CLVS: 基于可变相似度增强对比学习《Enhancing Contrastive Learning with Variable Similarity》(图像、对比学习、可变相似度、扩展对比学习、语义与增强表示对齐、理论分析泛化误差边界、模型学习将语义变化与增强程度进行对应)
2025年11月9日,看的一篇论文。
(现在是11月14日)
论文:Enhancing Contrastive Learning with Variable Similarity
GitHub:
NeurIPS 2025 Spotlight的论文。
有一说一,我不想贴翻译了。虽然我是看的原文,但是翻译出来有的时候就是会怪怪的,现在大家都有AI工具,好像也没必要浪费时间贴翻译。
(现在是11月17日,我还没写这篇博客,我这个老登有罪。)
以下结合ChatGPT的内容进行大体的梳理,不想全部翻译了。
1. 论文核心目标:
问题:传统对比学习框架中,通常假设“同一样本通过两次增强得到的两个视图(positive pair)”具有完全语义不变,即它们在语义上应当被拉得非常近(高相似度)。
实际情况:不同增强操作(裁剪、颜色扰动、旋转、遮挡等)对语义保留程度是不同的,有些增强强会破坏更多的语义特征,而有些增强弱则保留更多特征。因此设定一个固定的、高且相同的相似度目标(语义不变性,所有positive对都应尽量拉近到同一高度)可能忽略了增强造成的语义差异,甚至引导模型去盲目拉近那些语义其实较弱的视图对。
解决:引入“可变相似度(variable similarity)”概念,让不同增强强度/参数下的视图对具有不同的“理想相似度”目标,模型应当根据增强参数调整拉近的程度。
一句话论文:在对比学习中,positive对不应都被视为“同等强”的语义相似,而应按其增强强度/语义破坏程度设定不同的目标相似度。
2. 相关图片和框架图:
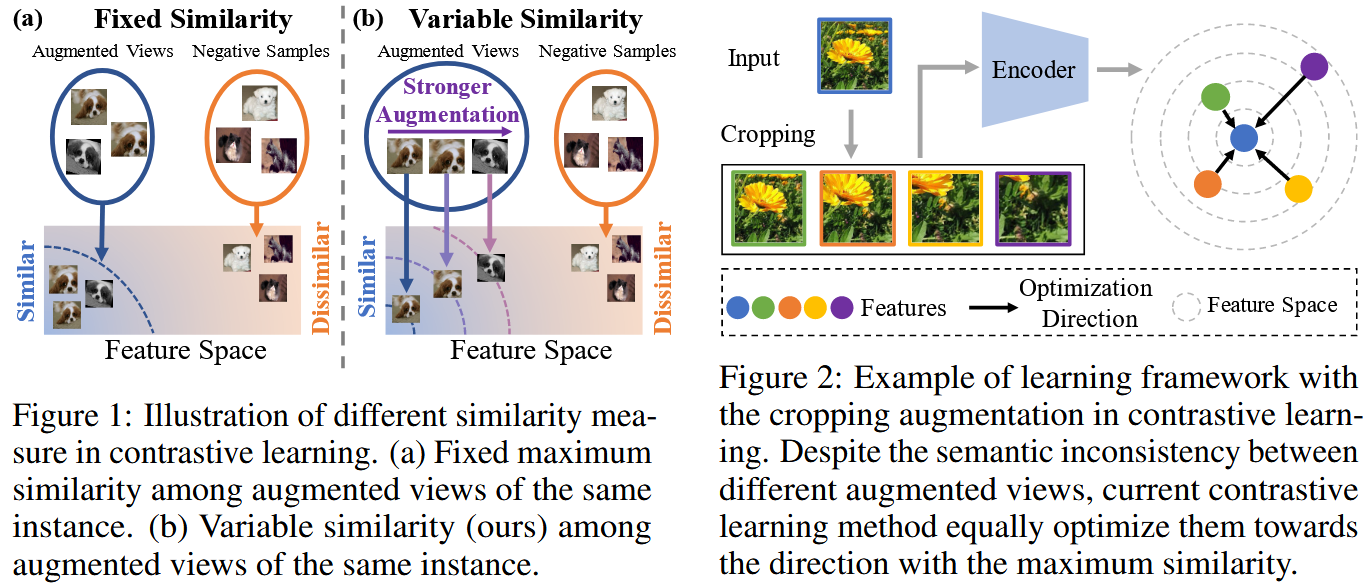
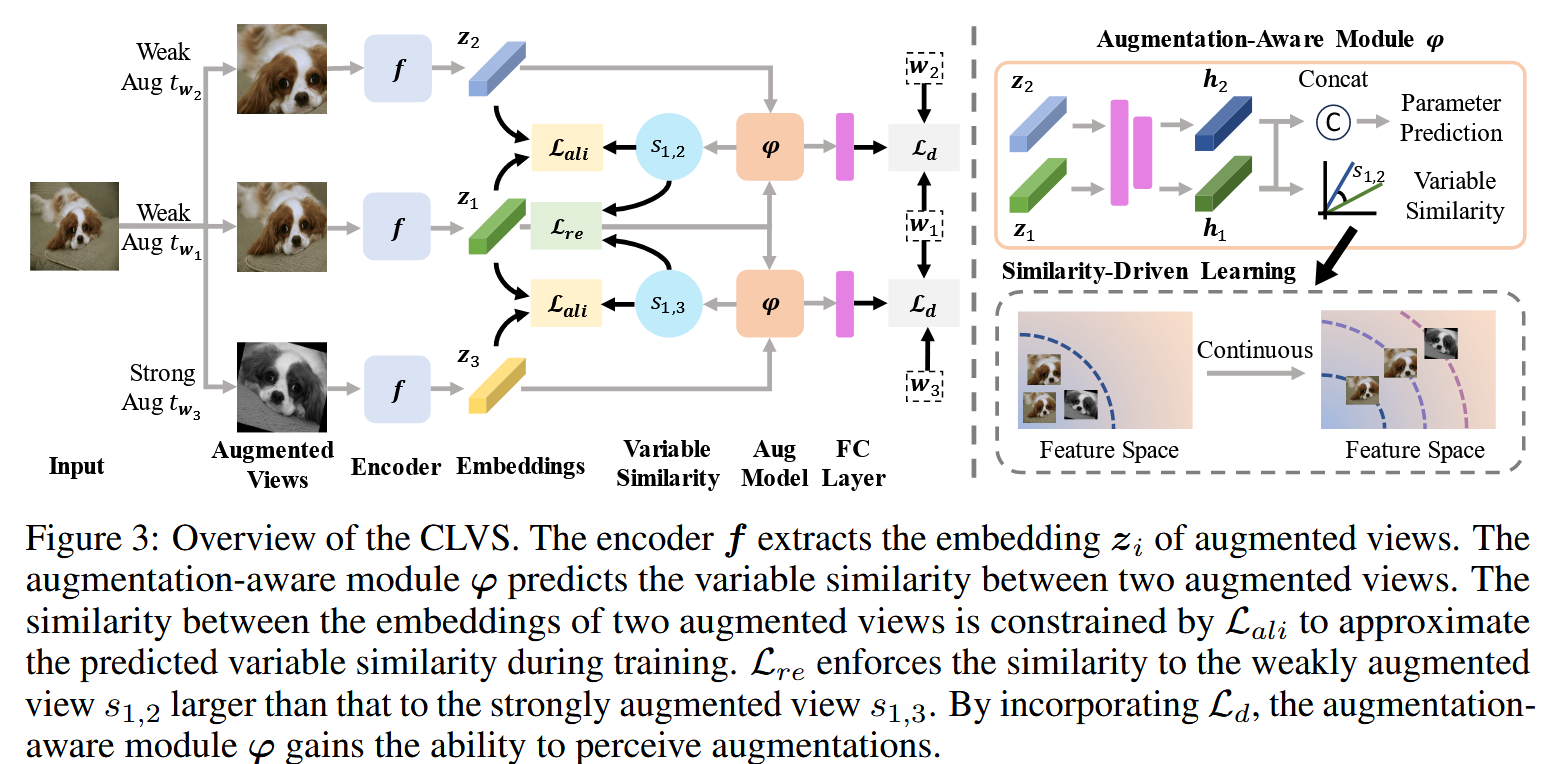
3. 方法机制:
(1)增强-感知模块(Augmentation-Aware Module):通过增强操作得到的两个视图,记录增强操作的参数/类型,将参数表示为一个向量w或差异向量d用于后续预测。设计一个模块用于预测“视图间理想相似度”或直接预测增强参数差异。引入损失Ld,用于训练模块去预测增强参数差异,让模块对增强强度敏感。
(2)可变相似度对齐(Variable Similarity Alignment):设定真实视图特征间的相似度,模块预测出的理想相似度,引入损失Lali,使得模型的实际特征相似度向预测的可变目标靠拢。
(3)相对相似度约束(Relative Similarity Constraint):约束弱增强视图对应的特征相似度 > 强增强视图对应的特征相似度,因为弱增强破坏语义少。引入损失Lre,来惩罚如果强增强的相似度反而高于弱增强的情况。
(4)总损失组合:整个训练过程的总损失为:Ltotal = Lcon(原始对比损失,如InfoNCE) + wLd + λLali + γLre。
(5)理论分析:通过引入可变相似度机制,可以减少估计相似度的方差,从而缩小泛化误差边界(Generalization Error Bound)。即其定理证明:若相似度目标被更精细定义,则模型的泛化误差上界能更低。(定量结果分析泛化误差边界)
4. 实验验证:
实验部分是在标准基础(如ImageNet-100,ImageNet-1k),以已有框架如MoCo和SimSiam为基础,加入CLVS方法。
5. 论文的创新性/新颖所在:
挑战了“增强视图必然语义不变”的传统假设,从更精细的角度考虑“增强强度->语义扰动”的关系。
在对比学习中,通过“拉近/推远”对的力度不再是二元(正对=同等强拉近,负对=强推远),而是连续可调的,有助于模型学习更自然、更弹性的表征。
既有泛化界分析,又有大规模实验结果,理论与实践兼顾。
6. 总结:
(1)主要针对正样本对(同一实例不同增强)的可变相似度机制,而对于负样本对是否也做可变结构尚未扩展(OpenReview的rebuttal中有审稿人问,作者的回复很不错.)。
(2)模块的引入增加了计算开销,大概涨了5%的开销。
(3)虽然有提升,但是在大规模数据集下(ImageNet-1k)提升较小,说明在强大基线下改进空间有限。
一些具体的细节:
1.
3.3 可变相似度的理论分析
这部分有一个作者推导出来的定理:

这个定理的证明是说明:模型的泛化误差上界(generalization error bound),也就是模型从有限样本训练集上学到的目标函数,在真实分布下能有多接近的一个理论保证。
形式上:
![]()
作者用一个定理(Theorem 1)给出了这个误差的上界。


整体可以理解为:模型的泛化误差 = (常数项) x (复杂度相关项) x (样本不确定性项)
这个定理给出了模型泛化误差的一个上界,说明当样本量N较大、正则化较强、对比结构参数合理时,模型从经验风险最小化到真实风险最小化的“偏差”会很小,从而具有良好的泛化能力。
2.
附录
1.定理1的证明:

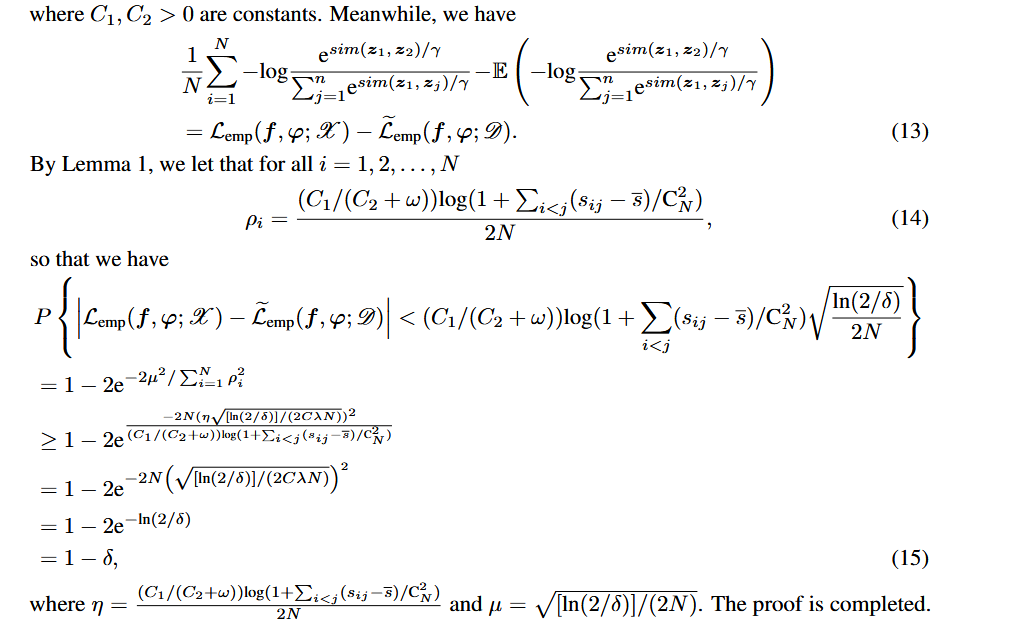
本质是一个泛化误差上界证明(generalization bound proof)。





一个粗糙版本的:

个人的一些疑问和细节问题(结合ChatGPT 5.1的回答):
1. 附录的C.6:大部分参数在0.5附近效果最好是可以理解的,论文中作者提到大部分在[0,1]的中心区域效果最好,因为特征集中在中心区域,但是为什么γ有边际效应?
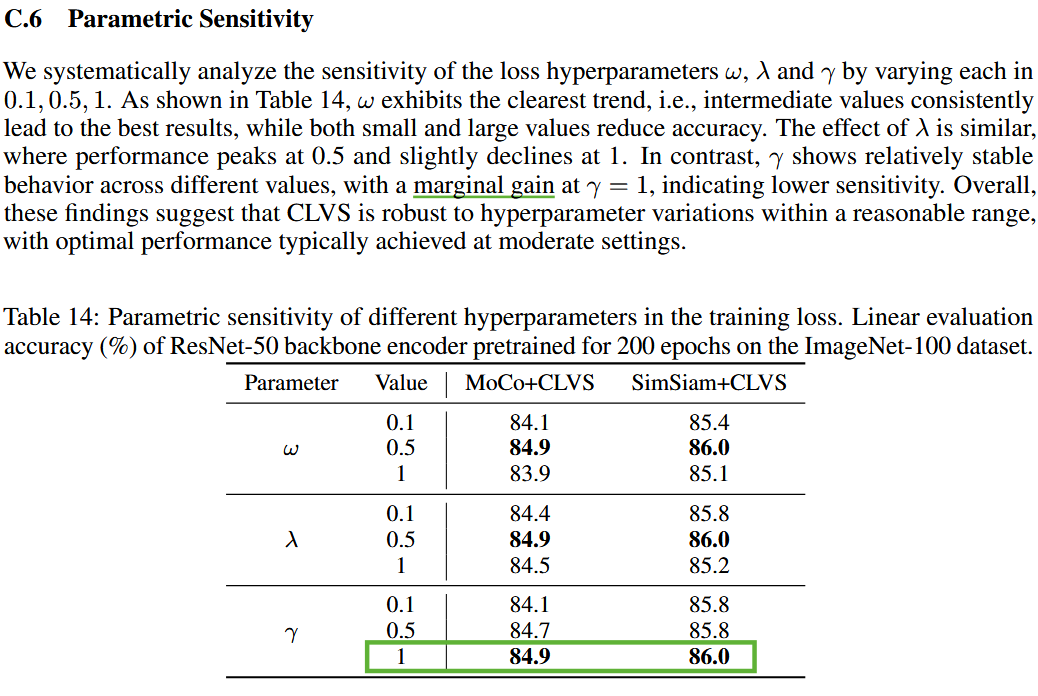
对比学习温度参数(temperature parameter)的边际效应。




2. 论文三个核心组件(增强感知学习、可变相似度对齐、相对相似度约束)之间的逻辑关系是什么?
(1)增强感知学习:目标是捕获增强参数与特征变化之间的映射关系。
目的:通过多层感知机(MLP)模块φ,将编码器提取的特征投射到一个增强感知空间,以便模型能够区分不同增强参数所带来的变化。
核心作用:让模型“知道”当前样本经过了哪种增强、增强幅度多大。学到“增强对语义的影响强度”这一隐含信息。为后续计算“可变相似度”提供更精细的特征表征。
(2)可变相似度对齐:就是为了对齐语义和增强表示之间的一致性。
目的:对齐语义一致性与增强表征一致性,即让“增强后的特征相似度”与模型预测出的“可变相似度”一致。
具体解释:模型通过增强感知模块φ预测两种增强视图之间的可变相似度。实际从编码器输出的特征中计算出真实的余弦相似度。然后使用对齐损失最小化两者差异。这样模型就会自动学到:不同增强导致的语义差异要反映在相似度中。
直观理解:如果增强变化小(语义几乎不变),模型应预测更高相似度;如果增强变化大(语义有偏差),模型应预测更低相似度。
(3)相对相似度约束:
目的:确保模型学习到的相似度满足一个相对排序原则:同一实例的“弱增强视图”之间的相似度应高于“强增强视图”之间的相似度。如果强增强的相似度比弱增强还高(语义矛盾),模型就会被惩罚。
直观理解:弱增强保留更多语义,应该更相似;强增强扰动更多语义,应该更不相似。该约束确保模型学到的“相似性排序”与人类语义认知一致。
总结:增强感知学习,目标:学习增强参数与特征变化的对应关系,对应关系:增强-->特征变化。可变相似度对齐,目标:对齐语义一致性与增强特征一致性,对应关系:语义相似性<-->表征相似性。相对相似度约束,目标:保证弱增强视图的语义一致性高于强增强视图,对应关系:弱增强>强增强(语义保真度)。
是一篇好论文,写的逻辑清晰易懂,故事讲的也好,还有理论和实验数据支撑,nice。
(从11月30日晚上开始补,12月1日上午继续补,现在12月1日,11:19补完了,太废物了,Orz.)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号