
JVM
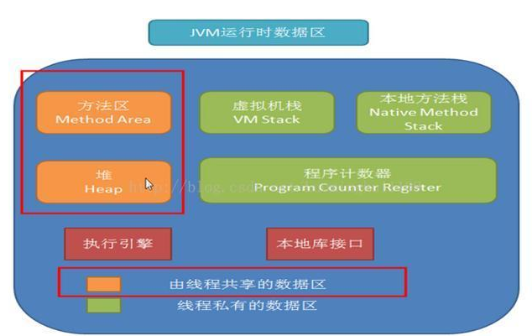
(1) Native Method Stack本地方法栈
它的具体做法是Native Method Stack中登记native方法,在Execution Engine执行时加载native libraies。
(2) PC Register程序计数器
每个线程都有一个程序计算器,就是一个指针,指向方法区中的方法字节码(下一个将要执行的指令代码),由执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不记。
(3) Method Area方法区
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法如构造函数,接口代码也在此定义。简单说,所有定义的方法的信息都保存在该区域,此区域属于共享区间。
静态变量+常量+类信息+运行时常量池存在方法区中,实例变量存在堆内存中。
(4) Stack 栈
① 栈是什么
栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题,只要线程一结束该栈就Over,生命周期和线程一致,是线程私有的。
基本类型的变量和对象的引用变量都是在函数的栈内存中分配。
② 栈存储什么?
栈帧中主要保存3类数据:
本地变量(Local Variables):输入参数和输出参数以及方法内的变量;
栈操作(Operand Stack):记录出栈、入栈的操作;
栈帧数据(Frame Data):包括类文件、方法等等。
③ 栈运行原理
栈中的数据都是以栈帧(Stack Frame)的格式存在,栈帧是一个内存区块,是一个数据集,是一个有关方法和运行期数据的数据集,当一个方法A被调用时就产生了一个栈帧F1,并被压入到栈中,A方法又调用了B方法,于是产生栈帧F2也被压入栈,B方法又调用了C方法,于是产生栈帧F3也被压入栈…… 依次执行完毕后,先弹出后进......F3栈帧,再弹出F2栈帧,再弹出F1栈帧。
遵循“先进后出”/“后进先出”原则。
(5) Heap 堆
堆这块区域是JVM中最大的,应用的对象和数据都是存在这个区域,这块区域也是线程共享的,也是 gc 主要的回收区,一个 JVM 实例只存在一个堆类存,堆内存的大小是可以调节的。类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,以方便执行器执行,堆内存分为三部分:
//////////////////////////////////////////////////////////////////////////////////////////////////////

内存空间:
JVM内存空间包含:方法区、java堆、java栈、本地方法栈。
方法区是各个线程共享的区域,存放类信息、常量、静态变量。
java堆也是线程共享的区域,我们的类的实例就放在这个区域,可以想象你的一个系统会产生很多实例,因此java堆的空间也是最大的。如果java堆空间不足了,程序会抛出OutOfMemoryError异常。
java栈是每个线程私有的区域,它的生命周期与线程相同,一个线程对应一个java栈,每执行一个方法就会往栈中压入一个元素,这个元素叫“栈帧”,而栈帧中包括了方法中的局部变量、用于存放中间状态值的操作栈,这里面有很多细节,我们以后再讲。如果java栈空间不足了,程序会抛出StackOverflowError异常,想一想什么情况下会容易产生这个错误,对,递归,递归如果深度很深,就会执行大量的方法,方法越多java栈的占用空间越大。
本地方法栈角色和java栈类似,只不过它是用来表示执行本地方法的,本地方法栈存放的方法调用本地方法接口,最终调用本地方法库,实现与操作系统、硬件交互的目的。
PC寄存器,说到这里我们的类已经加载了,实例对象、方法、静态变量都去了自己改去的地方,那么问题来了,程序该怎么执行,哪个方法先执行,哪个方法后执行,这些指令执行的顺序就是PC寄存器在管,它的作用就是控制程序指令的执行顺序。
执行引擎当然就是根据PC寄存器调配的指令顺序,依次执行程序指令。
一 jvm结构
jvm的内部结构如下图所示,这张图很清楚形象的描绘了整个JVM的内部结构,以及各个部分之间的交互和作用。
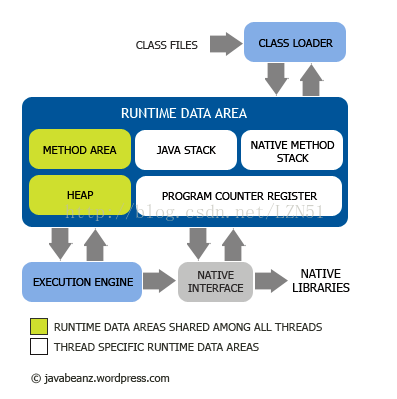
1 Class Loader(类加载器)就是将Class文件加载到内存,再说的详细一点就是,把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是类加载器的作用。
2 Run Data Area(运行时数据区) 就是我们常说的JVM管理的内存了,也是我们这里主要讨论的部分。运行数据区是整个JVM的重点。我们所有写的程序都被加载到这里,之后才开始运行。这部分也是我们这里将要讨论的重点。
3 Execution engine(执行引擎) 是Java虚拟机最核心的组成部分之一。执行引擎用于执行指令,不同的java虚拟机内部实现中,执行引擎在执行Java代码的时候可能有解释执行(解释器执行)和编译执行(通过即时编译器产生本地代码执行,例如BEA JRockit),也有可能两者兼备。任何JVM specification实现(JDK)的核心都是Execution engine,不同的JDK例如Sun 的JDK 和IBM的JDK好坏主要就取决于他们各自实现的Execution engine的好坏。
4 Native interface 与native libraries交互,是其它编程语言交互的接口。当调用native方法的时候,就进入了一个全新的并且不再受虚拟机限制的世界,所以也很容易出现JVM无法控制的native heap OutOfMemory。
二 Run Data Area(运行时数据区)
|
数据 |
描述 |
|
Program Counter Register |
程序计数器,线程私有、指向下一条要很执行的指令 |
|
Java Stack |
Java虚拟机栈,线程私有,生命周期与线程相同。描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口 |
|
Native Method Stack |
为虚拟机使用到的Native 方法服务 |
|
Heap |
线程共享,由于现在收集器基本采用的分代收集算法,所以Java堆中还可以细分:新生代和老生代;更细致一点的有Eden空间、From Survivor空间、To Survivor空间等。所有的对象实例以及数组都要在堆上分配,是垃圾收集器管理的主要区域 |
|
Method Area |
方法区,别名叫做非堆(Non-Heap),线程共享的内存区域。目的是与Java堆区分开来,存储类信息、常量、静态变量、即时编译器编译后的代码。 |
三 jmm
Java内存模型(Java Memory Model,JMM)JMM主要是为了规定了线程和内存之间的一些关系。根据JMM的设计,系统存在一个主内存(Main Memory),Java中所有变量都储存在主存中,对于所有线程都是共享的。每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是在工作内存中进行,线程之间无法相互直接访问,变量传递均需要通过主存完成。
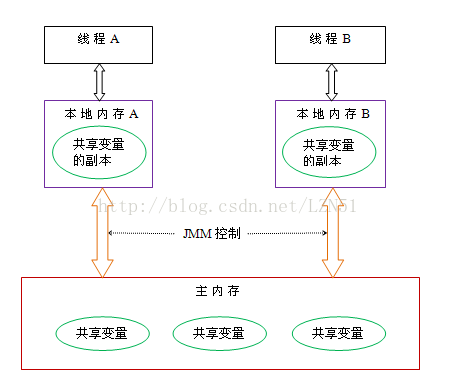
四 jvm和jmm之间的关系
jmm中的主内存、工作内存与jvm中的Java堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来,那从变量、主内存、工作内存的定义来看,主内存主要对应于Java堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域。从更低层次上说,主内存就直接对应于物理硬件的内存,而为了获取更好的运行速度,虚拟机(甚至是硬件系统本身的优化措施)可能会让工作内存优先存储于寄存器和高速缓存中,因为程序运行时主要访问读写的是工作内存。
以上是本人浏览各路大神的一点点总结,如涉及到侵犯问题,请及时联系,新手上路,多多指教。如遇大神,请斧正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号