

SDForger: 语言锻造时间序列:一种基于大型语言模型的合成数据生成方法《Forging Time Series with Language: A Large Language Model Approach to Synthetic Data Generation》(时间序列、序列文本化embedding、大语言模型、大模型、LLM、时序生成、LLM间接生成时序)
2025年11月18日看的一篇论文,19日看完了,记录一下。
(现在是11月20日,把博客写了.)
论文:Forging Time Series with Language: A Large Language Model Approach to Synthetic Data Generation
或者是:Forging Time Series with Language: A Large Language Model Approach to Synthetic Data Generation
GitHub:https://github.com/IBM/fms-dgt/tree/main/fms_dgt/public/databuilders/time_series
NeurIPS 2025 Poster的论文。
(不逐行逐句的翻译了,没意思,写一写总结的内容,如果有需要以往逐行逐句翻译的博客写作风格,请给我发评论。)
1. 论文核心问题:
当前时序生成的根本难题:(1)现有时序生成模型缺乏预训练、不易迁移。(2)模型难以捕获多变量依赖与长程结构。(3)时序数据本身难以直接输入LLM。(4)数据稀缺、隐私敏感。
2. 论文解决的问题:
将时序数据与文本条件相结合,使用大型语言模型生成合成多元时间序列,即使在数据稀缺的条件下也能实现高质量的生成。
(使用LLM直接建模时序序列存在难题,但是可以间接做,避免了序列长度和时序复杂性对LLM的限制。使用LLM做时序合成,不直接建模原序列。所以这篇论文可以做到效果好。)
3. 扩展:
时序数据与文本提示无缝结合,为多模态时间序列生成提供基础。
4. 大体实现流程:
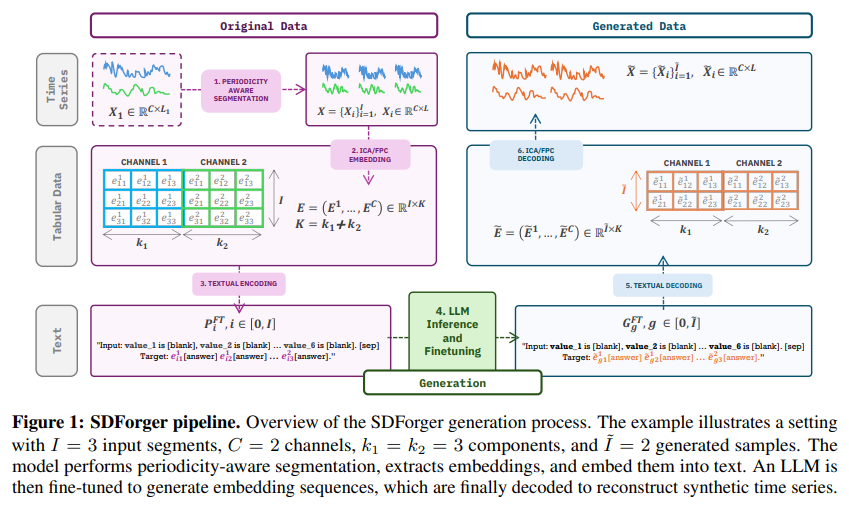
单变量/多变量时序信号转换为表格embedding -> 编码为文本进行大模型微调 -> 推理阶段通过文本embedding采样 -> 解码embedding为合成时间序列。
(合成的时间序列能完整保留原始数据的统计特性与时间动态。)
5. 具体的一些技术方法:
(1)周期性感知切片:有稍微利用一些人工先验,但整体还是靠流程自动实现的
(2)FastICA/FPC embedding(抽取低维时序embedding):线性基函数实现时序表示抽取,多变量处理为不同通道分别做embedding,再拼接。由此,不依赖时序片段长度,通道独立embedding且紧凑,实现LLM处理时序的能力。
(3)Textual embedding:把embedding行转换为结构化文本模板。
(4)在文本embedding上微调LLM。
(5)推理过程,生成新的embedding表格。
(6)用basis将embedding还原成时序。
6. 个人的一些疑问(结合ChatGPT 5.1的回答):
(1)论文中提到模型的嵌入空间是紧凑的嵌入空间,怎么定义这个“紧凑”?(论文Section 1中的“while its compact embedding space ensures fast inference, even for long time-series windows.”)
高频噪声、多尺度结构被线性基吸收,只保留核心模式。FPC只保留主成分(趋势、季节性),ICA只保留独立成分(独立形状模式),这让embedding的信息量密度极高。原始长度L的序列压缩成固定常数维度K(通常为3~7每通道)的embedding表示,使生成和微调完全与原始序列长度无关。
LLM的生成任务轻量(原本需要生成长序列,长token sequence,现在只需要生成固定维度数值向量,embedding是固定维度,维度非常低3~7每通道,与时间序列长度L无关,大幅压缩时序结构),大幅减少token数量,支撑LLM快速训练与推理,保留时序主要变化模式,极大提升速度和稳定性。
(2)论文的Figure2可视化了合成的数据,但是图片展示出来的合成的数据感觉大体都没超过原始灰色值的上下界?
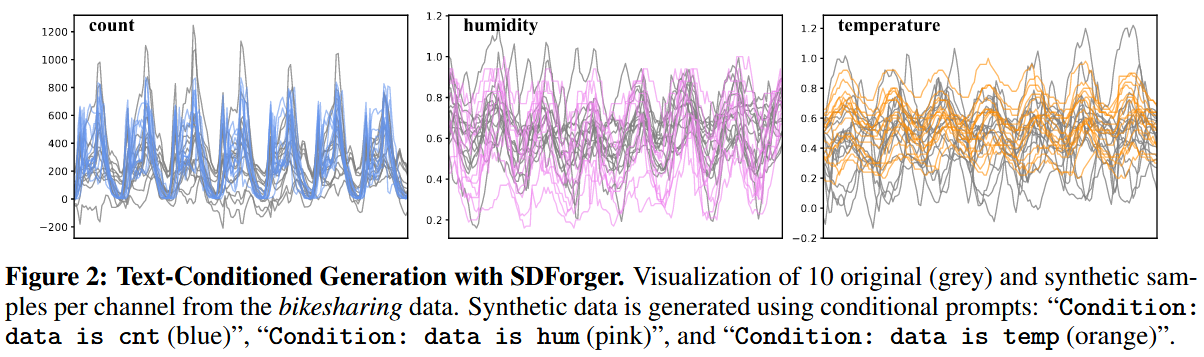
(a)embedding(FPC/ICA)本质是“线性基投影”,无法自然生成超出训练分布的极端值。论文Section 3.1中“Each row represents a time series embedding obtained by projecting the signal onto a set of learned basis functions.”提取到的embedding都属于原始数据的线性空间,embedding的结构决定了生成数据的“可达范围”,LLM无法突破这个范围。
(b)论文采用了filtering机制,过滤机制自动“”拒绝”过大的embedding(极值)。过滤机制的设计保证合成样本与原始数据统计一致性,所以牺牲了探索性与极值生成能力。就算有极端值本来有可能被生成,但会被过滤掉,所以最终是没有。
(c)LLM samping本身是“分布保持型”的,而不是“探索型”的,SDForger采用了multinomial sampling和温度控制,控制模式保持,所以不会像diffusion模型这种“可能穿越分布尾部”的模型。合成时序在原始训练序列的包络内。
(d)图2展示的是conditional prompts。约束了条件、温度等,这些条件性约束会进一步压缩生成变异范围。
(e)论文本身也没有追求“突破原始范围”的生成能力(所以我不要找茬了好吗)。论文追求的是保持与原始数据一致的统计特性,而不是超越原始分布。
总结:线性投影不会超越原始分布,就算生成了超越原始分布的embedding也被过滤机制过滤掉了,论文采用条件提示进一步约束条件,所以最终展示出来的效果就是:合成曲线在灰色真实曲线的包络内部摆动,很少出现突破。
(3)如果生成大批量的数据,会不会导致最终生成不出多样化的数据,因为原始数据的分布范围是有限的?
答案是:是。如果持续生成到足够大规模,合成数据的多样性最终一定会下降,因为SDForger的生成空间本质上受原始embedding分布限制,原始分布有限(封闭有限集)导致生成空间有限。理论上只能生成原始分布的变体,而不是新的regime。用有限分布采样大量点,会逐渐覆盖distribution的高密度区,后续采样必然重复/相似(多样性下降)。
当然,论文的设计,就是故意这样设计的,为了统计保真(fidelity),为了避免生成无效、偏离原始分布的异常数据。所以避免“坏数据”,但也牺牲了“长期大规模生成能力”。还是受原始数据的分布影响(所以说在数据稀缺下也能生成新的数据是相对而言的,并不是完全可持续的,当然要有个折中。)(放过这篇论文,有点发散了,老哥,OK。)
一些思考和细节问题(结合ChatGPT 5.1的回答):
1. 这篇论文用直白的话理解就是人为分割时序数据集,然后使用两种算法技术把分割后的数据进行表格化,然后得到的文本表格放入大模型中进行微调,然后使用一些模板化的提示语句,生成合成数据的表格,然后再把表格数据转换回时序数据。
(1)人为分割时序数据集:论文中对单条长序列进行周期感知的segmentation来得到多个窗口用于后续学习。论文原文Appendix A.1中:如果数据集中只有一条序列,为了估计时间序列的分布,需要切成多个窗口。切割是“periodicity-aware segmentation”(周期性感知切割),不是简单人为分段。切割窗口对齐自然周期峰值(通过ACF估计P)。所以本质上是为了生成多个训练实例,而不是随意切割。
(2)使用两种算法技术把分割后的数据进行表格化:论文使用两种线性基分解方法(Functional PCA(FPC)和FastICA),将每个切好的窗口映射为一个低维embedding(表格行),每个窗口,投射到k个basis,得到一个长度为K的embedding vector,所有embedding组成表格。这是论文的核心步骤(Section 3.1)
(3)得到的文本表格放入大模型中进行微调:论文不是预训练(pretraining)模型,而是对已有预训练的LLM(如GPT-2)进行微调(fine-tuning)。使用结构化的文本prompt对LLM进行fine-tuning,没有从头训练大模型。
(4)使用模板化的提示语句,生成合成数据的表格:论文使用Fill-in-the-middle templete,LLM在推理时用类似模板,但是不提供target值,让模型自己填。论文才采用了随机打乱列的顺序(feature permutation),减少位置偏置。生成过程使用multinomial sampling + temperature。
(5)再把表格数据转换回原始时序数据:论文的decoding过程,每个embedding的k维系数,和之前的basis(ICA/FPC),线性组合,就能恢复出时序曲线。所以就是把LLM生成的embedding还原成time series。
2. LLM在SDForger中不是直接学习“时间序列的深层表征”。LLM学到的只是FPC/FastICA生成的“低维embedding空间的分布结构”。LLM没有学到时序的深层结构(没有学习raw time series的representaion)。
时序的表示不是LLM学的,是FPC/FastICA学的。LLM只是学embedding的概率分布,并生成新的embedding。LLM并没有直接理解时序变化模式,而是在学习“FPC/FastICA抽出来的系数是怎么分布的、如何相关”,然后用这些规律生成新的系数,再根据基函数还原回时序。
LLM = 生成器(建模embedding分布)
FPC/ICA = 表征提取器(学习时序结构)
论文Section 3.1中“FPC identifies principal modes of variation by ...”以及“FastICA extracts statistically independent components by ...”,也就是说:理解趋势、周期、独立因素的都是基分解技术(FPC/ICA)负责,LLM完全不处理raw time series。LLM的任务就是:学习embedding的joint distribution,而非学习时序本身。论文Section 3.2.2中“Fine-tuning By training an LLM on structured text representations of the embedding tables, we enable it to learn meaningful patterns present in the data.”学的是embedding,不是time series。
论文Section 5.1的最后(7页底8页)中“distribution over a set of factors that all have the same “power”. Thus, the results suggest that the LLM is indeed better equipped to model the joint distribution when presented with independent factors rather than a hierarchy of variance-ordered components.”,模型学习的是embedding coefficient的联合分布。LLM的作用类似一个“复杂的tabular数据生成模型”。
3. 为什么LLM虽然不直接学习时序结构,生成的仍然像时序?
因为embedding是通过FPC/ICA获取的“时序分解系数”,每组系数对应一条具有时序结构的曲线,只要LLM能生成“合理的embedding分布”,通过basis decode就能得到“合理的时序”。LLM不是time series learner,是一个embedding learner + sampling engine。LLM学到的是“embedding如何组合成一个能重构合理时序的系数模式”。
论文的亮点:用最简单的LLM(GPT-2)也能生成复杂序列,因为时序的结构由embedding方法决定。
4. 为什么SDForger可以做到多样性diversity?
(1)论文Section3.2.2中“We use a multinomial distribution sampling strategy to reduce repetition and generate more creative and diverse outputs.”也就是说在生成embedding值时,使用Multinomial Sampling + Temperature,避免模式坍缩。
(2)FastICA embedding是independence-based,分布天然多样。论文Section 5.1中“ICA explicitly seeks statistically independent components. This tends to produce a more balanced and disentangled basis decomposition, where each component carries distinct information that have similar importance for data reconstruction.”ICA的系数更加独立、不相关,因此,embedding manifold更“宽广”,每个维度都更独立,LLM在采样时更容易“自由组合”不同方向。
(相反,FPC的embedding成分有明显主次顺序(variance ordered),反而diversity较差,所以ICA模型表现更好。)
(3)LLM的随机feature permutation强制“顺序无关”,不会记住固定模板。论文Section 3.2.1中“we apply a random permutation π to the encoded feature-value pairs within each instance.”每一行embedding转成文本时,字段顺序都被随机重新排列,LLM无法依赖“位置模式”记忆,只能学习embedding分布本身,这被论文明确描述为减少positional bias。
(4)基于diversity score的stopping criterion。论文Appendix A.4中“The diversity score provides a quantitative measure of how much variability remains in the generated norms. ...”越到后期embedding会收敛,一旦diversity不再提升,模型就会停止生成(generation stop criterion)。
所以,SDForger是通过采样机制 + embedding独立性 + 过滤策略实现diversity的,不是靠大模型理解时间序列。
总结:
1.存在理论上限,受原始数据分布的影响,模型本身没有表达新结构的能力,是一种在有限embedding分布(原始分布的有限子空间)中进行sampling的模型。想要实现大量多样性,需要修改embedding或让LLM直接建模序列。
2.SDForger本质上是一个高级的embedding distribution sampler,而不是新结构生成器/新模式发现器/自主结构学习模型。
有罪!现在是11月22日,21:25,怎么回事老哥?嗯?嗯?嗯???!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号