JVM学习笔记,理论知识,如有错误,欢迎指正!
垃圾的概念
指在程序运行中,创建出来的对象,在完成了一系列的逻辑后,这个对象已经不需要再使用了,但是java没有提供手动清理的方法,因为手动清理容易造成忘记回收,或者多次回收,所以java采用的是使用垃圾回收器,来对这个垃圾进行回收,释放空间。
怎么样判断一个对象是否为垃圾
在java代码编译为class文件后,称为B类,B类中会存在一个计数器,如果A类引用了B类,B类的计数器就会加1,就说明这个对象已经被引用了,不是垃圾了。但是,还有一种情况就是,A,B,C三个类 A类引用了B类,B类引用了C类,C类引用了A类,那么他们的计数器都各自为1,但是实际上又没有被真正的引用,这种叫做一堆垃圾(滑稽)。
所以,在判断一个对象是不是为垃圾有两种方法。
1.引用计数法:就是我们上面提到的。
2.根可达算法:即,从程序的根上来找,根对象引用的对象,肯定就不是垃圾,然后这个对象引用的子对象肯定也不是垃圾,一直找下去,然后没有被根对象或者子对象引用的,就全部算作是垃圾。
垃圾回收的常见算法概念
1。标记清除算法
在内存中将垃圾进行标记,然后等待垃圾回收的的时候一次性将垃圾都清除掉。弊端:容易造成空间碎片化。
2。copy(拷贝算法)
将一块内存划分成两块区域,每次只使用其中的一块区域,然后在进行垃圾回收的时候,将有引用的对象拷贝到另外一块没有使用的区域中去,然后将原本的那一块区域,整个都清空。弊端:对内存的要求会高一些,因为需要分两块。
3。标记压缩算法
第一种算法的变种,但是会在标记清除的时候压缩空间,将碎片空间进行压缩整理。弊端:耗费的资源和时间就相对较多。
部分垃圾回收器使用的内存模型
新生代+老年代 以及 永久代(JDK1.7)/ 元数据区(JDK1.8)
1.新生代:
新生代总共被分为三个区: Eden(伊甸区)+两个Suvivor(s0,s1)
Eden区:存储的是所有在程序中新创建的对象(这个过程还待学习),每个对象在一开始都会进入Eden区中,如果Eden区满了,装不下了,就会触发一次YGC(young GC),使用拷贝算法,清理Eden区和s0,将有引用的对象,都拷贝到s1区中,将Eden和s0清空,然后程序继续运行,指定触发下一次YGC的时候,清空Eden和s1,将有引用的对象拷贝到S0中。
2.老年代
存储大的对象以及在新生代中经给了一定GC次数的对象,即年龄大了的对象,假如没经过一次GC我们给这个对象的年龄+1,默认为15,cms默认为6,在对象的年龄足够后,就会进入老年代中。如果在程序中创建了一个大的对象,新生代装不下,那么这个对象也会直接进入老年代中。如果老年代也装不下了,就会触发一次FGC(Full GC),在老年代中进行一次
垃圾回收,这里为了避免碎片空间,所以使用的是标记压缩算法,但是同时也会造成资源的占用,而且,在使用部分的垃圾回收器的时候,还会造成STW(Stop the world)即,程序暂停了,然后垃圾回收器先把垃圾回收到,然后程序在继续运行。
这边还有一些记录的小知识点
1.永久代和元数据区,实际上都是存储class文件的位置,但是永久代是必须指定大小的,但是如果程序使用了动态代理等设计模式,可能会在永久代中创建很多的对象,严重的话可能会造成内存溢出。元数据区可以设置也可以不设置,大小完全受限制物理内存。
2.字符串常量等 在1.7中是存储在永久代中,1.8存储在堆中。
3.方法区是逻辑概念,跟class的存储是一样的。
4.永久代是受堆管理的,而元素区则是受操作系统管理。
5.老年代和新生代的比例是 2:1 即老年代占用内存的2/3 而新生代中,Eden区和suvivor区比例则是 8:1:1
部分垃圾回收器
Serial 新生代 串行回收
在触发了YGC后,会停止所有的用户线程,然后垃圾GC的线程启动,清空了所有的垃圾后,然后再继续执行用户线程。
Ps 新生代 并行回收
在触发了YGC后,会停止所有的用户线程,然后垃圾GC的多个线程启动,清空了所有的垃圾后,然后再继续执行用户线程。
ParNew 新生代 专门为了配合cms的并行回收所使用的新生代垃圾回收器
Serial Old 老年代垃圾回收器。算法跟新生代是一样的
Parallel Old 同上
CMS 老年代垃圾回收器 指在进行垃圾回收的时候,应用程序也可以继续执行 降低STW的时间(200ms) 并行GC 共4个阶段 初始标记 并发标记 重新标记 并发清理 在标记的时候会有漏标和错标 会产生浮动垃圾在老年代中产生碎片 错标的话会在第三阶段,重新标记。
缺点 内存碎片化 如果碎片化后来了一个大对象后,会 SO 串行清理压缩。
三色标记算法
CMS会在并发标记的时候,扫描每个对象 在这个时候会给每个对象打上黑灰白三个颜色的标记:
例如 一个对象A,A对象和A对象的直接引用都被扫描完了,这个A对象就会被标记会黑色, 而如果B对象被扫描完了,但是子对象C还没有被扫描完成 就会标记成灰色,然后在这个时候,假如这个B对象的子对象C在还没有在还没有标记完成的时候,就失去了引用,那这个C对象就变成了垃圾,就是白色 然后,已经被扫描完成的A突然又引用了C,就会造成错标
例如,一个对象在缓存中存储,被B对象取出,然后使用完成之后失去引用,然后A对象又再次取出,这时候就会造成这个线程,CMS为了解决了,就会有一个重新标记的阶段,在这一个阶段,会把所有的标记再重新检查一边,注意,这个时候是会造成STW的,但是因为已经标记过一次,本地会存在一次缓存,所以的话时间会短。
漏标的造成是因为,B对象有两个子对象,因为标记是并行线程来标记的,加入A线程扫描完了B对象的第一个引用,将B对象标记成了灰色,然后B对象这个时候失去了第一个引用 然后A线程继续扫描,之后就会把B对象设置为了灰色,然后第一个引用这个时候实际上是漏标了,不会清除掉。
CMS最大的问题就是,假如内存区域的碎片化太多了,那么如果这个时候进来了一个大的对象,放不下了,那么会使用SO来串行清理,这个时候如果内存区域很大的话,因为是串行,就会造成很长时间的STW。 漏标一般是不会处理的,等待下次的垃圾回收。
G1 也是使用的三色标记算法,但是为了解决错标的问题,G1在程序引用对象的时候,加入了一个屏障,如果一个对象A,在垃圾回收的时候,引用了一个对象B,此时如果对象A已经被标记为了黑色,那么A会重新被标记为灰色,并且,G1的内部还有一个队列,会将对象B加入队列中,在标记完成之后,进入第三个阶段的时候,会将队列中的对象再次取出,重新标记一边,
预防错标的情况发生。
下图,表示了一个对象,从开始创建,到被回收的流程
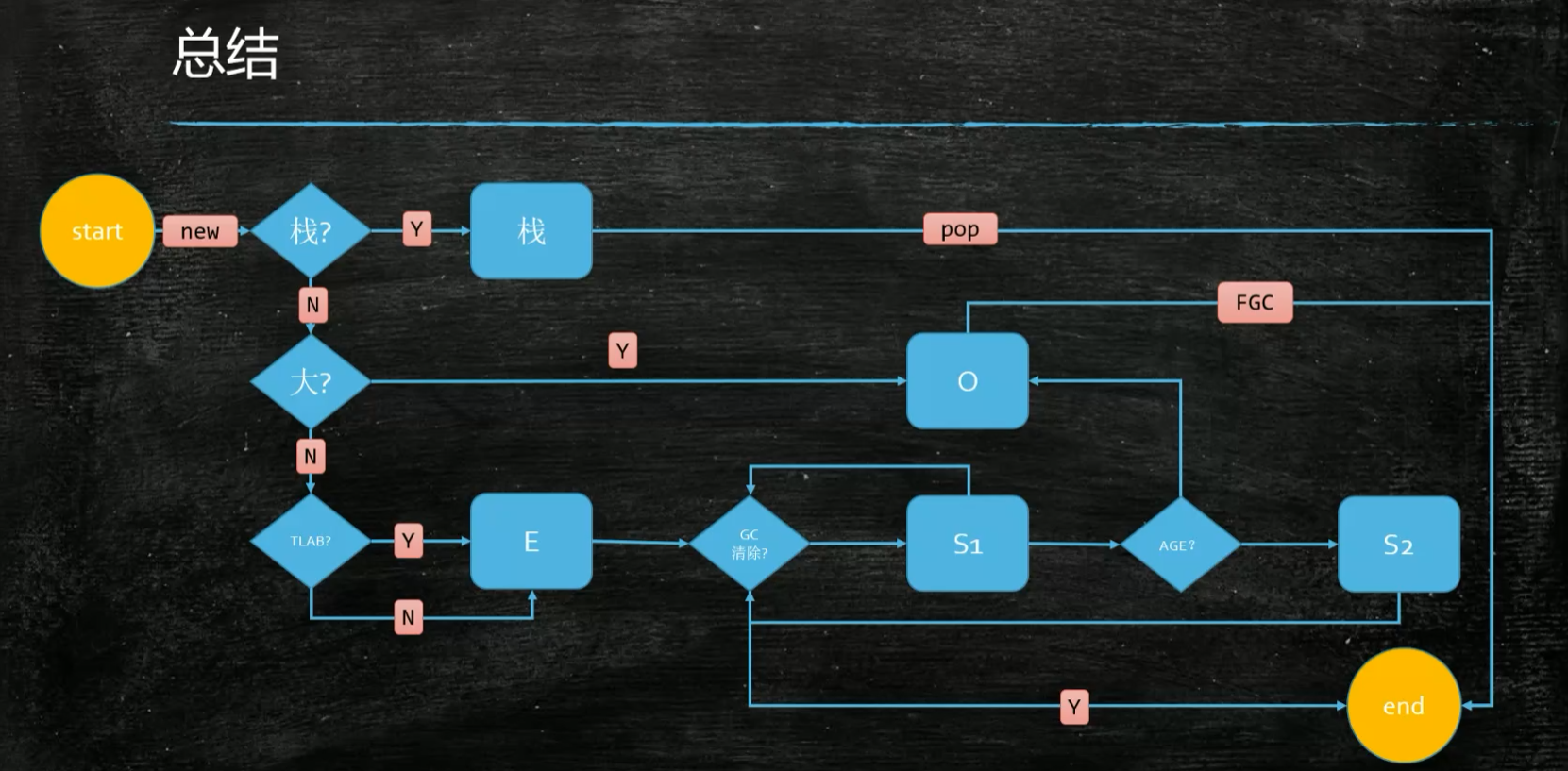
TLAB:代表的是,每个线程,在Eden区中,都会有属于自己的一小块内存,线程中创建对象,会预先在自己的这一小块内存中创建,如果创建不下,才会直接去Eden区中创建,因为,如果直接在Eden区中创建,还需要考虑到并发同步的问题。
总结:学习了GC的一点基础,已经垃圾回收算法的基本概念,在此做一个记录!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号