
6-12 SVM小结
介绍了SVM的概念以及如何利用SVM进行一个身高体重的训练和预测。如果类别比较简单的话,那么在二维空间上它有可能就是一条直线。如果类别比较复杂,那么投影到高维空间上它就是一个超平面。所以SVM的本质它就是寻求这样一个最优的超平面。超平面只要找到了,那么就可以利用这个超平面完成分类问题。
SVM支持很多核,这里主要使用线性核。
数据准备。数据也称为训练样本。在准备训练样本的时候需要注意几个地方,第一它需要有正负样本两种情况。第二正样本和负样本的个数不一定要完全相同,也有可能是1:2、1:3甚至是2:3、2:4,任意的组合都可以。
在准备样本的时候一定要准备一个label标签。这个label标签运用唯一的描述当前的训练数据。而正是因为有了这个label标签,所以它也是一个监督学习的过程。监督学习就是说在学习一个数据的时候,要监督一下它的对和错。比如说学习一个[152,53],来判断一下它是0和1。那么我们可以用1来监督它,1表明它就是男生的身高和体重。这是数据的问题。
如果大家对SVM的算法推导这方面感兴趣的话,大家可以课下找一些相关的资料和书籍来仔细地研究一下它到底是如何进行公式推导。
Hog特征区别于Haar特征,Hog特征更加地复杂,而且适用场景也不同。
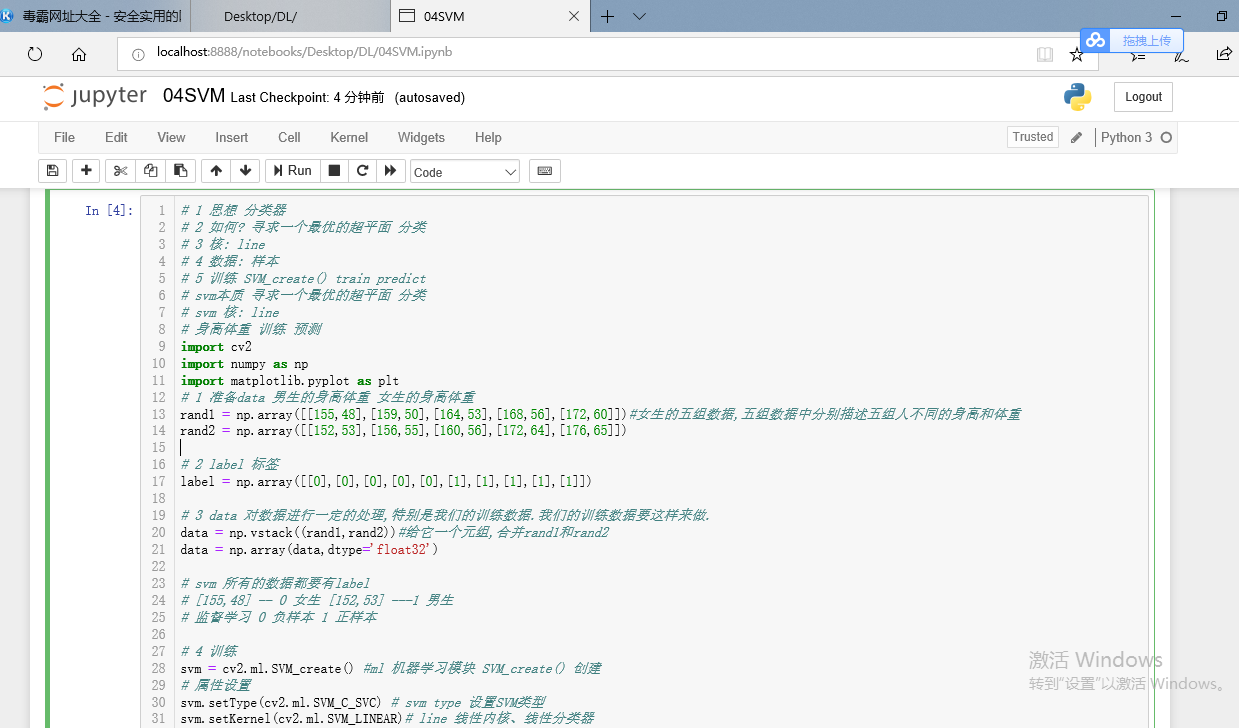
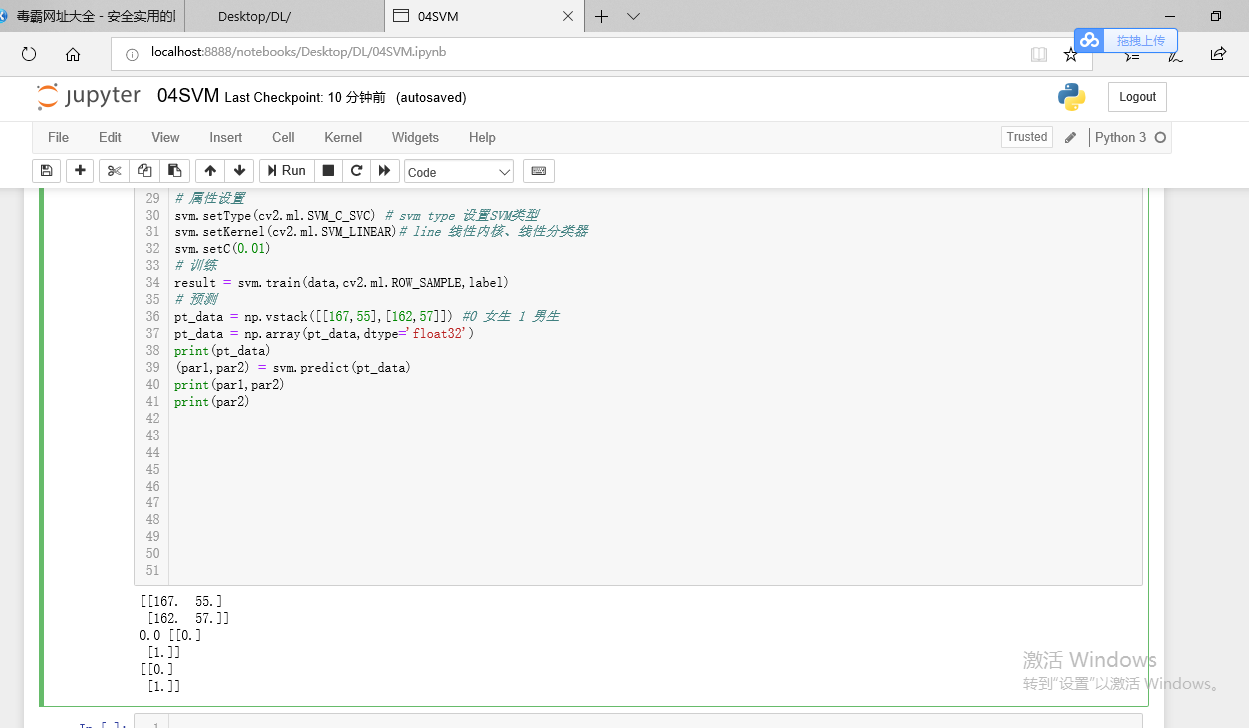
# 1 思想 分类器 # 2 如何? 寻求一个最优的超平面 分类 # 3 核: line # 4 数据: 样本 # 5 训练 SVM_create() train predict # svm本质 寻求一个最优的超平面 分类 # svm 核: line # 身高体重 训练 预测 import cv2 import numpy as np import matplotlib.pyplot as plt # 1 准备data 男生的身高体重 女生的身高体重 rand1 = np.array([[155,48],[159,50],[164,53],[168,56],[172,60]])#女生的五组数据,五组数据中分别描述五组人不同的身高和体重 rand2 = np.array([[152,53],[156,55],[160,56],[172,64],[176,65]]) # 2 label 标签 label = np.array([[0],[0],[0],[0],[0],[1],[1],[1],[1],[1]]) # 3 data 对数据进行一定的处理,特别是我们的训练数据.我们的训练数据要这样来做. data = np.vstack((rand1,rand2))#给它一个元组,合并rand1和rand2 data = np.array(data,dtype='float32') # svm 所有的数据都要有label # [155,48] -- 0 女生 [152,53] ---1 男生 # 监督学习 0 负样本 1 正样本 # 4 训练 svm = cv2.ml.SVM_create() #ml 机器学习模块 SVM_create() 创建 # 属性设置 svm.setType(cv2.ml.SVM_C_SVC) # svm type 设置SVM类型 svm.setKernel(cv2.ml.SVM_LINEAR)# line 线性内核、线性分类器 svm.setC(0.01) # 训练 result = svm.train(data,cv2.ml.ROW_SAMPLE,label) # 预测 pt_data = np.vstack([[167,55],[162,57]]) #0 女生 1 男生 pt_data = np.array(pt_data,dtype='float32') print(pt_data) (par1,par2) = svm.predict(pt_data) print(par1,par2) print(par2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号