

浅谈CBAM:卷积块注意力机制
仅为个人理解,不作为教学使用
目录
1. 引言
为什么需要注意力机制?
在深度学习,特别是卷积神经网络(CNN)的发展历程中,注意力机制(Attention Mechanism)已经成为了一个重要的技术突破。传统的CNN在处理图像时,对所有特征通道和空间位置一视同仁,这显然不够高效——因为并非所有特征都同等重要。
CBAM的核心思想
CBAM(Convolutional Block Attention Module,卷积块注意力模块)是一种轻量级的注意力机制,它通过同时关注通道维度和空间维度,帮助神经网络更好地聚焦于重要的特征,抑制无关的背景信息。

CBAM的核心优势:
-
轻量级:计算开销小,几乎不增加模型复杂度
-
端到端训练:无需额外的监督信号
-
即插即用:可以轻松嵌入到任何CNN架构中
-
双维度注意力:同时关注"是什么"(通道)和"在哪里"(空间)
2. CBAM核心概念
CBAM是什么?
CBAM是一种顺序的注意力机制,它沿着两个不同的维度——通道维度和空间维度——依次推断注意力图。
-
通道维度的注意力图:通过一个全连接层(MLP)生成
-
空间维度的注意力图:通过一个卷积层生成
顺序推断的重要性
CBAM采用顺序而非并行的方式处理注意力,这是其关键设计之一。具体来说:
第一步:通道注意力
-
判断"哪些通道重要"
-
在CNN中,一层特征是R×H×W(R是通道数,H、W是特征图的高和宽)
-
CBAM进行R×1×1的权重计算,得到R个通道的权重
-
作用:把"重要的语义通道"放大,不重要的压小
第二步:空间注意力
-
判断"哪些空间位置重要"
-
生成1×H×W的空间位置权重
-
作用:让网络关注"重要区域",忽略背景
为什么是顺序而不是并行?
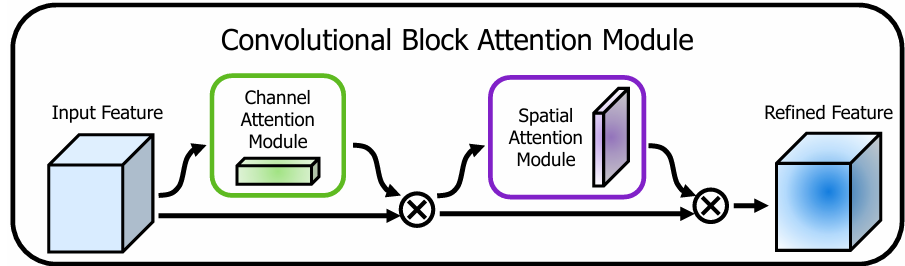

顺序处理的理由:
-
先语义,后位置:先确定哪些特征重要,再确定这些特征应该在哪些位置
-
信息流优化:通道注意力先过滤掉不重要的通道,减少空间注意力的计算负担
-
符合人类视觉:人眼也是先识别物体类别,再定位物体位置
核心要点总结
-
通道注意力关注"what"(是什么特征)
-
空间注意力关注"where"(在哪里)
-
CBAM通过先建模通道维度的语义重要性,再建模空间维度的位置信息,实现对特征的逐步精炼
3. 通道注意力模块(CAM)
理论基础
在CNN中,每个特征通道可以看作是对某种特定特征的响应(如边缘、纹理、颜色等)。通道注意力机制的目标是学习哪些通道更重要,并据此调整特征的权重。
通道注意力结构

通道注意力模块包含以下步骤:
-
空间聚合:使用平均池化和最大池化将空间维度压缩为1×1
-
平均池化:捕获全局语义信息
-
最大池化:捕获显著特征信息
-
两种池化互补,提高特征表达能力
-
-
特征融合:将两个池化结果相加
-
通道关系建模:通过共享MLP(多层感知机)学习通道间的依赖关系
-
降维:in_channels → in_channels/reduction_ratio
-
激活:ReLU
-
升维:in_channels/reduction_ratio → in_channels
-
reduction_ratio通常设为16,用于减少参数量
-
-
权重归一化:通过Sigmoid函数将权重限制在[0, 1]范围内
-
特征重标定:将权重与原始特征逐通道相乘
PyTorch实现
本文代码仅作结构示范。注意力模块的插入位置与参数需结合数据集、目标尺度分布、算力约束进行具体分析与消融实验后再确定。
import torch
import torch.nn as nn
import torch.nn.functional as F
class ChannelAttention(nn.Module):
"""通道注意力模块
Args:
in_channels (int): 输入特征图的通道数
reduction_ratio (int): 降维比例,默认为16
"""
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
# 空间聚合:平均池化和最大池化
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 输出: (batch, channels, 1, 1)
self.max_pool = nn.AdaptiveMaxPool2d(1) # 输出: (batch, channels, 1, 1)
# 共享MLP用于通道关系建模
# 使用1x1卷积替代全连接层,便于处理2D特征
self.fc = nn.Sequential(
# 降维层
nn.Conv2d(in_channels, in_channels // reduction_ratio,
kernel_size=1, bias=False),
nn.ReLU(inplace=True),
# 升维层
nn.Conv2d(in_channels // reduction_ratio, in_channels,
kernel_size=1, bias=False)
)
# Sigmoid激活函数,将权重归一化到[0, 1]
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""前向传播
Args:
x: 输入特征图,形状为 (batch, channels, height, width)
Returns:
加权后的特征图
"""
# 平均池化和最大池化
avg_out = self.fc(self.avg_pool(x)) # 形状: (batch, channels, 1, 1)
max_out = self.fc(self.max_pool(x)) # 形状: (batch, channels, 1, 1)
# 特征融合
out = avg_out + max_out # 形状: (batch, channels, 1, 1)
# 权重归一化
channel_weights = self.sigmoid(out) # 形状: (batch, channels, 1, 1)
# 特征重标定:逐通道相乘
return channel_weights * x
# 测试通道注意力模块
def test_channel_attention():
"""测试通道注意力模块"""
# 创建测试数据
batch_size = 2
channels = 64
height, width = 32, 32
x = torch.randn(batch_size, channels, height, width)
print(f"输入形状: {x.shape}")
# 创建通道注意力模块
ca = ChannelAttention(channels, reduction_ratio=16)
# 前向传播
output = ca(x)
print(f"输出形状: {output.shape}")
print(f"形状保持不变: {output.shape == x.shape}")
# 计算参数量
params = sum(p.numel() for p in ca.parameters())
print(f"通道注意力模块参数量: {params:,}")
return output
# 运行测试
test_channel_attention()
代码解析
关键组件说明:
-
AdaptiveAvgPool2d和AdaptiveMaxPool2d:自适应池化层,无论输入尺寸如何,都输出1×1的空间尺寸
-
共享MLP:使用两个1×1卷积层实现,分别处理平均池化和最大池化的结果
-
Sigmoid函数:确保通道权重在[0, 1]范围内,实现软选择机制
-
逐通道相乘:将学习到的权重应用到原始特征上,实现特征重标定
参数量计算:
-
假设输入通道数为C,reduction_ratio为16
-
第一个卷积层:C × (C/16) × 1 × 1 = C²/16
-
第二个卷积层:(C/16) × C × 1 × 1 = C²/16
-
总参数量:C²/8
4. 空间注意力模块(SAM)
理论基础
通道注意力告诉我们"哪些特征重要",但还需要知道"这些特征在图像的哪些位置重要"。这就是空间注意力模块的任务。
空间注意力机制学习哪些空间位置(像素)更重要,并据此调整特征图。
空间注意力结构
空间注意力模块包含以下步骤:
-
通道聚合:沿着通道维度进行平均池化和最大池化
-
平均池化:计算每个位置所有通道的平均值
-
最大池化:计算每个位置所有通道的最大值
-
输出形状:(batch, 1, height, width)
-
-
特征拼接:将两个池化结果在通道维度拼接
- 输出形状:(batch, 2, height, width)
-
空间关系建模:使用卷积层生成空间注意力图
-
通常使用7×7卷积核
-
输出形状:(batch, 1, height, width)
-
-
权重归一化:通过Sigmoid函数将权重限制在[0, 1]范围内
-
特征重标定:将权重与原始特征逐位置相乘
PyTorch实现
本文代码仅作结构示范。注意力模块的插入位置与参数需结合数据集、目标尺度分布、算力约束进行具体分析与消融实验后再确定。
class SpatialAttention(nn.Module):
"""空间注意力模块
Args:
kernel_size (int): 卷积核大小,默认为7
"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
# 计算padding以保持输出尺寸不变
padding = kernel_size // 2
# 卷积层用于生成空间注意力图
# 输入2通道(平均池化+最大池化),输出1通道
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size,
padding=padding, bias=False)
# Sigmoid激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""前向传播
Args:
x: 输入特征图,形状为 (batch, channels, height, width)
Returns:
加权后的特征图
"""
# 通道聚合:沿通道维度进行平均池化和最大池化
avg_out = torch.mean(x, dim=1, keepdim=True) # 形状: (batch, 1, H, W)
max_out, _ = torch.max(x, dim=1, keepdim=True) # 形状: (batch, 1, H, W)
# 特征拼接
x_cat = torch.cat([avg_out, max_out], dim=1) # 形状: (batch, 2, H, W)
# 空间关系建模
spatial_map = self.conv(x_cat) # 形状: (batch, 1, H, W)
# 权重归一化
spatial_weights = self.sigmoid(spatial_map)
# 特征重标定:逐位置相乘
return spatial_weights * x
# 测试空间注意力模块
def test_spatial_attention():
"""测试空间注意力模块"""
# 创建测试数据
batch_size = 2
channels = 64
height, width = 32, 32
x = torch.randn(batch_size, channels, height, width)
print(f"输入形状: {x.shape}")
# 创建空间注意力模块
sa = SpatialAttention(kernel_size=7)
# 前向传播
output = sa(x)
print(f"输出形状: {output.shape}")
print(f"形状保持不变: {output.shape == x.shape}")
# 计算参数量
params = sum(p.numel() for p in sa.parameters())
print(f"空间注意力模块参数量: {params:,}")
return output
# 运行测试
test_spatial_attention()
代码解析
关键组件说明:
-
torch.mean和torch.max:沿通道维度进行聚合,分别计算平均值和最大值
-
torch.cat:在通道维度拼接两个池化结果
-
卷积层:使用7×7卷积核捕捉较大的空间上下文信息
-
逐位置相乘:将学习到的空间权重应用到原始特征上
参数量计算:
-
假设使用7×7卷积核
-
参数量:2 × 7 × 7 × 1 = 98
-
非常轻量!
5. CBAM完整实现
CBAM模块整合
现在我们将通道注意力和空间注意力整合成一个完整的CBAM模块。
PyTorch实现
本文代码仅作结构示范。注意力模块的插入位置与参数需结合数据集、目标尺度分布、算力约束进行具体分析与消融实验后再确定。
class channel_attrntion(nn.Module):
def __init__(self,in_channels,reduction_ratio=16):
super(channel_attrntion, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)#张量层面池化
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_channels,in_channels//reduction_ratio,kernel_size=1,bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels//reduction_ratio,in_channels,kernel_size=1,bias=False)
)#mlp降维并先用一个小网络判断哪些通道重要,再把重要的通道放大,不重要的压小
self.sigmoid = nn.Sigmoid()
def forward(self,x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return x * self.sigmoid(out)
class space_attention(nn.Module):
def __init__(self, kernel_size = 7):
super(space_attention, self).__init__()
padding = kernel_size // 2
self.cov = nn.Conv2d(2,1,kernel_size,padding=padding,bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
avg_out = torch.mean(x,dim = 1,keepdim=True)#通道层面进行平均和最大池化
max_out, _ = torch.max(x,dim=1,keepdim=True)
x_cat = torch.cat([avg_out,max_out],dim=1)#通道拼接
out = self.cov(x_cat)
return x * self.sigmoid(out)
class CBAM(nn.Module):
def __init__(self, in_channels, reduction_ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.channel_attention = channel_attrntion(in_channels, reduction_ratio)
self.spatial_attention = space_attention(kernel_size)
def forward(self, x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x
def autopad(k, p=None, d=1):
# kernel, padding, dilation
# 对输入的特征层进行自动padding,按照Same原则
if d > 1:
# actual kernel-size
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
# auto-pad
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
# SiLU激活函数
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
# 标准卷积+标准化+激活函数
default_act = SiLU()
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# 标准瓶颈结构,残差结构
# c1为输入通道数,c2为输出通道数
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
# CSPNet结构结构,大残差结构
# c1为输入通道数,c2为输出通道数
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
# 进行一个卷积,然后划分成两份,每个通道都为c
y = list(self.cv1(x).split((self.c, self.c), 1))
# 每进行一次残差结构都保留,然后堆叠在一起,密集残差
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class SPPF(nn.Module):
# SPP结构,5、9、13最大池化核的最大池化。
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
class Backbone(nn.Module):
def __init__(self, base_channels, base_depth, deep_mul, phi, pretrained=False):
super().__init__()
#-----------------------------------------------#
# 输入图片是3, 640, 640
#-----------------------------------------------#
# 3, 640, 640 => 32, 640, 640 => 64, 320, 320
self.stem = Conv(3, base_channels, 3, 2)
# 64, 320, 320 => 128, 160, 160 => 128, 160, 160
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2),
C2f(base_channels * 2, base_channels * 2, base_depth, True),
CBAM(base_channels*2)
)
# 128, 160, 160 => 256, 80, 80 => 256, 80, 80
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2),
C2f(base_channels * 4, base_channels * 4, base_depth * 2, True),
CBAM(base_channels*4)
)
# 256, 80, 80 => 512, 40, 40 => 512, 40, 40
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2),
C2f(base_channels * 8, base_channels * 8, base_depth * 2, True),
CBAM(base_channels*8)
)
# 512, 40, 40 => 1024 * deep_mul, 20, 20 => 1024 * deep_mul, 20, 20
self.dark5 = nn.Sequential(
Conv(base_channels * 8, int(base_channels * 16 * deep_mul), 3, 2),
C2f(int(base_channels * 16 * deep_mul), int(base_channels * 16 * deep_mul), base_depth, True),
SPPF(int(base_channels * 16 * deep_mul), int(base_channels * 16 * deep_mul), k=5),
CBAM(int(base_channels * 16 * deep_mul))
)
def forward(self, x):
x = self.stem(x)
x = self.dark2(x)
#-----------------------------------------------#
# dark3的输出为256, 80, 80,是一个有效特征层
#-----------------------------------------------#
x = self.dark3(x)
feat1 = x
#-----------------------------------------------#
# dark4的输出为512, 40, 40,是一个有效特征层
#-----------------------------------------------#
x = self.dark4(x)
feat2 = x
#-----------------------------------------------#
# dark5的输出为1024 * deep_mul, 20, 20,是一个有效特征层
#-----------------------------------------------#
x = self.dark5(x)
feat3 = x
return feat1, feat2, feat3
参数说明
CBAM模块的三个关键参数:
-
in_channels(必需)
-
输入特征图的通道数
-
例如:对于ResNet50的第2阶段,可能是256
-
-
reduction_ratio(可选,默认16)
-
通道注意力MLP的降维比例
-
较小的值(如8):参数更多,表达能力更强,但计算量更大
-
较大的值(如32):参数更少,计算更快,但表达能力可能受限
-
推荐值:16(在大多数情况下效果很好)
-
-
kernel_size(可选,默认7)
-
空间注意力卷积核大小
-
常见选择:3、5、7
-
较大的核:能捕捉更大的空间上下文,但计算量稍大
-
推荐值:7(论文中的默认值)
-
参数量对比:
| 组件 | 参数量(C=256, r=16, k=7) | 说明 |
|---|---|---|
| 通道注意力 | 8,192 | C²/8 |
| 空间注意力 | 98 | 2×k² |
| CBAM总计 | 8,290 | 非常轻量 |
6. 总结
核心要点回顾
回顾CBAM(卷积块注意力机制)的原理和实现
1. CBAM是什么?
-
一种轻量级的注意力机制
-
同时关注通道和空间两个维度
-
顺序处理:先通道,后空间
2. 为什么有效?
-
通道注意力:筛选重要特征(what)
-
空间注意力:定位重要区域(where)
-
符合人类视觉机制
3. 如何实现?
-
通道注意力:池化 + MLP + Sigmoid
-
空间注意力:通道聚合 + 卷积 + Sigmoid
-
代码简单,易于理解和修改
4. 如何应用?
-
可嵌入任何CNN架构
-
在关键位置添加CBAM
-
端到端训练,无需额外标注
实际应用建议
对于初学者:
-
从简单的任务开始(如图像分类)
-
先理解单个模块的工作原理
-
使用默认参数(reduction_ratio=16, kernel_size=7)
-
逐步尝试应用到更复杂的任务
对于进阶用户:
-
根据任务调整CBAM参数
-
尝试不同的嵌入位置
-
可视化注意力图,理解模型行为
-
与其他注意力机制结合使用
对于研究者:
-
探索CBAM与Transformer的结合
-
研究动态注意力机制
-
优化计算效率
-
拓展到其他领域(如NLP)
未来学习方向
掌握了CBAM后,你可以继续学习:
-
更复杂的注意力机制:
-
Self-Attention(自注意力)
-
Cross-Attention(交叉注意力)
-
Multi-Head Attention(多头注意力)
-
-
Vision Transformer (ViT):
-
纯Transformer的视觉模型
-
与CNN的结合(如ViT + ResNet)
-
-
模型压缩与优化:
-
知识蒸馏
-
网络剪枝
-
量化压缩
-
-
可解释性研究:
-
注意力可视化技术
-
模型解释方法
-
对抗样本分析
-
参考资源
CBAM原始论文:
-
Woo, S., Park, J., Lee, J. Y., & Kweon, I. S. (2018). "CBAM: Convolutional Block Attention Module". In ECCV 2018.
官方实现:
结语
CBAM是一个优雅而强大的注意力机制,它在保持轻量级的同时,显著提升了CNN的性能。通过本文的学习,你应该能够:
-
理解CBAM的原理和工作机制
-
实现完整的CBAM代码
-
将CBAM应用到实际的深度学习项目中
-
评估和分析CBAM的效果
深度学习的世界里,注意力机制是一个永恒的话题。从最早的SE-Net,到CBAM,再到Transformer的Self-Attention,我们一直在探索如何让神经网络"学会关注"。
最后,记住一句话:
"注意力机制的核心不是让神经网络'看到更多',而是让神经网络'关注得更准'。"
Happy Coding! 🚀
Created with ❤️ for the Deep Learning Community

 浙公网安备 33010602011771号
浙公网安备 33010602011771号