basis 字符编码
字符编码的作用
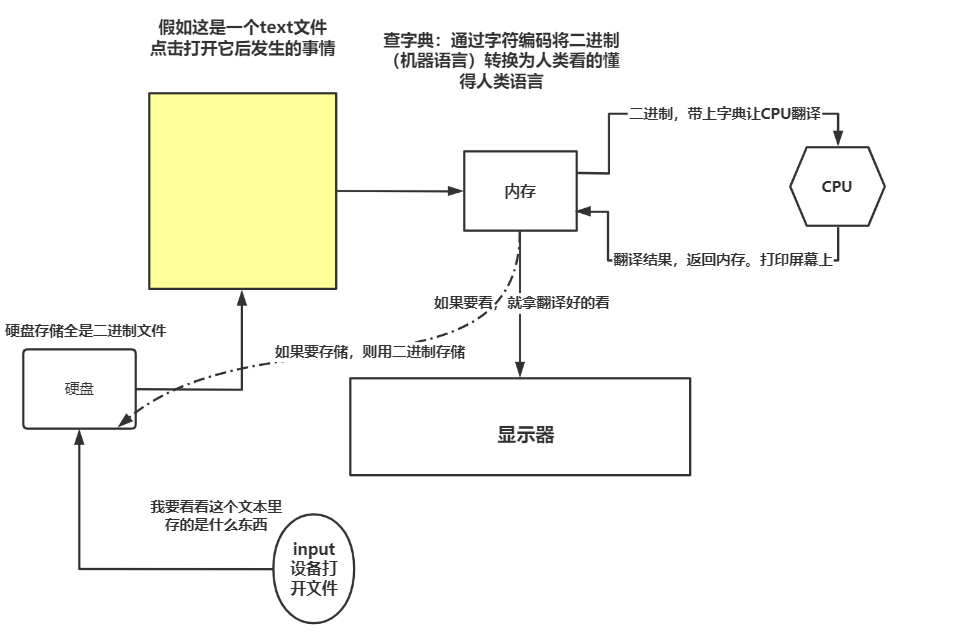
我们都知道,计算机内部是由二进制组成。我们人类如果想要与计算机进行交流和沟通,就必须有一个将人类语言翻译为计算机语言的过程。那么字符编码就可以认为是像一本词典一样,它详细的记载了人类语言与计算机语言之间的关系,当人类将人类语言作为指令或者数据交给计算机时(如修改文本文件内容,修改好的内容就是一组二进制数据),计算机就会通过字符编码(可以理解为查字典)将人类语言转换为计算机语言,然后计算机进行一系列的处理后再通过字符编码将计算机语言转换为人类语言交予输出设备供人类查看。
字符编码发展史
ASCII码表的出现
由于计算机是西方世界发明。所以第一本人类与计算机之间沟通的翻译词典则只会记载英文与计算机语言之间的关系,它叫做ASCII码表。用一串二进制来表示一个字符,如大写字母A代表的二进制是:'0b1000001'(十进制65),而小写字母a代表的二进制是'0b1100001'(十进制97)。它一共有8位二进制数组成,实际上7位即可表示全部的英文了。但是为了后期的拓展做准备,还是规定了8位一组。事实证明8位一组是明智的选择,后来ASCII码表这本词典中陆陆续续的还加入了很多其他的字符。
在ASCII码表中,一个字符占用1Bytes(8bit)的空间

其他编码的出现
随着计算机的不断发展,越来越多的国家也开始使用计算机。但是不好意思,计算机语言与人类语言的翻译词典只有一本ASCII码表。也就是说人类语言中只有英语或者ASCII码表中记载的符号才能被计算机认识,其他的语言一律不行。
为了解决这种办法,陆陆续续的又出现了其他的字符编码表。
- 日本的
Shift-JIS表 - 韩国的
Euc-kr表 - 中国的
GBK表 - ...
这些表都有一个共同的特点。他们除了融合了ASCII表中的所有人类语言与计算机语言之间的关系外,还包含了本国语言与计算机语言之间的关系。唯一不同的是占用字符空间不一样。这里拿GBK来举例:在GBK中,一个英文或字符占用1Bytes(8bit),而一个中文字符则占用2Bytes(16bit)
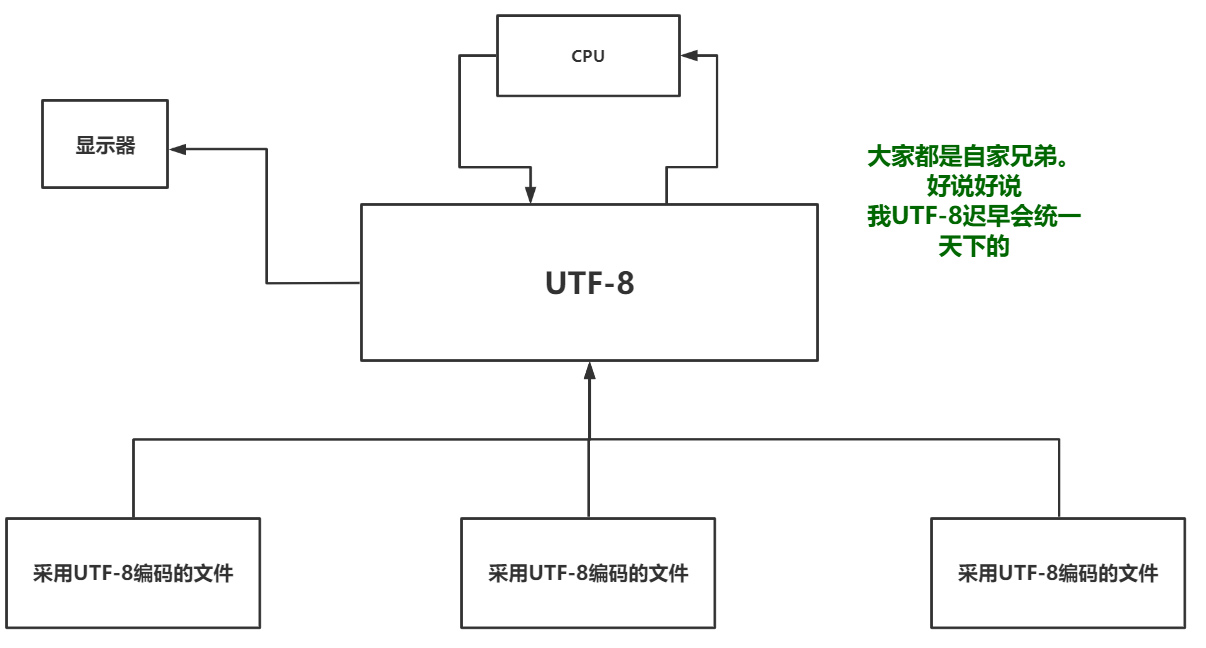
这样看似很和谐,实际上有一个致命的问题。看下图:
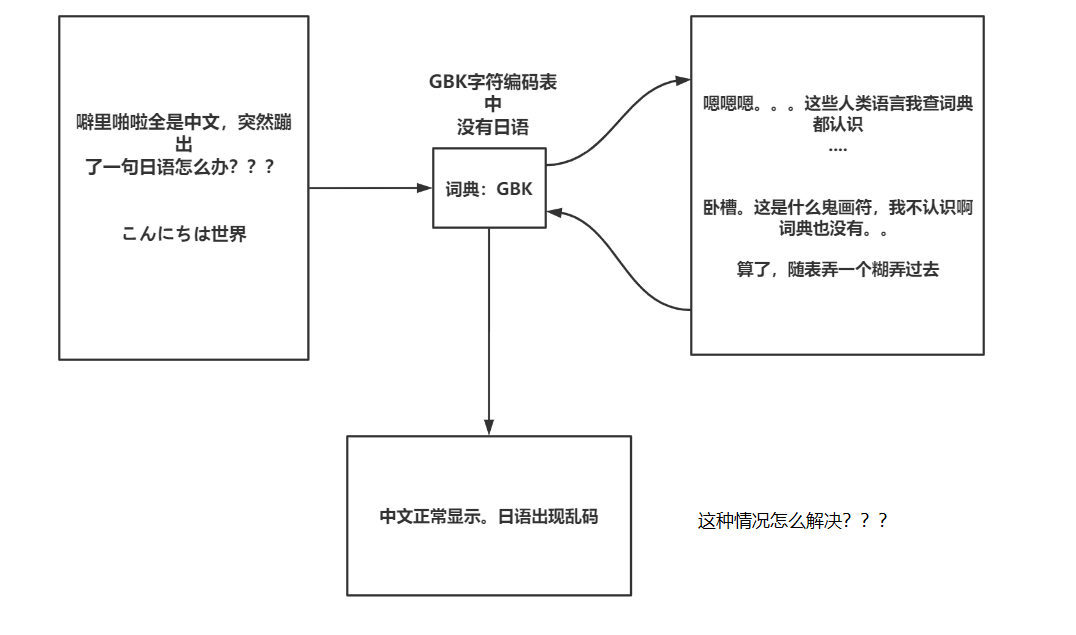
Unicode编码出现
随着世界经济统一化,地球已经变为地球村。谁也不想打开一个日本动作片网站一看全是什么都不认识的乱码吧?为了解决这个问题,1990年研发的Unicode编码产生了至关重要的作用(1990年研发,1994年正式投入使用)。Unicode编码融合了所有人类语言与计算机语言之间的关系。现在计算机内存中带的那本翻译词典也都是Unicode编码表。
有了它,麻麻再也不用担心打开动作片网站不认识标题了。

在Unicode中,中文或者英文字符统一都占用2Bytes的空间(16bit),这一点尤其重要。直接催促了UTF-8的现世。
UTF-8编码出现
哈,看到这里肯定有人疑问。Unicode这么屌,为什么不用他直接进行存储呢?还用什么GBK和什么Shift-JIS啊?别急,我们先看看GBK的内存占用空间。GBK中文2字节,英文1字节。如果用Unicode进行存储那么英文也是2字节,使用者噼里啪啦全部都写了好多英文。那占用空间就多了很多,占用空间一多当点击保存的时候必然硬盘的工作量更大了,硬盘工作量大导致I/O延迟致使整个程序的运行速度就慢了下来。所以,我们不用Unicode进行存储,为了解决这种办法。出现了UTF-8 (全称Unicode Transformation Format,即Unicode的转换格式)。被称为:可变长的字符编码
UTF-8英文字符占1Bytes(8bit),中文占3Bytes(24bit),生僻字则也可能使用4Bytes进行存储(32bit)。看起来占用空间更多了是吗?错了,其实占用空间相比于Unicode少了很多。因为在世界范围上来说,英文的资料比中文的资料多得多。
那么,既然这样的话为什么内存中不使用UTF-8来做翻译词典呢?为什么还要用Unicode做翻译词典?这个原因很简单。Unicode包含于其他字符编码之间的关系,而UTF-8则不包含这个关系,所以在如今GBK或者Shift-JIS依旧存在的情况下(此外还有很多字符编码)。使用Unicode作为翻译词典会更好。
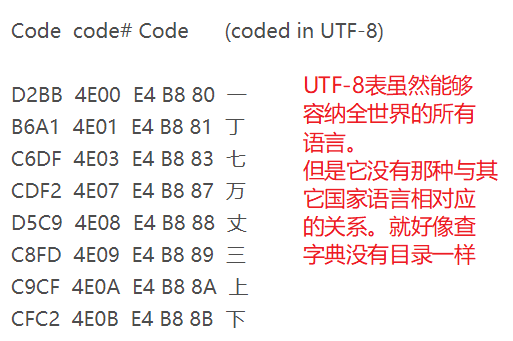

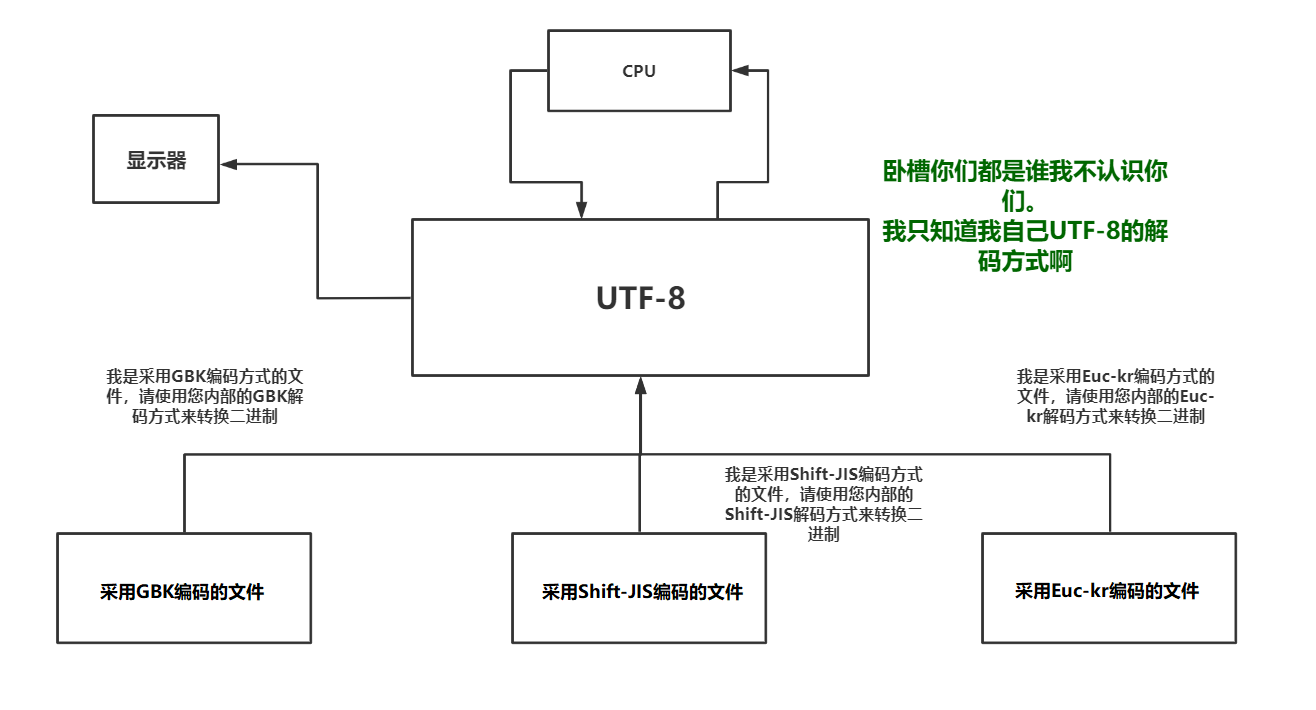
字符编码发展趋势
UTF-8对比Unicode唯一的缺点就是没有与其他字符编码之间的对应关系。其实这个缺点也不叫缺点。随着时间的推移以及越来越多的人使用UTF-8编码格式进行存储文件那么全世界共同使用同一套标准的话内存中就可以使用UTF-8来做这人类语言与机器语言之间翻译的桥梁了。如图所示:
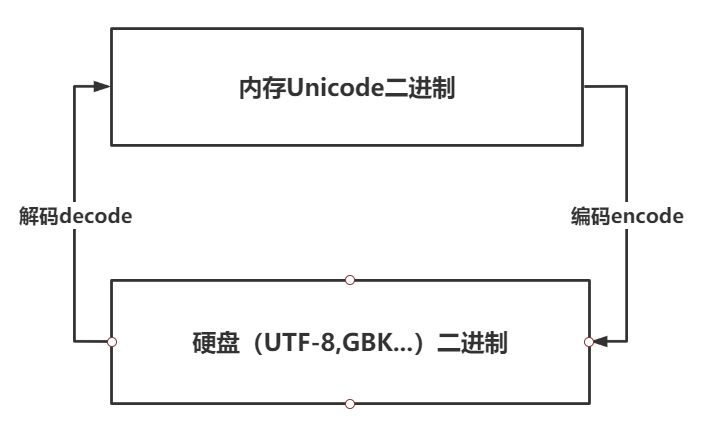
如何理解编码与解码
解码decode与编码encode图示:
在写入文件时,采用什么方式进行编码,在读取文件时,采用什么方式进行解码?
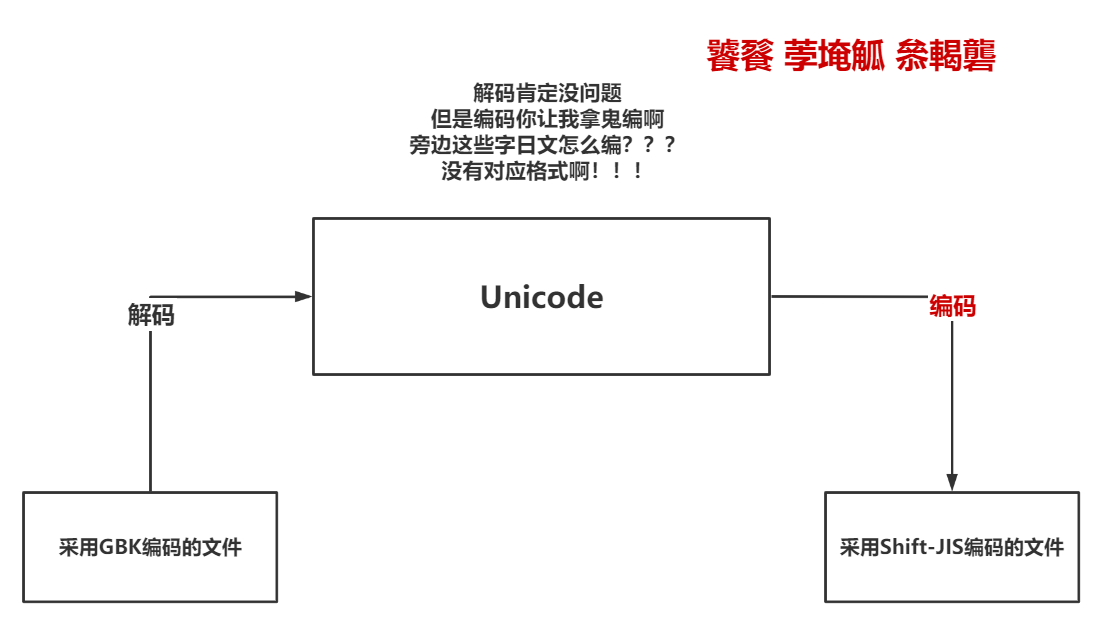
Unicode不支持跨编码互转
很多新手朋友都有一个猜想。认为不同的编码都可以通过Unicode互相转换,其实这么做是不可能的。我们看一下图示
其他编码转Unicode的底层实现
这一节我想了很久要不要写。因为涉及到的东西太过底层了,所以也是郁闷了挺久。还是写写吧,感兴趣的朋友可以看一下,不感兴趣的朋友可以不看。
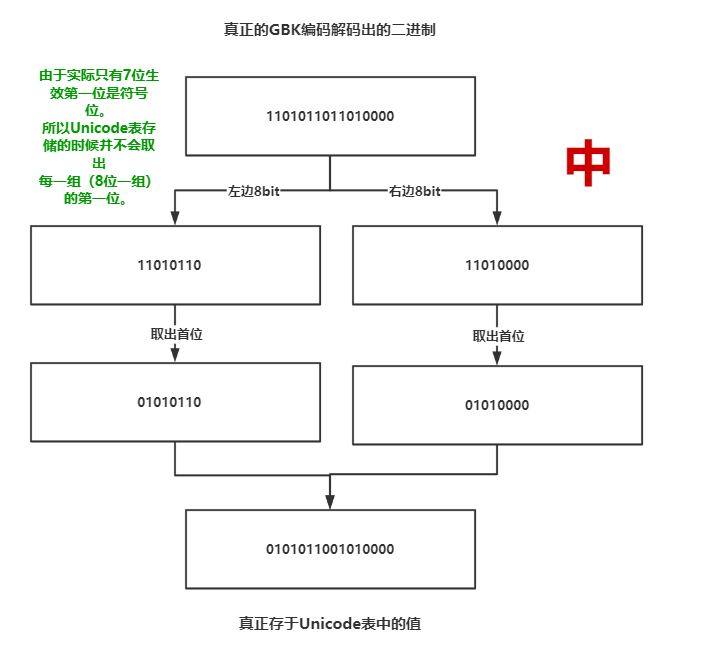
首先看一下中在Unicode中与GBK编码的关系

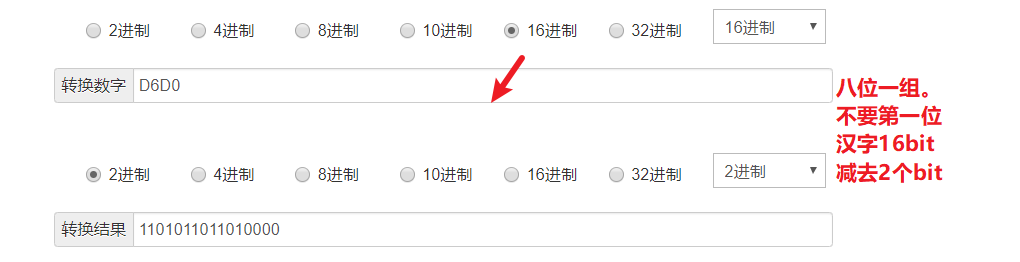
我们尝试写一个脚本,使用Python2来测试它的GBK编码是不是真的如同图上一样。
# coding:gbk
x = "中"
print([x]) # ['\xd6\xd0'] python2中列表元素会打印编码,python3则是直接打印字符
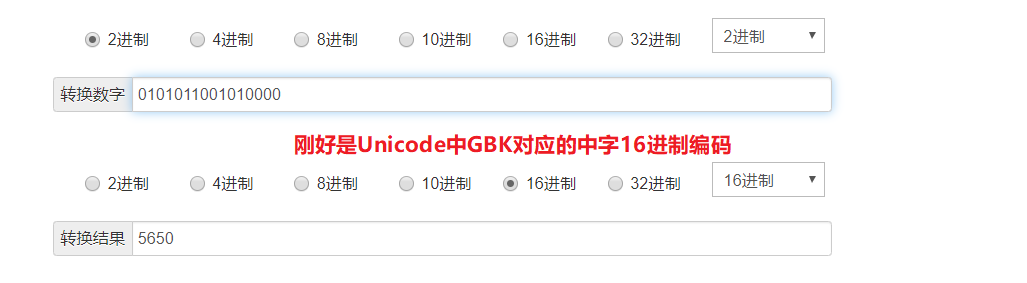
可以看到这里居然出现了D6D0,说好的5650呢?是怎么回事?
GBK编码汉字占2Bytes(16bit),英文占1Bytes(8bit)。如何区分它们?其实首位代表符号位。如果是汉字首位是1,如果是英文首位就是0。故汉字取15位,英文取7位才是Unicode表中真正存的值!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号