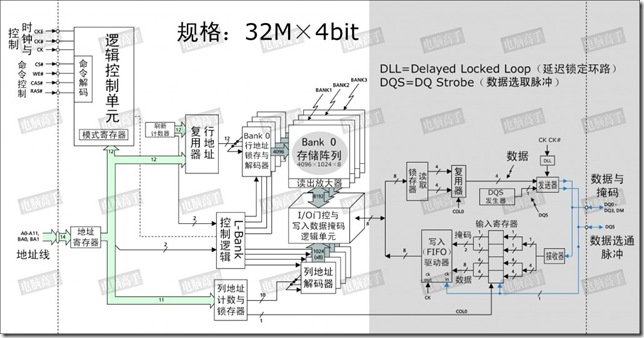
这是一颗128Mbit的内存芯片,从图中可以看出来,白色区域内与SDRAM的结构基本相同,但请注意灰色区域,这是与SDRAM的不同之处。首先就是内部的L-Bank规格。SDRAM中L-Bank 存储单元的容量与芯片位宽相同,但在DDR SDRAM中并不是这样,存储单元的容量是芯片位宽的一倍,所以在此不能再套用讲解SDRAM时 “芯片位宽=存储单元容量” 的公式了。也因此,真正的行、列地址数量也与同规格SDRAM不一样了。
以本芯片为例,在读取时,L-Bank在内部时钟信号的触发下一次传送8bit的数据给读取锁存器,再分成两路4bit数据传给复用器,由后者将它们合并为一路4bit数据流,然后由发送器在DQS的控制下在外部时钟上升与下降沿分两次传输4bit的数据给北桥。这样,如果时钟频率为100MHz,那么在I/O端口处,由于是上下沿触发,那么就是传输频率就是200MHz。
这种内部存储单元容量(也可以称为芯片内部总线位宽)=2×芯片位宽(也可称为芯片I/O总线位宽)的设计,就是所谓的两位预取(2-bit Prefetch),有的公司则贴切的称之为2-n Prefetch(n代表芯片位宽)。
差分时钟
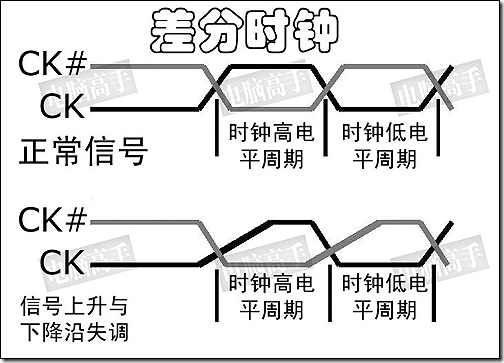
差分时钟是DDR的一个必要设计,但CK#的作用,并不能理解为第二个触发时钟(你可以在讲述DDR原理时简单地这么比喻),而是起到触发时钟校准的作用。由于数据是在CK的上下沿触发,造成传输周期缩短了一半,因此必须要保证传输周期的稳定以确保数据的正确传输,这就要求CK的上下沿间距要有精确的控制。但因为温度、电阻性能的改变等原因,CK上下沿间距可能发生变化,此时与其反相的CK#就起到纠正的作用(CK上升快下降慢,CK# 则是上升慢下降快)。而由于上下沿触发的原因,也使CL=1.5和2.5成为可能,并容易实现。与CK反相的CK#保证了触发时机的准确性。
数据选取脉冲(DQS)
总结:DQS是双向信号,源自于产生数据的那一侧;读内存时候,由内存产生,DQS的沿和数据的沿对齐;写入内存时候,由外部产生,DQS信号的中间对应数据沿,此时DQS的沿对应数据最稳定的中间时刻。
DQS是DDR SDRAM中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每一颗芯片都有一个DQS信号线,它是双向的,在写入时它用来传送由北桥发来的DQS信号,读取时,则由芯片生成DQS向北桥发送。完全可以说,它就是数据的同步信号。
在读取时,DQS与数据信号同时生成(也是在CK与 CK#的交叉点)。而DDR内存中的CL也就是从CAS发出到DQS生成的间隔,数据真正出现在数据I/O总线上相对于DQS触发的时间间隔被称为 tAC。注意,这与SDRAM中的tAC的不同。实际上,DQS生成时,芯片内部的预取已经完毕了,tAC是指上文结构图中灰色部分的数据输出时间,由于预取的原因,实际的数据传出可能会提前于DQS发生(数据提前于DQS传出)。由于是并行传输,DDR内存对tAC也有一定的要求,对于 DDR266,tAC的允许范围是±0.75ns,对于DDR333,则是±0.7ns,有关它们的时序图示见前文,其中CL里包含了一段DQS的导入期。
DQS是为了保证接收方的选择数据, DQS在读取时与数据同步传输,那么接收时也是以DQS的上下沿为准吗?不,如果以DQS的上下沿区分数据周期的危险很大。由于芯片有预取的操作,所以输出时的同步很难控制,只能限制在一定的时间范围内,数据在各I/O端口的出现时间可能有快有慢,会与DQS有一定的间隔,这也就是为什么要有一个tAC规定的原因。而在接收方,一切必须保证同步接收,不能有tAC之类的偏差。这样在写入时,芯片不再自己生成DQS,而以发送方传来的DQS为基准,并相应延后一定的时间,在DQS的中部为数据周期的选取分割点(在读取时分割点就是上下沿),从这里分隔开两个传输周期。这样做的好处是,由于各数据信号都会有一个逻辑电平保持周期,即使发送时不同步,在DQS上下沿时都处于保持周期中,此时数据接收触发的准确性无疑是最高的。在写入时,以DQS的高/低电平期中部为数据周期分割点,而不是上/下沿,但数据的接收触发仍为DQS的上/下沿。
写入延迟
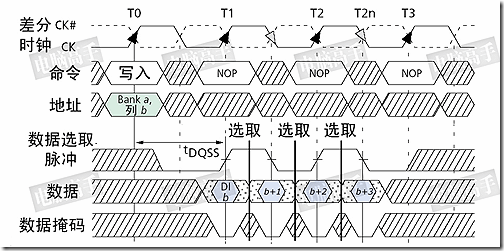
在上面的DQS写入时序图中,可以发现写入延迟已经不是0了,在发出写入命令后,DQS与写入数据要等一段时间才会送达。这个周期被称为DQS相对于写入命令的延迟时间(tDQSS, WRITE Command to the first corresponding rising edge of DQS),对于这个时间大家应该很好理解了。
为什么要有这样的延迟设计呢?原因也在于同步,毕竟一个时钟周期两次传送,需要很高的控制精度,它必须要等接收方做好充分的准备才行。tDQSS是DDR内存写入操作的一个重要参数,太短的话恐怕接受有误,太长则会造成总线空闲。tDQSS最短不能小于0.75个时钟周期,最长不能超过1.25个时钟周期。有人可能会说,如果这样,DQS不就与芯片内的时钟不同步了吗?对,正常情况下,tDQSS是一个时钟周期,但写入时接受方的时钟只用来控制命令信号的同步,而数据的接受则完全依靠DQS进行同步,所以 DQS与时钟不同步也无所谓。不过,tDQSS产生了一个不利影响——读后写操作延迟的增加,如果CL=2.5,还要在tDQSS基础上加入半个时钟周期,因为命令都要在CK的上升沿发出。
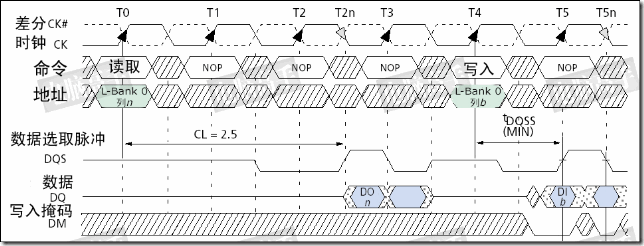
当CL=2.5时,读后写的延迟将为tDQSS+0.5个时钟周期(图中BL=2)
另外,DDR内存的数据真正写入由于要经过更多步骤的处理,所以写回时间(tWR)也明显延长,一般在3个时钟周期左右,而在DDR-Ⅱ规范中更是将tWR列为模式寄存器的一项,可见它的重要性。
突发长度与写入掩码
在DDR SDRAM中,突发长度只有2、4、8三种选择,没有了随机存取的操作(突发长度为1)和全页式突发。这是为什么呢?因为L-Bank一次就存取两倍于芯片位宽的数据,所以芯片至少也要进行两次传输才可以,否则内部多出来的数据怎么处理?而全页式突发事实证明在PC内存中是很难用得上的,所以被取消也不希奇。
但是,突发长度的定义也与SDRAM的不一样了(见本章节最前那幅DDR简示图),它不再指所连续寻址的存储单元数量,而是指连续的传输周期数,每次是一个芯片位宽的数据。对于突发写入,如果其中有不想存入的数据,仍可以运用DM信号进行屏蔽。DM信号和数据信号同时发出,接收方在DQS的上升与下降沿来判断DM的状态,如果DM为高电平,那么之前从DQS 中部选取的数据就被屏蔽了。有人可能会觉得,DM是输入信号,意味着芯片不能发出DM信号给北桥作为屏蔽读取数据的参考。其实,该读哪个数据也是由北桥芯片决定的,所以芯片也无需参与北桥的工作,哪个数据是有用的就留给北桥自己去选吧。
延迟锁定回路(DLL)
DDR SDRAM对时钟的精确性有着很高的要求,而DDR SDRAM有两个时钟,一个是外部的总线时钟,一个是内部的工作时钟,在理论上DDR SDRAM这两个时钟应该是同步的,但由于种种原因,如温度、电压波动而产生延迟使两者很难同步,更何况时钟频率本身也有不稳定的情况(SDRAM也内部时钟,不过因为它的工作/传输频率较低,所以内外同步问题并不突出)。DDR SDRAM的tAC就是因为内部时钟与外部时钟有偏差而引起的,它很可能造成因数据不同步而产生错误的恶果。实际上,不同步就是一种正/负延迟,如果延迟不可避免,那么若是设定一个延迟值,如一个时钟周期,那么内外时钟的上升与下降沿还是同步的。鉴于外部时钟周期也不会绝对统一,所以需要根据外部时钟动态修正内部时钟的延迟来实现与外部时钟的同步,这就是DLL的任务。
DLL不同于主板上的PLL,它不涉及频率与电压转换,而是生成一个延迟量给内部时钟。目前DLL有两种实现方法,一个是时钟频率测量法(CFM,Clock Frequency Measurement),一个是时钟比较法(CC,Clock Comparator)。
CFM是测量外部时钟的频率周期,然后以此周期为延迟值控制内部时钟,这样内外时钟正好就相差了一个时钟周期,从而实现同步。DLL就这样反复测量反复控制延迟值,使内部时钟与外部时钟保持同步。
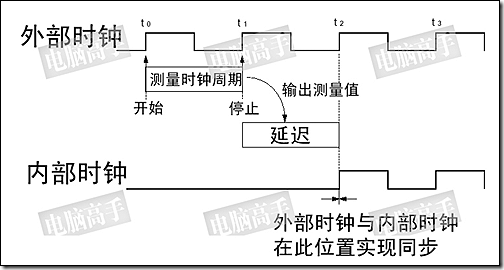
CC的方法则是比较内外部时钟的长短,如果内部时钟周期短了,就将所少的延迟加到下一个内部时钟周期里,然后再与外部时钟做比较,若是内部时钟周期长了,就将多出的延迟从下一个内部时钟中刨除,如此往复,最终使内外时钟同步。
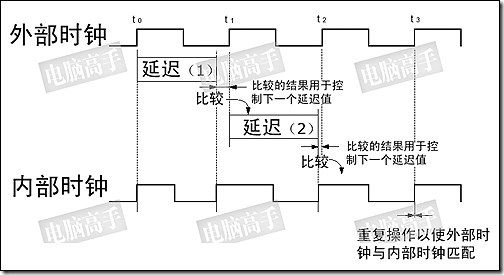
CFM与CC各有优缺点,CFM的校正速度快,仅用两个时钟周期,但容易受到噪音干扰,并且如果测量失误,则内部的延迟就永远错下去了。CC的优点则是更稳定可靠,如果比较失败,延迟受影响的只是一个数据(而且不会太严重),不会涉及到后面的延迟修正,但它的修正时间要比CFM长。DLL功能在DDR SDRAM中可以被禁止,但仅限于除错与评估操作,正常工作状态是自动有效的。

DDR4流程
译文:DDR4 - Initialization, Training and Calibration - 知乎 (zhihu.com)
初始化->ZQ校准->Vref DQ校准->读写训练(存储介质训练/初始校准)
初始化:一系列设计好的步骤组成的命令序列,上电后自动执行
1.DRAM上电
2.复位完成后,给出CKE
3.使能并产生CK/CK#
4.发送MRS命令,按照特定序列读取/配置Mode Register
5.ZQ校准(ZQCL)
6.使能DRAM进入IDLE状态
至此,DRAM已经确定工作频率、时序参数(CAS Latency、CAS Write Latency)
ZQ校准:ZQ校准概念和DDR数据信号线DQ的电路相关。DQ是双向引脚,管脚后边的电路有多个并联的240Ω电阻组成,用于提高信号完整性,由于颗粒制造的时候不可能精确240Ω,此外阻值也会因为温度和电压条件的变化而变化,所以需要校准到接近240Ω,用于提高信号完整性。
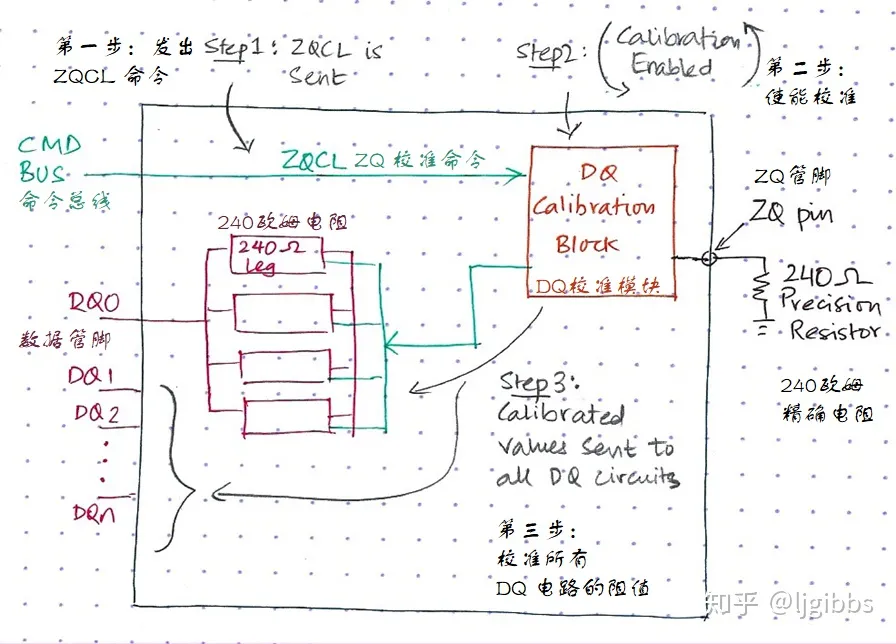
1.每个DRAM颗粒必须具有专用DQ校准模块
2.DQ模块连接至外部电阻的引脚和精确为240Ω的电阻
原因:1.DQ引脚连接的电阻用于提高信号的完整性。
2.DQ引脚本来的电阻由于工艺、电压、温度的影响不能精确达到240Ω
3.引入DQ校准模块通过ZQ引脚连接外部电阻,在初始化阶段对DQ电阻值进行校准
一般来讲,DQ 电路中的 240 欧姆电阻是 Poly Silicon Resistor 类型的,通常来说,它们的阻值会略大于 240 欧姆。,因此,DQ电阻上并联许多PMOS管,管子开启时候,通过并联电阻降低DQ电阻值,从而接近240Ω。图中放大了某个电阻的内部结构,有 5 个 PMOS 管与 DQ 电阻并联,通过 VOU[0:4] 控制管子的开关,以控制并联上来的电阻数量。
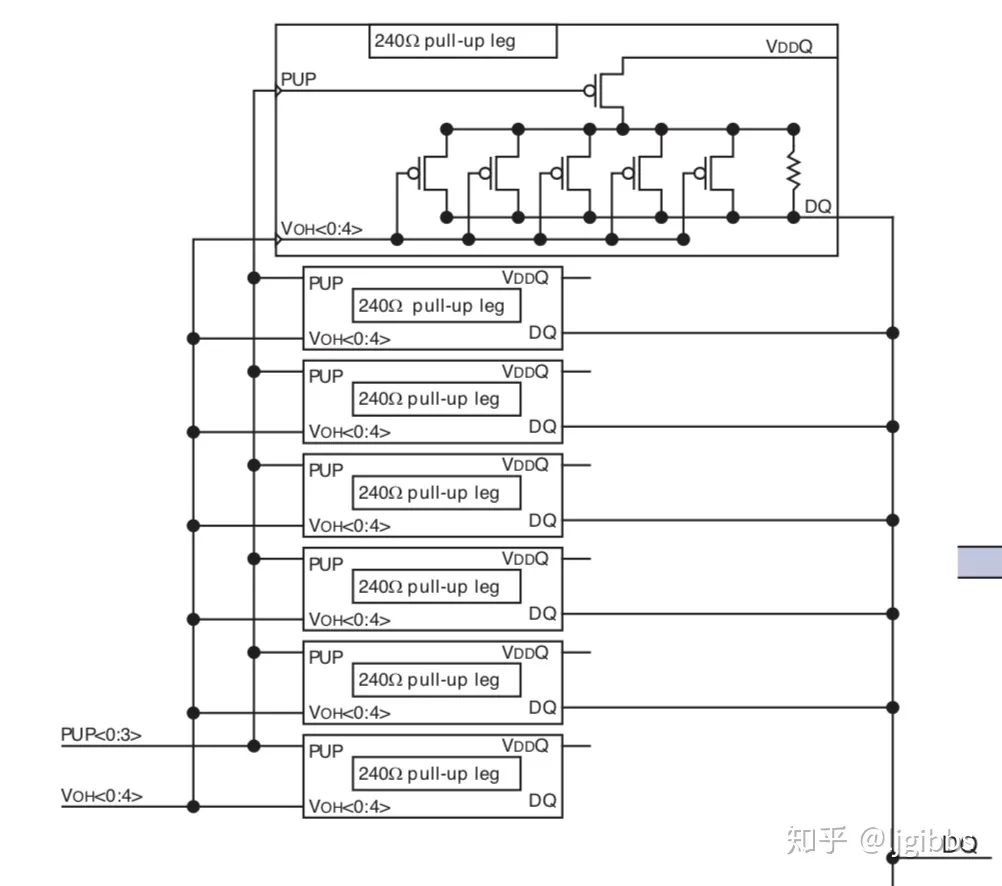
连接至DQ校准模块的电路包括一个由两个电阻组成的分压电路,其中一个是上面的可调阻值的电阻,另一个是精准的240Ω外部电阻。
当ZQCL命令发出的时候,DQ校准控制模块使能,通过内部逻辑控制Voh[0:4]信号调整poly电阻阻值直到电路分压达到VDDQ/2,即两者均为240Ω,此时ZQ校准结束,并保存此时VOH值,复制到每个DQ管脚的电路。
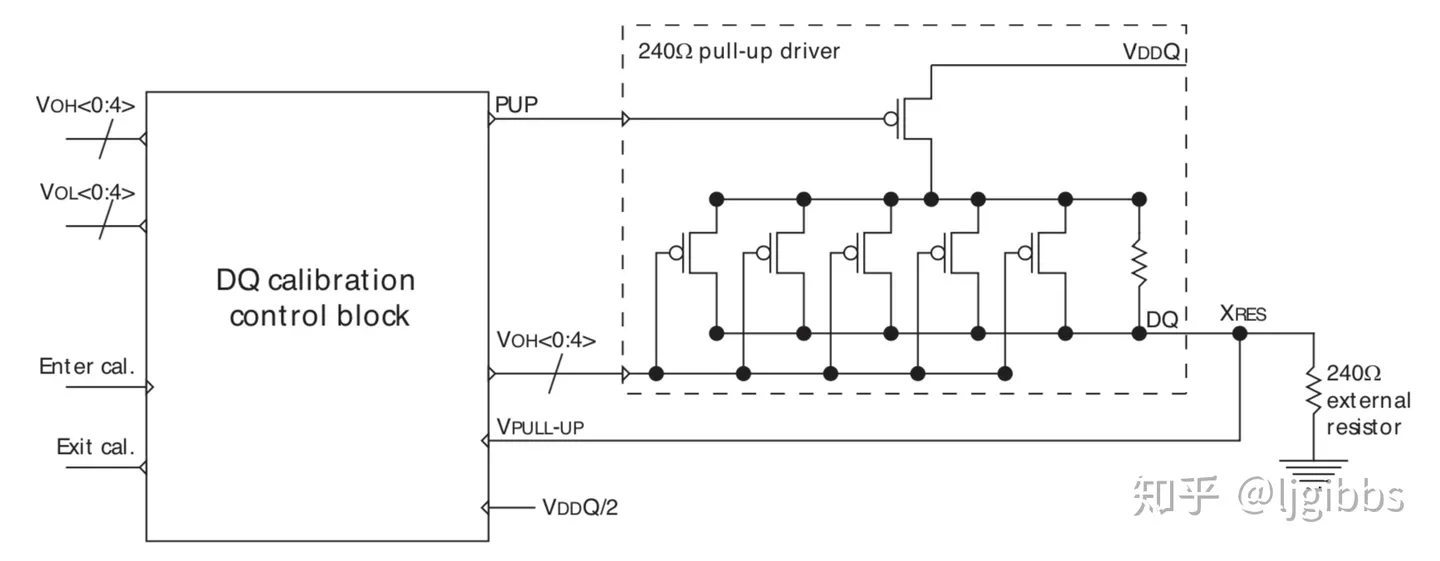
为什么不在出厂的时候直接调好呢?
因为并联的电阻网络允许用户在不同的使用条件下对电阻进行调整,为读操作调整驱动强度,为写操作调整端接电阻值。此外不同的PCB具有不同的阻抗,可调整的电阻网络根据不同的PCB单独调整电阻值,提高信号完整性,最大化信号眼图,允许DRAM工作在更高的频率下。
信号驱动强度通过mode registerMR1[2:1]控制
DQ判决电平校准Vref DQ Calibraton
读写训练 Read/Write Training
完成上述步骤后初始化已经完成,进入IDLE状态,但是此时的存储介质依旧处于未正确工作的状态,在正确读写DRAM之前,DDR控制器或者物理层还必须进行读写训练,也成为存储介质训练/初始校准
1.运行算法,以对齐DRAM的时钟信号CK与数据有效信号DQS的边沿
2.运行算法,确定DRAM颗粒的读写延迟
3.将采样时刻移动至读取数据眼图的中央
4.报告错误,如果此时的信号完成性太差,没办法确保可靠的读写操作
读写训练的目的是为了消除时钟线和数据线之间的相对延迟的不同对数据读写的影响
DRAM是一个很呆的器件,很多操作都必须DDR控制器完成,CAS的延时是固定的,不会变化。DDR控制器需要根据布线延迟以及结构的路由延迟,调整数据与地址信号之间的延迟,保证数据到达每个DRAM的相对延迟满足CWL
例如:CWL=9,主机发出列地址之后,由于地址到达各DRAM的时间不同,因此需要不同的延迟,在各个数据线上发送数据,保证数据到达DRAM的延迟均为9.
读操作也需要类似的工作,每个 DRAM 颗粒位于 DIMM 的不同位置,距离主机的距离不同。因此每个 DRAM 颗粒接收到读命令的时间不同,因此后续回应的读数据到达主机的时间也不相同。初始化期间,主机确定各个 DRAM 颗粒的延迟,并以此训练内部的电路,使电路能够在正确的时刻采样来自 DRAM 的读数据。
读写训练的算法,常见的:
1.Write leveling
DRAM 写入中最重要的,不能违反的时序参数是 tDQSS,表示数据有效信号 DQS 相对时钟信号 CK 的相对位置。tDQSS 必须在协议规定的 tDQSS(MIN) 和 tDQSS(MAX) 之间。如果 tDQSS 超出规定的限制,那么可能会写入错误的数据。
既然内存条上每个 DRAM 颗粒的数据有效信号相对于时钟的延迟都不同,所以控制器必须对每个 DRAM 颗粒的 tDQSS 进行训练,并根据训练的结果满足每个颗粒不同的延迟需求。
2.Read Centering
Read Centering 的目的是训练控制器的读采样电路,在读数据眼图的中央进行采样,以获得最稳定的采样结果。
3.Write Centering
Write Centering 的目的是设定每条数据信号线上写数据的发送延迟,使 DRAM 端能够根据对齐数据眼图的中央的 DQS 采样数据信号 DQ。
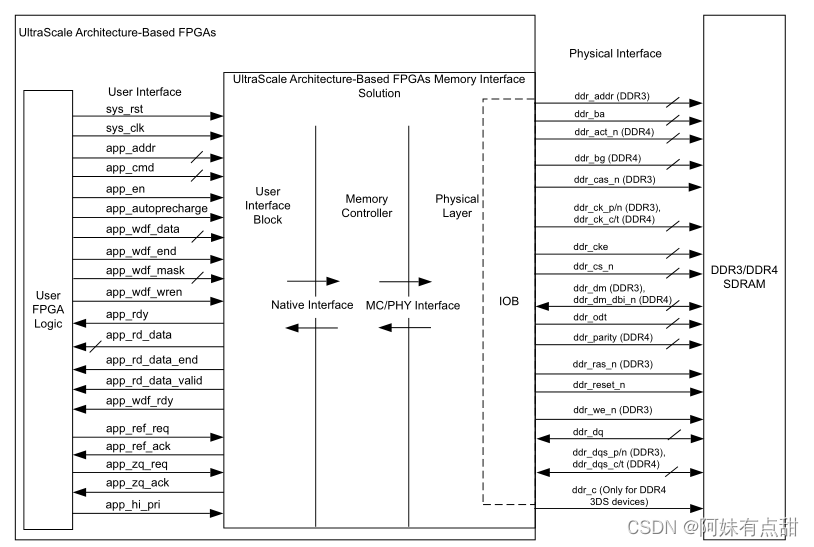
DDR4 MIG IP核
这个IP核相当于提供了SDRAM存储类型的解决方案,支持完整的内存控制器和仅物理层(PHY)解决方案。
1.控制器:控制器接收来自用户接口的突发事务,并生成与SDRAM之间的事务,负责SDRAM的定时参数和刷新。合并读写事务,减少相关总线陷入死循环的次数,并且控制器还会重新排序指令以提高SDRAM数据总线的利用率。
2.物理层:物理层为SDRAM提供高速接口,该层包括FPGA内部的硬件软件模块校准逻辑,目的是确保SDRAM硬件接口的最佳时序。
硬件模块包括数据序列化和传输;数据捕获与反序列化;高速时钟生成与同步;每个pin引脚具有电压和温度跟踪的粗延迟元件和细延迟元件;
软件模块包括内存初始化;校准模块提供了一种完整的方法来设置硬件模块和软件IP中的所有延迟,以便与内存接口一起工作。
应用接口:用户接口提供了一种类似于简易FIFO的接口,数据被缓存,读取的数据按照要求的顺序呈现,该用户接口在控制器的本地接口之上,本地接口不能由用户接口访问,并且当从SDRAM接收返回数据时候没有缓冲,然后用户接口缓冲读写数据,并根据需要重新排列数据
DQS 是DDR中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每一颗芯片都有一个DQS信号线,它是双向的,在写入时它用来传送由北桥发来的DQS信号,读取时,则由芯片生成DQS向北桥发送。完全可以说,它就是数据的同步信号。
DDR时钟频率详解
例如MT41J256M16xx-125型号的DDR
IO时钟频率,也就是DDR频率:-125代表tCK = 1.25ns,则芯片支持最大时钟频率为1/1,25ns = 800MHZ
位宽:256M16代表芯片数据位宽16bit,16根数据线;
补充:1.当一个FPGA上挂多个DDR,如4片ddr3,位宽则会相应增大;16*4 = 64bit,再乘以DDR3的突发长度BL=8;那么程序设计里DDR3的读写位宽就变成了16*4*8=512bit;
2.明明是512M的DDR,为什么又写成256M呢?因为256M16是16根数据线16bit,对应过来就是2个byte;256M *16bit = 512MByte; 一般大B 指的是Byte,小b指的是bit;
带宽:由于DDR方式传输,所以芯片的每一根数据线 传输速率=2*800 = 1600MT/S=1600Mbit/s;
那么带宽就是16根数据线同时传输的数据速率 = 1600Mbit/s x 16 = 25600Mbit/s = 3200Mbyte/s = 3.125GByte/s
虽然DDR可以达到1600MT/s,但是也要考虑FPGA芯片的最高时钟频率
时钟结构
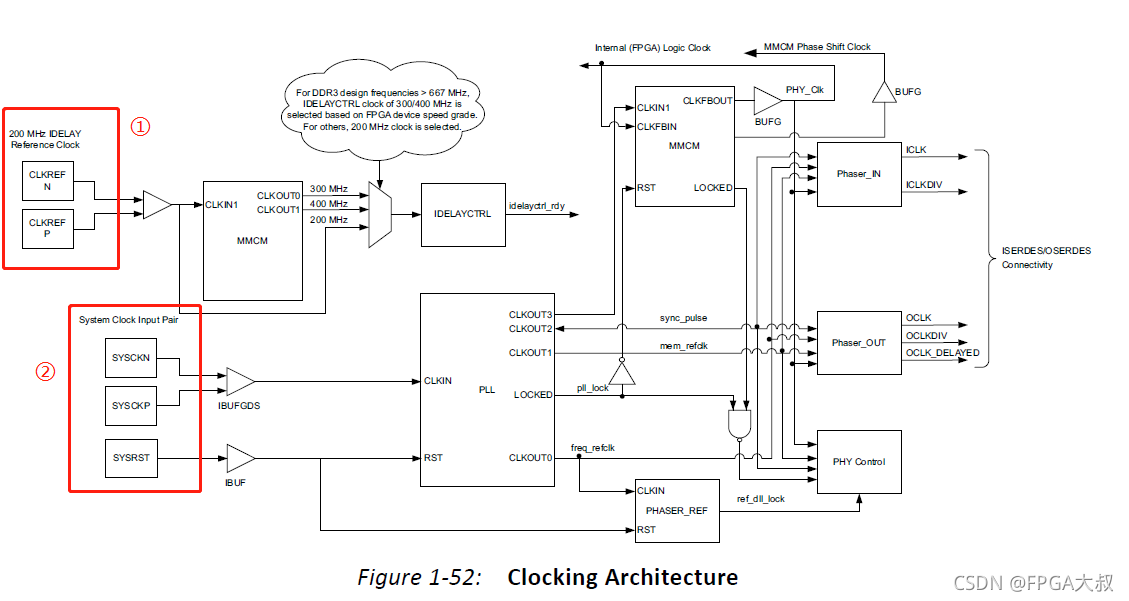
DDR3配置
如上图,参考时钟需要为200mhz;系统时钟,系统时钟为系统输入时钟
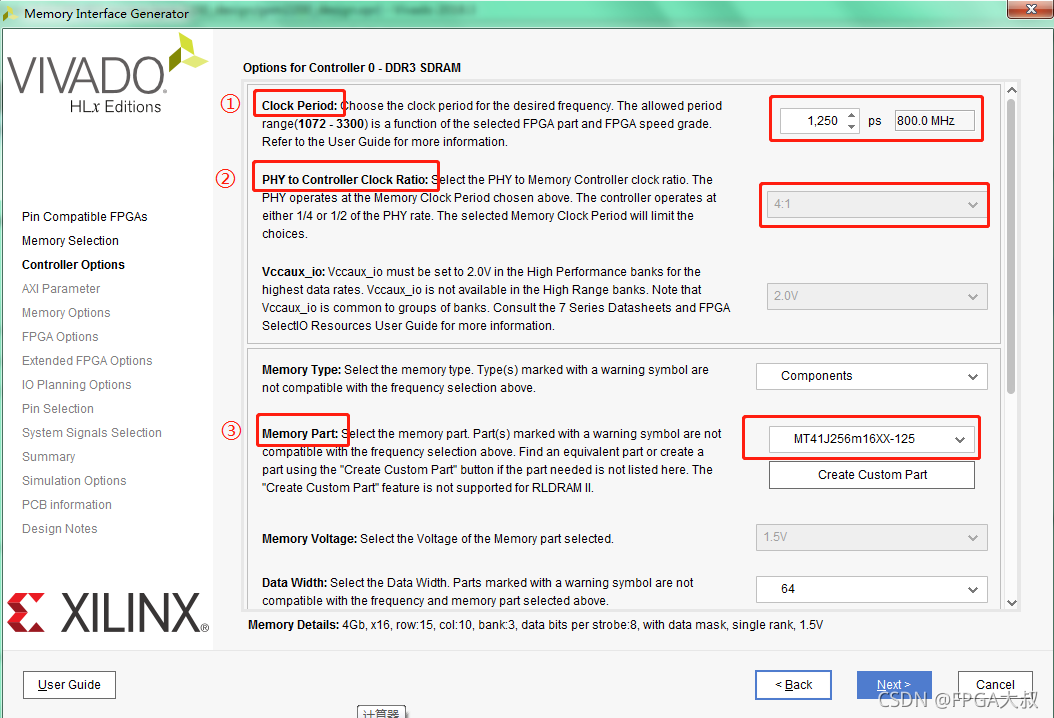
①处的Clock Period设置的参数就是 MIG 的PHY 接口对DDR3的时钟,也就是DDR3芯片实际跑的IO时钟频率,它由system clock(主时钟)倍频而来
②物理侧到控制器时钟的比例,可选4:1或2:1;决定了ui_clk的频率;有个4:1,说明MIG 输出到app接口上的时钟ui_clk = 800M/4=200M ,即到时我们在写RTL逻辑代码时操作MIG核时,用的就是这个200M时钟;(AXI用户接口操作时钟)
数据位宽,由DDR型号决定,但是当FPGA挂了多片DDR时,位宽相应增加;
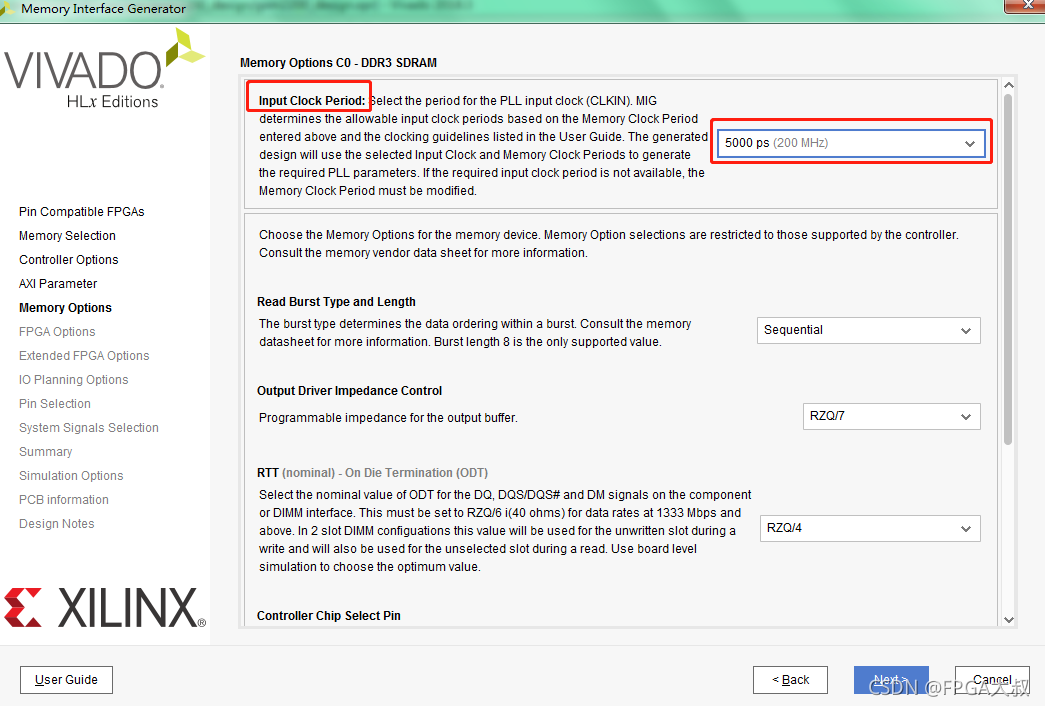
input clock period 对应的时钟就是MIG核的系统时钟,板子的时钟信号如果是200MHZ就可以直接接入,也可以由PLL/MMCM输入;
配置MIG核时选择多少M时钟,那么这里就要输入多少M,推荐选择200Mhz,因为参考时钟也是200Mhz,配置的时候参考时钟可以直接使用系统时钟,减少端口信号
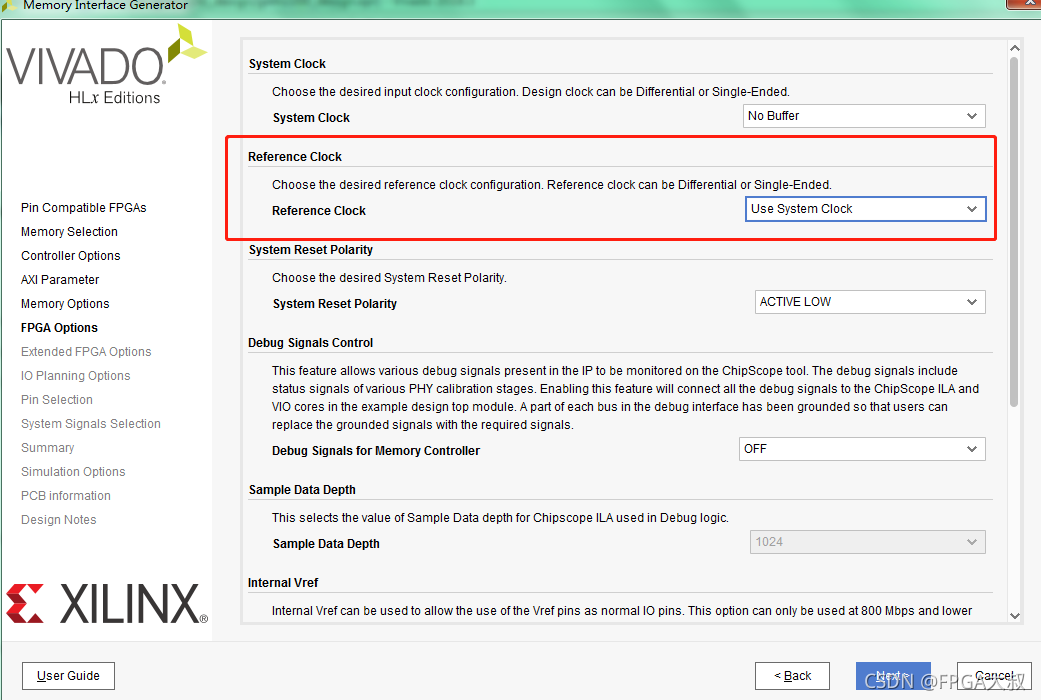
当我们系统时钟为200M时,参考时钟就可以直接使用系统时钟(use system clock)
DDR4 MIG 配置
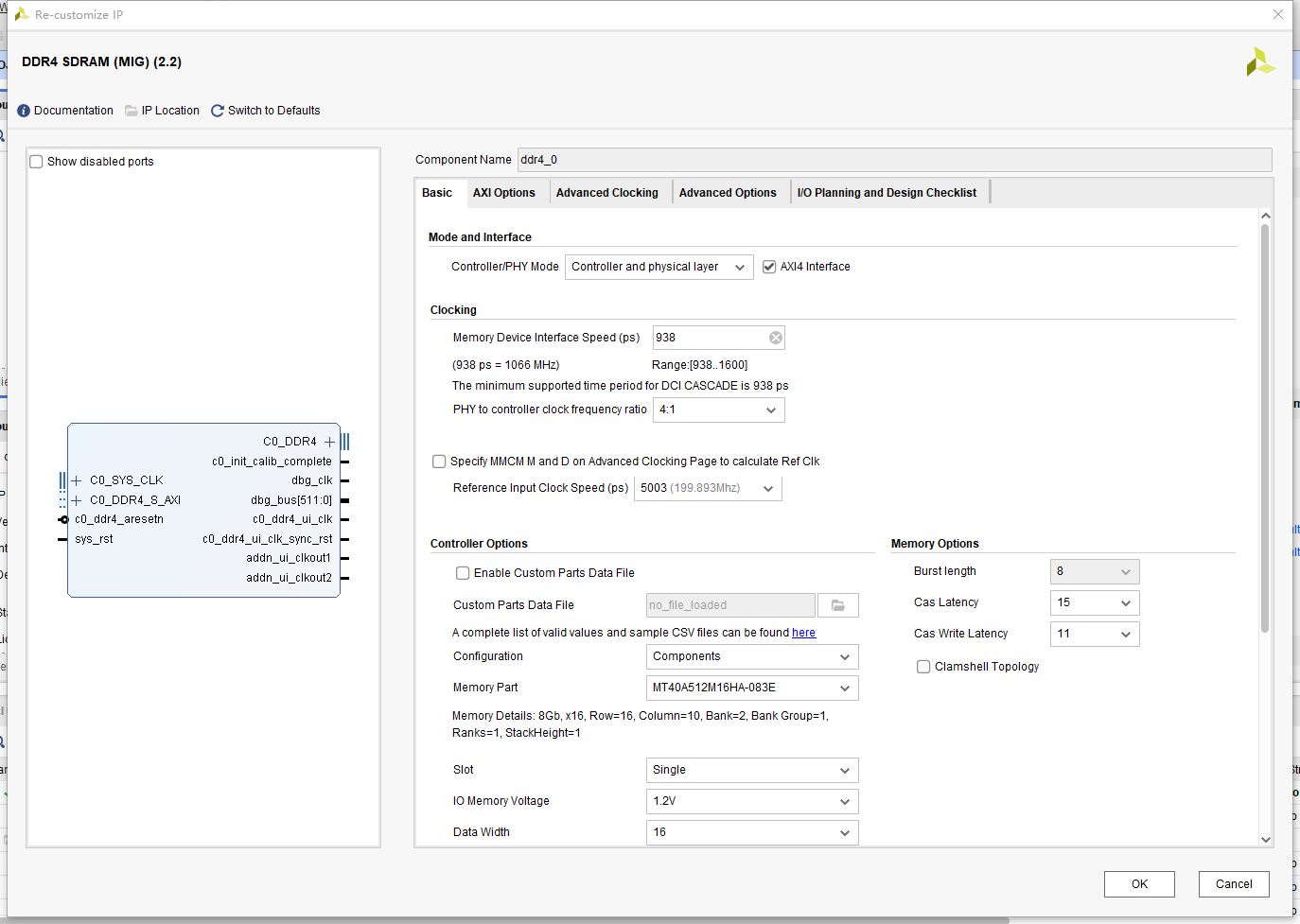
如上图所示,直接选择938,对应1066MHZ;下边只能选4:1,所以ui_clk = 1066/4;参考时钟频率选择5003ps,也就是大约200mhz,由板子的200MHZ差分时钟直接提供;
enable custom parts data file
当memory part下拉选项中没有需要的DDR型号时,可以自己编写所需的DDR4存储器的CSV参数文件,导入IP核后,即可从memory part中选择相应型号。我的板子上的DDR4虽然列表没有同名字的,但是有平替选项; MT40A512M16HA-083E == MT40A512M16LY-062E
数据位宽(注意,这里的位宽代表的是DDR内部存储数据的位宽):这里仅选用1片,就选择16bit; 由所选用的DDR颗粒数据宽度和数量决定,若DDR颗粒位宽为16bit,共选用4片DDR4,那么此处数据位宽为64。
CAS latency 和 CAS write latency(CL与CWL)
CL和CWL根据选择的DDR4型号进行选择,其中CWL可以从MR2寄存器中定义选择。
DDR是根据行列寻址的,首先需要发送预充电指令,内存开始初始化行地址选通(RAS),列地址选通(RAS)后,同时发送列地址和读写指令,访问对应DDR地址的数据。
CL指的是:列地址和读指令发送后,DDR输出第一个数据之间所需要的时间。
CWL指的是:列地址和写指令发送后,数据写入到DDR所需要的时间。
相当于数据延迟
clamshell topology
当电路板的正面和反面都存在DDR4颗粒时(镜像对接),勾选此选项。选择此模式的原因是方便PCB布线,通过CS0和CS1分别控制正面和反面的DDR4
Data Mask and DBI(Data Bus Inversion,依据DDR特性,DBI存在的意义在于降低功耗)
依据PG105手册选择下拉框,目前默认选择DM NO DBI
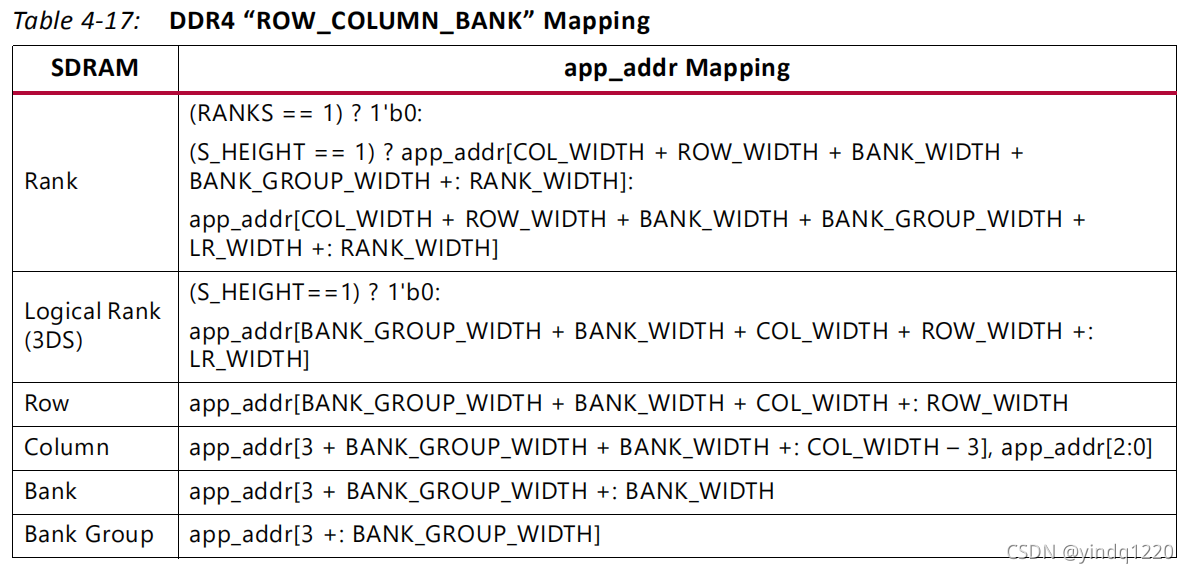
memory address map
通过此处选择用户输入地址信号(app_addr)与DDR控制器IP核的地址信号映射关系,默认为 ROW COLUMN BANK的顺序,如下图
ordering
命令执行顺序,分为两种情况:a.normal,允许DDR IP核依据内部控制器算法按照优先级别对外部输入的读命令、写命令等进行重新排序;b.strict,要求DDR IP核严格按照输入的命令依次执行,可能会降低DDR IP核的带宽利用率。
Force Read and Write commands to use AutoPrecharge,enable autoprecharge input,enable user refresh and ZQCS input
此三个选项需要对DDR、自身应用程序有较深的认识时勾选,目的在于提高读写的效率,由用户自行控制预充电、自刷新、ZQCS保持命令。当不勾选时,IP核自动控制预充电、刷新、ZQCS命令,默认不勾选。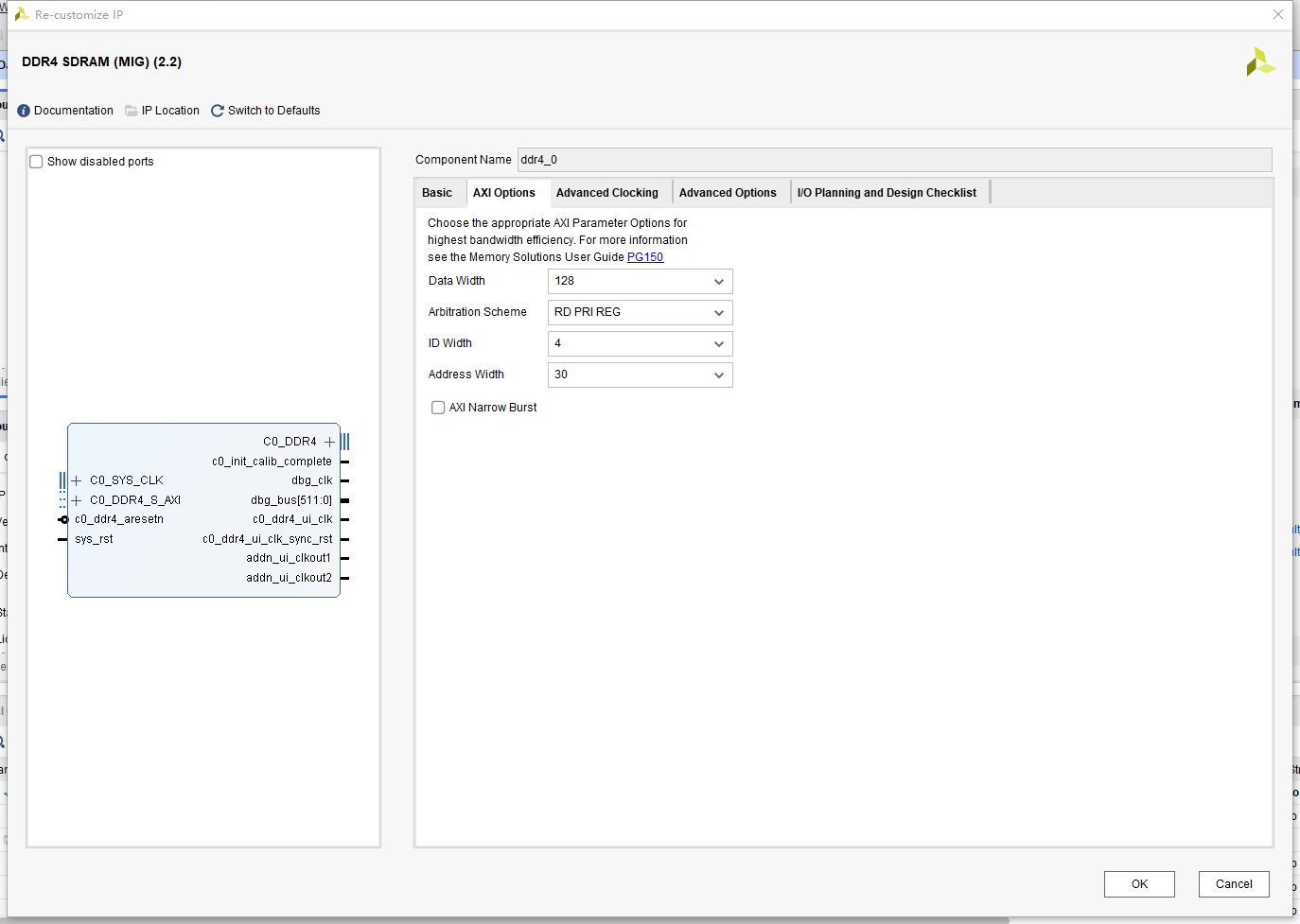
AXI Options 直接选择默认的128位宽就行,也就是每次AXI用户操作写的数据都需要拼成128bit,在写入DDR内部的时候会自动分割成前边设置好的每个地址16bit;
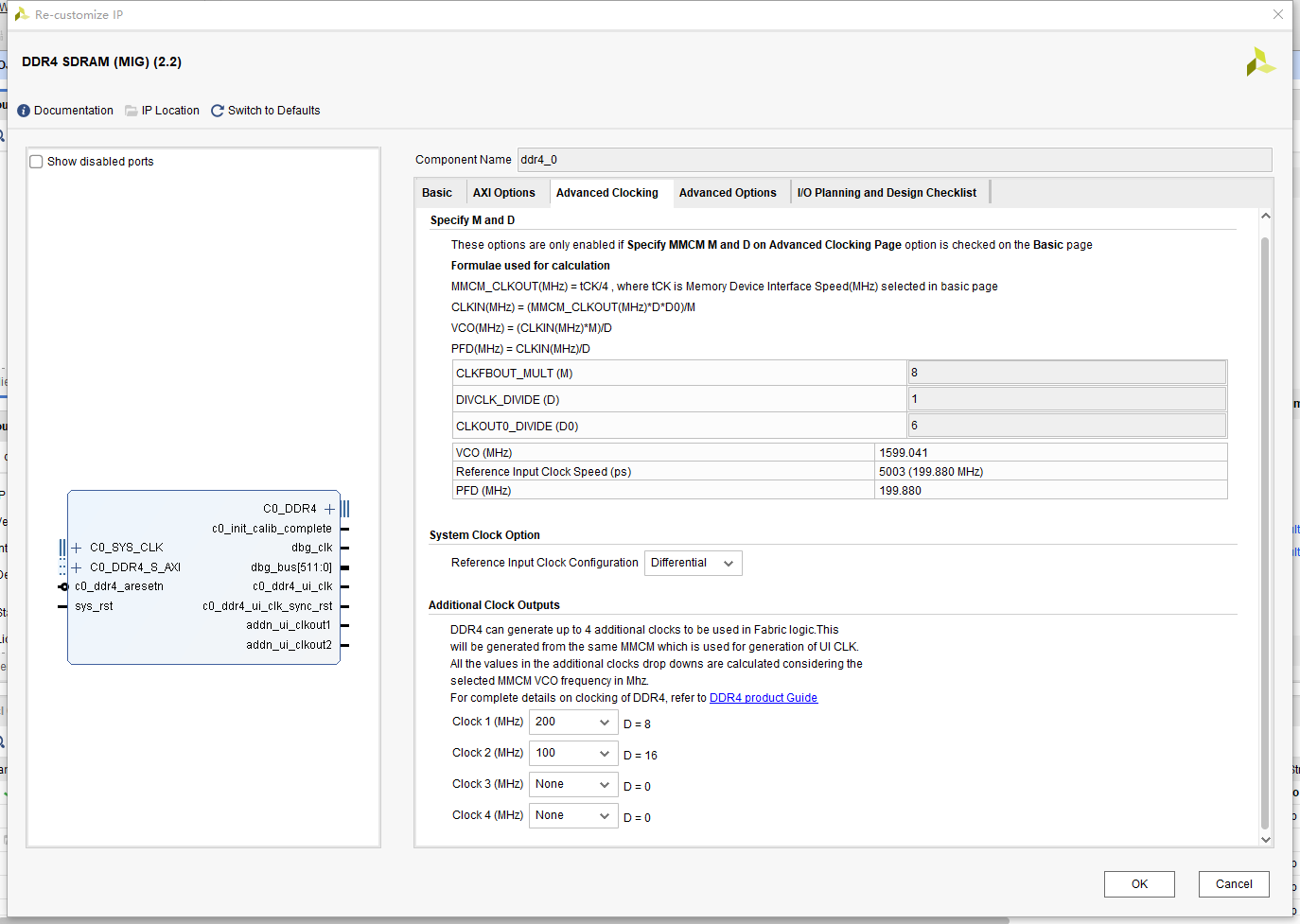
需要注意的是,系统时钟选择的是板子的晶振产生的200MHZ,所以参考时钟选择差分时钟;DDR4有4个时钟输出端口,在系统时钟给了DDR4后,其他模块需要用到的时钟可以在DDR4里边的Additional Clock Outputs 设置,这些时钟都通过BUFG输出到全局时钟,所以如果使用PLL进行进一步操作的时候,需要将时钟输入的source设置为Global buffer
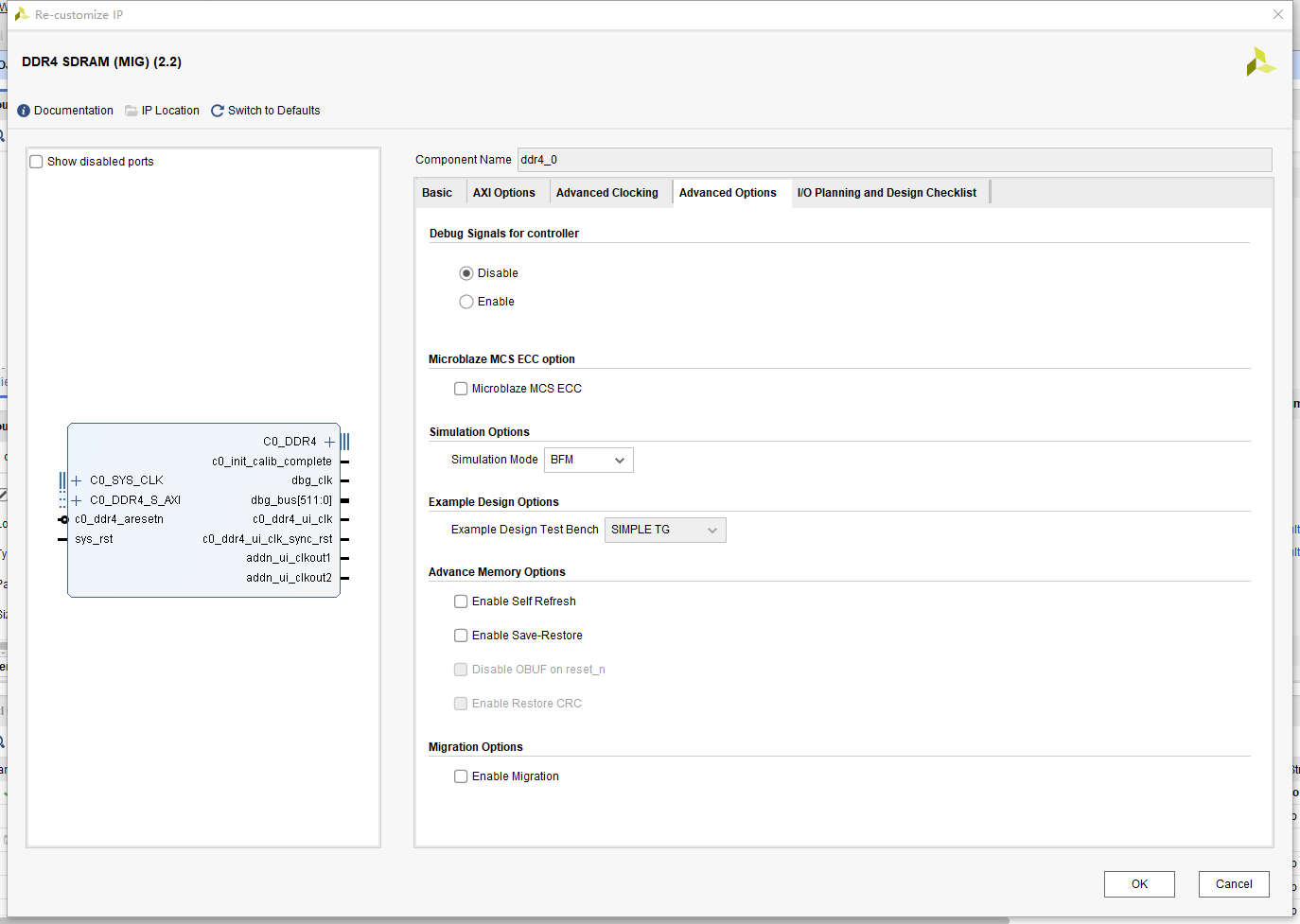
这里保持默认即可(Enable Self Refresh这个没选,不过也正常工作了,应该也勾选上吧)
在我的工程采用的是AXI 接口来进行读写DDR4
AXI_DDR
module axi4_master_ctrl(
//sys signals
input clk ,//ui_clk
input rst_n ,
// Write Address Ports
output wire [ 3:0] m_axi_awid ,
output reg [27:0] m_axi_awaddr ,
output wire [ 7:0] m_axi_awlen ,
output wire [ 2:0] m_axi_awsize ,
output wire [ 1:0] m_axi_awburst ,
output wire m_axi_awlock ,
output wire [ 3:0] m_axi_awcache ,
output wire [ 2:0] m_axi_awprot ,
output wire [ 3:0] m_axi_awqos ,
output reg m_axi_awvalid ,
input m_axi_awready ,
// Write Data Ports
output wire [127:0] m_axi_wdata ,
output wire [15:0] m_axi_wstrb ,
output wire m_axi_wlast ,
output reg m_axi_wvalid ,
input m_axi_wready ,
// Write Response Ports
input [ 3:0] m_axi_bid ,
input [ 1:0] m_axi_bresp ,
input m_axi_bvalid ,
output reg m_axi_bready ,
// Read Address Ports
output wire [ 3:0] m_axi_arid ,
output reg [27:0] m_axi_araddr ,
output wire [ 7:0] m_axi_arlen ,
output wire [ 2:0] m_axi_arsize ,
output wire [ 1:0] m_axi_arburst ,
output wire m_axi_arlock ,
output wire [ 3:0] m_axi_arcache ,
output wire [ 2:0] m_axi_arprot ,
output wire [ 3:0] m_axi_arqos ,
output reg m_axi_arvalid ,
input m_axi_arready ,
// Read Data Ports
input [ 3:0] m_axi_rid ,
input [127:0] m_axi_rdata ,
input [ 1:0] m_axi_rresp ,
input m_axi_rlast ,
input m_axi_rvalid ,
output reg m_axi_rready ,
//wfifo
input wr_trig ,
output wfifo_rd_en ,
input [127:0] wfifo_rd_data ,
//rfifo
input rd_trig ,
output rfifo_wr_en ,
output [127:0] rfifo_wr_data
);
//======================define===============
parameter AWADDR_MAX = 1920*1080*2-256;
parameter ARADDR_MAX = 1920*1080*2-256;
// SIM
// localparam AWADDR_MAX = 1024*2-256 ;
// localparam ARADDR_MAX = 1024*2-256 ;
reg [7:0] wr_cnt;
reg wr_work;
reg rd_work;
//==================main code================
assign m_axi_awid = 'd0;
//assign m_axi_awaddr = 'd64; //地址以Byte为单位
assign m_axi_awlen = 'd15;
assign m_axi_awsize = 'd4;
assign m_axi_awburst = 'd1;
assign m_axi_awlock = 'd0;
assign m_axi_awcache = 'd0;
assign m_axi_awprot = 'd0;
assign m_axi_awqos = 'd0;
//wr_work
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
wr_work <= 1'b0;
else if(m_axi_bready && m_axi_bvalid)
wr_work <= 1'b0;
else if(wr_trig && !wr_work)
wr_work <= 1'b1;
end
//write address
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
m_axi_awaddr <= 'd0;
else if(m_axi_awvalid && m_axi_awready && m_axi_awaddr == AWADDR_MAX)
m_axi_awaddr <= 'd0;
else if(m_axi_awvalid && m_axi_awready)
m_axi_awaddr <= m_axi_awaddr + 'd256;
end
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
m_axi_awvalid <= 1'b0;
else if(m_axi_awvalid && m_axi_awready)
m_axi_awvalid <= 1'b0;
else if(wr_trig && wr_work == 1'b0)
m_axi_awvalid <= 1'b1;
end
//write data
assign m_axi_wdata = wfifo_rd_data;
assign wfifo_rd_en = m_axi_wready & m_axi_wvalid;
assign m_axi_wlast = (wr_cnt == m_axi_awlen) ? 1'b1 : 1'b0;
assign m_axi_wstrb = 16'hffff;
always @(posedge clk or negedge rst_n) begin
if(rst_n == 1'b0)
m_axi_wvalid <= 1'b0;
else if(m_axi_wvalid == 1'b1 && m_axi_wready == 1'b1 && m_axi_wlast == 1'b1)
m_axi_wvalid <= 1'b0;
else if(wr_trig == 1'b1 && wr_work == 1'b0)
m_axi_wvalid <= 1'b1;
end
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
wr_cnt <= 'd0;
else if(m_axi_wready && m_axi_wvalid && m_axi_wlast)
wr_cnt <= 'd0;
else if(m_axi_wvalid && m_axi_wready)
wr_cnt <= wr_cnt + 1'b1;
end
//write response
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
m_axi_bready <= 1'b0;
else if(m_axi_bready && m_axi_bvalid)
m_axi_bready <= 1'b0;
else if(m_axi_wready && m_axi_wvalid && m_axi_wlast)
m_axi_bready <= 1'b1;
end
//=============================================================
//==========read==============================
//read address
assign m_axi_arid = 'd0;
//assign m_axi_awaddr = 'd64; //地址以Byte为单位
assign m_axi_arlen = 'd15;
assign m_axi_arsize = 'd4;
assign m_axi_arburst = 'd1;
assign m_axi_arlock = 'd0;
assign m_axi_arcache = 'd0;
assign m_axi_arprot = 'd0;
assign m_axi_arqos = 'd0;
//rd_work
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
rd_work <= 1'b0;
else if(m_axi_rready && m_axi_rvalid && m_axi_rlast)
rd_work <= 1'b0;
else if(rd_trig && !rd_work)
rd_work <= 1'b1;
end
//read address
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
m_axi_arvalid <= 1'b0;
else if(m_axi_arvalid && m_axi_arready)
m_axi_arvalid <= 1'b0;
else if(rd_trig && !rd_work)
m_axi_arvalid <= 1'b1;
end
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
m_axi_araddr <= 'd0;
else if(m_axi_arvalid && m_axi_arready && m_axi_araddr == ARADDR_MAX)
m_axi_araddr <= 'd0;
else if(m_axi_arvalid && m_axi_arready)
m_axi_araddr <= m_axi_araddr + 'd256;
end
always@(posedge clk or negedge rst_n)begin
if(!rst_n)
m_axi_rready <= 1'b0;
else if(m_axi_rready && m_axi_rvalid && m_axi_rlast)
m_axi_rready <= 1'b0;
else if(m_axi_arvalid && m_axi_arready)
m_axi_rready <= 1'b1;
end
//read data
assign rfifo_wr_data = m_axi_rdata;
assign rfifo_wr_en = m_axi_rready & m_axi_rvalid;
endmodule信号连接关系
axi4_master_ctrl axi4_master_ctrl_inst(
//sys signals
.sclk (ui_clk ),//ui_clk
.s_rst_n (pll0_locked) ,//init_calib_complete
// Write Address Ports
.m_axi_awid (m_axi_awid ),
.m_axi_awaddr (m_axi_awaddr ),
.m_axi_awlen (m_axi_awlen ),
.m_axi_awsize (m_axi_awsize ),
.m_axi_awburst (m_axi_awburst),
.m_axi_awlock (m_axi_awlock ),
.m_axi_awcache (m_axi_awcache),
.m_axi_awprot (m_axi_awprot ),
.m_axi_awqos (m_axi_awqos ),
.m_axi_awvalid (m_axi_awvalid),
.m_axi_awready (m_axi_awready),
// Write Data Ports
.m_axi_wdata (m_axi_wdata ) ,
.m_axi_wstrb (m_axi_wstrb ) ,
.m_axi_wlast (m_axi_wlast ) ,
.m_axi_wvalid (m_axi_wvalid ) ,
.m_axi_wready (m_axi_wready ) ,
// Write Response Ports
.m_axi_bid (m_axi_bid ),
.m_axi_bresp (m_axi_bresp ),
.m_axi_bvalid (m_axi_bvalid ),
.m_axi_bready (m_axi_bready ),
// Read Address Ports
.m_axi_arid (m_axi_arid ),
.m_axi_araddr (m_axi_araddr ),
.m_axi_arlen (m_axi_arlen ),
.m_axi_arsize (m_axi_arsize ),
.m_axi_arburst (m_axi_arburst ),
.m_axi_arlock (m_axi_arlock ),
.m_axi_arcache (m_axi_arcache ),
.m_axi_arprot (m_axi_arprot ),
.m_axi_arqos (m_axi_arqos ),
.m_axi_arvalid (m_axi_arvalid ),
.m_axi_arready (m_axi_arready ),
// Read Data Ports
.m_axi_rid (m_axi_rid ),
.m_axi_rdata (m_axi_rdata ),
.m_axi_rresp (m_axi_rresp ),
.m_axi_rlast (m_axi_rlast ),
.m_axi_rvalid (m_axi_rvalid),
.m_axi_rready (m_axi_rready),
//WFIFO
.wr_trig (wr_trig ),
.wfifo_rd_en (wfifo_rd_en ),
.wfifo_rd_data (wfifo_rd_data ),
// RFIFO
.hdmi_vs (hdmi_vs),
.rd_trig (rd_trig ),
.rfifo_wr_en (rfifo_wr_en ),
.rfifo_wr_data (rfifo_wr_data )
);
ddr4_0 ddr4_0_inst (
.c0_init_calib_complete (init_calib_complete), // output wire c0_init_calib_complete
// output wire dbg_clk
.c0_sys_clk_p(clk_200mhz_p), // input wire c0_sys_clk_p
.c0_sys_clk_n(clk_200mhz_n),
// output wire [511 : 0] dbg_bus
.c0_ddr4_adr (ddr4_adr ), // output wire [16 : 0] c0_ddr4_adr
.c0_ddr4_ba (ddr4_ba ), // output wire [1 : 0] c0_ddr4_ba
.c0_ddr4_cke (ddr4_cke ), // output wire [0 : 0] c0_ddr4_cke
.c0_ddr4_cs_n (ddr4_cs_n ), // output wire [0 : 0] c0_ddr4_cs_n
.c0_ddr4_dm_dbi_n (ddr4_dm_dbi_n ), // inout wire [1 : 0] c0_ddr4_dm_dbi_n
.c0_ddr4_dq (ddr4_dq ), // inout wire [15 : 0] c0_ddr4_dq
.c0_ddr4_dqs_c (ddr4_dqs_c ), // inout wire [1 : 0] c0_ddr4_dqs_c
.c0_ddr4_dqs_t (ddr4_dqs_t ), // inout wire [1 : 0] c0_ddr4_dqs_t
.c0_ddr4_odt (ddr4_odt ), // output wire [0 : 0] c0_ddr4_odt
.c0_ddr4_bg (ddr4_bg ), // output wire [0 : 0] c0_ddr4_bg
.c0_ddr4_reset_n (ddr4_reset_n ), // output wire c0_ddr4_reset_n
.c0_ddr4_act_n (ddr4_act_n ), // output wire c0_ddr4_act_n
.c0_ddr4_ck_c (ddr4_ck_c ), // output wire [0 : 0] c0_ddr4_ck_c
.c0_ddr4_ck_t (ddr4_ck_t ), // output wire [0 : 0] c0_ddr4_ck_t
.c0_ddr4_ui_clk (ui_clk ), // output wire c0_ddr4_ui_clk
.c0_ddr4_ui_clk_sync_rst (), // output wire c0_ddr4_ui_clk_sync_rst
.c0_ddr4_aresetn (pll0_locked), // input wire c0_ddr4_aresetn
.c0_ddr4_s_axi_awid (m_axi_awid), // input wire [3 : 0] c0_ddr4_s_axi_awid
.c0_ddr4_s_axi_awaddr (m_axi_awaddr), // input wire [29 : 0] c0_ddr4_s_axi_awaddr
.c0_ddr4_s_axi_awlen (m_axi_awlen), // input wire [7 : 0] c0_ddr4_s_axi_awlen
.c0_ddr4_s_axi_awsize (m_axi_awsize), // input wire [2 : 0] c0_ddr4_s_axi_awsize
.c0_ddr4_s_axi_awburst (m_axi_awburst), // input wire [1 : 0] c0_ddr4_s_axi_awburst
.c0_ddr4_s_axi_awlock (m_axi_awlock), // input wire [0 : 0] c0_ddr4_s_axi_awlock
.c0_ddr4_s_axi_awcache (m_axi_awcache), // input wire [3 : 0] c0_ddr4_s_axi_awcache
.c0_ddr4_s_axi_awprot (m_axi_awprot), // input wire [2 : 0] c0_ddr4_s_axi_awprot
.c0_ddr4_s_axi_awqos (m_axi_awqos), // input wire [3 : 0] c0_ddr4_s_axi_awqos
.c0_ddr4_s_axi_awvalid (m_axi_awvalid), // input wire c0_ddr4_s_axi_awvalid
.c0_ddr4_s_axi_awready (m_axi_awready), // output wire c0_ddr4_s_axi_awready
.c0_ddr4_s_axi_wdata (m_axi_wdata), // input wire [127 : 0] c0_ddr4_s_axi_wdata
.c0_ddr4_s_axi_wstrb (m_axi_wstrb), // input wire [15 : 0] c0_ddr4_s_axi_wstrb
.c0_ddr4_s_axi_wlast (m_axi_wlast), // input wire c0_ddr4_s_axi_wlast
.c0_ddr4_s_axi_wvalid (m_axi_wvalid), // input wire c0_ddr4_s_axi_wvalid
.c0_ddr4_s_axi_wready (m_axi_wready), // output wire c0_ddr4_s_axi_wready
.c0_ddr4_s_axi_bready (m_axi_bready), // input wire c0_ddr4_s_axi_bready
.c0_ddr4_s_axi_bid (m_axi_bid), // output wire [3 : 0] c0_ddr4_s_axi_bid
.c0_ddr4_s_axi_bresp (m_axi_bresp), // output wire [1 : 0] c0_ddr4_s_axi_bresp
.c0_ddr4_s_axi_bvalid (m_axi_bvalid), // output wire c0_ddr4_s_axi_bvalid
.c0_ddr4_s_axi_arid (m_axi_arid), // input wire [3 : 0] c0_ddr4_s_axi_arid
.c0_ddr4_s_axi_araddr (m_axi_araddr), // input wire [29 : 0] c0_ddr4_s_axi_araddr
.c0_ddr4_s_axi_arlen (m_axi_arlen), // input wire [7 : 0] c0_ddr4_s_axi_arlen
.c0_ddr4_s_axi_arsize (m_axi_arsize), // input wire [2 : 0] c0_ddr4_s_axi_arsize
.c0_ddr4_s_axi_arburst (m_axi_arburst), // input wire [1 : 0] c0_ddr4_s_axi_arburst
.c0_ddr4_s_axi_arlock (m_axi_arlock), // input wire [0 : 0] c0_ddr4_s_axi_arlock
.c0_ddr4_s_axi_arcache (m_axi_arcache), // input wire [3 : 0] c0_ddr4_s_axi_arcache
.c0_ddr4_s_axi_arprot (m_axi_arprot), // input wire [2 : 0] c0_ddr4_s_axi_arprot
.c0_ddr4_s_axi_arqos (m_axi_arqos), // input wire [3 : 0] c0_ddr4_s_axi_arqos
.c0_ddr4_s_axi_arvalid (m_axi_arvalid), // input wire c0_ddr4_s_axi_arvalid
.c0_ddr4_s_axi_arready (m_axi_arready), // output wire c0_ddr4_s_axi_arready
.c0_ddr4_s_axi_rready (m_axi_rready), // input wire c0_ddr4_s_axi_rready
.c0_ddr4_s_axi_rlast (m_axi_rlast), // output wire c0_ddr4_s_axi_rlast
.c0_ddr4_s_axi_rvalid (m_axi_rvalid), // output wire c0_ddr4_s_axi_rvalid
.c0_ddr4_s_axi_rresp (m_axi_rresp), // output wire [1 : 0] c0_ddr4_s_axi_rresp
.c0_ddr4_s_axi_rid (m_axi_rid), // output wire [3 : 0] c0_ddr4_s_axi_rid
.c0_ddr4_s_axi_rdata (m_axi_rdata), // output wire [127 : 0] c0_ddr4_s_axi_rdata
.addn_ui_clkout1(clk_200m),
.addn_ui_clkout2(clk_100m),
.dbg_clk ( ),
.dbg_bus ( ),
.sys_rst ( ) // input wire sys_rst
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号