spark 预编译安装
1.下载地址:
上传虚拟机或服务器
2. 解压文件
tar -xzvf spark-3.0.0-preview-bin-hadoop2.7.tgz
3.配置环境变量
vi /etc/profile

source /etc/profile
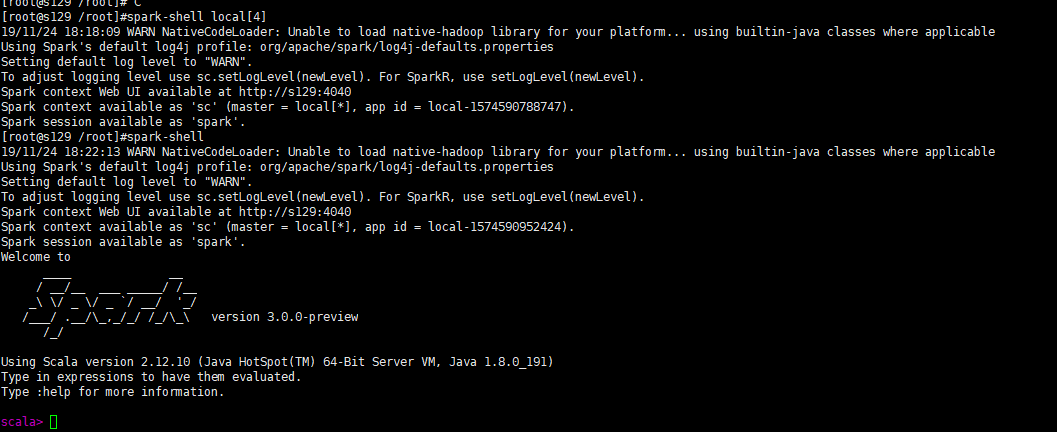
4. 启动spark
spark-shell local[4]
local[n] n就是线程数 可加 可不加看场景
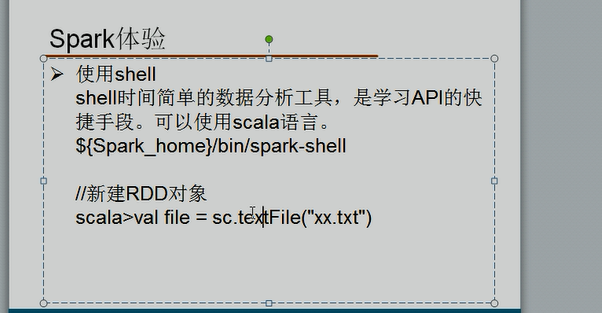
sprk RDD操作



1.下载地址:
上传虚拟机或服务器
2. 解压文件
tar -xzvf spark-3.0.0-preview-bin-hadoop2.7.tgz
3.配置环境变量
vi /etc/profile
source /etc/profile
4. 启动spark
spark-shell local[4]
local[n] n就是线程数 可加 可不加看场景
sprk RDD操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号