DBA MySQL主从复制
主从介绍
当一个功能开发完成后,我们需要追求其极致性能,而对于性能影响较大的可能就是数据库的读写操作,因为对于MySQL数据库来讲数据是存储在磁盘上的,我们知道从磁盘上读取数据的I/O时间远远大于从内存中进行读取。
那么如何将MySQL的性能进行进一步提升就成了人们思考的问题。
随之而来的就是多集群解决方案,如读写分离等相关技术,当然这一切的前提都是主从复制。
可以说主从复制是高可用架构的一种基础技术,熟悉掌握主从复制后方能进行进一步高可用架构的学习。
说到底什么是主从复制呢?我们得从服务的全年无故障率开始说起,对于非计划任务内的故障停机时间,一年之中有以下3个标准:
- 99.9%可用时,一年内大概有525.6分钟处于停机状态,该级别属于比较优秀的企业全年无故障率
- 99.99%可用时,一年内大概有52.56分钟处于停机状态,该级别属于相当优秀的企业全年无故障率
- 99.999%可用时,一年内大概有5.256分钟处于停机状态,该级别属于金融类企业的全年无故障率
如何减少故障停机时间?这里有一个基础的方案就是采用2个MySQL服务,他们中数据相同,有一个发生故障后立马切换至另一服务,进行服务保障。
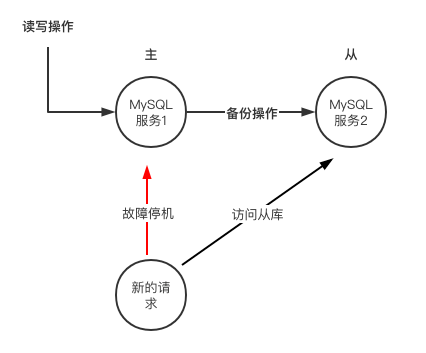
像这种同一时间只有一个MySQL实例处于服务状态的架构被称之为单活架构,在主库发生故障时切换至从库这样的操作是会花费一些时间的。
既然有单活架构,那么也有多活架构,如下就是一些比较常见的多活架构:
NDB Cluster
Oracle RAC
Sysbase cluster
InnoDB Cluster(MGR)
PXC
MGC
多活架构草图概述:
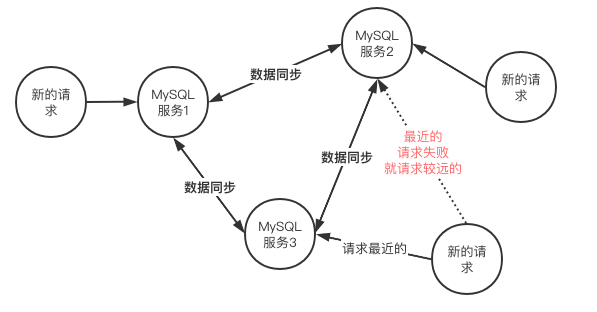
通过上面两张图发现,我们始终要保障多个MySQL服务之间的数据同步,因此主从的数据一致性是其关键技术点。
主从简介
以下是一些关于主从的简介:
- 主从复制其实是根据二进制日志进行复制的
- 主库的修改操作会记录二进制日志
- 从库会请求新的二进制日志,并将其进行回放操作(恢复),最终达到主从数据同步
- 主从复制的核心功能在于从库能够对主库进行辅助备份,处理物理损坏
- 主从复制是扩展新型高可用、高性能、分布式架构的前提
如何进行主从搭建?这里有一些搭建主从复制的前提条件:
- 两台或以上的MySQL实例,且server_id,server_uuid均不同
- 主库开启二进制日志
- 主库创建专用的用户,将来会由从库指定该用户为自己进行复制二进制日志记录的操作
- 从库必须保证和主库的数据是一致的
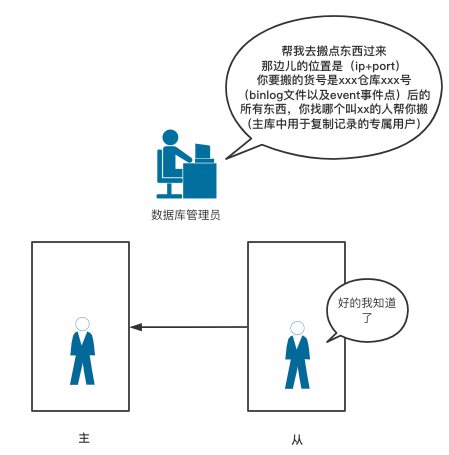
- 人为告诉从库一些必要信息,如主库的ip+port、负责复制主库记录给从库的专属用户、复制记录用户的用户密码、以及该用户从主库那个日志文件的那个事件号后开始复制
- 从库应该开启专门的复制线程
用一幅图来概述主从搭建的过程:
搭建多实例
点我跳转
注意,在上述操作完成后主库应当开启binlog记录,但是暂时先不开GTID模式(先搭建普通的event主从)。
从库不开binlog记录。
event主从搭建
主库操作
如果你的主库是新的,可以为主库录入一些数据:
T > mysql -uroot -S /tmp/mysql3307.sock
M > CREATE DATABASE db1 CHARSET utf8;
M > use db1;
M > CREATE TABLE t1(id INT) CHARSET utf8;
M > INSERT INTO t1 VALUES(1),(2),(3);
M > exit;
首先,主库要先创建一个用于复制的用户。
T > mysql -uroot -p -S /tmp/mysql3307.sock -e "grant replication slave on *.* to repl@'%' identified by '123'";
# 注意,如果是线上环境,请设置repl用户的允许登录地址
# repl用户的权限是仅用于复制操作
其次是我们需要对主库已有的信息就行一个全备份:
T > mysqldump -uroot -p -S /tmp/mysql3307.sock -A --master-data=2 --single-transaction -R -E --triggers > /tmp/full.sql
查看全备文件,记录主库当前在截止全备后的二进制日志记录文件以及记录event事件的位置::
T > vim /tmp/full.sql
# -- CHANGE MASTER TO MASTER_LOG_FILE='mysql_bin.000001', MASTER_LOG_POS=1040; !重要信息
从库操作
然后是登录从库进行导入全备文件:
T > mysql -uroot -S /tmp/mysql3308.sock
M > source /tmp/full.sql;
从库目前需要与主库进行链接,当主库发生任何操作后从库也一并执行操作,其实说白了就是监听主库二进制日志的变化,从库也做出相应的变化:
# 使用help change master to;获得帮助,帮助信息如下
# MASTER_HOST='master2.example.com', 主库的地址
# MASTER_USER='replication', 主库中用于复制的用户
# MASTER_PASSWORD='password', 主库中用于复制的用户的密码
# MASTER_PORT=3306, 主库的端口号
# MASTER_LOG_FILE='master2-bin.001', 从主库的那个二进制日志文件进行截取?
# MASTER_LOG_POS=4, 从主库的那个event事件开始截取?
# MASTER_CONNECT_RETRY=10; 如果从库断开与主库的链接,尝试重新链接的次数
# 直接输入下面一大坨命令
M > CHANGE MASTER TO MASTER_HOST='127.0.0.1',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql_bin.000001',
MASTER_LOG_POS=1040,
MASTER_CONNECT_RETRY=10;
在从库中开启复制二进制日志记录文件,复制完成后检查主从复制的状态:
# 从库进行复制主库二进制日志记录文件
M > START SLAVE;
# 检查复制状态,确保下面两个选项都是yes
M > SHOW SLAVE STATUS\G;
# Slave_IO_Running: Yes
# Slave_SQL_Running: Yes
主从验证
现在我们登陆主库,在主库中新创建一张表,查看从库是否有任何变化:
T > mysql -uroot -p -S /tmp/mysql3307.sock
M > use db1;
M > CREATE TABLE t2(id INT) CHARSET utf8;
M > INSERT INTO t2 VALUES(1),(2),(3);
登陆从库,查看从库中是否对应主库产生变化:
T > mysql -uroot -p -S /tmp/mysql3308.sock
M > use db1;
M > SHOW TABLES;
+---------------+
| Tables_in_db1 |
+---------------+
| t1 |
| t2 |
+---------------+
M > SELECT * FROM t2;
+------+
| id |
+------+
| 1 |
| 2 |
| 3 |
+------+
至此,基础的event主从搭建全部完成。
event主从流程
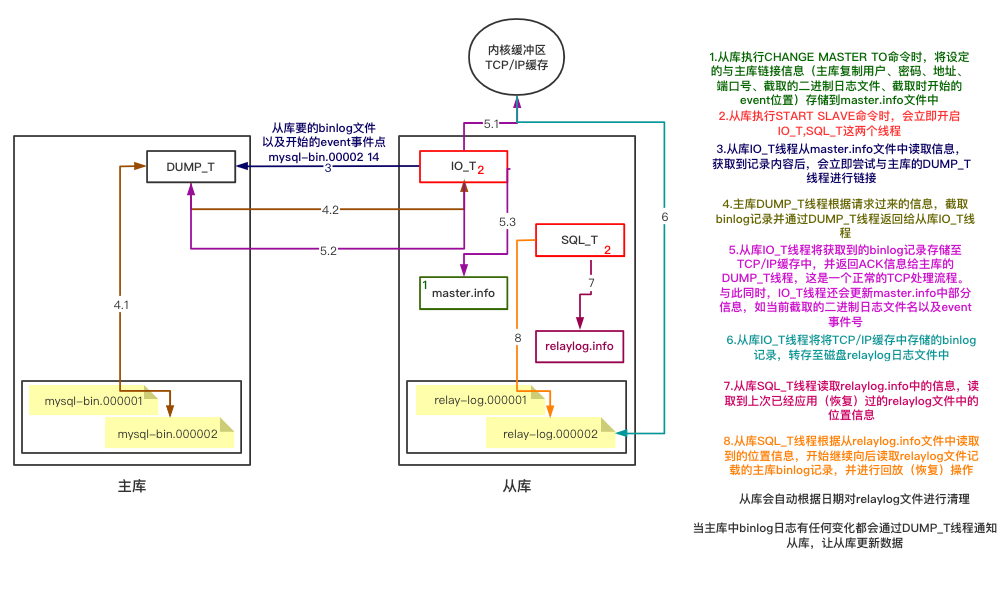
文件相关
在主从复制中,主库会用到的文件文件如下:
BINLOG : 二进制日志文件
在主从复制中,从库会用到的文件如下:
relaylog : 中继日志
master.info : 保存主库信息的文件
relaylog.info : 从库中级日志应用信息
# 在数据目录下存放
线程相关
在主从复制中,主库会用到如下的线程:
BINLOG_DUMP_THREAD : DUMP_T
# T = thread,线程
在主从复制中,从库会用到如下的线程:
SLAVE_IO_THREAD : IO_T
SLAVE_SQL_THREAD:: SQL_T
工作原理
工作原理如下图所示:
主从监控
监控命令
在主从环境中,我们要经常登录从库,检查主从是否稳定。
命令如下:
T > SHOW SLAVE STATUS\G;
监控信息
以下是主库相关的信息:
Master_Host: 127.0.0.1
Master_User: repl
Master_Port: 3307
Connect_Retry: 10
Master_Log_File: mysql_bin.000001
Read_Master_Log_Pos: 1474
# Master_Host:主库地址
# Master_User:主库负责向从库复制binlog记录的用户
# Master_Port:主库端口号
# Master_Log_File:主库当前正在使用的binlog文件
# Read_Master_Log_Pos: 从库已读主库的binlog记录位置,与主库SHOW MASTER STATUS做对比,如果一致说明主从性能很好
# 该信息存储在从库master.info文件中
以下是从库与relay-log相关的信息:
Relay_Log_File: centos-relay-bin.000002
Relay_Log_Pos: 754
Relay_Master_Log_File: mysql_bin.000001
# Relay_Log_File:从库正在使用的中继日志文件名
# Relay_Log_Pos:从库当前读取中继日志的信息
# 该信息存储在从库relay-log.info文件中
以下是从库执行的binlog位置信息:
Exec_Master_Log_Pos: 1735
# 该位置信息最好与Read_Master_Log_Pos相同
以下是从库线程的允许状态信息:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
# Slave_IO_Running:从库与主库的链接状态
# Slave_SQL_Running:从库SQL_T线程的执行状态
# ...ERROR:最近的一次报错
以下是过滤的主库binlog相关信息:
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
# Replicate_Do_DB:过滤库白名单,当前从库的SQL_T线程仅回放该名单库的binlog记录
# Replicate_Ignore_DB:过滤库黑名单,当前从库的SQL_T线程不回放该名单库的binlog记录
# Replicate_Do_Table:过滤表白名单
# Replicate_Do_Table:过滤表黑名单
# Replicate_Wild_Do_Table:模糊的表名白名单,如以t开头..
# Replicate_Wild_Ignore_Table: 模糊的表名黑名单,如以t开头..
以下是主从的非人为延时状态,说明性能有问题:
Seconds_Behind_Master: 0
# 大概估算主从复制时的同步时间差
以下是主从的人为延迟状态信息:
SQL_Delay: 0
SQL_Remaining_Delay: NULL
# SQL_Delay:人为设定的延迟从库设定秒数
# SQL_Remaining_Delay:当前还剩多长时间回放下一个relay-log记录
以下是GTID主从复制有关的状态:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
# Retrieved_Gtid_Set: 以获取到的主库binlog中GTID信息
# Executed_Gtid_Set: 当前从库已执行的GTID事务号
# Auto_Position: 是否开启自动位置确认
event主从问题
链接问题
从库链接主库链接不上,可以从以下两个方面入手解决。
- 检查主库的用户名、密码是否设置正确,是否存在允许登录地址设置有误,比如允许从所有地址登录符号为%而你填了个*
- 检查主库的链接线程是否过多?在主库中输入SHOW PROCESSLIST;进行查看
- 主库是否打开了禁止域名解析的设置--skip-name-resolve,或者是否打开了禁止远程登录的设置--skip-networking
- 检查从库的请求链接的主库是否输入有误,如主库负责复制binlog的用户密码是否输入错误等
如果是从库的链接信息填写错误,则可以重新进行填写:
# 停止从库复制行为
M > STOP SLAVE;
# 重置复制信息
M > RESET SLAVE ALL;
# 重新设置链接信息
M > CHANGE MASTER TO ...;
# 重新开始从库复制行为
M > START SLAVE;
如果是主库方面的原因,比如链接线程太多导致的,那么我们可以加大主库的链接线程数:
M > SET GLOBAL MAX_CONNECTIONS=300;
复制问题
如果主库进行了RESET MASTER;命令,从库的SLAVE信息和主库的binlog信息就对不上了。
如果很不幸的发生了这种问题,建议换个DBA,或者重新搭建主从。
主库的日志清理,只能使用定期清理。
SQL_T线程
由于SQL_T线程会去读取中继日志信息,从中继日志中读取复制的主库binlog记录,所以一旦中继日志relay-log文件发生丢失,就必然会导致从库的SQL_T线程出现问题。
对于中继日志被人为删除的解决办法只有重新搭建主从。
还有可能出现的问题是主库的数据在从库上已经存在,可能由于唯一性约束等原因导致SQL_T线程无法回放relay-log记录。
对于这种问题最好的解决办法就是禁止从库写入。
除此之外还有2个解决方案:
# 1.从库下执行
M > STOP SLAVE;
M > SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1;
# 将同步指针向下移动一个,如果多次不同步,可以重复操作。
# 举例:如果主库的binlog是为uniqe字段插入数据,但正好从库已有数据发生冲突,可执行该命令进行跳过
# 2.从库中配置文件设置
[mysqld]
slave-skip-errors = 1032,1062,1007
# 从库忽略以上错误
1007:对象已存在
1032:无法执行DML
1062:主键冲突,或约束冲突
一句话,构建主从必须保证数据一致性,数据一致性最为重要,其次是数据同步性。
所以禁止从库写入是最好的解决方案:
# 将下列选项在从库配置文件或global级别设置为on
T > SHOW VARIABLES LIKE "%READ_ONLY%"";
# 缺点,不能限制root用户
延时问题
如果你没有做延时方面的操作,但是就是出现了主从延时,则可以从以下几个原因入手:
-
主库的
binlog刷写策略有误:# 检查设置为1 M > SELECT @@sync_binlog; -
主库可能存在大量的写入操作,导致
binlog_dump线程忙不过来。# 主库的数据可以同时被多个线程操控进行并行处理 # 但是event主从中,主库DUMP线程只有一个,为了保证binlog传输时顺序不会乱所以是串行传输 # 搭建GTID的主从,可以将DUMP线程变更为并行传输 -
从库中
SQL_T线程只有一个,但是主库可能传输太多的记录SQL_T线程忙不过来# 搭建GTID的主从,就可以开启多个SQL_T线程 # 大事务拆成小事务,加快SQL_T线程的回放过程
判断到底是主库还是从库的问题导致延迟:
# 第一步,使用监控命令,查看延迟时间:Seconds_Behind_Master
M > SHOW SLAVE STATUS\G;
# 第二步,查看主库的MASTER的Position是否与从库的Read_Master_Log_Pos信息是否一致
# 如果一致,则没有延迟问题
# 如果主库大,从库小,接着往下看
M7 > SHOW MASTER STATUS;
M8 > SHOW SLAVE STATUS\G;
# 查看从库的Exec_Master_Log_Pos与从库的Read_Master_Log_Pos是否一致
# 如果一致,则没有延迟问题
# 如果Read_Master_Log_Pos大,则从库SQL_T线程有问题,查看是否有锁相关的语句或者大事务
M > SHOW MASTER STATUS;
延时从库
功能概述
延时从库是人为定制的一种策略,从库作为主库的备份方案。
当主库发生异常时,在延迟时间内登录从库阻止即将到来的异常操作执行。
举个例子,主库DROP DATABASE操作成功后,如果从库不做延时策略,则立马也会执行该操作,所以我们需要设定延时从库。
配置工作
在从库的基础配置完成后,再填入以下配置项,一般设置3-6小时,单位为秒数:
M > STOP SLAVE;
M > CHANGE MASTER TO MASTER_DELAY = 300;
M > START SLAVE;
M > SHOW SLAVE STATUS\G;
或者你也可以在直接搭建主从时填入以下配置:
M > CHANGE MASTER TO
MASTER_HOST='master2.example.com',
MASTER_USER='replication',
MASTER_PASSWORD='password',
MASTER_PORT=3306,
MASTER_LOG_FILE='master2-bin.001',
MASTER_LOG_POS=4,
MASTER_CONNECT_RETRY=10.
MASTER_DELAY = 300;
延迟检查
执行以下命令查看配置项,可进行延迟检查:
M > SHOW SLAVE STATUS\G;
# SQL_Delay:人为设定的延迟从库设定秒数
# SQL_Remaining_Delay:当前还剩多长时间回放下一个relay-log记录
恢复思路
当主库发生误操作后,从库如果开了延迟,则可以在延迟时间内登录从库进行以下操作:
第一步,主库已经发生误操作了,登录从库停止SQL_T线程的回放工作:
M > STOP SLAVE sql_thread;
第二步,打开监控命令,查看从库目前使用的中继日志信息:
M > SHOW SLAVE STATUS\G;
# Relay_Log_File:从库正在使用的中继日志文件名
# Relay_Log_Pos:从库当前读取中继日志的信息(作为截取起点使用),如event号为996
第三步,使用event工具,查看从库中继日志记录,找到误操作的事件号并进行记录:
M > SHOW RELAYLOG EVENTS IN 'centos-relay-bin.000002';
# 注意,查看中继日志与查看二进制日志不同。
# 中继日志只看左边的信息,event开始点和结束点都在左边的Pos中
# 右边的End_log_pos是binlog的记录,不用管也不用看
# 假设误操作的事件号开始为1123
第四步,使用mysqlbinlog工具对relay-log进行截取,生成SQL文件。
T > mysqlbinlog --start-position=996 --stop-position=1123 数据目录/centos-relay-bin.000002.log > /tmp/relay.sql
第五步,从库进行恢复:
M > source /tmp/relay.sql
第六步,将从库解除复制身份,令其设置为主库,进行全备,将原本的主库设置为从库,清除所有数据,操作步骤参见主从搭建:
# 从库操作
# 1. 停止从库复制行为,解除复制身份
M > STOP SLAVE;
M > RESET SLAVE ALL;
# 2.创建复制用户
# 3.进行全备
# 主库操作
# 1.删除所有原本的数据
# 2.导入全备文件
# 3.CHANGE MASTER TO命令,设为从库
# 4.执行START SLAVE,开始复制。
过滤复制
功能概述
在一些高可用架构中,我们常常会对一些数据量级比较大的数据库进行单独构建从库。
如下图所示:
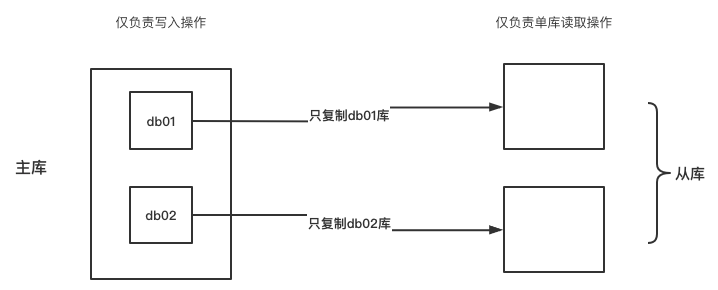
这样的好处就是对于主库来说的压力会大大减少。
实现方案
实现方案有两种,第一种是在主库上对binlog进行记录时只记录某个库,当然这种实现方案很少会被应用到:
M > SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql_bin.000001 | 1735 | | | |
+------------------+----------+--------------+------------------+-------------------+
# Binlog_Do_DB:binlog日志白名单,只针对某个库进行记录
# Binlog_Ignore_DB:binlog日志黑名单,只针对某个库不进行记录
第二种方案以从库为核心做配置,当SQL_T线程执行回放操作时,仅针对某个库的binlog记录进行回放:
M > SHOW SLAVE STATUS\G;
# Replicate_Do_DB:过滤库白名单,当前从库的SQL_T线程仅回放该名单库的binlog记录
# Replicate_Ignore_DB:过滤库黑名单,当前从库的SQL_T线程不回放该名单库的binlog记录
只需要在从库的my.cnf中配置如下选项即可:
[mysqld]
replicate_db_db=db01
replicate_ignore_db=db02
监控信息
主要在从库上监控以下信息:
M > SHOW SLAVE STATUS\G;
# Replicate_Do_DB:过滤库白名单,当前从库的SQL_T线程仅回放该名单库的binlog记录
# Replicate_Ignore_DB:过滤库黑名单,当前从库的SQL_T线程不回放该名单库的binlog记录
# Replicate_Do_Table:过滤表白名单
# Replicate_Do_Table:过滤表黑名单
# Replicate_Wild_Do_Table:模糊的表名白名单,如以t开头..
# Replicate_Wild_Ignore_Table: 模糊的表名黑名单,如以t开头..
半同步复制
功能概述
如果不开启半同步复制则从库IO_T线程从主库DUMP线程获取到binlog记录后将binlog记录刷新至中继日志relay-log中,主库此时并不关心从库SQL_T线程是否会执行回放操作。
如果开启半同步复制,则主库会开一个ACK_receiver线程,当从库将binlog记录刷新至中继日志relay-log后,会向主库发送一次ACK确认请求,告诉主库我已经同步了,此时主库才会继续交由DUMP线程通知从库IO_T线程有新的binlog记录,你来取。
如下图所示:
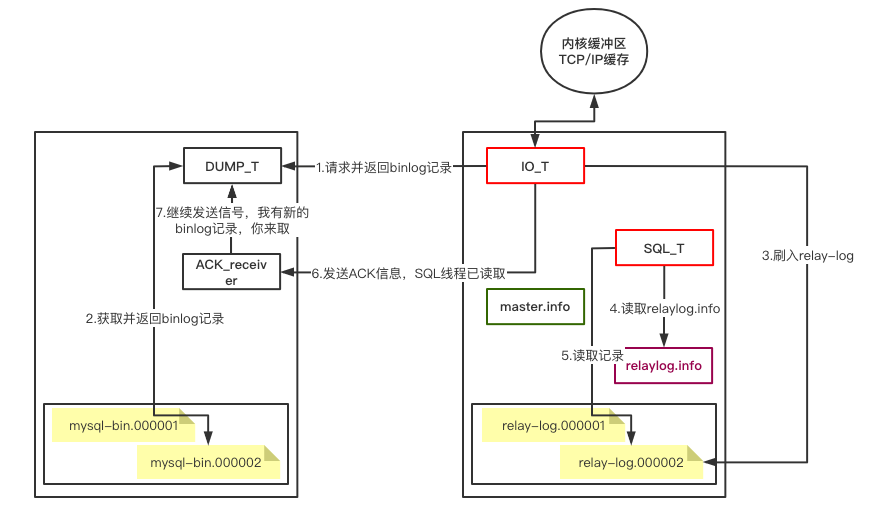
由于半同步复制会将主库的DUMP_T线程通知从库IO_T的工作变成同步状态,所以性能下降比较严重。
一般企业里很少使用,仅做了解即可。
实现方案
第一步,主库加载插件:
M > INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
第二步,从库加载插件:
M > INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
第三步,主从库查看插件是否加载成功:
M > SHOW plugins;
第四步,主库启动半复制,开启ACK_receiver线程:
M > SET GLOBAL rpl_semi_sync_master_enabled = 1;
第五步,从库启动半复制,控制SQL_T线程读取完relay-log后交由IO_T线程发送ACK信息:
M > SET GLOBAL rpl_semi_sync_slave_enabled = 1;
第六步,重启从库上的IO_T线程:
M > STOP SLAVE io_thread;
M > START SLAVE io_thread;
第七步,检查主从库的配置项是否成功:
# 主库
M > SHOW STATUS LIKE 'Rpl_semi_sync_master_status';
# 从库
M > SHOW STATUS LIKE 'Rpl_semi_sync_slave_status';
GTID主从
功能概述
在当今的企业主从复制中,GTID主从必须开启。
一是为了能够保障DMUP线程与IO_T线程中的binlog传输能够支持并行传输。
二是为了能够让从库的SQL_T线程开启多个,进行并行回放。
三是为了简略从库搭建主从时的步骤。
搭建核心
在使用GTID搭建主从时,需要注意在主库与从库的配置文件中加入以下配置项。
当然你也可以选择仅在主库下加入配置项,对于在从库中加入配置项是为了后续的数据恢复主从关系互换更加方便:
# 主库
[mysqld]
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
# 从库
[mysqld]
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
# gtid-mode:打开GTID模式
# enforce-gtid-consistency: GTID幂等性约束配置
# log-slave-updates:slave更新是否记入binlog日志,方便数据恢复后从库进行全备,切换主从身份
在进行mysqldump全备份主库时,需要注意备份语句中不要添加以下参数:
# --set-gtid-purged=off
# 当关闭时,全备文件中不会生成GTID号,使用GTID搭建主从复制就会失败
# 使用默认项auto即可,默认即使开启,则会生成GTID。
注意,在搭建主从时,从库CHANGE MASTER TO的设置也会发生变化,使用如下语句进行配置:
M > CHANGE MASTER TO MASTER_HOST='127.0.0.1',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_CONNECT_RETRY=10;
MASTER_AUTO_POSITION=1;
# MASTER_AUTO_POSITION=1 参数详解
# 如果是mysqldump的主库全备恢复,那么在全备的SQL文件中会存在已截取的GTID事务号
# MASTER_AUTO_POSITION=1实际上是让从库从主库GTID事务号1后开始截取,如果是mysqldump进行逻辑备份恢复
# 则会自动将该参数调整为全备SQL文件中的GTID事务号+1
# 那么如果是XBK物理备份怎么填写该参数呢?你需要在xtrabackup_binlog_info文件中,读取出已截取的GTID事务号
# 填写时+1即可。
# 总结!mysqldump逻辑备份恢复,该参数填1,内部会自动进行校正
# XBK物理备份恢复,检查xtrabackup_binlog_info文件,该参数在GTID事务号基础上+1
模式区别
相比于传统的event主从复制,GTID主从复制有大致以下的区别:
-
在主从复制环境中,主库发生过的事务,在全局都是由唯一
GTID记录的,更方便Failover -
在复制过程中,从库不再依赖
master.info文件,而是直接读取最后一个relay-log的GTID号 -
在复制时,从库如果恢复了主库的
mysqldump全备文件,会自动调整下一次使用SLAVE复制开始的GTID事务号,更加智能了,仅限于主库的全备是mysqldump备份
监控信息
主要在从库上监控以下信息:
M > SHOW SLAVE STATUS\G;
# Retrieved_Gtid_Set: 以获取到的主库binlog中GTID信息
# Executed_Gtid_Set: 当前从库已执行的GTID事务号
# Auto_Position: 是否开启自动位置确认

 浙公网安备 33010602011771号
浙公网安备 33010602011771号