GEM: 增强MLLM模型,通过时间序列与图像实现接地心电图理解《GEM: Empowering MLLM for Grounded ECG Understanding with Time Series and Images》(多模态、模态对齐(MLP)、ECG时序+图像+文本解释、工程整合、构造高颗粒度指令数据集、提示工程)
2025年11月24日和25日看完的这篇论文。
(现在是11月25日,感冒生病了,今日份计划未完成,放过自己.)
论文:GEM: Empowering MLLM for Grounded ECG Understanding with Time Series and Images
GitHub:https://github.com/lanxiang1017/GEM
NeurIPS 2025 Poster的论文。
有一说一,因为对当前多模态融合的发展现状了解的并不多,所以并不太清楚这篇论文带来的影响,但是对里面的一些处理方式我还是有自己的疑问的(保命发言)。
(21:33,突然不想写了,先鸽着吧,干别的了.)
(今天是12月4日,写完.)
1. 论文提出的问题:
目前多模态大语言模型在自动化ECG面临的两个关键限制:(1)ECG时间序列与ECG图像之间的多模态协同不足;(2)在将诊断结果与细粒度波形证据相联系方面,可解释性有限。
2. 论文解决的问题:
将ECG时间序列、12导联ECG图像与文本,用于基于证据且符合临床思维的ECG解读的MLLM(多模态大型语言模型)。
3. 相关图片和流程图:
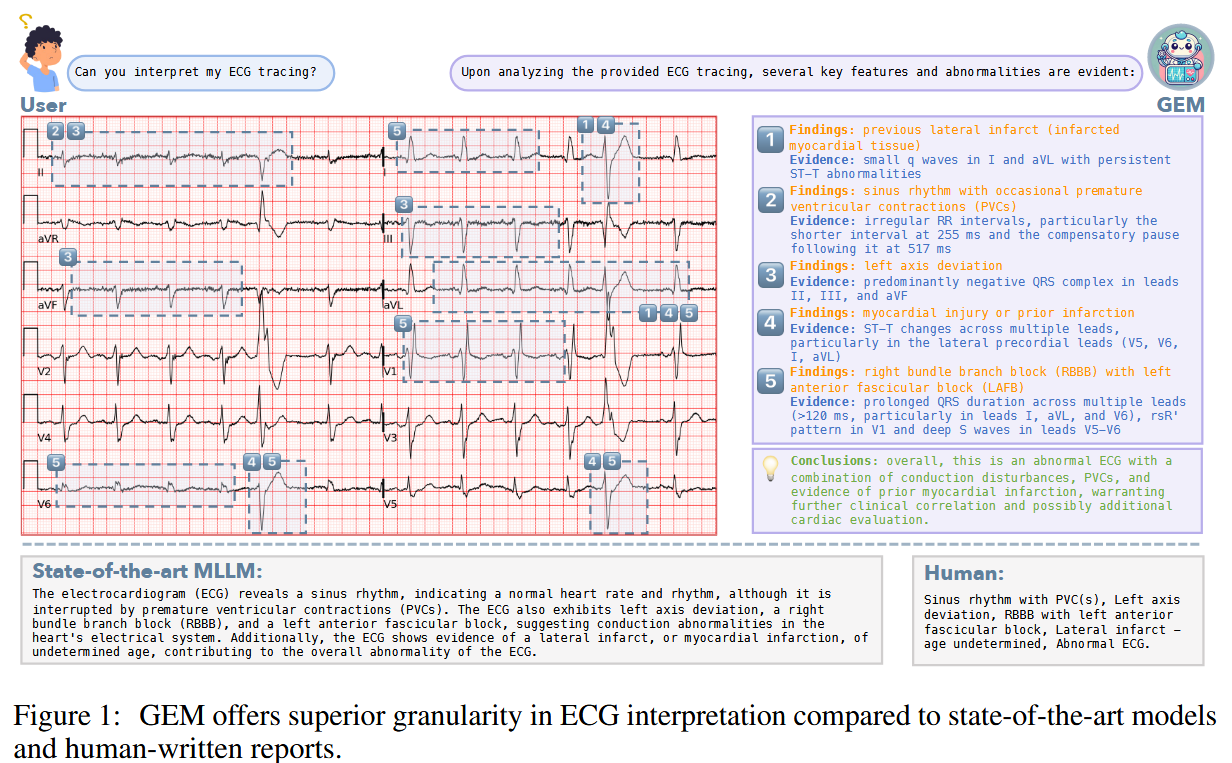
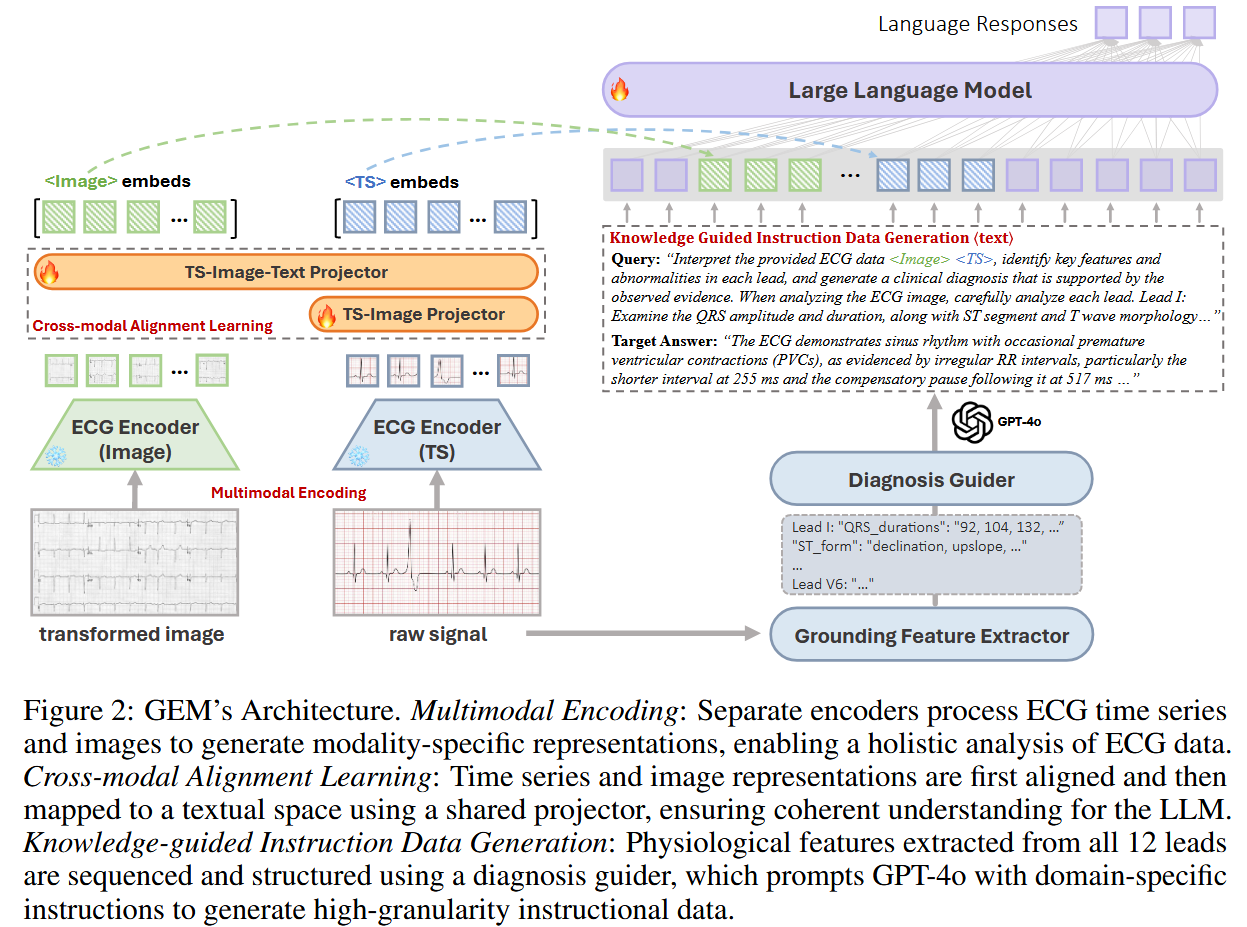
4. 方法机制:
(1)双编码器框架,用于提取互补的时间序列(捕捉动态生理信号)与图像特征(捕捉空间波形结构)。(我个人认为的槽点:都是用的既有模型方法,不叫方法创新,论文中说“We tackle these challenges through three novel approaches”.)
(2)用于有效多模态理解的跨模态对齐。(槽点2:用的MLP把(1)得到的结果进行对齐.)
(3)基于知识引导的指令数据生成方法,用于生成高粒度的grounding数据(ECG-Grounding),将诊断与可测参数(如QRS/PR间期)相连接。
5. 目的:
提出了Grounded ECG Understanding任务,是具有临床动机的基准,用于评估MLLM在grounded ECG理解方面的能力(明确一下是这个目的)。
6. 挑战:
在建模方面,有效整合不同模态的信息。在数据方面,目前没有可用于训练LLM进行高粒度ECG解读的指令数据。
7. 贡献点:
(1)首个统一的多模态ECG模型。协同整合原始ECG时间序列、12导联ECG图像与文本指令。
(2)首个高粒度的ECG Grounding数据集。知识引导指令数据生成方法生成ECG-Grounding数据集。
(3)面向临床的诊断系统。提出Grounded ECG Understanding任务,具有临床动机的基准。
8. 具体方法内容:
(1)多模态编码:时序编码器:使用已有的模型。图像编码器:使用已有的模型。
(2)跨模态对齐学习:先用一个MLP把时序特征映射到图像维度,然后再用一个MLP把对齐维度的时序特征和图像特征投影到一致的文本空间中,对齐文本嵌入的维度。
(3)知识引导的指令数据生成(这部分是重点):
a.特征提取器:从原始ECG时序中提取出来波形、参考点的幅度、间期等元素(生理特征),然后结构化为特征序列(按时间排序),得到一个字典x_fs,键为特征名称,值为对应的特征值。如何实现这个结构化?使用已有模型方法FeatureDB(不包含可训练参数)。
b.诊断引导器:目的是构造提示x_p,为样本生成专门定制的详细分析指令。目的是确保能激活GPT-4o的潜在医学知识。具体如何实现?提示工程(Prompt engineering),领域知识提示模板。(大白话:用提示语句把特征提取器得到的特征输入GPT-4o,让GPT-4o写解释。就是一个Prompt生成器。)
c.ECG-Grounding Data:使用GPT-4o从已有的数据库(MIMIC-IV-ECG)中整理得到细粒度的指令-相应对。
(4)训练:训练两种基础LLM:LLaVA、PULSE。均执行一次监督式微调(SFT)。冻结时序编码器,冻结图像编码器,只训练MLP和LLM,融合后的表示仅用于下游LLM的next-token prediction。
9. 实验:
(1)使用GPT-4o对MLLM的响应进行评分。使用一组预定义的指标衡量。这些指标就是作者构造的Grounded ECG Understanding任务,基于心脏科指南设计,具体指标见论文内容4.2。
(2)数据集的测试集:MIMIC-IV-ECG(领域内数据集)(指令数据也是用这个数据集生成的)、PTB-XL(领域外数据集)(领域内外就是测试样本来自不同的数据分布)。
(3)ECG-Bench:两个任务:异常检测(AUC、F1和Hamming Loss等指标)和报告生成(GPT-4o评估报告的准确性,评分上限100)。
(4)仅训练一个epoch。
个人的一些疑问和细节问题(结合ChatGPT 5.1的回答):
1. 对这篇论文的评价:
论文的创新主要是:“工程整合+指令数据构造“”,不是方法创新。
所谓的“多模态对齐” ≈ 一个MLP。
三模态(时序+图像+文本)本质上信息冗余,没有从信息论证明融合的必要性。(没有多模态融合的“互补信息量”分析(原文写的是“time series models capture dynamic changes but may overlook spatial patterns, while image-based models detect global structures but may miss subtle temporal details.”),没有信息熵分析,没有验证三模态是否有互补性,没有解释验证为什么必须加图像(因为这个图像本质上就是时序的可视化,存在信息冗余),从raw signal可以完全重构ECG图,而且实验结果里TS+IMG的组合的结果提升不多。)
从Grounded ECG Understanding任务上来说,这篇论文创新是可以的,但是如果从技术上来说,我认为创新有限。
2. 融合后的多模态向量的用途?
融合后的多模态向量的真正用途是:在推理阶段(inference)提供模型输入。即:(time series embedding + image embedding) -> LLM -> 诊断 + 解释。
融合后的embedding的唯一功能,就是作为LLM的输入序列。没有额外的pretrain,没有contrastive learning。
3. 文中构造Grounding指令数据集时,采用了FeatureDB提取结构化生理特征的函数,不包含可训练参数,那这个函数是如何工作的?
FeatureDB是医学特征工程的自动化生理特征提取器。由传统的信号处理和ECG delineation组成,用于自动提取心拍级别的特征。
4. 文中3.4内容“In contrast, our ECG-Grounding provides more accurate, holistic, and evidence-driven interpretations with diagnoses grounded in measurable ECG features.”,这里的证据驱动,证据是x_fs吗?可测量体现在哪里?
证据驱动(evidence-driven)就是FeatureDB提取的生理特征,即x_fs(心拍级结构化特征)。
可测量体现在这些特征是临床标准化的物理量(),不是神经网络的latent features。
5. 构造指令数据集(文中3.4内容)的整体流程就是:从时序信号自动提取生理特征,然后诊断引导器把这些特征组织成GPT-4o的提示,然后GPT-4o再生成最终的诊断解释文本,由此构造出指令数据集。(套娃?)
确实有点专家系统 -> prompt -> GPT -> 训练LLM的二次生成链(nested generation pipeline)。虽然论文中并没有承认这是“二次生成/套娃”,包装为知识引导的生成和特征接地的解释。但是本质就是:FeatureDB提供知识,诊断引导器提供格式,GPT-4o生成,再训练LLM。
6. 模型训练(文中3.5内容)冻结是因为用其他模型提取了是吧?联合训练就是指令微调是吧?是很常规的训练策略是吧?
整个训练流程就是标准的MLLM的指令微调流程,freeze encoders + train projection layers + train LLM。
7. 评估标准是由作者自己定义的,也是用GPT-4o进行评分的,感觉GEM这篇论文就是一个自洽的闭环系统,而不是被独立数据检验的模型,有种自嗨的错觉。(仅个人意见,可喷。)
GEM的实验结果有一部分就是用作者自己提出的指标上。GEM在最关键的评估任务上:训练集由GPT-4o生成,评估标准作者自定义,评估者也是GPT-4o,被评模型的输出与GPT-4o风格天然接近(因为训练数据就是GPT-4o生成的。)
虽然确实有临床医生的评估,但是更像是补充性的故事性案例,并不是科学意义的独立验证。
self-generated -> self-alignedd -> self-evaluated的闭环体系,模型不是被独立数据检验,而是被自己制造的数据和自己定义的规则检验。
8. 消融实验,好像纯TS的效果和加了图像的,提升并没有非常明显。有的加了图像,效果还下去了,而且和PULSE相比,提升有的不明显?
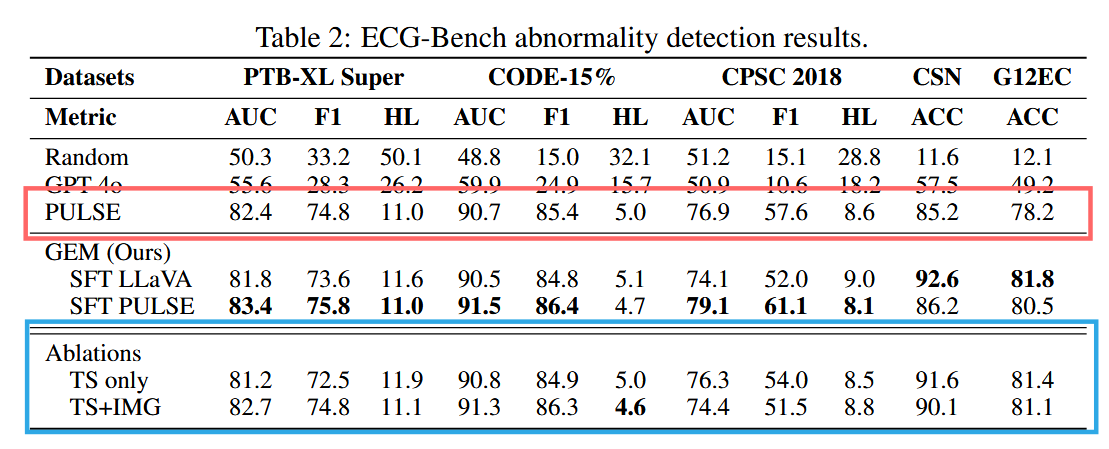
根据这个表格的结果分析,在ECG-Bench(异常检测)上,GEM提出的“三模态优势”在核心的异常检测任务中并未体现。图像模态的贡献非常弱,有轻微提升,非强力提升。甚至在多数据集上有负贡献。
(除此之外,作者文中并没有明确说消融实验用的哪个基础LLM,盲猜是PULSE版本的消融实验。)
9. 这篇论文最大的创新点/贡献点?
构造了高颗粒度(heartbeat-level)的ECG-Grounding数据集。模型方法上并没有创新。但是工程创新也是创新嘛。
现在是12月5日,16:32,昨天还是没写完,问题部分没写完,我有罪,我是狗(bushi)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号