DBA MongoDB 设计模式
文档模型
JSON文档
MongoDB的集合是一种无模式的状态,没有字段,没有约束。
因此对于MongoDB的数据存储模型搭建来讲变的十分简单,需要什么字段就直接丢进去即可。
但是后期对于MongoDB集合的管理却变的较为复杂,相较于传统的关系型数据库,初次接触MongoDB的同学可能对这种结构的管理显得十分的懊恼。
例如,公司采用的文档结构可能刚开始没有email字段,并且该服务已经运行一阵,有了成百上千万条数据。
但是到了某一天领导发现需要加入email字段可能更好一点,此时存在的问题就是已经存储的集合文档中没有email字段,但后面新加入的文档就有了email字段,管理十分复杂。
在这里我不想再复述JSON的好处,它对于开发人员来讲十分的友好,但是对于运维人员来讲可能存在管理复杂的情况,所以学习如何设计、管理、优化MongoDB文档就十分的有必要了。
BSON存储
JSON文档是一个抽象的概念,本身是在JavaScript中以对象的方式存在。
但是我们后面发现许多的后台应用都需要与前端打交道,渐渐的JSON成为了一种标准,但是JSON也有很多缺点,这里不再赘述,在数据类型一章节中已有详细介绍。
那么BSON到底是什么,BSON是一种轻量的二进制格式,JSON则是直接存储在磁盘上的非二进制格式。
BSON对于JSON来讲有以下几点突破:
- 效率,BSON设计能更好表示数据,占用更少的空间,大多数时候,BSON要比JSON更加高效(传输、存储大数据)
- 可遍历性,BSON牺牲了空间效率,但是更容易遍历,如在字符串前面加入该字符串的长度,而不是在结尾处使用一个终结符,这对MongoDB的内嵌文档十分有用
- 性能,BSON的编码解码速度很快,由C的风格表现形式来表示类型,在大多数编程语言中都非常快
设计基础
设计误区
在关系型数据库中搭建数据模型的三要素为实体、属性、关系。
并且对于关系型数据库的数据模型三层深度来讲,具有概念模型、逻辑模型、物理模型等逐步细化的过程。
但是对于MongoDB来讲,集合的无状态性常常会让人陷入3个误区:
- 不需要模型设计,业务上有什么新的字段就直接丢进去
- 用一个超级大的文档来组织所有数据
- MongoDB不支持关联或者事务(4.x版本以完美支持事务了),所以某些关键性的应用场景不应该使用MongoDB
对于以上三点观念,均是错误的。
设计理念
JSON文档设计不需要遵从第三范式,从而允许冗余的发生。
因此,概念建模和逻辑建模之后,一般直接可以用于实际生产(不需要物理建模),这也是无模式的一种特点。
如下,在JSON文档数据模型中,我们并不需要细分需要多少张表、需要哪些字段,而是直接添加即可:
{
"name" : "Jack",
"gender" : "male",
"phones" : [
{"type" : "work", "number" : 653897},
{"type" : "home", "number" : 793812}
],
"hobby":["game", "music"],
"addr":[
{"type" : "work", "province" : "JiangSu", "city" : "NanJing"},
{"type" : "home", "province" : "ZheJiang", "city" : "HangZhou"}
]
}
这是我随意想出来的一种数据格式,如果是关系型数据库则需要大量的时间来进行表的划分,字段的约束等。
对于关系型数据库来讲,物理建模可能会花费较大的时间,并且在逻辑建模时也要充分的给予考虑,整体设计较为复杂。比如,对模型的关系来讲,关系型数据库会采用关联、主外键约束等,而对MongoDB来讲,则只需要内嵌数组或者引用字段即可。
MongoDB文档的设计原则必须遵循,性能与开发易用,关于易于管理这个点来说相较于关系型数据库并没有那么方便,但是也要做好设计。
设计实践
基础模型
整个模型建立可分为4个步骤:
-
根据业务需求推导出概念模型与逻辑模型。
-
列出实体关系。
-
决定内嵌方式,开始进行物理建模。
-
完成基础模型构建。
首先,我们以一个简单的需求来开始,要建立一个学生信息库,此时仅仅在概念模型上,我们有了一个思维,原来要建立一个学生信息库,那肯定是以学生为中心。
其次,我们需要对该需求进行细分,建立逻辑模型,比如学生是否应该有学号?班级?课程?教师?成绩?部门?以及它们的关系是什么,如:
-
学号与学生是一对一
-
成绩与学生是一对一
-
班级与学生是一对多
-
部门与学生是多对多
-
课程与学生是多对多
-
教师与学生是多对多
建立物理模型之前,首先要有3个大方向:
- 对于一对一关系来讲,使用内嵌文档或直接在顶层书写,不涉及数据冗余
- 对于一对多关系来讲,使用数组嵌文档,不涉及数据冗余
- 对于多对多关系来讲,使用数组嵌文档,使用冗余表达多对多关系
需要注意的是,如果内嵌过多,文档大小超过16MB的话是会写入不进去的,应该也在考虑范围中。
有了大的方向,开始建立物理模型:
{
# 基础信息
"studentName" : "Jack",
"studentAge" : 18,
"studentGender" : "male",
# 一对一(如果放在关系型数据库中,可能仅是逻辑一对一,不排除具有同分数的情况,对于MongoDB来讲不用考虑这一点)
"studentId": 33023,
"grades": {
"English" : 98,
"Mathematics" : 88,
"Language" : 92
},
# 一对多:对学生来讲,和班级的关系一般是学生仅有一个班级,而一个班级可以有多个学生
# 此时我们在学生方面使用内嵌文档即可,因为学生对班级是1。如果一个一对多关系学生是多的一方,则考虑使用
# 数组+内嵌文档
"class" : {
"name" : "Grade Three Class One",
"principal" : "teachLiu"
},
# 多对多
"department" : [
{"name" : "dep01"},
{"name" : "dep02"},
],
"course" : [
{"type" : "English", "teacher" : "teachWang"},
{"type" : "mathematics", "teacher" : "teachLi"},
{"type" : "Language", "teacher" : "teachZhang"},
]
}
# 在上述示例中并未建立与教师的任何直接关系
# 而是通过班级负责人、课程教师等信息与老师建立间接关系
模型引用
模型的改动要依照实际情况来决定。
对于上述模型来讲,一个文档中存储的数据量级较少,因此改动可能较少。
而对于其他业务的模型,如一个内嵌文档可能达到上百万级别的数据且变更比较频繁时,可以考虑将该内嵌文档使用单独的集合进行存放,使用模型引用的方式进行查询。
如,最开始的时候文档模型是这样的,这是一个网购公司对一年中订单的成交记录:
{
"years" : "xxxx年",
"totalSales" : 9392939,
"netProfit" : 6302938,
"orders" : [
{"orderId" : "xxxx-xxxx-xxxx-xxxx", "date" : "xxx", "price": 100},
{"orderId" : "xxxx-xxxx-xxxx-xxxx", "date" : "xxx", "price": 100},
{"orderId" : "xxxx-xxxx-xxxx-xxxx", "date" : "xxx", "price": 100},
]
}
一个文档中存放一年的记录,显然设计十分的不合理,如果订单量过多,则可能导致文档大小超过16MB的限制。
在这里给出的模型改动建议是将orders这个内嵌字段中数据作为一个新的集合存放,一个新的集合代表一年的订单记录,一个集合中最多有12个文档代表每月的订单记录。
# 订单年份表
--------------------------------------------------------------------------------
{
"years" : "2008年",
"totalSales" : 9392939,
"netProfit" : 6302938,
"orders_ids" : [1, 2, 3, 4, 5, 6] # 月份
}
--------------------------------------------------------------------------------
{
"years" : "2009年",
"totalSales" : 6345339,
"netProfit" : 3242938,
"orders_ids" : [1, 2, 3]
}
--------------------------------------------------------------------------------
# 新集合 某年订单月份表
--------------------------------------------------------------------------------
{
order_id : 1, # 1月份
orders : [
{"orderId" : "xxxx-xxxx-xxxx-xxxx", "date" : "xxx", "price": 100},
{"orderId" : "xxxx-xxxx-xxxx-xxxx", "date" : "xxx", "price": 100},
]
}
--------------------------------------------------------------------------------
{
order_id : 2, # 2月份
orders : [
{"orderId" : "xxxx-xxxx-xxxx-xxxx", "date" : "xxx", "price": 100},
{"orderId" : "xxxx-xxxx-xxxx-xxxx", "date" : "xxx", "price": 100},
]
}
--------------------------------------------------------------------------------
在查询时,我们可以使用聚合进行查询,利用$lookup进行多表关联查询:
db.年份表.aggregate({
{
$match : {
years : {$eq : "xxxx年"}
},
$lookup : {
from : "某年订单月份表",
localField : "orders_ids",
foreignField : "order_id",
as : "别名(用作内嵌文档显示)",
}
}
})
示例演示:
db.yearOrders.aggregate([
{
'$match': {
'years': {
'$eq': '2008年'
}
}
}, {
'$lookup': {
'from': 'year2008Orders',
'localField': 'orders_ids',
'foreignField': 'order_id',
'as': 'order'
}
}
])
查出的结果:
[ { _id: ObjectId("6050297b78923004692c9966"),
years: '2008年',
totalSales: 9392939,
netProfit: 6302938,
orders_ids: [ 1, 2, 3, 4, 5, 6 ],
order:
[ { _id: ObjectId("6050299778923004692c9967"),
order_id: 1,
orders:
[ { orderId: 'xxxx-xxxx-xxxx-xxxx', date: 'xxx', price: 100 },
{ orderId: 'xxxx-xxxx-xxxx-xxxx', date: 'xxx', price: 100 } ] },
{ _id: ObjectId("6050299e78923004692c9968"),
order_id: 2,
orders:
[ { orderId: 'xxxx-xxxx-xxxx-xxxx', date: 'xxx', price: 100 },
{ orderId: 'xxxx-xxxx-xxxx-xxxx', date: 'xxx', price: 100 } ] } ] } ]
设计模式
分桶设计
在某些特定的场景中,如数据点采集频繁,数据量多的业务设计文档时可采用分桶设计。
如下所示,这是一个监控,每分钟录入一条文档:
{
"name" : "xxxx监控",
"startTime" : "xxxx年xx月xx日xx时xx分xx秒",
"status" : {
"a1" : "xxx", # 不同的监控项
"b1" : "xxx",
"c1" : "xxx",
}
}
这样每分钟都会录入一些重复信息,如name,startTime等,这使得对索引的建立等都会占据很大的空间。
使用分桶设计,每个小时生成一个新的文档进行录入,期间不断在已有文档上插入数据:
{
"name" : "xxxx监控",
"startTime" : "xxxx年xx月xx日xx时xx分xx秒",
"status" : [
{"a1" : "xxx", "b1" : "xxx", "c1" : "xxx"}, # 代表一分钟的信息
{"a1" : "xxx", "b1" : "xxx", "c1" : "xxx"},
{"a1" : "xxx", "b1" : "xxx", "c1" : "xxx"},
...
]
}
列转行
列转行的设计通常应用在大文档,具有很多字段,且这些字段很多都要建立索引时使用。
我们以上面学生表的情况举例,为什么课程要这样设计:
"course" : [
{"type" : "English", "teacher" : "teachWang"},
{"type" : "mathematics", "teacher" : "teachLi"},
{"type" : "Language", "teacher" : "teachZhang"},
]
而不设计成这个样子呢?
"course" : {
"English" : "teachWang",
"mathematics" : "teachLi",
"Language" : "teachZhang",
}
这是因为第一种方案更加利于索引的管理,如果采用第二种方案建立索引时则需要向下面这样建立:
db.students.createIndex({"course.English" : 1})
db.students.createIndex({"course.mathematics" : 1})
db.students.createIndex({"course.Language" : 1})
如果后面有新的课程,则需要重复进行建立,而使用第一种方案你只需要这样建立索引即可:
db.students.createIndex({"course.type" : 1})
版本号
可能该开始的时候你的业务中没有email字段。
过了很久之后第二版时又上线了email字段。
如何进行管理呢?添加一个版本号字段即可,如下所示:
{
"name" : "Jack",
"age" : 18,
"gender" : "Male",
"phone" : 382734,
}
{
"name" : "Jack",
"age" : 18,
"gender" : "Male",
"phone" : 382734,
"email" : "xxxx@gmail.com",
"schema_version" : "2.0"
}
近似计算
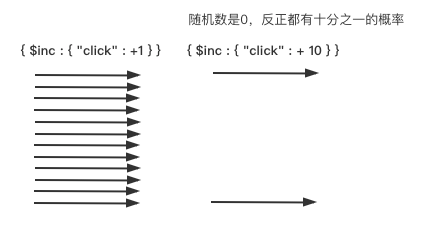
对于某些不需要准确性结果的统计操作,可以采用近似计算的方式进行解决。
如,网站点击频率,如果每一个用户点击一次都进行一次写入操作的话,无疑数据库压力会很大。
使用近似计算解决这个问题,生成随机数0-9,则有十分之一的概率随机数是0,如果随机数是0直接将点击量+10即可:
预聚合
如果要统计某个商品今天卖出去了多少,这个星期卖出去了多少等类似的场景,可以通过预聚合字段来解决频繁写入的问题:
{
"_id" : 1,
"柴" : 9239,
"米" : 8328,
"油" : 232,
"盐" : 3282
}
更新时:
db.collection.update(
{_id : 1},
{
$inc : {
"柴" : +1,
"米" : +1,
"油" : +1,
"盐" : +1
}
}
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号