GRLSTM: 基于图的残差LSTM轨迹相似性计算《GRLSTM: Trajectory Similarity Computation with Graph-Based Residual LSTM》(轨迹路网融合、知识图谱嵌入、图神经网络、残差网络、点融合图、多头图注意力网络GAT、残差LSTM、点感知损失函数(图的点损失函数、轨迹的点损失函数))
2023年10月18日,14:14。
来不及了,这一篇还是看的翻译。
论文:GRLSTM: Trajectory Similarity Computation with Graph-Based Residual LSTM(需要工具才能访问)
GitHub:
AAAI 2023的论文。
摘要
轨迹相似性的计算是许多空间数据分析应用中的一项关键任务。然而,现有的方法主要是为欧几里得空间中的轨迹设计的,这忽略了真实世界的轨迹通常在道路网络上生成的事实。本文通过提出一种新的框架GRLSTM(基于图的残差LSTM)来解决这一差距。为了联合捕获轨迹和道路网络的特性,所提出的框架将知识图谱嵌入(KGE)、图神经网络(GNN)和残差网络结合到多层LSTM(残差LSTM)中。具体而言,该框架构建了一个点知识图来研究点的多重关系,因为点可能属于轨迹和道路网络。引入KGE来学习点嵌入和关系嵌入以构建点融合图,而GNN用于捕获点融合图的拓扑结构信息。最后,使用残差LSTM来学习轨迹嵌入。为了进一步提高最终轨迹嵌入的准确性和鲁棒性,我们引入了两个新的基于邻域的点损失函数,即基于图的点损失函数和基于轨迹的点损失功能。使用两个真实世界的轨迹数据集对GRLSTM进行了评估,实验结果表明GRLSTM显著优于所有最先进的方法。
介绍
有人提出利用基于嵌入的相似性计算方法,其中每个轨迹都被编码为具有深度学习模型的潜在向量。这意味着轨迹相似性可以在线性时间内通过向量相似性计算来计算。
尽管上述这些方法对于测量欧几里得空间中的轨迹相似性是有效的,但对于计算道路网络上的轨迹相似度,它们并不像预期的那样有效。路网(Wang et al.2021)是指由各种道路组成的道路系统,这些道路相互连接并交织成一个网络。此前,一些研究(Chen et al.2010;尚等人2017b;李、丛和程2020)试图解决道路网络上的轨迹相似性计算问题。特别是,这些研究采用了手工制作的启发式方法来将轨迹与道路网络对齐,并定义了一些有效的相似性函数(Shang et al.2017b)来测量道路网络上的轨迹相似性。然而,这些方法仍然存在计算复杂度高的问题。为了解决上述挑战,最新的框架GTS(Han et al.2021)在道路网络上使用了深度学习方法和图神经网络(GNN)(Kipf and Welling 2017),并取得了不错的性能。然而,GTS遗漏了两个问题。首先,GTS在图形处理期间只考虑道路网络信息而忽略轨迹信息。一个关键点是,由于数据丢失或采样率不一致,轨迹中的相邻点在道路网络上不一定相邻。如图1所示,虚拟边{e12,e35}处于轨迹中,而不存在于道路网络上。另一方面,GTS在不考虑点优化的情况下对轨迹使用优化策略。
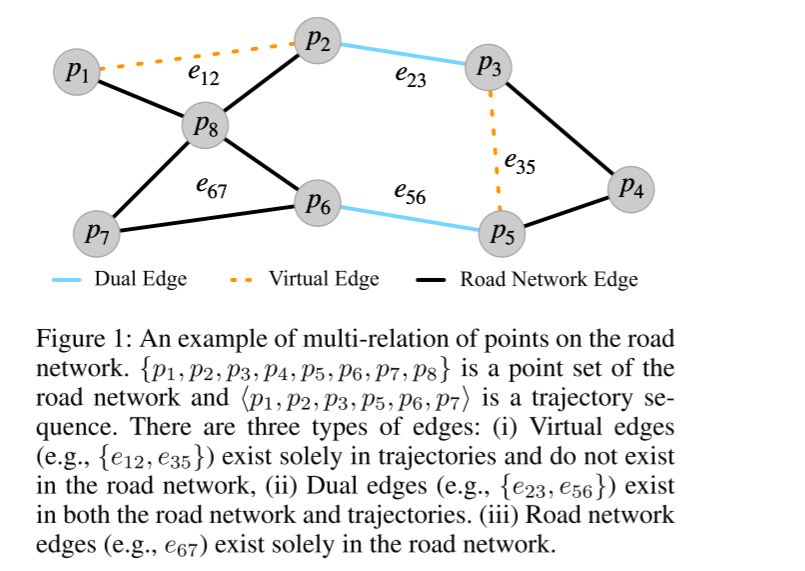
图 1:路网中点的多重关系示例。{p1,p2,p3,p4,p5,p6,p7,p8}是道路网络的点集,⟨p1,p2,p3,p5,p6,p7⟩是轨迹序列。有三种类型的边缘:(i) 虚拟边缘(如{e12, e35})只存在于轨迹中,不存在于路网中;(ii) 双重边缘(如{e23, e56})同时存在于路网和轨迹中。(iii) 道路网络边缘(如 e67)只存在于道路网络中。
为了利用轨迹和道路网络的点信息,我们提出了一个新的框架,即GRLSTM。特别是,我们通过构建知识图,考虑到每个点在道路网络和轨迹中都有多个关系。然后,我们将KGE方法应用于知识图,并通过k最近选择进一步构建融合图。接下来,引入GAT(Velickovic等人,2018)来捕获融合图的拓扑结构信息。通过多层LSTM来学习最终的轨迹表示。为了解决深层LSTM中各层之间的消失梯度问题,我们通过将残差网络(He等人,2016)纳入多层LSTM中,设计了一个新的模块,即残差LSTM。此外,我们设计了两个新的基于邻居的点感知损失函数来优化GRLSTM:(i)基于图的点损失。为了优化图级的点嵌入,我们认为图中连接的点应该是相似的。(ii)基于轨迹的点损失。我们认为轨迹中的点是一个相似的集合。换句话说,同一轨迹中的点嵌入应该是相似的。这是基于观察到的轨迹通常是从同一辆车上采样的。
简而言之,本文的主要贡献总结如下:
•我们提出了GRLSTM,一种新的道路网络轨迹相似性计算框架。它使用KGE用知识图对多个点的关系进行建模。我们将残差网络引入多层LSTM来学习轨迹嵌入,这可以解决梯度消失问题。
•我们设计了两个新的基于邻居的点感知损失函数(即基于图的点损失和基于轨迹的点损失)来有效地训练GRLSTM。
•我们在两个真实世界的数据集上进行了广泛的实验。实验表明,与最先进的方法相比,我们的方法有了显著的改进。
相关工作
无深度学习的轨迹相似性
在传统方法中,轨迹相似性计算方法主要有两种。一种是基于欧几里得空间,使用动态编程来分析轨迹片段,如动态时间扭曲(DTW)(Yi、Jagadish 和 Faloutsos,1998 年)、最长公共子序列(LCSS)(Vlachos、Gunopulos 和 Kollios,2002 年)、带真实惩罚的编辑距离(ERP)(Chen 和 Ng,2004 年)以及真实序列上的编辑距离(ERD)(Chen、Ozsu,¨ 和 Oria,2005 年)。 和 Oria 2005)。这些方法通常利用一些优化技术(Rakthanmanon 等人,2012 年)来减少计算时间,但会受到噪声点的干扰,导致最终精度下降。另一种轨迹相似性计算方法基于道路网络。在这些方法中,每条轨迹的所有坐标点都需要映射到道路网络中,以找到相应的节点。然后使用相似度函数计算轨迹之间的相似度。早期的方法只是简单地应用最短路径算法和设置相似度来计算轨迹相似度。后来,Shang 等人(Shang et al. 2017b, 2018, 2019)在考虑了空间和时间的相似性后提出了联合相似性函数,并通过剪枝和索引技术加快了计算速度。也出现了设计新函数(Wang 等人,2018)来计算轨迹之间的相似性。(Zheng等人,2021)提出了一种分布式内存管理框架来加速轨迹相似性查询。然而,传统的基于道路约束的方法要么过于简单,要么受计算复杂度高的影响,由于处理大规模数据的问题,很难在实践中应用。
深度学习的轨迹相似性
近年来,深度学习模型在轨迹相似性计算方面表现出了卓越的性能。有一些研究将深度学习应用于空间数据分析(Han 等,2019,2020;Zhao 等,2020)。由于轨迹序列的特点,现有的一些研究应用自然语言处理的深度学习模型生成轨迹表示。轨迹之间的相似性可以通过测量轨迹表示之间的关系来获得。李等人(Li et al. 2018)采用编码器解码器模型获得轨迹嵌入。Yao等(Yao et al. 2019, 2020)将注意力机制引入空间网络,利用成对距离辅助学习处理,使得性能更加有效。为了提高轨迹嵌入的学习质量,张等人(Zhang et al. 2020)设计了几个新的损失函数。Han 等人(Han et al. 2021)首先将 GNN 引入道路网络的轨迹相似性计算。
前言
带道路网的轨迹
略。
问题定义
略。
基于图的残差LSTM
在本节中,我们将介绍一种用于轨迹表示学习的新型框架 GRLSTM,它包括三个部分:点知识图嵌入、融合图嵌入和残差-LSTM。图 2 显示了我们模型的整体框架。
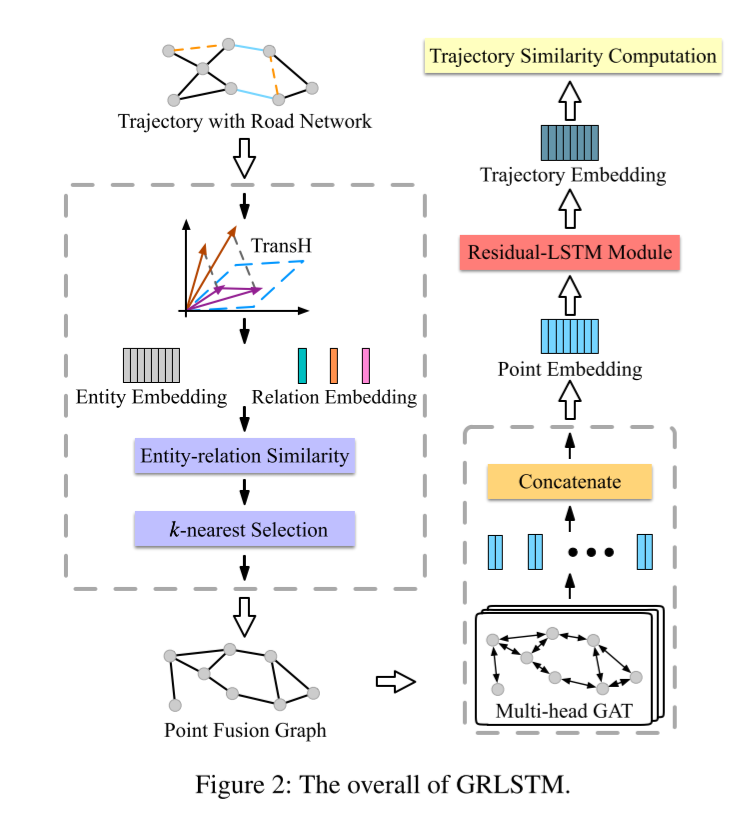
知识图谱在点上的嵌入
每个点既属于路网,也属于轨迹。由于设备采样率不同或数据丢失,轨迹通常不是道路网络上的连续序列,这意味着轨迹中的相邻点在道路网络上并不一定相邻。换句话说,轨迹中存在一些虚拟边缘,而道路网络中却没有,如图 1 中的边缘 {e12,e35}。
为了解决上述问题,我们将道路网络和轨迹结合起来,构建了一个知识图谱。知识图谱是一种语义网络,可以揭示实体之间的关系。具体来说,给定一个轨迹数据集和道路网络图,我们构建一个道路网络-轨迹知识图谱 G = (V,E,R),其中 R 有三种关系类型:道路网络边 rn、轨迹虚拟边 rt、对偶边 rnt。因此,每个 e = ⟨u、v⟩∈ E 与一个关系 r∈R 可以构建一个三元组(例如,⟨u、rn、v⟩)。
为了有效揭示实体(即点)之间的关系,我们使用 TransH(Wang 等人,2014 年)来学习实体和关系嵌入。TransH 的基本思想是使用不同的超平面来表示不同的关系空间,并将关系视为超平面上的平移操作。形式上,给定一个三元组 ⟨u,r,v⟩,其中 u、v ∈ V,r ∈ R,相应的实体嵌入 eu 和 ev 首先投影到超平面 wr 上,约束 ||wr||2 = 1,具体如下:
![]()
其中,eu⊥ 和 ev⊥ 分别表示 eu 和 er 的投影嵌入。然后,我们使用分数函数 f(-) 计算三元组的差值,可表示为:
略。(时间来不及了)
到目前为止,每个实体(即点)和每个关系都是通过嵌入来表示的。为了捕捉不同关系中点的相关性,我们设计了一个实体-关系相似度函数 s(-),用于计算特定关系 r 中点 u 和点 v 之间的嵌入相似度:
![]()
为了整合轨迹和路网信息,我们通过相似性来构建点融合图 Gf ∈ R|V||×|V||。在此,我们使用 k-nearest selection 方法,根据相似性获得点 vi 的邻居集 Ns(vi),以保持图的稀疏性并减少噪声。然后,我们得到如下图:
![]()
Gf 是一个新的图,它有通过相似性构建的新边。请注意,轨迹中的相邻点在融合图中也不一定相邻。但是,通过使用 KGE 以及相似性对点进行建模,融合图中的点可以同时包含路网和轨迹特征。因此,Gf 可以更好地表示融合图中每个点的特性,而这是路网图所不具备的。(这段话没看懂,呜呜呜T-T)
点上的图嵌入
为了捕捉融合图 Gf 中的拓扑结构,我们采用图注意网络(GAT)(Velickovic 等人,2018 年)来学习图嵌入。GAT 使用消息传递图神经网络实现聚合和更新处理。形式上,给定点嵌入 P =p1, p2, ..., p|V| ,我们按如下方式更新节点嵌入:
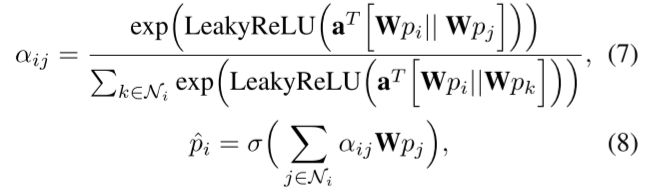
其中,W 和 a 是可学习参数,σ 是激活函数,|| 表示串联,Ni 是可从 Gf 中获得的邻居集。为了提高 GAT 的特征表达能力,我们按照(Velickovic 等人,2018 年)的建议使用多头 GAT。我们将多头 GAT 的输出嵌入连接起来,具体如下:
![]()
其中,H 是头部数量,|| 是连接操作,σ 是激活函数。
到目前为止,新的点嵌入是通过图嵌入层学习的,其中包含来自 Gf 的丰富图结构信息。然后,我们将这些点嵌入作为残差-LSTM 模块的输入,学习轨迹嵌入。
多层 LSTM 与残差网络
轨迹数据是一种典型的序列结构,因此基于 RNN 的方法是一种合适的方法。在我们的实现中,我们选择 LSTM 来学习轨迹嵌入。具体来说,我们首先将轨迹中的每个点转换为基于图的点嵌入。然后,我们使用 LSTM 融合序列嵌入。在这里,我们将 LSTM 最后一个时间步的输出作为最终的轨迹嵌入。为了获得更好的性能,我们在模型中进一步应用了多层 LSTM。但是,简单地堆叠 LSTM 的层数会导致严重的梯度消失问题,使收敛性急剧下降,学习效果变差。此外,多层 LSTM 还会延长训练时间。因此,我们需要找到一种既能解决多层 LSTM 梯度消失问题,又不增加训练时间的方法。
受 ResNet(He 等人,2016 年)的启发,我们在多层 LSTM 中引入了残差网络。ResNet 在计算机视觉领域大放异彩,有效解决了深度模型学习中的梯度消失问题。由于其出色的性能,我们在模型中将 ResNet 集成到了多层 LSTM 中。对于多层 LSTM 中的每一个时间步 i,我们用以下方式表示 ResidualLSTM 中的残差块:
![]()
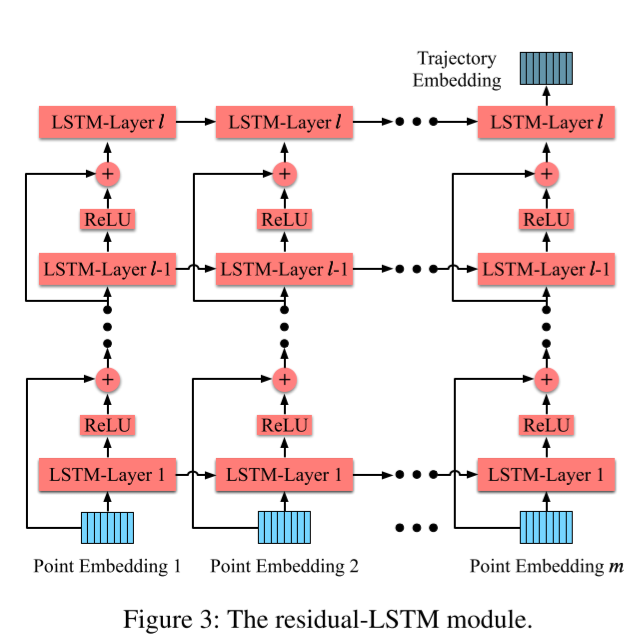
其中,ˆip(l-1) 和 ˆp(l) 分别是第 l 层残差-LSTM 在第 i 个时间步的输入和输出。W(l) i 表示第 l 层中第 i 个时间步骤的所有可学习参数。H(-) 代表身份连接,可通过 H(ˆp(l-1) i ) = ˆip(l-1) 得到。我们将残差-LSTM 最后一层的最后一个时间点隐藏输出作为最终轨迹嵌入。
如图 3 所示,我们在不同 LSTM 层之间建立身份连接操作。我们将上一层 l 的输入与上一层 l 的输出相结合,作为下一层 l +1 的输入。这种结构有两个好处。一方面,残差网络的引入可以通过身份连接解决多层 LSTM 中的梯度消失问题。另一方面,残差块除了按元素加法和激活操作外,不增加任何额外的训练参数。因此,与多层 LSTM 相比,残差 LSTM 在训练时间上的增加几乎可以忽略不计。
目标函数
嵌入相似性
训练结束后,训练集中的所有轨迹都会转换为轨迹嵌入。在本研究中,我们使用点积来衡量轨迹嵌入之间的相似性。假设轨迹 τi 和 τj 的嵌入分别为 ti 和 tj。轨迹嵌入相似度得分的计算方法如下:
![]()
同样,我们也可以用点积定义点嵌入相似度得分。假设点 vi 和 vj 的嵌入分别为 pi 和 pj。点嵌入相似度得分可定义为:
![]()
然后,我们可以定义目标函数,通过这些相似性函数来优化我们的模型。
点感知损失函数
图 1 显示,路网中的点具有不同的属性,而点融合图 Gf 就是根据这些属性构建的。受这些不同关系的启发,我们定义了两种基于邻居的点感知损失函数(即基于图的点损失和基于轨迹的点损失)来优化点嵌入。在这里,我们首先定义了两种点邻接关系,以便更好地详细说明我们的基于邻接的点感知损失函数。
基于图形的点邻接。我们将基于图的点邻接定义为融合图上的一阶邻接。直观地说,图上的每个节点与其一阶邻居都有很高的相似度。我们将一个点的一阶邻居集表示为 Ngp,即 |Ngp| = k。
请注意,k-近邻选择的数量对融合图上的一阶邻居数量有很大影响。为了减少这些影响,我们采用在其他基于排序的应用中广泛使用的采样内成对方法来设计基于图的点损失函数。形式上,给定一个轨迹集 T = {τ1, τ2, ..., τm} 和 τi =D vi 1, vi 2, ..., vi |τi| E 定义基于图的点损失函数如下:
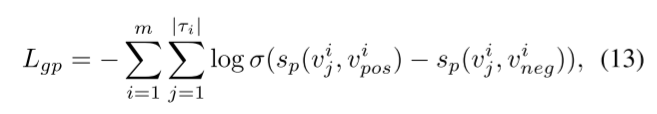
其中,σ 为 sigmoid 函数,vi j 为轨迹 τi 的一个点,vi pos 为从 Ngp(vi j) 中采样的一个正点,vi neg /∈ Ngp(vi j) 为从融合图中采样的一个负点。
基于轨迹的点邻接。根据前面的分析,轨迹中相邻的点在路网中不一定相邻,融合图 Gf 也是如此。然而,轨迹中相邻点之间的相似度很高,例如车辆的运动趋势。具体来说,给定轨迹 τ = v1, v2, ..., v|τ| 和一个点 vi∈ τ,我们将 vi 的上一点和下一点定义为基于轨迹的点邻域,其中 v1 只有下一点,v|τ| 只有上一点。我们用 Ntp 和 |Ntp| ∈ {1, 2} 表示基于轨迹的点邻域。
同样,我们使用成对函数来设计基于轨迹的点损失函数。形式上,给定一个轨迹集 T = {τ1, τ2, ..., τm} 和 τi = D vi 1, vi 2, ..., vi |τi| E∈ T,我们对基于轨迹的轨迹点损失函数定义如下:

其中,σ 是 sigmoid 函数,vi j 是轨迹 τi 的一个点,vi pos 是从 Ntp(vi j)中采样的一个正点,vi neg /∈ τi 是从融合图中采样的一个负点。
轨迹感知损失函数
根据公式 11,我们可以用线性复杂度计算两条轨迹之间的相似度。然而,我们的目标是找到最相似的轨迹,而不仅仅是计算相似度得分。因此,我们需要定义轨迹感知损失函数来优化我们的模型。
按照(Han 等人,2021 年)的方法,我们也使用配对法来设计轨迹损失函数。形式上,给定一个轨迹集 T = {τ1, τ2, ..., τm},我们定义轨迹损失函数如下:
![]()
其中,σ 是西格玛函数,τpos 是与τi 最相似的轨迹,τneg 是来自 T/ {τi, τpos} 的负样本。
最后,最终目标函数可写成:
![]()
实验
在本节中,我们将进行一系列实验。主要介绍数据集、超参数设置和评估指标。然后,我们将对实验结果进行详细分析。
实验设置
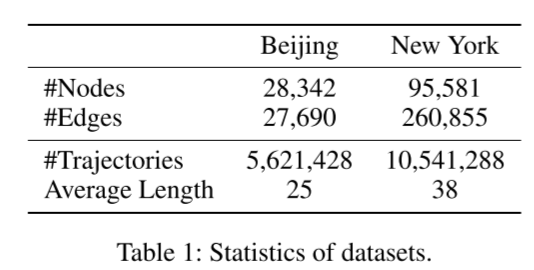
数据集。我们使用了北京和纽约这两个不同城市的真实道路网络。表 1 显示了两个数据集的详细信息。在北京的道路网络中,共有 28,342 个节点和 27,690 条边。对于北京的轨迹,我们使用了 T-drive 项目 1 中的出租车轨迹。这些出租车轨迹是通过出租车 ID、GPS 坐标和时间戳从 10357 辆出租车中收集的。我们将这些轨迹按小时分割,去掉短时轨迹。这样就得到了 5,621,428 条轨迹,北京轨迹的平均长度为 25。我们使用空间相似函数(Shang 等人,2017b)通过 GPS 坐标创建北京路网的地面实况。在纽约路网中,有 95,581 个节点和 260,855 条边。对于纽约的轨迹,我们从网站 2 收集了出租车行驶数据。我们使用相同的预处理方法来处理这些轨迹,并得到地面实况。最后,我们得到了 10,541,288 条轨迹,这些轨迹的平均长度为 38。对于这两个数据集,我们按照 [0.2, 0.1, 0.7] 的比例将这些数据随机分成训练集、验证集和测试集。
超参数。在我们的模型中,嵌入维度为 128,基线的设置与此相同。我们使用 Adam(Kingma 和 Ba,2015 年)来优化模型,北京数据集的学习率设置为 5e-4,纽约数据集的学习率设置为 1e-3。北京数据集的训练批次大小为 256,纽约数据集的训练批次大小为 512。我们将残差-LSTM 的层数设为 4,GAT 的头数设为 8,GAT 层数设为 1,k 邻近选择在北京数据集中设为 10,在纽约数据集中设为 30。我们的模型由 Pytorch 实现,并在 Nvidia RTX3090 GPU 上进行训练。具体实现细节可参见本网站。
评估指标。根据之前的研究,我们采用 HR@K 作为主要性能指标。topk 命中率(HR@k)考察的是返回的 top-k 结果与地面实况之间的重叠程度。在实验中,我们采用 HR@1、HR@5、HR@10、HR@20 和 HR@50 作为主要性能指标。
基准。在实验中,我们将 GRLSTM 与以下竞争对手进行了对比评估:
- Traj2vec(Yao 等人,2018 年): 一种序列到序列模型,用于学习轨迹嵌入。均方误差被用作优化模型的损失函数。
- Siamese(Pei、Tax 和 van der Maaten,2016 年): 连体网络上的时间序列学习方法。它使用交叉熵损失函数来训练模型。
- NeuTraj(Yao 等人,2019 年): 该框架修改了 LSTM 的结构,以学习基于网格的轨迹嵌入。
- Traj2SimVec(Zhang 等人,2020 年): 该方法通过点匹配为轨迹相似性采用了一种新的损失。
- GTS(Han 等,2021 年): 该框架是第一个在道路网络上利用图学习进行轨迹相似性计算的模型。它使用 GCN 和 LSTM 学习轨迹嵌入。
整体性能
表 2 报告了与基线对比的实验结果。根据这些结果,我们的分析总结如下:
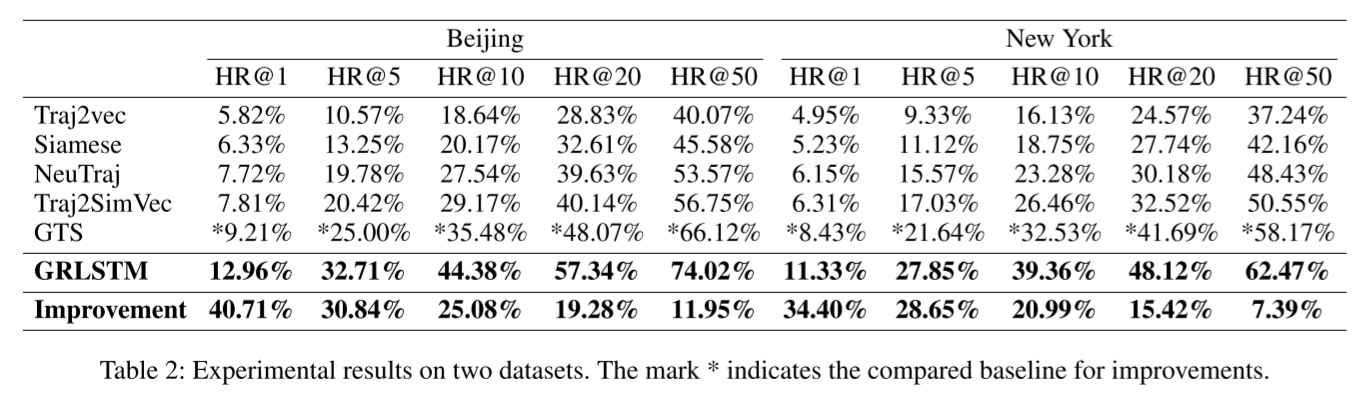
总体而言,我们的 GRLSTM 在两个数据集上取得了最佳性能,在 top-k 命中率指数方面明显优于所有最先进的基线方法。与最佳基准 GTS 相比,我们的模型在北京数据集上的平均改进率为 25.57%,在纽约数据集上的平均改进率为 21.37%。值得一提的是,在北京和纽约数据集上,GRLSTM 的 HR@1 相对于 GTS 分别提高了 40.71% 和 34.40%。这些巨大进步可归因于四个原因: 1) 我们考虑了路网中点的多重关系,并应用 KGE 学习实体嵌入和关系嵌入。基于这些嵌入,我们进一步构建了点融合图,其中每个点都集成了轨迹和路网信息。2) 我们使用多头 GAT 学习基于图的点嵌入,它可以从不同的隐藏通道捕捉融合图的属性。3). 我们在多层 LSTM 中引入了残差网络,这使得我们的模型可以训练更深的 LSTM 并大幅提高性能。4)我们设计了两个新的基于邻居的点感知损失函数,可以从不同的点方面优化我们的模型。
具体来说,Traj2vec 的损失函数是基于拟合方法设计的,对于更复杂的模型,其准确率会显著降低。GRLSTM 学习基于图的点嵌入,并使用这些学习到的点嵌入来表示轨迹嵌入。GRLSTM 采用了三种成对损失函数进行优化,与 Trajvec 的均方误差损失、Siamese 的交叉熵损失和 NeuTraj 的回归损失相比,成对损失函数更为有效。此外,我们模型中的成对损失可以学习偏序关系,更适合 topk 推荐。Traj2SimVec 使用 L2-norm 来计算嵌入向量之间的差值,而我们的模型使用点积来计算相似度,因此线性复杂度更高,效果更好。与使用简单 GNN 聚合邻居信息的 GTS 相比,我们的模型使用的 GAT 比简单 GNN 有更强的图表示学习能力。更重要的是,我们的模型考虑了道路网络中点和轨迹的多重关系,而 GTS 仅根据道路网络学习轨迹嵌入。
消融实验
略。
我们使用北京数据集进行消融实验,结果如表 3 所示,并得出以下分析和结论。
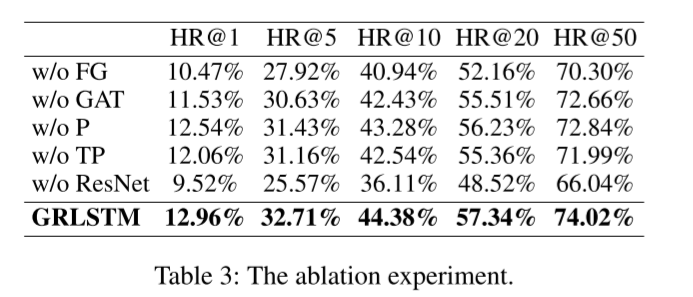
首先,我们发现点融合图可以显著提高性能。事实上,道路网络中的点并不包含任何轨迹序列信息。然而,融合图中的每个点都充分包含了路网和轨迹信息,可以更好地表示点的多重相关性,因为点融合图是由 KGE 的实体(即点)嵌入和关系嵌入计算出的实体-关系相似性构建的。
其次,GAT 的性能优于 GCN,尤其是多头 GAT。GCN 使用邻居的度信息来更新中心节点的嵌入,而 GAT 采用了关注机制,可以聚合邻居节点的嵌入,用关注因子更新中心节点的嵌入,并通过给邻居分配不同的权重而获益。
第三,我们的两个新颖的基于邻居的点感知损失函数对我们的模型有很大贡献。基于图的点损失函数以图为基础,可以利用图的邻居信息优化我们的模型。在训练过程中,它使用图中的一阶邻居相似度以及成对函数来优化点嵌入。对于基于轨迹的点损失函数,它使用正负采样的成对函数来衡量轨迹上点的相似性。
此外,残差网络能显著提高我们模型的性能,这说明了残差网络在多层 LSTM 中的重要性。多层 LSTM 在反向传播时会产生严重的梯度消失,从而导致严重的性能下降问题。多层 LSTM 的训练时间随着层数的增加而增加。通过在多层 LSTM 中引入残差网络,可以在不增加训练时间的情况下解决梯度消失问题。
残差-LSTM 层实验
为了揭示残差网络在多层 LSTM 中的作用,我们基于北京数据集设计了残差-LSTM 层数实验。结果如表 4 所示,其中 GRLSTM-l 表示带残差网络的 l 层 LSTM,GLSTM-l 表示不带残差网络的 l 层 LSTM。
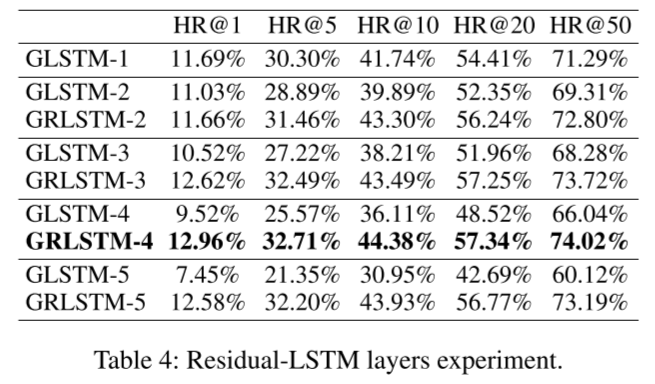
首先,残差网络可以显著提高多层 LSTM 的性能。随着 LSTM 层数的增加,多层 LSTM 的性能开始下降。其中,与 GLSTM-1 相比,GLSTM-5 的 HR@1 性能甚至降低了 36.27%。相反,在残差网络的帮助下,多层 LSTM 的性能有了大幅提升。显然,残差网络可以很好地解决多层 LSTM 的梯度消失问题。此外,当 LSTM 层数超过 4 层时,GRLSTM 的最终结果趋于平稳,这表明我们的模型在第 4 层时达到了最佳状态。与 GRLSTM-4 相比,GRLSTM-5 的性能略有下降,这表明我们的模型似乎略微过度拟合。
结论
本文提出了一种名为 GRLSTM 的新型道路网络轨迹相似性计算框架。在我们的模型中,我们研究了道路网络上点的多重关系,并构建了点知识图谱。我们利用知识图嵌入方法来学习实体(即点)和关系嵌入。通过学习嵌入和 k 近邻选择,我们进一步构建了点融合图,以整合轨迹和路网信息。为了捕捉点融合图的拓扑特性,我们使用多头 GAT 学习基于图的点嵌入。然后,我们设计了一个名为 ResidualLSTM 的新模块来学习最终的轨迹嵌入,其中多层 LSTM 中的残差网络可以解决梯度消失问题。此外,我们还设计了两个新的基于邻居的点感知损失函数来优化 GRLSTM,包括基于图的点损失函数和基于轨迹的点损失函数。大量实验表明,我们的 GRLSTM 模型在两个实际数据集上的表现明显优于现有方法。
现在是22:03,结束。
(呜呜呜呜呜,我是憨批,之前看的论文一直没看完,明天开组会,临时凑一篇,下午去上课都在看论文,我也是醉了,我就是最菜的那个人。准备去写汇报PPT了。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号