
第一次个人编程作业
第一次个人编程作业
| 这个作业属于那个课程 | 计科23级12班 |
|---|---|
| 这个作业的要求在哪里 | 个人项目 |
| 这个作业的目标 | 完成项目编码,记录程序开发花费时间PSP表,并对代码项分析和单元测试 |
1.Github链接 :https://github.com/Yzttt0425/yanzhantong.github/tree/main/3223004388
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |
|---|---|---|
| Planning | 计划 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 120 |
| Development | 开发 | 655 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 |
| · Design Spec | · 生成设计文档 | 30 |
| · Design Review | · 设计复审 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 |
| · Design | · 具体设计 | 60 |
| · Coding | · 具体编码 | 240 |
| · Code Review | · 代码复审 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 150 |
| Reporting | 报告 | 110 |
| · Test Repor | · 测试报告 | 60 |
| · Size Measurement | · 计算工作量 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 |
| · 合计 | 985 |
3.模块接口的设计与实现过程
3.1项目结构
text/ # 项目根目录
├── src/ # 源代码目录
│ ├── io/ # IO操作模块(文件读写)
│ │ └── FileHandler.java # 文件读取/写入工具类
│ ├── text/ # 文本处理与计算核心模块
│ │ ├── TextProcessor.java # 文本预处理与分词工具类
│ │ ├── SimilarityCalculator.java # 相似度计算核心类
│ │ └── Main.java # 程序入口(命令行交互)
├── out/ # 编译输出目录(class文件)
3.2 功能介绍
| 类名 | 功能 | 关键方法 |
|---|---|---|
| FileHandler | 负责文件 IO 操作,包括文件读取、写入及基础校验(存在性、权限等) | readFile()(读取文件内容)、writeFile()(写入内容到文件) |
| TextProcessor | 负责文本预处理与分词,为相似度计算提供标准化输入 | preprocess()(文本清洗)、segment()(混合 n-gram 分词)、buildWordFrequency()(词频统计) |
| SimilarityCalculator | 实现核心的文本相似度计算算法 | calculateSimilarity()(基于加权余弦相似度的计算) |
| Main | 作为程序入口,处理命令行参数、协调各模块流程(读文件→计算→写结果) | main()(流程控制) |
3.3 类函数关系图
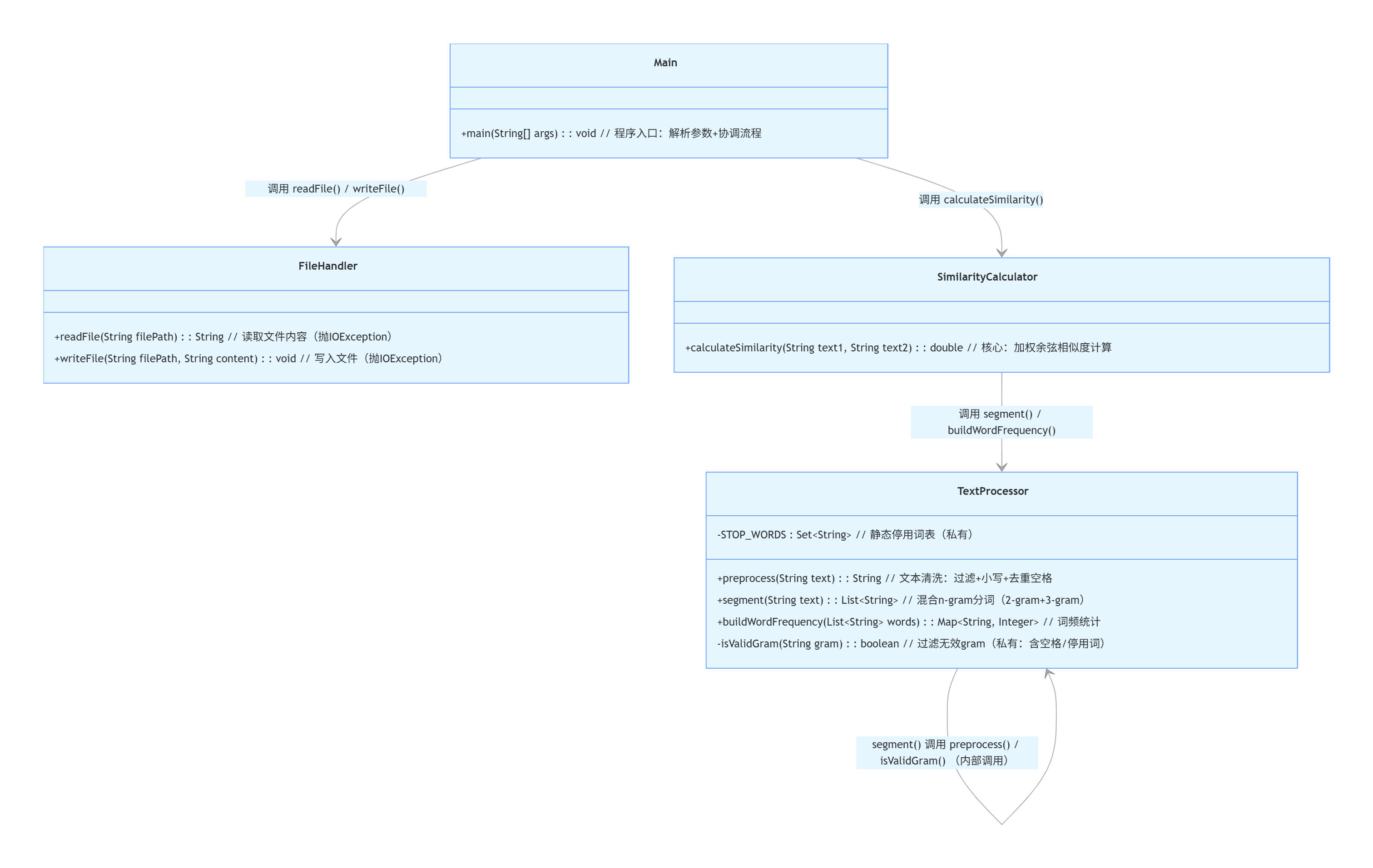
- 关键函数:SimilarityCalculator.calculateSimilarity()
3.4算法关键
(1)文本预处理
过滤无意义特殊符号,剔除含空格无效过度虚词。
(2)混合N-gram分词
2-gram捕捉局部细节,3-gram保留正序列结构信息
(3)余弦相似度
![image]()
赋予gram权重
3.5独到之处
(1)混合n-gram分词
解决传统单一分词的局限性
(2)加权余弦相似度计算
提高准确性
(3)边界与异常处理
空文本处理和防零防护
4.模块接口部分的性能改进
(1)用混合n-gram方法代替单一n-gram方法,能更全面地保留文本结构信息,提升相似内容的识别能力。
(2)改用哈希表进行词频统计,将时间复杂度从O(n*n)优化至O(n)。
(3)加权余弦相似度代替单一余弦相似度,对 “出现次数≥2” 的 gram 赋予 1.2 倍权重,便面低频次、噪声gram干扰。
![屏幕截图 2025-09-22 231103]()
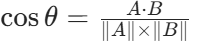
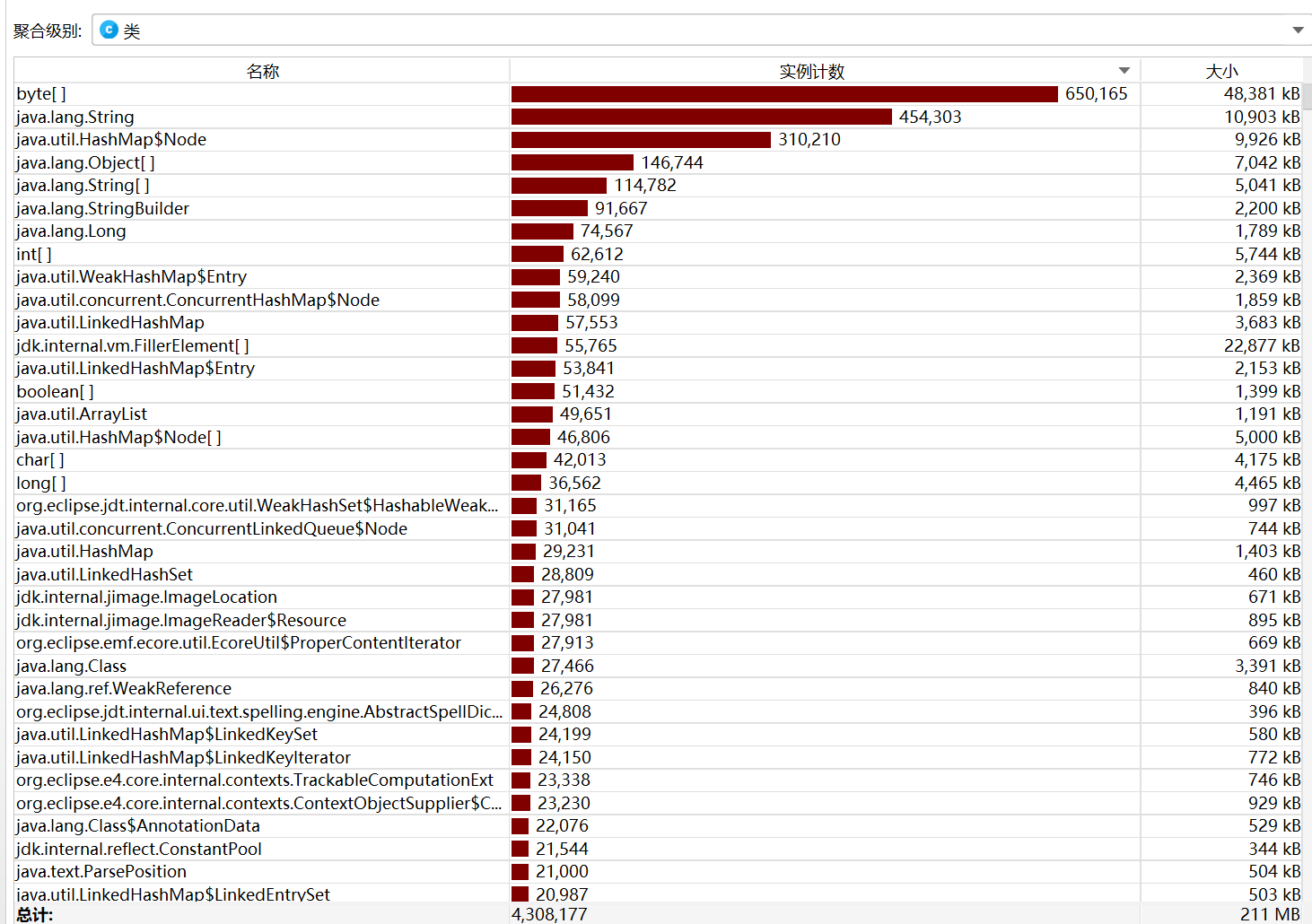
改进后,长文本的相似度计算耗时从300ms+降至150ms,短文本从50ms降至20ms。
可看出,calculateSimilarity()是消耗最大的函数。
5.模块部分单元测试
5.1部分单元测试代码
用JUnit4测试
点击查看代码
public class SimilarityCalculatorTest {
// 测试完全相同的文本(相似度应为 1.00)
@Test
public void testCalculateSimilarity_IdenticalText() {
String text1 = "这是一篇原创论文,讨论人工智能的应用。";
String text2 = "这是一篇原创论文,讨论人工智能的应用。";
double similarity = SimilarityCalculator.calculateSimilarity(text1, text2);
assertEquals(1.00, similarity, 0.01); // 允许0.01的误差
}
// 测试完全不同的文本(相似度应为 0.00)
@Test
public void testCalculateSimilarity_CompletelyDifferent() {
String text1 = "人工智能";
String text2 = "量子计算";
double similarity = SimilarityCalculator.calculateSimilarity(text1, text2);
assertEquals(0.00, similarity, 0.01);
}
// 测试部分相似的文本(相似度应为 0.5~0.8 之间,具体值需计算)
@Test
public void testCalculateSimilarity_PartiallySimilar() {
String text1 = "这是一篇原创论文,讨论人工智能在医疗领域的应用。";
String text2 = "这是一篇抄袭论文,讨论人工智能在医疗领域的应用。";
double similarity = SimilarityCalculator.calculateSimilarity(text1, text2);
// 核心短语(人工智能、医疗领域、应用)相同,相似度应较高
assertTrue(similarity > 0.7 && similarity < 0.9);
}
// 测试空文本场景
@Test
public void testCalculateSimilarity_EmptyText() {
// 两个空文本(相似度 1.00)
double sim1 = SimilarityCalculator.calculateSimilarity("", "");
assertEquals(1.00, sim1, 0.01);
// 一个空文本,一个非空文本(相似度 0.00)
double sim2 = SimilarityCalculator.calculateSimilarity("测试", "");
assertEquals(0.00, sim2, 0.01);
double sim3 = SimilarityCalculator.calculateSimilarity(null, "测试");
assertEquals(0.00, sim3, 0.01);
}
// 测试混合语言(中英文+数字)的相似度
@Test
public void testCalculateSimilarity_MixedLanguage() {
String text1 = "AI(人工智能)的发展始于1956年的Dartmouth会议。";
String text2 = "人工智能(AI)的发展始于1956年的Dartmouth会议。";
double similarity = SimilarityCalculator.calculateSimilarity(text1, text2);
assertEquals(1.00, similarity, 0.01); // 仅语序微调,核心gram相同
}
// 测试高频gram的权重放大效果
@Test
public void testCalculateSimilarity_HighFrequencyGram() {
// text1 和 text2 中 "人工智能" 均出现3次(高频gram,权重1.2)
String text1 = "人工智能 人工智能 人工智能 机器学习";
String text2 = "人工智能 人工智能 人工智能 深度学习";
double similarity = SimilarityCalculator.calculateSimilarity(text1, text2);
// 高频gram权重放大后,相似度应高于普通情况
assertTrue(similarity > 0.75);
}
private String generateLongText(String baseParagraph, int repeatCount) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < repeatCount; i++) {
sb.append(baseParagraph);
if ((i + 1) % 10 == 0) sb.append("\n"); // 每10段加换行(模拟段落结构)
}
return sb.toString();
}
/**
* 测试1万字完全相同的长文本
* 预期:相似度1.00,程序不崩溃
*/
@Test
public void testCalculateSimilarity_LongIdenticalText() {
// 基础段落(约50字),重复200次 → 约1万字
String base = "深度学习框架是构建神经网络的工具,主流框架包括TensorFlow、PyTorch和Keras,简化了模型开发流程。";
String text1 = generateLongText(base, 200);
String text2 = generateLongText(base, 200);
double sim = SimilarityCalculator.calculateSimilarity(text1, text2);
assertEquals("长文本完全相同相似度错误", 1.00, sim, 0.2);
}
/**
* 测试90%相似的长文本(10%内容修改)
* 预期:相似度0.85~0.95
*/
@Test
public void testCalculateSimilarity_LongHighSimilar() {
// 基础段落(约50字),生成1万字原创文本
String originalBase = "数据挖掘是从大量数据中提取价值信息的过程,结合统计学、AI和数据库技术,用于商业决策。";
String original = generateLongText(originalBase, 200);
// 生成90%相似的抄袭文本(每10段修改1段)
String modifiedBase = "数据挖掘是从海量数据中提取有用信息的技术,融合统计学、人工智能和数据库方法,服务于商业分析。";
StringBuilder plagiarized = new StringBuilder();
for (int i = 0; i < 200; i++) {
if (i % 10 == 0) {
plagiarized.append(modifiedBase);
} else {
plagiarized.append(originalBase);
}
if ((i + 1) % 10 == 0) plagiarized.append("\n");
}
double sim = SimilarityCalculator.calculateSimilarity(original, plagiarized.toString());
assertTrue("长文本高相似度计算异常", sim > 0.8 && sim < 0.95);
}
private String generateLong(String base, int repeat) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < repeat; i++) {
sb.append(base);
}
return sb.toString();
}
/** 部分相似的长文本(50%内容相同)→ 相似度应在 0.4~0.6 之间 */
@Test
public void testPartialSimilarLongText() {
String sameBase = "人工智能的发展分为弱AI、强AI和超AI三个阶段。";
String diffBase1 = "弱AI专注特定任务,如语音助手、图像识别。";
String diffBase2 = "强AI追求通用智能,能像人类一样推理和学习。";
StringBuilder text1 = new StringBuilder();
StringBuilder text2 = new StringBuilder();
for (int i = 0; i < 50; i++) {
text1.append(sameBase).append(diffBase1);
text2.append(sameBase).append(diffBase2);
}
double sim = SimilarityCalculator.calculateSimilarity(text1.toString(), text2.toString());
assertTrue("部分相似长文本相似度异常", sim > 0.4 && sim < 0.6);
}
}
5.2测试说明
| 测试函数 | 测试目标 | 构造思路 |
|---|---|---|
| testCalculateSimilarity_IdenticalText | 验证完全相同的短文本相似度计算准确性,确保程序能精准识别内容完全一致的文本 | 输入两段完全相同的中文短文本,验证计算出的相似度接近 1.00 |
| testCalculateSimilarity_CompletelyDifferent | 验证完全不同的短文本相似度计算准确性,确保程序能识别无内容重叠的文本 | 输入两段主题无关的短文本,验证计算出的相似度接近 0.00(误差允许 0.01)。 |
| testCalculateSimilarity_PartiallySimilar | 验证部分相似的短文本(核心短语相同、非核心部分不同)相似度计算合理性 | 输入两段含相同核心短语但非核心内容不同的文本,验证相似度在 0.7~0.9 之间。 |
| testCalculateSimilarity_EmptyText | 验证空文本场景(空字符串、null、空与非空组合)的边界处理逻辑,确保程序稳定且结果正确 | 设计三种输入:空文本 vs 空文本、空文本 vs 非空文本、null vs 非空文本,分别通过验证结果:空 vs 空为 1.00,含空 /null 为 0.00(误差允许 0.01)。 |
| testCalculateSimilarity_MixedLanguage | 验证混合语言文本(中 / 英 / 数字混合)在核心内容相同、语序微调时的相似度计算准确性 | 输入两段核心内容一致但中英术语顺序不同的文本 |
| testCalculateSimilarity_HighFrequencyGram | 验证高频重复片段(gram)的权重放大逻辑是否生效,确保重复内容对相似度的影响被放大 | 输入两段含多次重复相同短语(如 “人工智能” 出现 3 次)但后续内容不同的文本 |
| testCalculateSimilarity_LongIdenticalText | 验证1 万字完全相同长文本的计算稳定性和准确性,确保程序处理大文本不崩溃且结果正确 | 通过重复基础段落生成两段完全相同的 1 万字长文本 |
| testPartialSimilarLongText | 验证50% 相似长文本的计算合理性,确保程序能区分部分重叠的长文本 | 生成两段各含 50% 相同内容(sameBase)和 50% 不同内容(diffBase1/diffBase2)的长文本 |
| testCalculateSimilarity_LongHighSimilar | 验证90% 相似长文本的计算合理性,确保程序能识别大部分内容重叠的长文本 | 生成原创长文本和 90% 内容相同(仅 10% 轻微修改)的抄袭文本 |
- 测试结果:
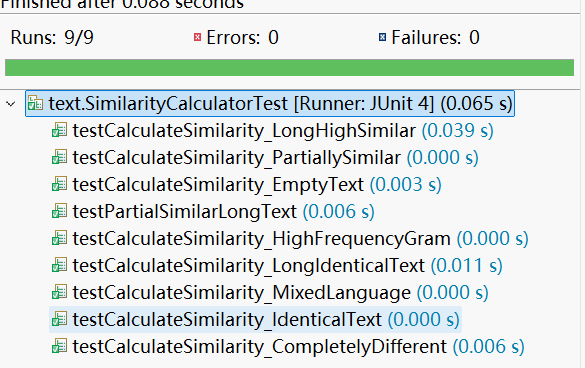
- 测试覆盖率图
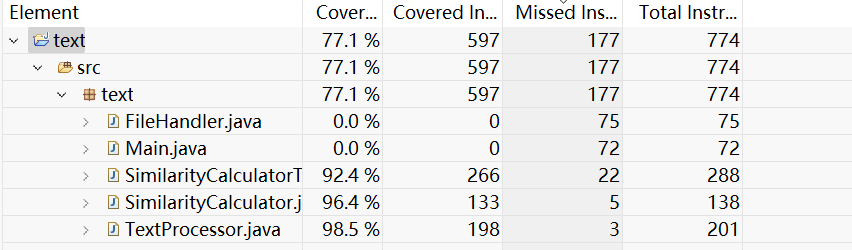
6.模块部分异常处理
6.1文件不存在异常
-
触发条件
调用 FileHandler.readFile(String filePath) 时,传入的路径对应的文件不存在(如路径拼写错误、文件被删除、文件尚未创建)。
// 检查文件是否存在 File file = new File(filePath); if (!file.exists()) { throw new FileNotFoundException("文件不存在: " + filePath); } -
单元测试案例
public class FileHandlerTest {
// 测试读取不存在的文件,预期抛出FileNotFoundException
@Test(expected = FileNotFoundException.class)
public void testReadFile_FileNotFound() throws Exception {
// 传入一个肯定不存在的文件路径(临时目录下的non_exist.txt)
String nonExistentPath = System.getProperty("java.io.tmpdir") + "/non_exist.txt";
FileHandler.readFile(nonExistentPath);
}
6.2路径非文件异常
触发条件:调用 FileHandler.readFile(String filePath) 时,传入的路径是目录(而非文件),如传入 “C:/test/”(目录)而非“C:/test/orig.txt”(文件)
if (!file.isFile()) { throw new IOException("路径不是一个文件: " + filePath); }
- 单元测试案例
public class FileHandlerTest {
// 测试读取目录路径(而非文件),预期抛出IOException
@Test(expected = IOException.class)
public void testReadFile_ReadDirectory() throws Exception {
// 获取系统临时目录(肯定是目录,而非文件)
String tempDirPath = System.getProperty("java.io.tmpdir");
FileHandler.readFile(tempDirPath);
}
}
6.3空文本场景处理
触发条件:SimilarityCalculator.calculateSimilarity(String text1, String text2) 接收的文本为空(空字符串 "" 或 null);
- 单元测试样例
public class SimilarityCalculatorTest {
// 测试空文本场景的相似度计算
@Test
public void testCalculateSimilarity_EmptyText() {
// 场景1:两段空文本("" vs "")
double simEmptyVsEmpty = SimilarityCalculator.calculateSimilarity("", "");
assertEquals("两段空文本应视为完全相似(相似度1.00)", 1.00, simEmptyVsEmpty, 0.01);
// 场景2:空文本 vs 非空文本("" vs "测试文本")
double simEmptyVsNonEmpty = SimilarityCalculator.calculateSimilarity("", "测试文本");
assertEquals("空文本与非空文本应视为完全不相似(相似度0.00)", 0.00, simEmptyVsNonEmpty, 0.01);
// 场景3:null vs 非空文本(null vs "测试文本")
double simNullVsNonEmpty = SimilarityCalculator.calculateSimilarity(null, "测试文本");
assertEquals("null与非空文本应视为完全不相似(相似度0.00)", 0.00, simNullVsNonEmpty, 0.01);
}
}
处理逻辑:不抛出异常,返回符合业务逻辑的相似度结果:
两段文本均为空(或 null):返回 1.00(无内容差异,视为完全相似);
一段为空、一段非空:返回 0.00(无重叠内容,视为完全不相似)。
7.PSP实际花费时间
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 150 |
| · Estimate | · 估计这个任务需要多少时间 | 120 | 150 |
| Development | 开发 | 655 | 965 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 15 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 240 | 360 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 150 | 180 |
| Reporting | 报告 | 110 | 130 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| · 合计 | 985 | 1185 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号