

【知识强化】第五章 中央处理器 5.5 指令流水线
下面我们进入流水线的学习,这是本章当中最容易考到的一个知识点,所以大家一定要提起精神。

我们来看一下,我们整个中央处理器,也就是我们的第五章,分为五个小节。我们在之前已经把CPU的功能和结构,指令的执行过程,数据通路的功能和基本结构,以及控制器的功能和工作原理都给大家讲完了。那么,到这里,我们所有的CPU它的功能,它的结构,以及它是如何工作的都已经给大家完全地讲完了。最后的第五节是用来干什么的呢?是用来提高我们CPU的工作效率的。那么为什么要引入流水线的结构,显然就是为了提高我们的工作效率。那么有哪些结构?那么引入流水线会带来哪样的问题,那么这就是我们整个第五节要解决的。那么第一节的内容呢我们先把流水线的简单的知识,以及它的一些性能指标给大家讲一下。可能和书上的顺序不太一样,但是呢大家把这个搞清楚之后,我们再来去详细地去研究我们的流水线。
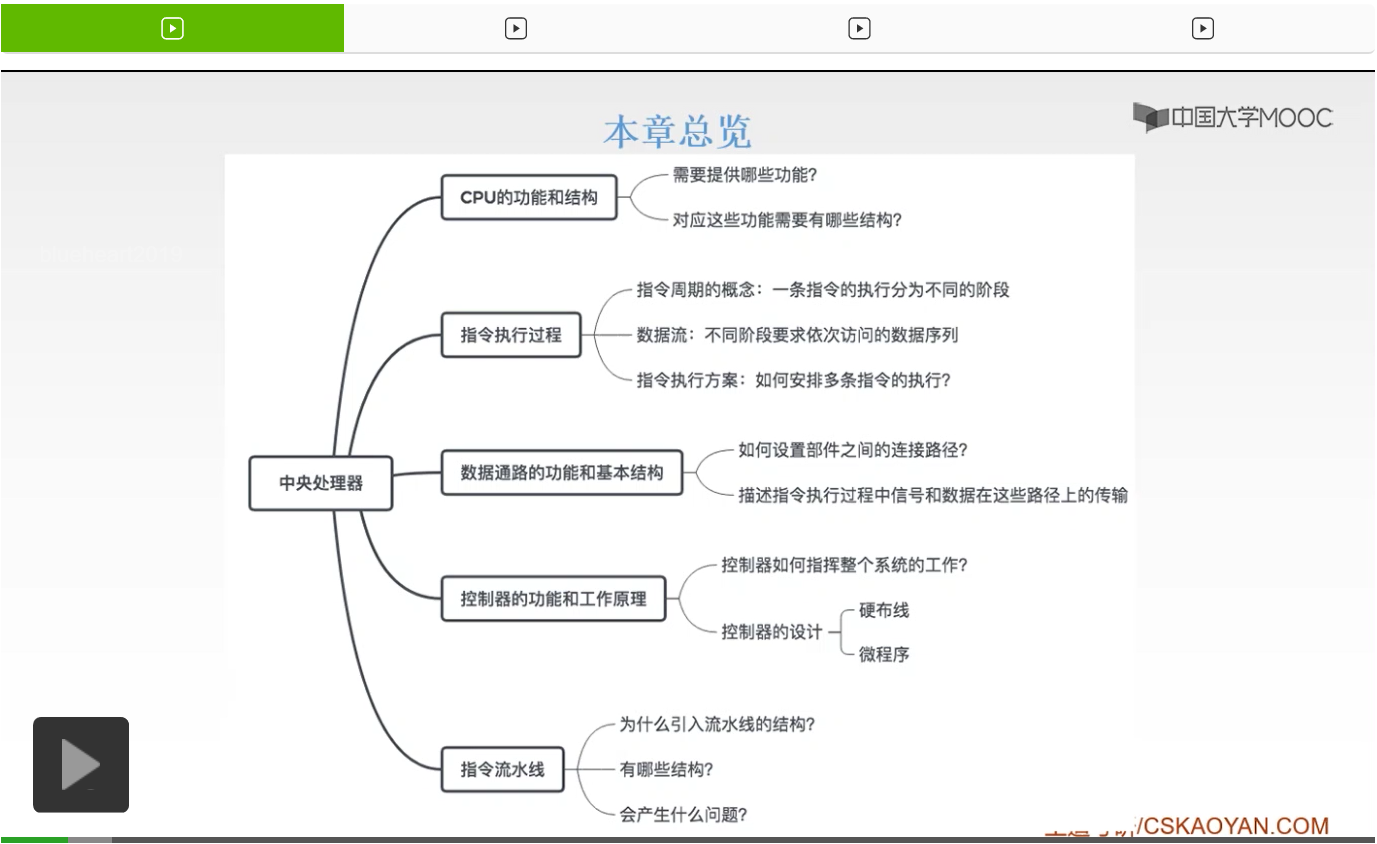
好,我们先来看一下什么叫做流水线。流水线大家应该听过好多次了,也就是说我们的一条指令,它的执行过程,可以分成多个阶段,或者说呢我们可以把它分成多个过程。那么根据不同的计算机呢,我们可以分成不同的这样的阶段和过程。

那么一般来说呢,我们是把它分位取指阶段,分析阶段和执行阶段的。那么什么叫做取指阶段呢?
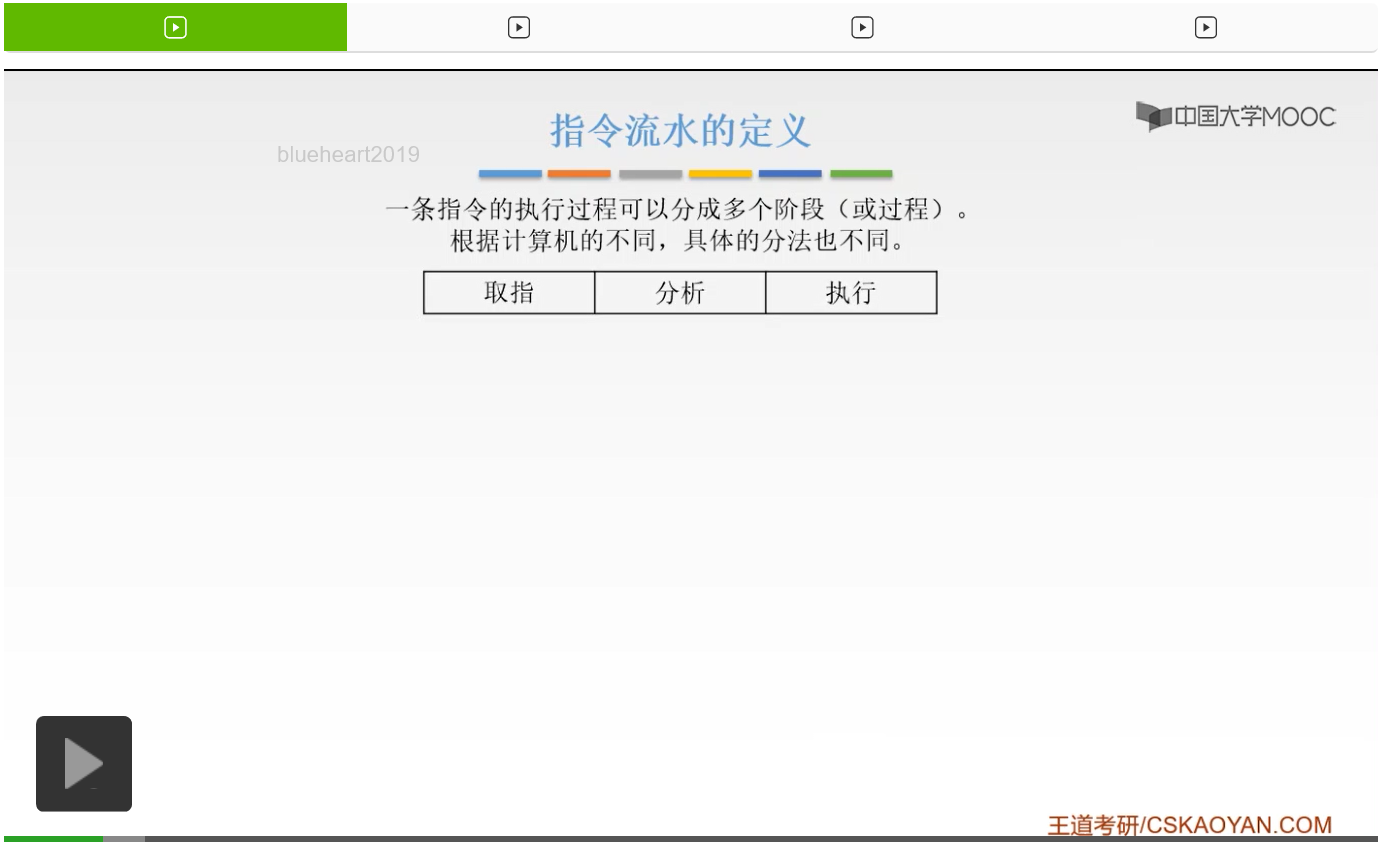
取指阶段,也就是根据我们的PC内容去访问我们的主存,然后呢根据我们的地址然后把主存当中的内容去取到我们的IR当中。那么,这就是取址阶段的它的任务。
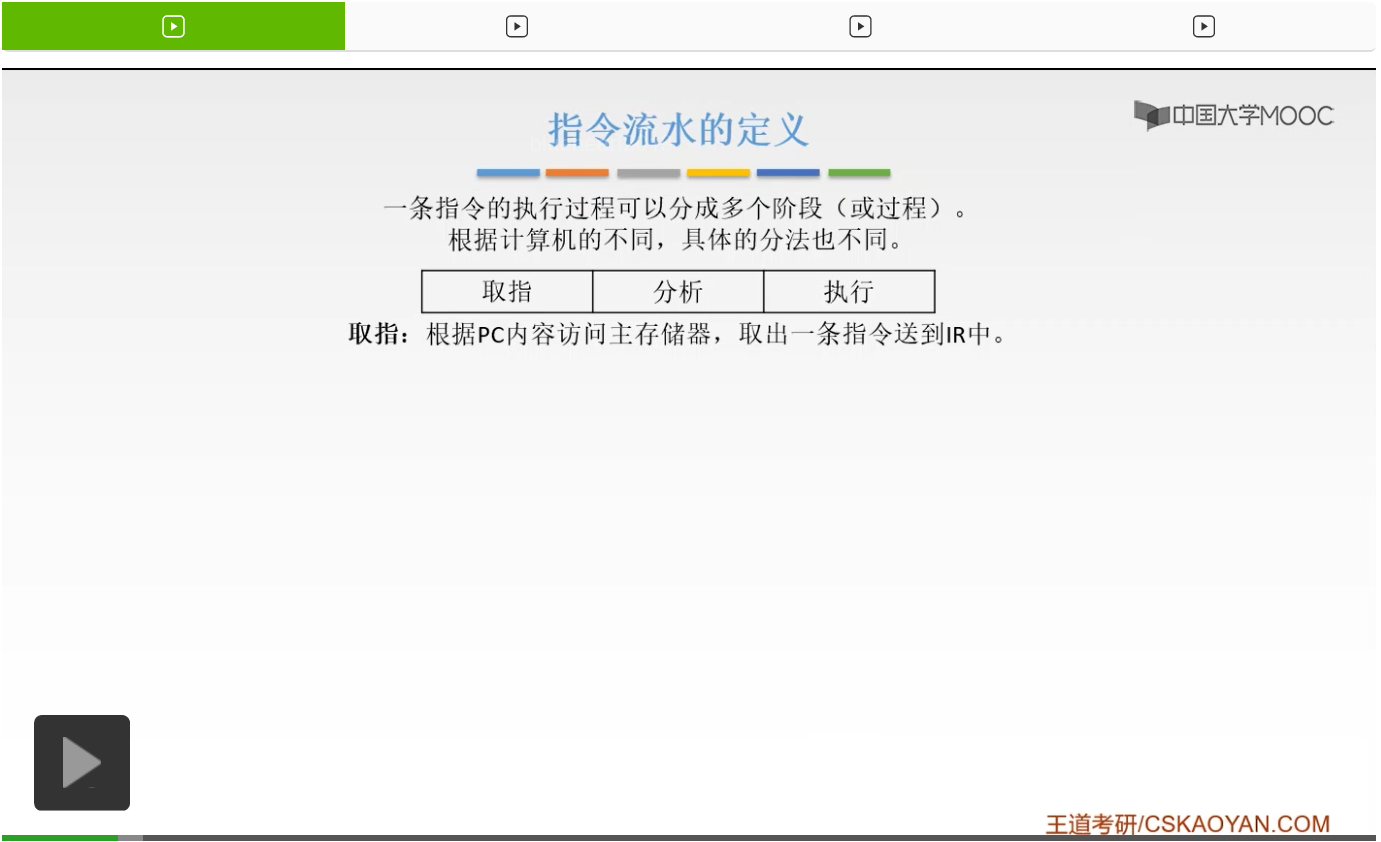
分析阶段是干什么的呢?分析阶段就是根据我们所取到的这条指令,然后对它的操作码的部分进行译码,然后呢根据我们指令的一个寻址方式,然后和我们地址字段当中的内容形成我们操作数的有效地址,也就是EA。然后从有效地址当中取出我们的操作数。这个就是我们的第四章所完成的内容对吧。

最后是执行阶段。执行阶段就是根据我们的操作码字段去完成我们这个指令要我们去干什么,由我们去执行,然后把我们的结果再写回到寄存器或者我们的主存当中。那么一般来说,一条指令,从取指到分析到执行,
好的,从这一节课开始,我们来分析一下指令流水线的影响因素。
我们来回顾上一节讲过的内容。我们把指令流水线的一些重要的东西都已经给大家讲完了。把它的基本概念,以及表示方法给大家讲了一下。基本概念就是说,什么叫流水线?为什么要采用流水线技术呢?就是为了提高我们的执行效率。因为我们的指令的执行过程,我们可以把它分解成不同的阶段,然后它每一个阶段呢占用的都是不同的资源,是互不影响的。所以我们就可以是,在同一个时刻,是把所有的资源都利用上,那么就使得多条指令能够同时执行。那么这就提高了我们的执行效率。那么表示指令流水线呢,有两种方法,第一种方法是指令流程图。它呢主要是用来分析我们流水线的技术,就比如我们这一节课将要用它来分析影响我们流水线的因素。那么第二种方法呢就是时空图,那么我们上一节课也使用时空图来分析了流水线的性能。那么说到流水线的性能呢,我们主要有三个性能指标。第一个叫做吞吐率,第二个叫做加速比,第三个叫做效率。它们的所有的公式,都一定要把它背下来,尤其重要的就是这个流水线,它的时间的计算,是如何计算的,大家一定要搞清楚。那么这个指令流水线啊,它有一个理想的情况。也就是说,我们假设各个阶段它花费的时间都是相同的,并且呢在每一个阶段执行结束之后,都能够进行下一个阶段都不需要等待,那么这是一种理想的情况。但是实际的流水线呢,并不能够满足我们这种理想的情况,那么这就导致了我们流水线性能的下降。所有我们这一节课,就要来分析一下,流水线的影响因素,以及它的解决方法。
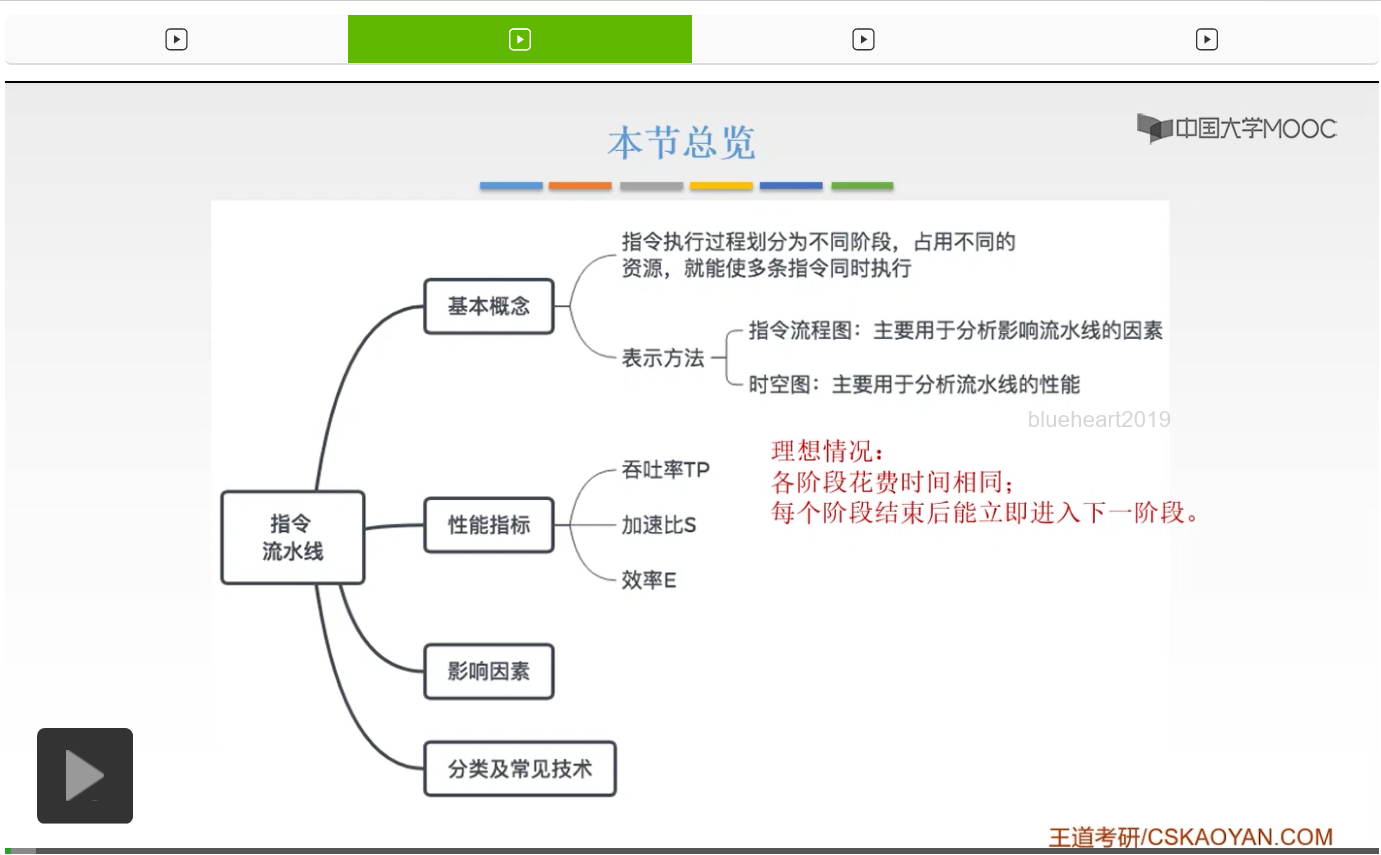
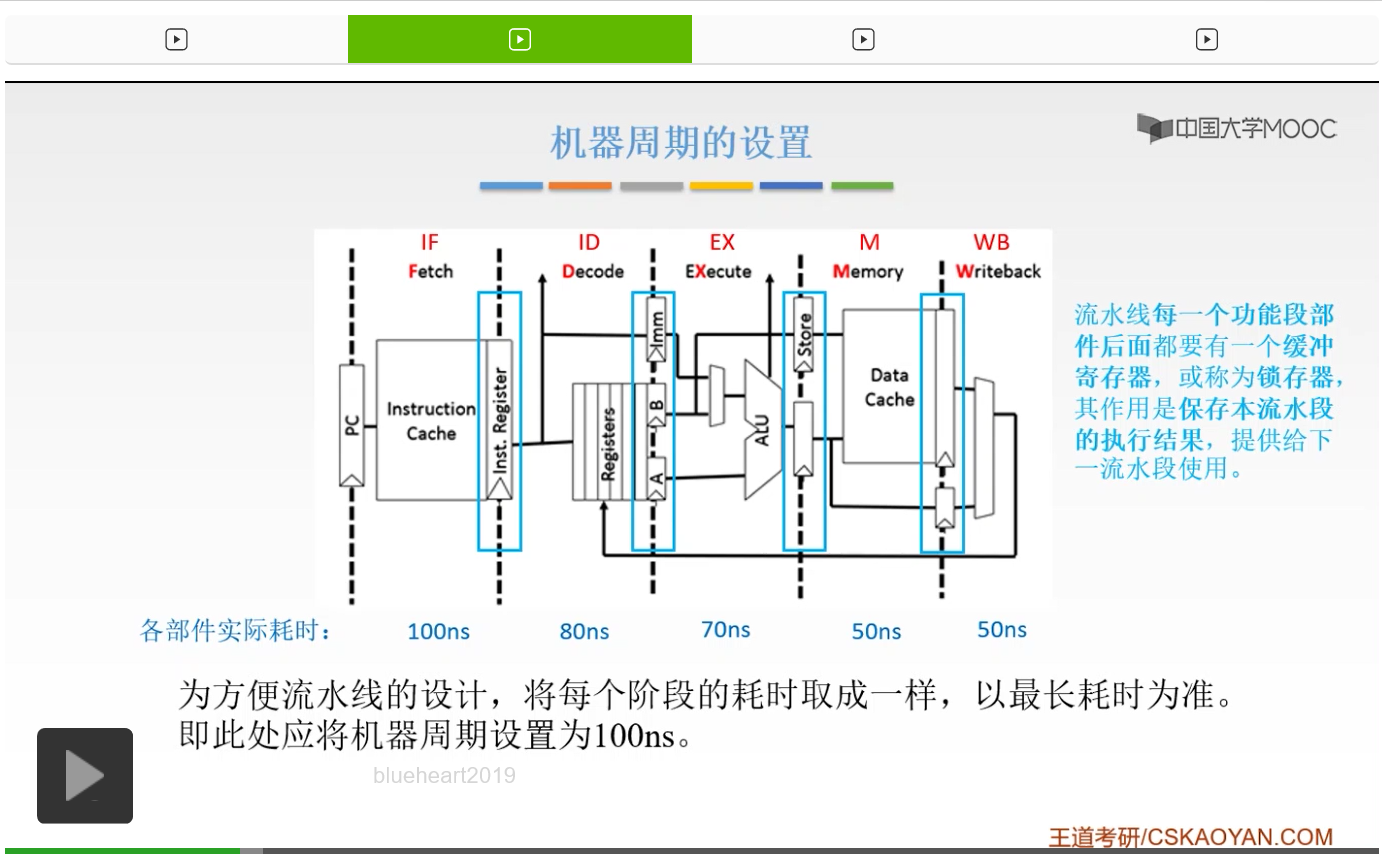
那么我们首先来看一下,我们呢把一个指令分成这五个执行阶段。那么这是一般的划分方法,也是最常用的划分方法,就是把它分成五段。哪五段呢?

第一段呢是取指,我们把它记为IF。第二个呢叫译码,我们把它记为ID。第三段呢叫做执行,我们把它记为EX。第四个呢我们把它记为访存,也就是把它记成M,也就是Memory。最后一个呢是写回,Writeback,所以我们把它记为WB。所以呢一般来说,我们常用的就是把一条指令的执行过程分成五个执行阶段。那么这五个阶段呢,是采用的不同的硬件资源,所以呢是能够互不影响互不干扰的。那么我们可以看到啊,就是第一个阶段取指阶段,和第四个阶段访存阶段,我们呢是为了采用不同的硬件资源,我们呢就把这个存储器啊,划分为指令存储器和数据存储器。所以呢在取指阶段和访存阶段,访存呢就是去取数的阶段呢我们是互不干扰的。所以,这样的硬件资源都是独立的。也就是Instruction Cache和这个Data Cache,它呢是独立的。所以呢在第一阶段和第四阶段它是互不干扰的。那么这就是一般的一条指令的划分方法以及它占用的一些硬件资源。那么这一张图呢,大家看一下就知道了。重点呢就是我们的这五个阶段,IF、ID、EX、M和WB,要把它知道是什么意思。那么我们之前说过理想情况就是说这五个阶段,每一个阶段它花费的时间应该是相等的,但是实际上这五个阶段时间不可能是完全一样的。
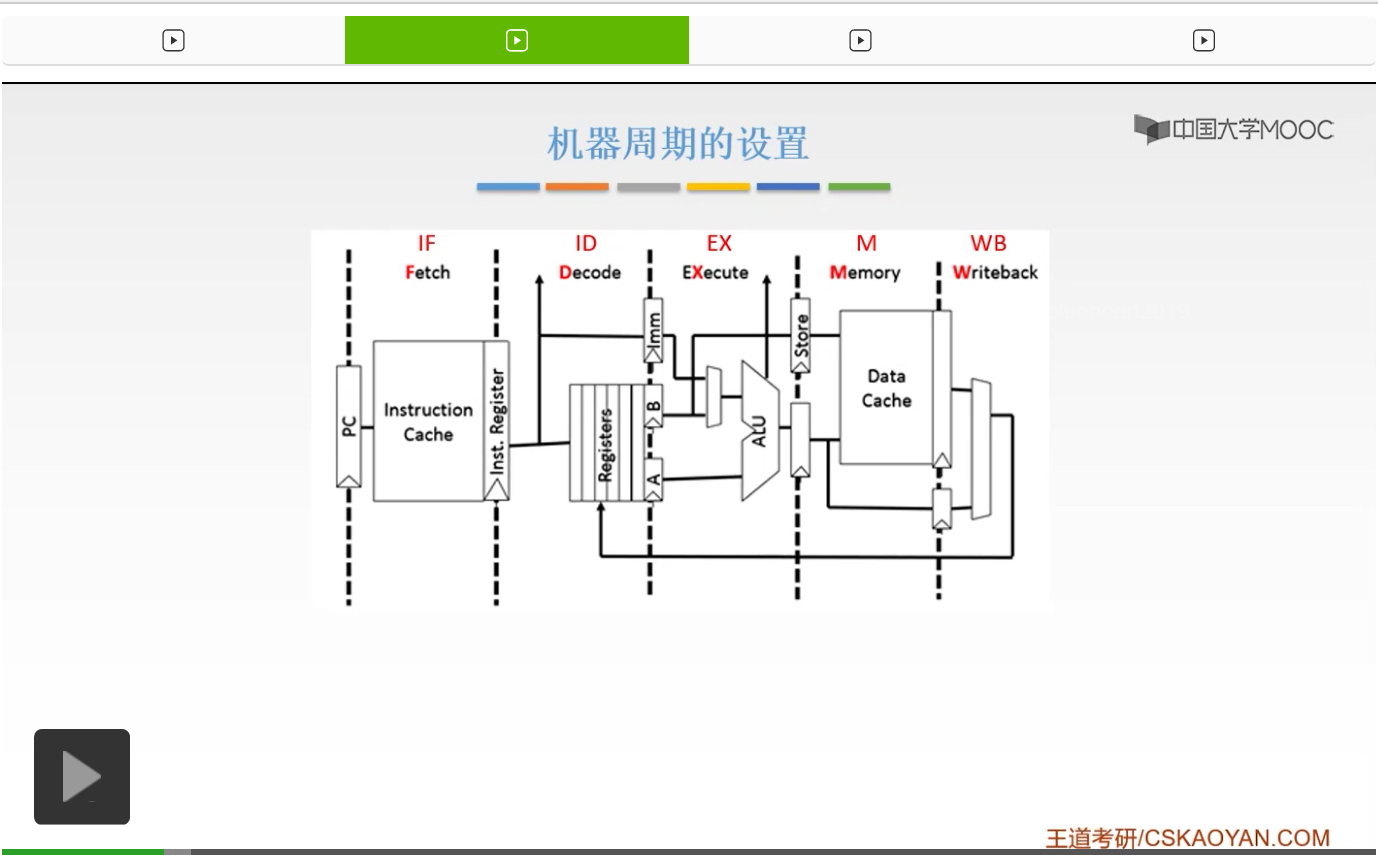
各部件的实际耗时呢,取指阶段它的耗时是最长的,达到100ns,其余呢都比它要短一点。但是呢它们之间也是有着细微的差距的。所以为了使我们能够达到理想的这样的情况,也就是说我们的每一个阶段,它的耗时都应该是相等的。并且呢,在一个阶段执行结束之后,能够立刻进入下一个阶段,不需要等待。
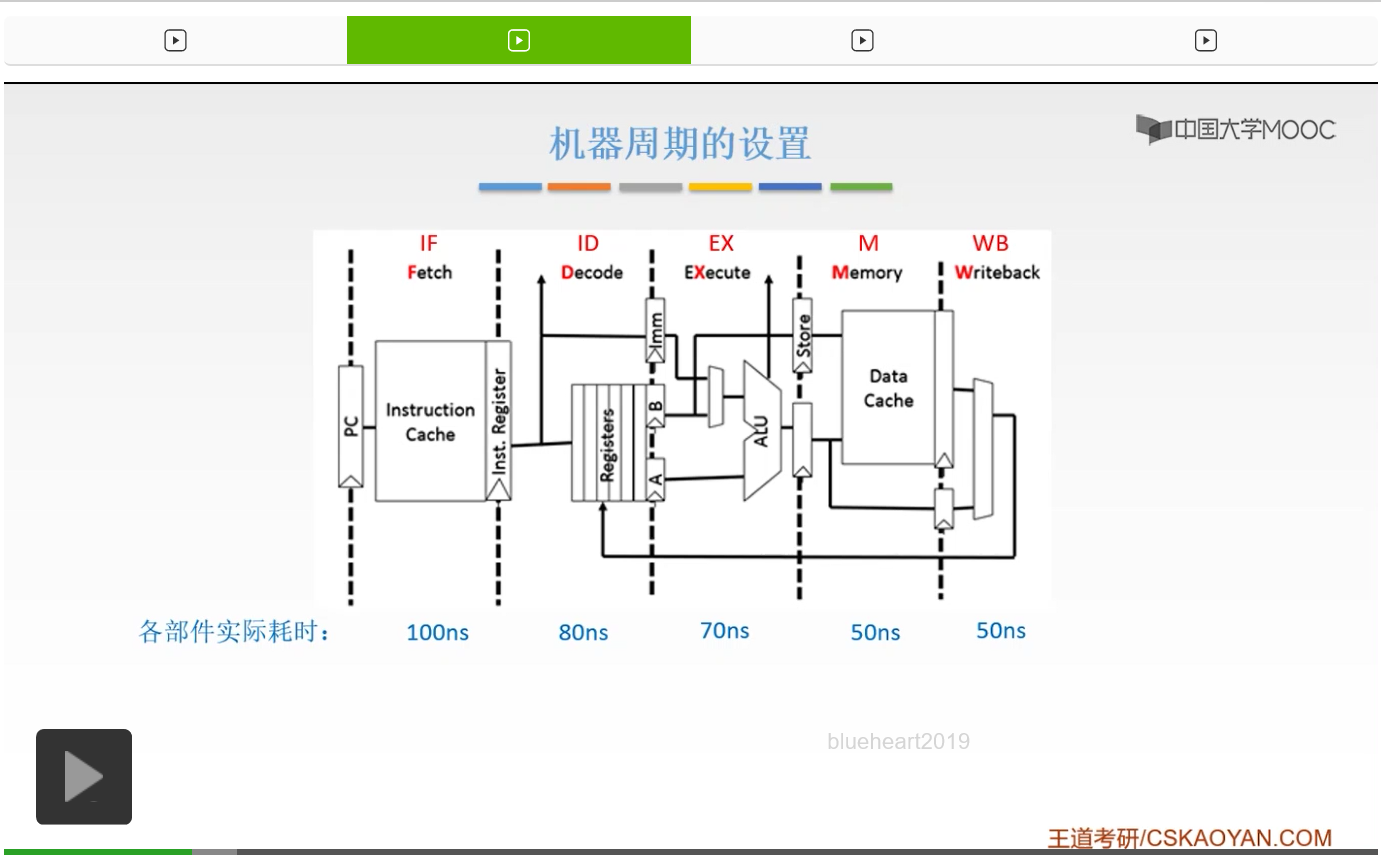
所以呢我们就把最长的这个取指阶段的耗时,也就是这100纳秒,我们呢就把每一个阶段都取成这样的100ns。所以呢我们就把机器周期设置为100ns。
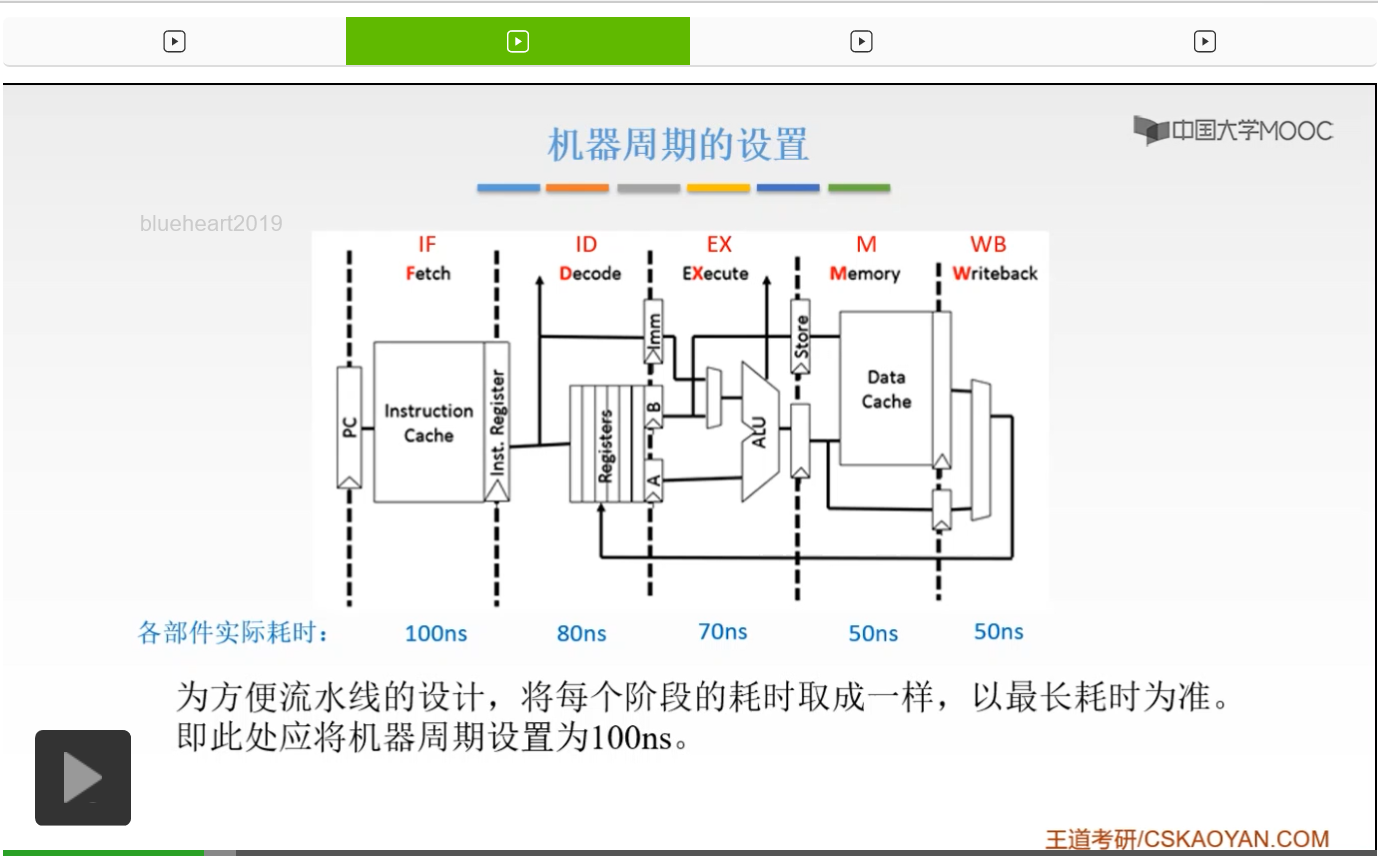
除了这一方面的设计,我们为了使第二个条件也就是说我们一个指令、一个阶段执行结束之后,能够立刻地进入下一个阶段,所以呢我们还要在下面,在每一个阶段的最后,加上寄存器。也就是说我们万一这个阶段提前结束了,那么这个数据并不能够立刻地进入到下一个阶段,为什么呢?因为我们的另外的指令还在占用着我们的硬件资源,如果我们立刻把这一条数据传入到下一个阶段的硬件资源的话,必然会产生错误。所以我们要在每一个阶段的硬件后面都加一个寄存器,用来暂存我们提前完成的这样的数据。

所以呢在流水线的每一个功能段,它的部件后面,都必须有一个缓冲的这样的寄存器,或者呢把它称为锁存器。也就是说,要保存我们本流水段的这样的执行结果,然后提供给下一个流水段使用。那么为什么不能够你一旦执行完了就立刻流入到下一个流水段呢?是为了防止产生数据的混淆、数据的干扰而产生错误。因为我们知道,我们这一条指令执行完了的时候,如果下一个流水段,它的那条指令还在占用着我们的硬件资源,你这样一旦流入到里面之后,这样的数据必然会产生干扰,也就必然会出现错误,所以我们必须要有一个缓冲的寄存器。好的,这个我们把机器周期的设置以及这样的硬件资源,还有我们指令阶段的这样的划分,都给大家简单地提了一下。
那么我们就来看一下,影响流水线的这样的因素。一般来说呢,影响流水线的因素有这三个,第一个叫做结构相关,也把它称为资源冲突。第二个呢叫做数据相关,也可以是称为数据冲突。第三个叫做控制相关,也可以称为控制冲突。我们来一一地分析一下这三种影响流水线的这样的因素,它是如何来影响流水线的,它为什么能够影响,以及解决它的一些方法。

首先我们来看一下结构相关,也就是资源冲突。听它的名字就知道,资源冲突嘛,也就是说多条指令在同一个时刻占用了同一个资源,那么就必然会产生冲突。因为我们多条指令这个资源只有这一个,比如说这样的存储器它只有这一个。但是呢,我们在多条指令都要去访问这个存储器,都要去用到这个存储器,那么这多条指令一定会造成干扰,一定会形成冲突。
所以呢我们来看这样的一个小例子。那么我们之前在划分这五个阶段的时候,我们把第一个阶段和第四个阶段用了不同的硬件,但是如果它用的是同一个硬件的话,会造成什么后果呢?比如我们的Load这条指令,它在第四个阶段,也就是访存这个阶段,访问的呢是存储器。然后看我们的第三条指令,也就是Instruction 3,它在第一个阶段也就是取址阶段,它都在用这个存储器,我们用红色的地方给它标出来了。所以,这两条指令,Load这条指令和Instruction 3这条指令,它们这两条指令,在同一个时刻,它占用了同一个资源,也就是这个Memory。所以,它就形成了冲突,这种冲突我们把它称为结构相关,或者呢把它称为资源冲突。那么概念大家都应该清楚了,这张图只是给大家举个例子,不必要深究。只是告诉你为什么会产生资源冲突。那么解决它的方法是什么呢?有两种方法。

第一种方法就是说,我们如果形成了冲突,那么后一条指令我们就暂停暂停一个周期,把它往后挪一下。等它占用,等前面这一条指令占用完了之后,解除了占用之后,你再去使用这个硬件。所以呢也就是说后一条产生冲突的这样的指令,我先暂停一个周期,等前一条指令占用完了我再去占用这个硬件。那么这是第一种解决方法,很容易理解对吧。就暂停一下,我不同时执行了,我就往后挪一下不就可以了吗?那么第二种解决方法就是我们开头提出的那种方法,我们把这个资源重复地进行配置。那么我们在不同的阶段,在同一个时刻,我就用不同的这样的资源不就可以了吗?我不去用这同一个资源,我用不同的资源,它就不会产生冲突了。所以,我单独地去设置指令存储器和数据存储器,这样呢这两项操作,取址和访存,那就可以单独地各自地在不同的存储器当中,一个呢在数据存储器当中,一个呢在指令存储器当中进行执行。所以这种方法呢就叫做资源的重复配置。
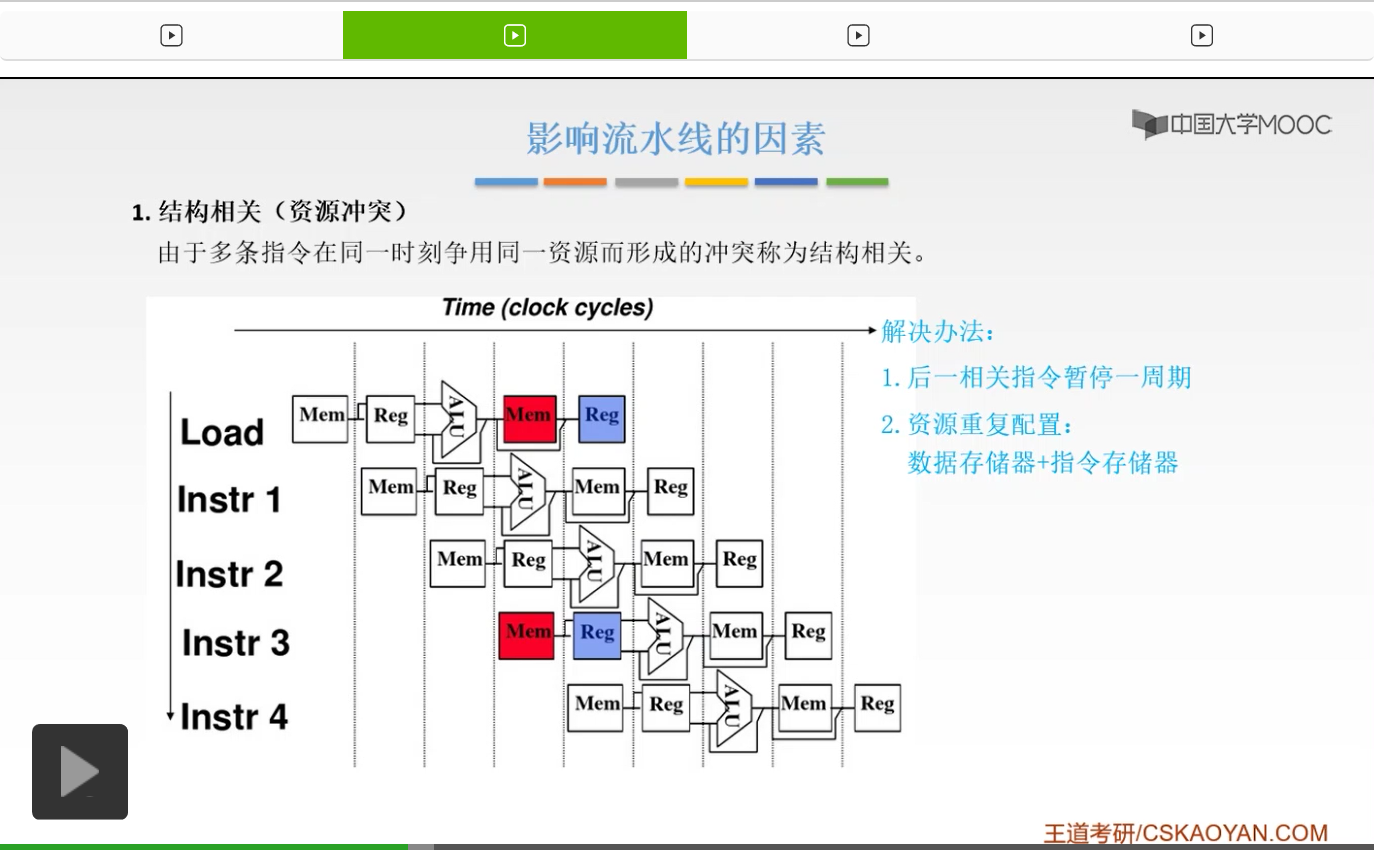
也就是这个样子的,指令存储器。一个呢是数据存储器,Instruction Memory和Data Memory,这样呢就不会造成冲突了。比如我们的Load指令和Instruction 3这条指令,在第四个阶段和第一个阶段的时候,一个呢用的是Dm,一个呢用的是Im,刚才标红的那部分。这时候呢就不会产生冲突了。那么大家要掌握的是什么?掌握的就是说结构相关,也就是资源冲突它的定义是什么,为什么会产生这样的冲突。第二个呢大家一定要把解决方案给弄清楚,记下来。那么这个是比较简单的。

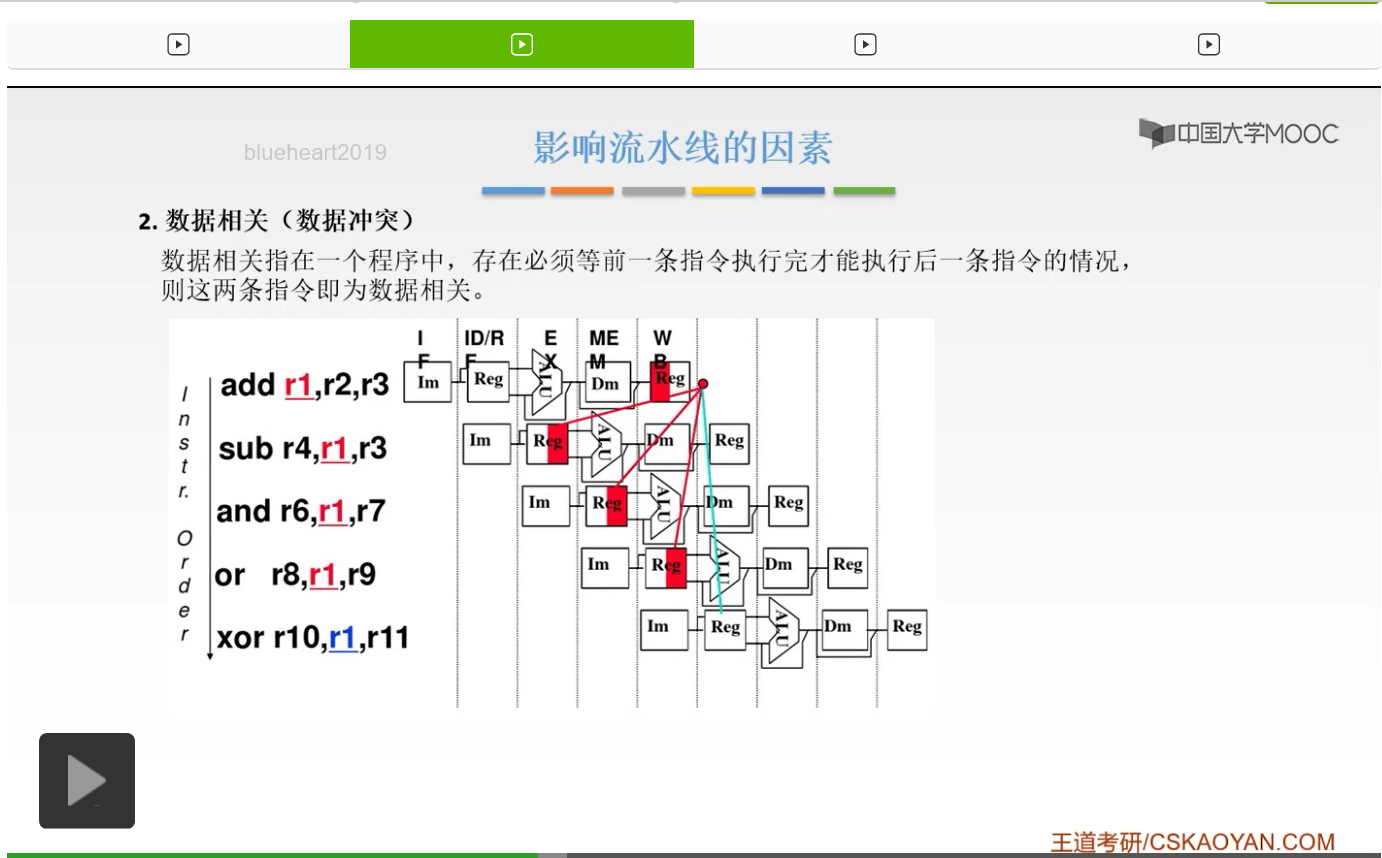
我们来看第二个。这个呢就稍微复杂一点了,叫做数据相关,也称为数据冲突。也就是说,在一个程序当中,必然会存在这样的指令,就是说我这个下一条指令要用到你上一条指令产生的一个结果,也就是说我这条指令的输入是你上一条指令的结果。你上一条指令没有结果的话,我这一条指令就没有办法执行。所以呢这就叫做数据相关,或者叫做数据冲突。就是说在同一个程序当中,肯定会存在前一条指令执行完了,我后一条指令才能够进行执行。那么这两条指令就必然就不可能同时执行。那么你要等前一条指令产生了结果之后,我第二条指令才能够去执行。因为你没有结果我就没有输入,没有输入的话我怎么能够进行执行呢?所以这就叫做数据相关,大家把这个概念要记下来。

我们来看这样的一个例子。就是说第一条指令,add r1、r2、r3,它的意思就是说,把r2和r3里面的数据进行相加,相加完的结果呢存回到r1当中。那么后面的三条指令,都用到了r1里面的结果。第二条指令Sub r4,r1,r3,就是说用r1的结果去减掉r3,然后再把它存到r4里面。你得r1里面有东西,你才能去和r3进行相减对吧。同样的,下面这个与操作和或操作都要用到r1,所以你第一条指令不执行完了,我后面三条指令都没有办法执行。我们后面的这个流水线的图你也可以看到,你必须等第五条这个阶段结束,写回,也就是说把这结果写回存到r1里面,你后面才能可以用。你第二条指令在译码的时候你就要用到r1了。同样的下面两条指令在第二个阶段你都要用到r1里面的东西。但是你如果上面没有结果的话,我这后面的几条指令都没有办法执行,所以呢这就叫做数据冲突。那么有什么解决方法呢?同样的,大家想到的第一个解决方法是什么呀?就是把后面这三条指令你等一等嘛,你等它执行完了你再去执行嘛对吧。
所以第一种解决方法就是把遇到相关的这样的指令,以及后续的这一些指令都暂停一个或者几个时钟周期,一直等到数据相关的问题消失之后,你再进行执行。这儿有两种方法来解决,第一种呢叫做硬件阻塞,也就是用硬件去阻塞它。第二种呢就是软件插入这个空指令。那么这两种方法,一个呢是硬件,一个呢是软件。
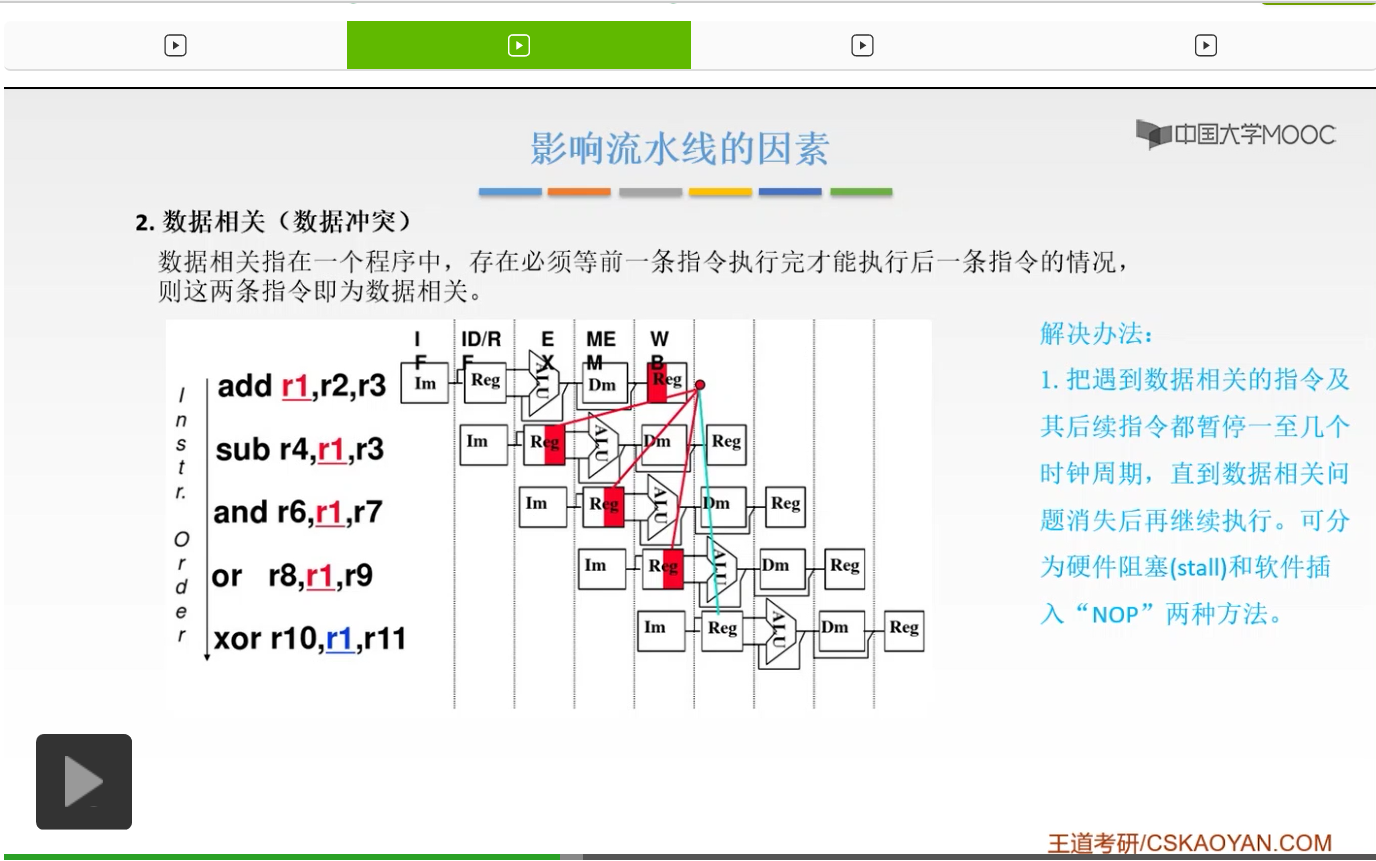
那么我们来看一下,这是硬件的方法。也就是说,你第一条指令执行完了之后,你先等一等,等三条,然后你这个r1已经写回了,那么第二条指令,Sub这条指令减指令你在译码阶段的时候,就可以用到它了,对吧。所以这是非常直观的,这是硬件阻塞。
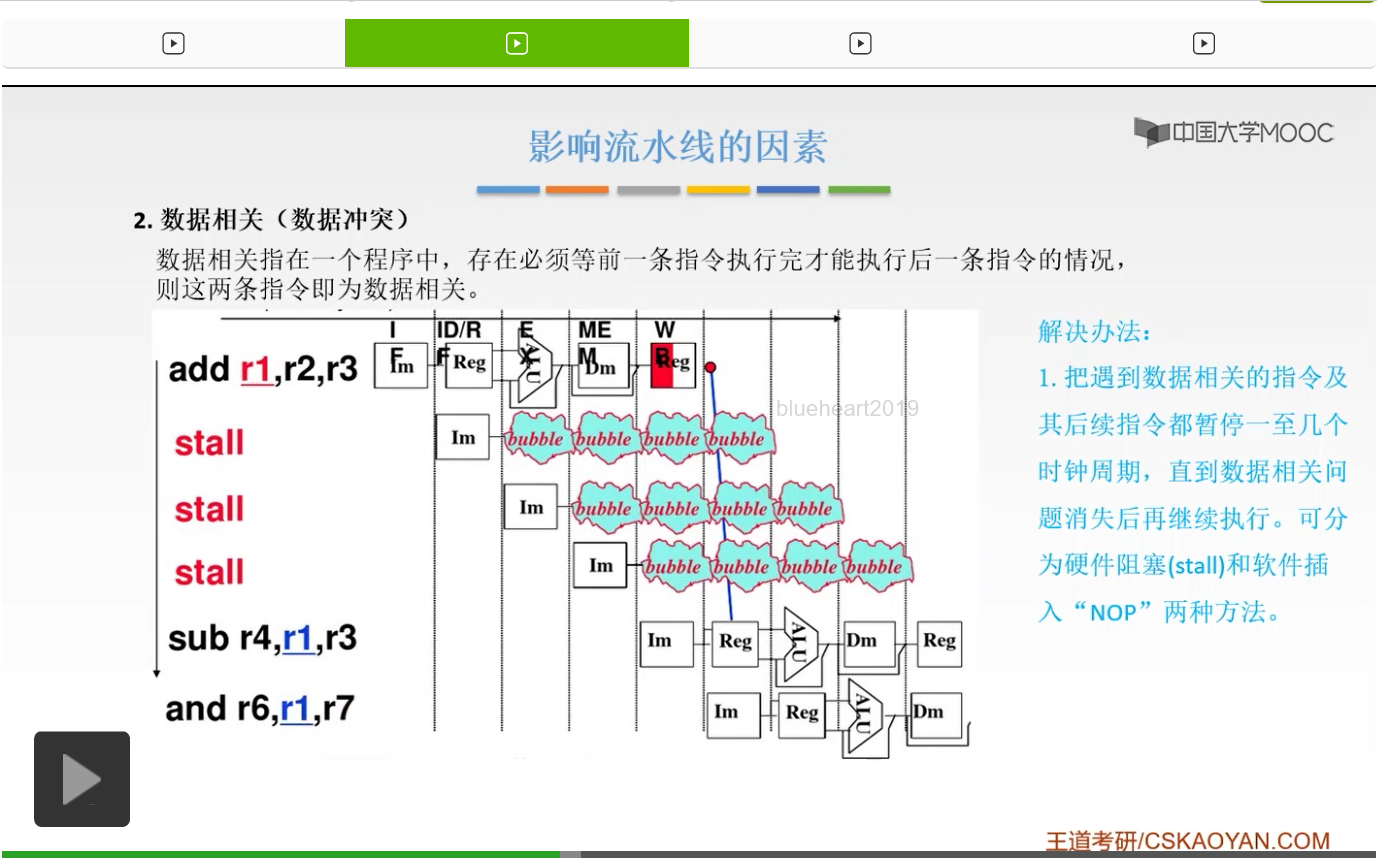
那么这是软件插入这个空指令的方法。同样的也是这个样子。还是这样,它插入的呢是空指令。那么这是第一种解决方法。这是我们首先想到的方法,就是去暂停。
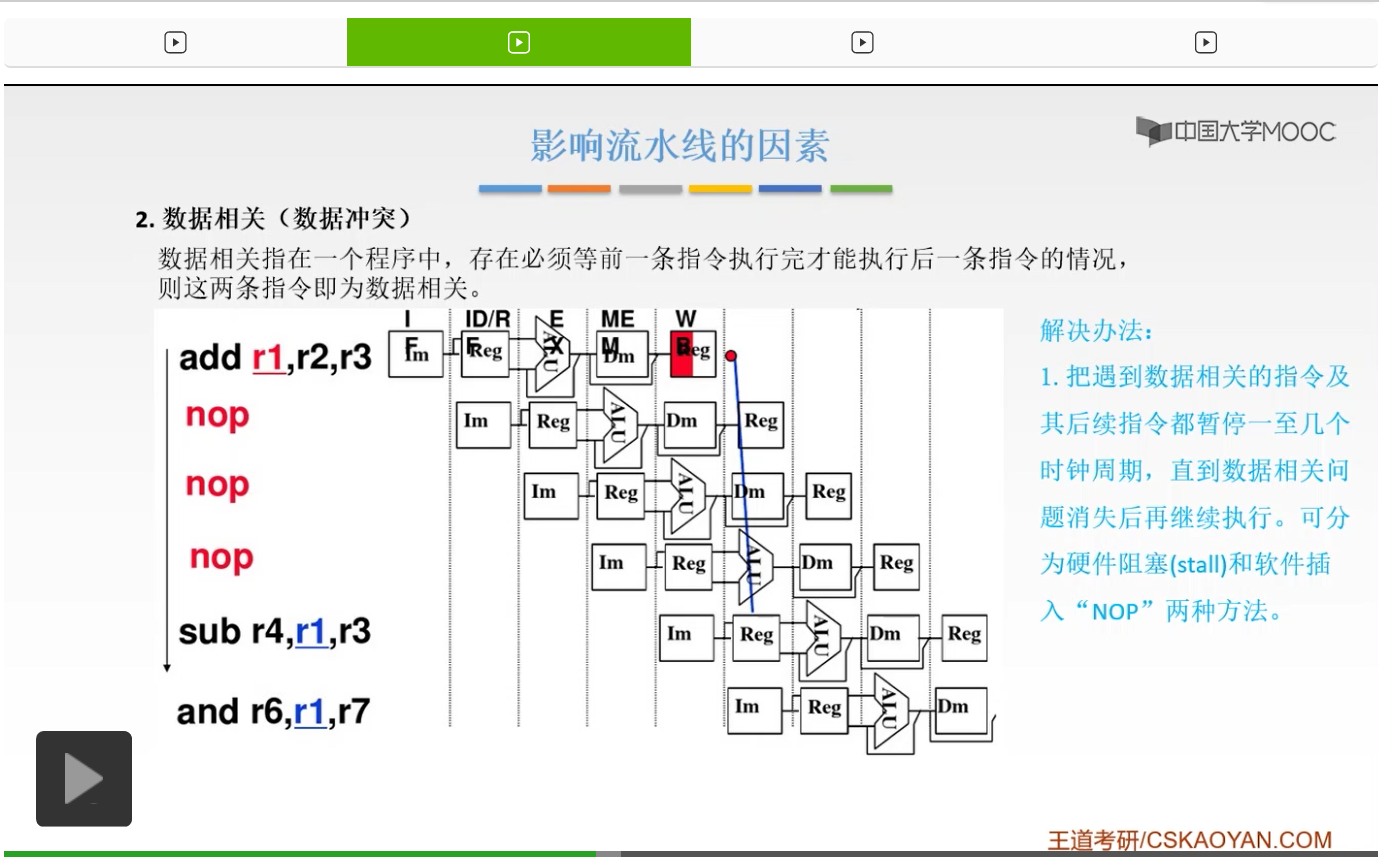
那么我们来看第二种解决方法。第二种解决方法是什么呢?我们为什么会出现这个相关。因为我们要用到r1里面的数据对吧,后面的这样的指令我要用到r1里面的数据,那我首先就想到,我可不可以提前一点,我不等它写回了,写回是说什么,写回就是说我要把这个数据存到这个r1里面,那我现在我就不等到它写回,我就提前地去使用,我结果一出来我就去使用,可不可以呢?你用的是r1里面的数据对吧,你现在用的是r1里面的数据,而不是说我要用这个r1。你存不存也就无所谓了,你现在用的是什么呢?用的说到底还是r2加上r3这样的一个结果对吧,那我就等这个结果出来,我就去把它用到,我先不写回,我先用它,可不可以呢?这是可以的。那么这是第二种解决方法,
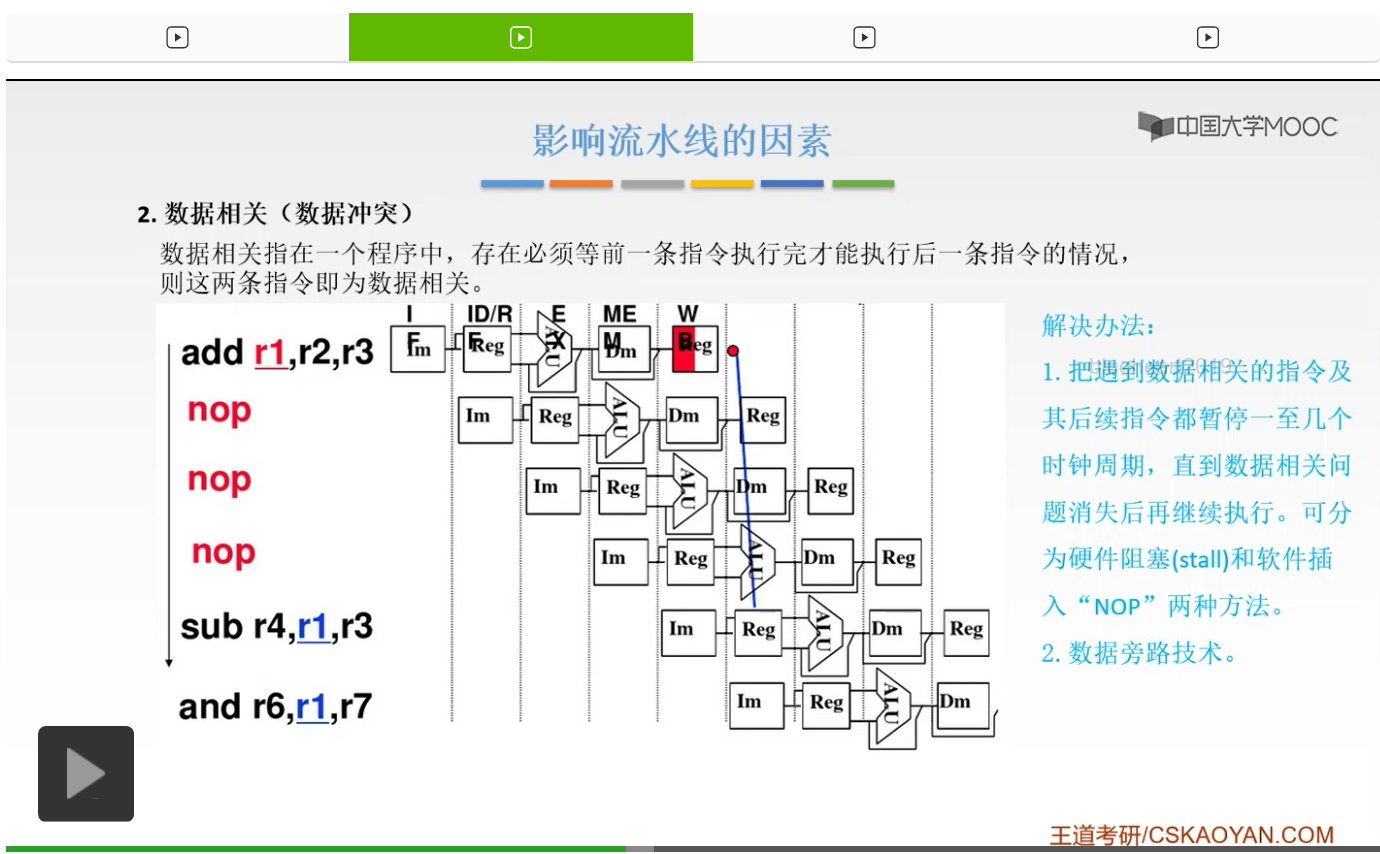
也就是说这叫做数据旁路技术。它是什么意思呢?就是这样的。也就是说不必要等到前一条指令把我们的结果写回到寄存器,下一条指令我也不去读它,我就直接把它的ALU的计算结果作为我的输入数据来进行计算。我取址呢我也不到你那个r1里面去取,我也不去写回了。我就等你ALU一计算出来我就去用它,直接把它拿过来用就可以了,这样就不会产生这样的冲突了。你把ALU一旦有了,那我就直接把它拿过来不就可以了吗?对吧。这两种是等价的,你再好好地想一想。我现在用的是什么?我现在用的是r2加上r3这样的一个结果,存回到r1,然后我再到r1里面去读这个数,然后我把它再拿过来用。那我现在就不这样,我现在的ALU一旦把r2加r3计算出来,我就把它输入进来,我就去用这个结果进行相减不就可以了吗?对吧,所以这就叫做数据旁路技术。我们可以看到这个图中已经画出来,这是我们用红线标出来的这个部分。就是说我ALU的结果一计算出来,我就不去访存,也不去写回了,我就直接把它拿过来用,拿到这个ALU里面,拿到这个指令里面用。我先去用,你写回你再慢慢写呗。我先去用它,对吧,所以这是数据旁路技术。那么这种思想大家有没有理解了?如果没有理解你再好好地想一想。就是说我现在用的是什么?我现在要用的并不是我要用r1这个寄存器,我要用的是r2加r3的结果,对吧。那我就不去把它写回,我也不去访存,我把它直接拿过来用。一旦r2加r3的结果出来了,我就把它拿出来。那么这样就不必要插入我们的暂停,不必要插入我们的空指令,也不必要去暂停了。那么这是数据相关的第二种方法,数据旁路技术。

那么第三种方法,也就用到我们的编译器去优化它,调整我们指令的顺序来解决这样的数据相关。这个大家了解一下就可以了。在编译原理这门课当中,大家应该学到过这方面的内容。我们计组当中就不去深究了,你只要知道有这么个解决方法就可以了。那么数据相关这一部分内容还是比较重要的,还是比较难的理解。所以大家一定要把它的概念搞清楚,然后把它的前两种解决方法把它记到。第三种解决方法由于涉及到我们的编译,所以我们计组这门课的重点不在于这儿,大家知道一下就可以了,有这么个方法就可以了,不必要去深究,你只要知道可以通过编译优化来解决数据冲突这样的冲突就可以了。

好的我们来看一道题目,来加深对数据相关的概念的印象。假设某一条指令流水线,
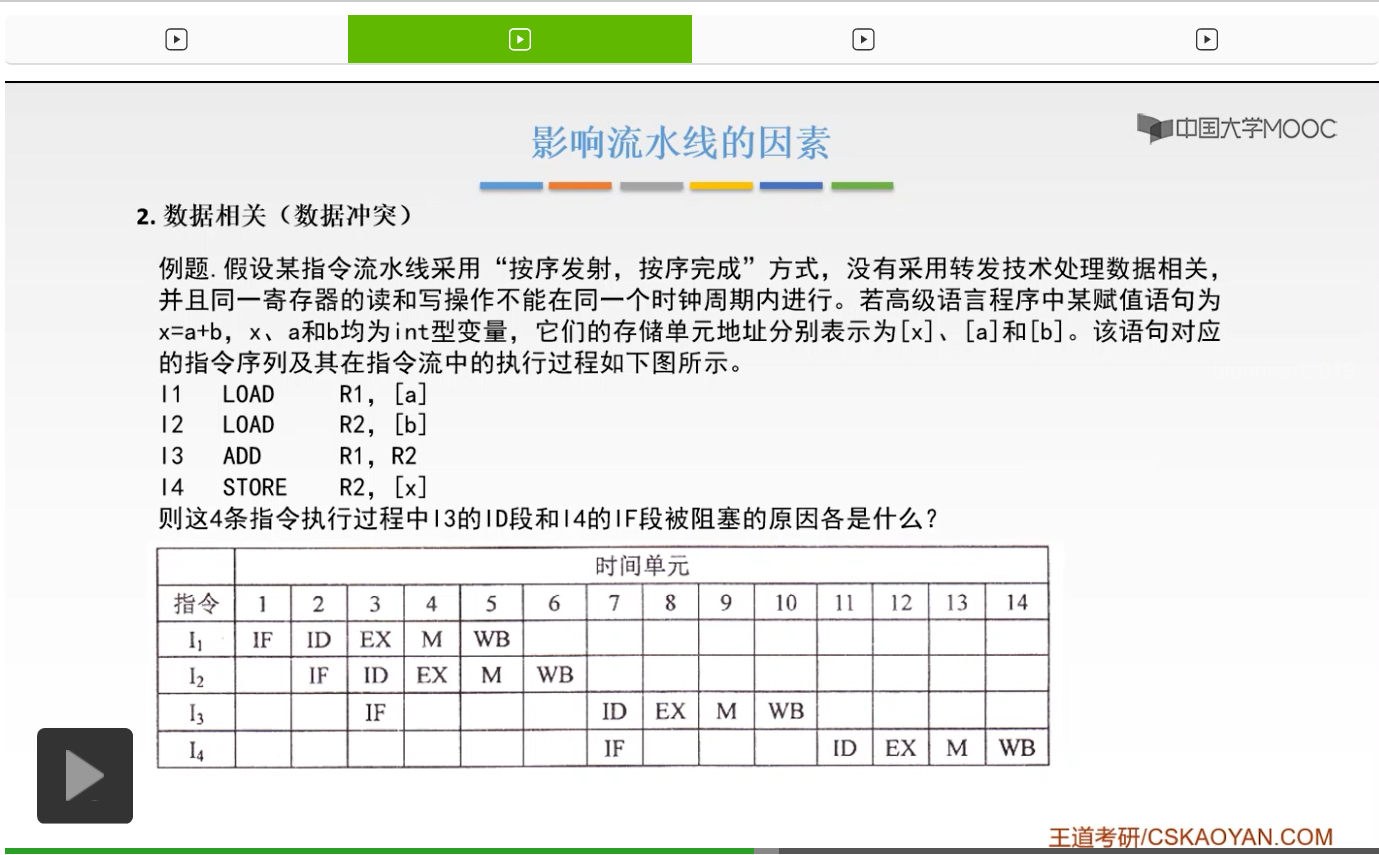
那么在本节的最后,我们把指令流水线这一部分一些零碎的知识点给大家讲一下。注意,这一部分的内容重点在哪儿?重点在第一小节,它的那个性能的计算那一部分,以及第二小节,就是上一节课我们讲的冲突的类型这一部分内容,那么我们这一节课的东西呢大家看一下浏览一下过一下就OK了,不需要花太多力气在我们这一节课当中,给大家读一下就可以了。
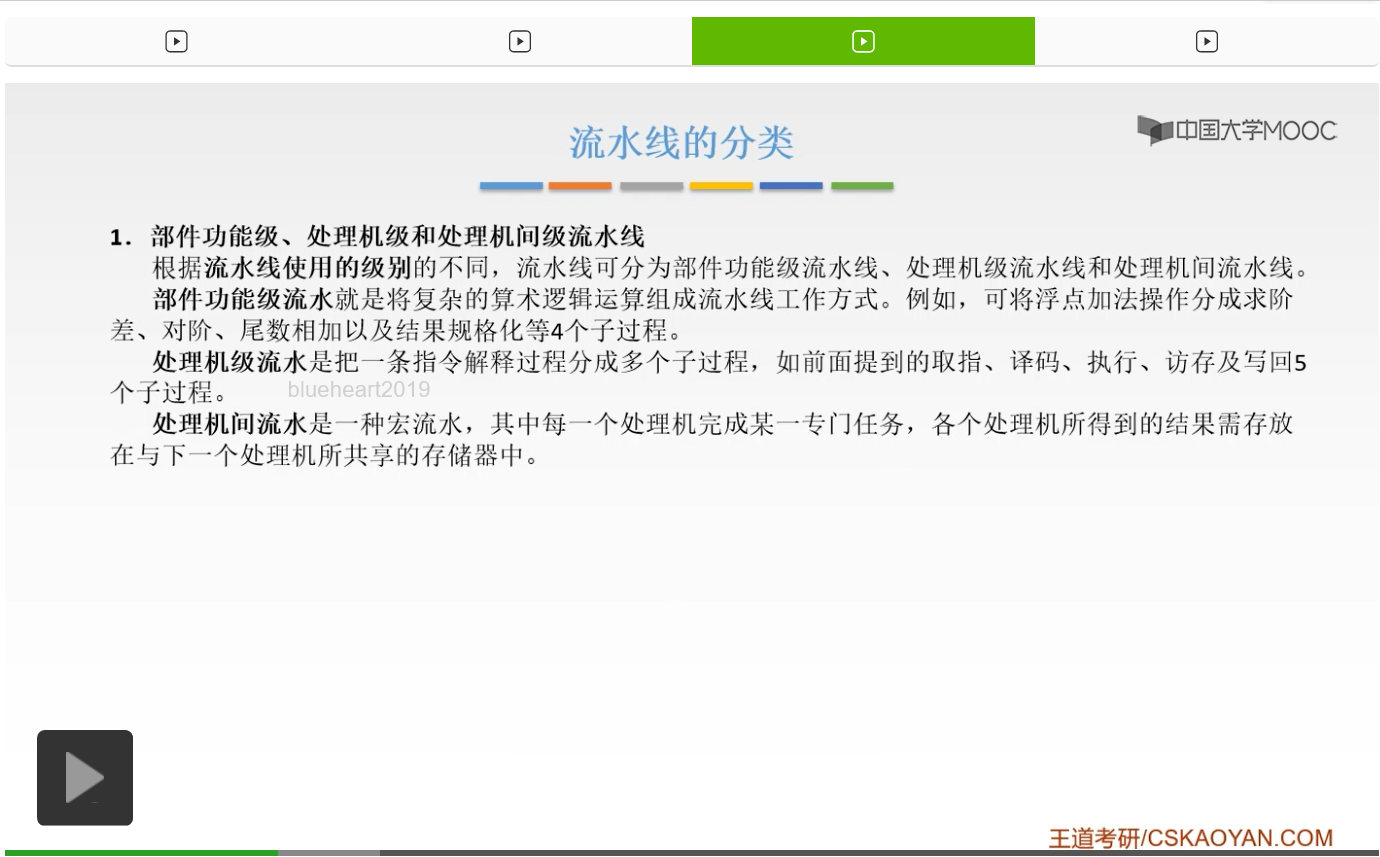
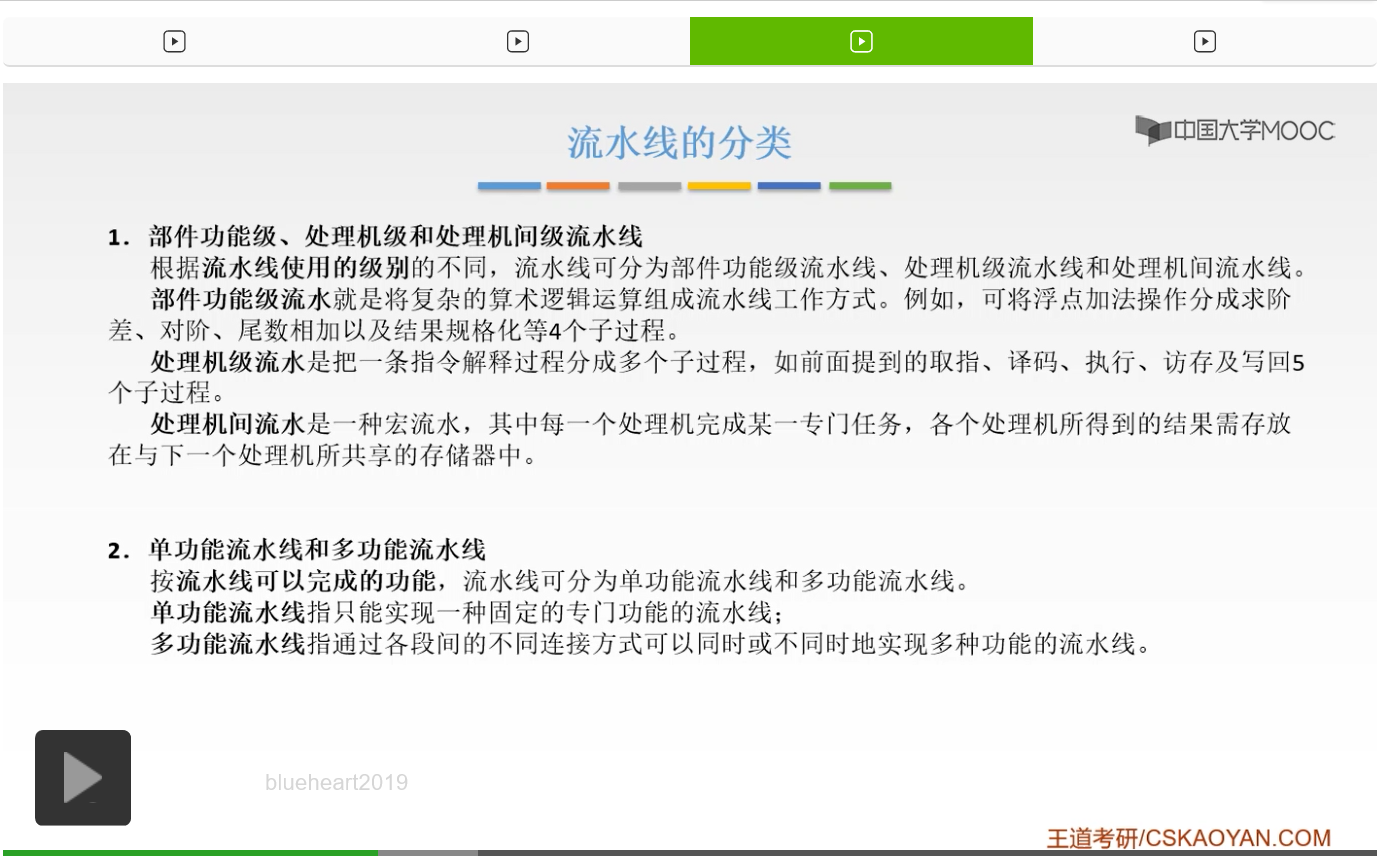
我们来看一下指令流水线的分类。首先第一种分类方式是这样的,叫做部件功能级、处理机级和处理机间级的这样的一个流水线。那么比如什么叫做部件功能级呢?是这样的。就是说我们把复杂的这样的算术逻辑工作,流水线的这样的工作方式。举个例子就是说,我们之前第二章的时候讲浮点数的运算的时候,浮点数的加法操作可以分成求阶差、对阶、尾数相加以及结果规格化这四个子过程。那么我们就可以把这四个子过程呢把它进行一个流水,那么这就是部件功能级的这样的流水。处理机级呢就是我们一直在讲的这种方式,就是把一条指令的执行过程分成若干个子过程,就是取址、译码、执行、访存、写回这五个子过程,然后呢再进行一个流水。那么处理机间级呢,就是说它是每一个处理的任务,然后呢各个处理机得到的结果呢,放到下一个处理机共享的这样的一个存储器当中。那么这就是处理机间的这样的一个流水。那么这是第一种分类方式,
第二种分类方式呢?叫做单功能流水线和多功能流水线。比如说一条流水线它可以完成一个功能还是多个功能。单功能流水线呢就是说我们这条流水线只能执行一个固定的这样的功能。而多功能呢就是说我们各段它可以采用不同的连接方式,然后呢采用不同的连接方式之后,就可以同时或者不同时地实现多种的这样的功能。那么就是说把我们各段的连接方式进行一个改变,然后去实现不同的功能。
第三种呢叫做动态流水线和静态流水线。这个呢,和上一个分类方式有点像,但是它是说按照同一个时间内它各段的连接方式来划分的。如果同一个时间内,各段只按照同一个功能这样进行连接,然后工作,这就叫做静态流水线,它是不改变这样的连接方式的。而动态流水线,是说在同一时间内,在某一段正在执行某一个功能的时候,另一段在实现其他的运算,所以它叫做动态流水线。它的功能呢是可以进行改变的,它可以完成不同的功能,一个段在执行这个功能这个运算,而其他的段呢在进行另一个运算。那么这叫做动态流水线。
那么还有的叫做线性流水线和非线性的。线性的就是说,就像一根线一样。你输入到输出,你都只能通过一次,就跟流水一样,你不能往回流,奔流到海不复回嘛,对吧,就是说你通过一次又一次就结束了。而非线性呢它是说它存在反馈,它是可以向前流的,向之前去流的,一些功能段可以多次地进行通过,然后呢进行一个反馈。它可以进行线性的这样的递归运算,啊这是叫做非线性的流水线。
那么值得注意的是最后,在书上的还给大家讲了流水线的多发技术,这个大家也要掌握一下,知道它的概念。什么叫做超标量技术呢?就是说这样的。我们之前啊,在画这个图的时候,我们只是一条指令一条指令去进行流水,但是超标量就是说我在一个时钟周期里面可以并发地发送多条的这样的指令。也就是说,可以采用并行的一个操作方式,使得多条指令去编译并且执行,然后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号