
AI大模型入门宝典:从零到一,看懂所有核心术语
大家好,我是maoku。是不是经常在看AI文章或视频时,被一堆英文缩写和专业术语搞得头晕眼花?“Transformer”、“LoRA”、“RLHF”、“RAG”……每个词好像都认识,连起来就不知道在说什么了。
别担心,你不是一个人。今天这篇文章,就是为你准备的“AI大模型术语翻译指南”和“知识地图”。我将抛弃枯燥的词条解释,用一个“从零开始创建和用好一个大模型”的完整故事线,把上百个核心术语串起来,让你不仅能读懂,更能理解它们之间的逻辑关系。
当你读完,这些术语将不再是孤立的符号,而是一个清晰技术蓝图上的坐标点。
引言:为什么我们需要一张“地图”?
想象一下,你要组装一台顶级电脑。如果你面前只有一堆散落的零件(CPU、显卡、内存条……)和缩写说明书,肯定会无从下手。但如果你有一张清晰的组装流程图,告诉你第一步装什么、怎么装、为什么这么装,一切就会豁然开朗。
学习大模型技术也是如此。术语是“零件”,理解它们之间的连接与 workflow(工作流程)才是关键。 这篇文章就是那张流程图,带你走过大模型的“诞生”(训练)、“成长”(微调)到“工作”(应用)的全过程。无论你是想入行的新人、还是需要与技术人员沟通的产品经理,这张地图都能帮你快速建立系统认知。
技术原理:大模型的“一生”——从训练到应用
我们沿着大模型的“生命历程”,将核心术语分为几个关键阶段来理解。
第一阶段:模型的“诞生与基础教育”(训练基础)
这个阶段的目标是创造一个具备通用语言能力和知识的“聪明大脑”。
- 大模型(LLM):最终产物,一个参数量巨大(如千亿、万亿)、能理解和生成自然语言的“大脑”。
- 预训练:模型的“基础教育”。让这个大脑在海量、无标注的通用互联网文本上学习,目标是学会语言的规律(语法、句法)和世界知识(事实、常识)。这就像让一个孩子通过阅读百科全书和所有网站来识字和了解世界。
- Transformer:实现这一切的底层“万能公式”或“学习引擎”。它是几乎所有现代大模型的基础架构,其核心是自注意力机制。
- 自注意力:让模型在处理一句话时,能动态衡量句中每个词与其他所有词的关系。比如理解“它”指代什么,“但是”转折了谁。这就像你读文章时,眼睛和大脑会不断在词间来回关联,而非孤立地看每个字。
- 多头注意力:用多组“注意力”同时工作,有的关注语法结构,有的关注语义关联,让理解更全面。
- Decoder-only 架构:当前主流大模型(如GPT系列)采用的结构。它只使用Transformer的解码器部分,以自回归的方式,像猜谜一样一个字一个字地生成文本。
- Token:模型眼中的“字”。不是简单的汉字或单词,而是通过算法拆分出的基本语义单位(可能是字、词根或常用组合)。比如“Transformer”可能被拆成“Trans”、“form”、“er”三个Token。
- Embedding(嵌入):模型的“理解方式”。把每个离散的Token转换成一个稠密的、连续的数学向量(一串数字)。在这个向量空间里,语义相近的词(如“猫”和“狗”)位置也接近,模型借此理解语义。
这个阶段的关键挑战与技巧:
- 梯度消失/爆炸:模型太深,学习信号(梯度)传着传着就没了或炸了,导致学不下去。解决方案包括更好的网络结构(如残差连接)和归一化技术(如 LayerNorm)。
- 过拟合:模型死记硬背了训练数据,但不会举一反三。需要通过正则化手段防止,比如Dropout(随机让一部分神经元“休眠”,增强鲁棒性)。
- 稳定训练:使用Warmup策略,训练开始时用小学习率“热身”,再慢慢增大,防止一开始就“跑偏”。
第二阶段:模型的“专业技能培训”(微调与对齐)
预训练模型是个“通才”,但要让它在特定任务上成为“专家”,就需要微调。
- 微调:在预训练模型的基础上,用特定领域或任务的数据进行额外训练,调整其参数。
- 指令微调 / SFT(监督微调):让模型学会“听指令”。使用大量
{指令,期望输出}的配对数据来训练。例如,指令:“把这句话翻译成英文”,输出:“Translate this sentence into English.”。经过SFT,模型才从“续写文本”变成“回答问题”的助手。 - RLHF(基于人类反馈的强化学习):让模型学会“品味”和“分寸”。这是ChatGPT显得如此“贴心”和“无害”的关键。
- 核心逻辑:不再提供标准答案,而是让模型生成多个回答,由人类或奖励模型评判哪个更好(更 helpful、honest、harmless)。然后通过强化学习(如PPO算法)训练模型,使其趋向于生成高分回答。
- 对齐:RLHF的终极目标,让模型的价值观、行为目标与人类期望保持一致。
- 高效微调技术:为了避免对庞大模型进行全参数微调的巨额成本,诞生了:
- LoRA:在原有模型旁附加少量可训练的低秩矩阵,微调时只训练这些“小插件”,效果接近全参数微调,但成本极低。
- QLoRA:LoRA的“省钱升级版”。先把原模型量化压缩(如从16位浮点数转为4位整数),再在上面做LoRA,让消费级显卡也能微调大模型。
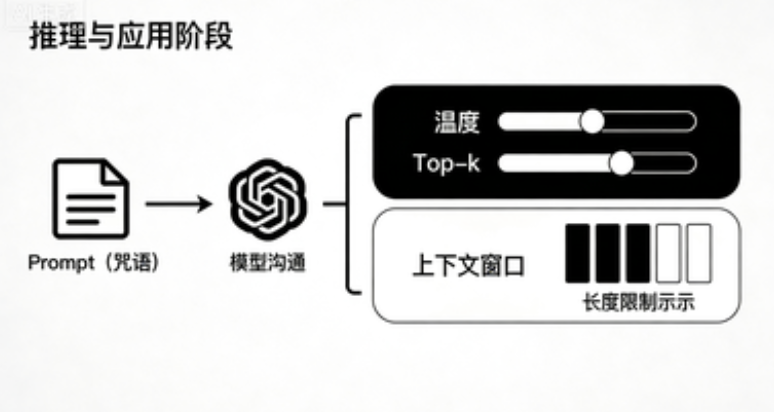
第三阶段:模型的“工作与产出”(推理与应用)
模型训练好了,我们如何让它为我们工作?
- 推理:使用训练好的模型处理新输入并产生输出的过程。
- 生成策略:如何让模型“说话”?
- 自回归生成:最基础的方式,像接龙,生成一个Token,把它加进去,再生成下一个。
- 采样:如何从模型预测的概率分布中选下一个Token?纯选概率最大的(贪婪搜索)会显得呆板。
- 温度:控制随机性的“旋钮”。温度高,输出更随机、有创意;温度低,输出更确定、保守。
- Top-k/Top-p:更聪明的采样法。Top-k:只从概率最高的k个候选里选;Top-p:从累积概率达到p的最小候选集中选。两者都用于避免选中那些概率极低的“奇怪”Token。
- 束搜索:保留多个较优的候选序列并行探索,最后选整体最优的,常用于机器翻译等任务。
- Prompt(提示词)与 Prompt Engineering:我们与模型沟通的“咒语”。精心设计的Prompt能极大激发模型潜力,比如通过Few-shot(少样本) 在Prompt里给几个例子让模型模仿,或使用Chain of Thought(思维链) 提示让模型“一步一步想”。
- 上下文窗口:模型一次性能处理和记忆的最大文本长度(输入+输出)。就像它的“工作记忆”容量。
- 幻觉:模型最令人头疼的毛病——自信地编造事实、引用或数据。因为它本质是“语言模式拟合器”,而非“事实数据库”。
第四阶段:增强模型能力与应对局限(进阶工程)
为了解决幻觉、知识陈旧等问题,工程师们发明了“外挂”。
- RAG(检索增强生成):给模型配一个“外部知识库”。
- 流程:用户提问 → 用嵌入模型将问题转为向量 → 去向量数据库中检索相关文档片段 → 将“问题+检索到的知识”一并送给大模型生成回答。
- 优点:回答更准确、可溯源、可更新知识。
- 工程化部署:如何让模型服务千万用户?
- 量化:将模型从高精度转为低精度存储和计算,大幅减小体积、提升推理速度。
- 模型/张量/流水并行:把一个大模型拆开,分布到多个GPU或服务器上协同工作。
- 推理框架:专门优化大模型推理速度的软件。
- API/服务化部署:将模型封装成标准的网络接口,供各种应用调用。
第五阶段:检验与守护(评估与安全)
如何确保模型可用、可靠、安全?
- 评估指标:
- 困惑度:衡量模型对文本的“熟悉程度”,值越低,说明文本越符合模型的认知,通常意味着更流畅。
- 安全与对抗:
- 红队测试:组建专家团队,像黑客一样,主动设计各种诱导性、攻击性的Prompt,试图“攻破”模型防线,找出其安全漏洞,从而进行修复。
实践步骤:亲手微调一个专属模型
了解了全貌,我们通过一个最简单的任务——用LoRA微调一个“正能量评论生成器”——来串联关键步骤。
目标:让模型学会将中性或轻微负面的句子,改写成积极向上的风格。
步骤1:准备“教材”(数据集)
创建一个JSON文件 positive_tune.jsonl,每条数据包含一个instruction和output。
{"instruction": "改写这句话,让它充满正能量:今天下雨了,没法出门。", "output": "虽然下雨带来了不便,但正是聆听雨声、享受室内温馨的好时光!"}
{"instruction": "改写这句话,让它充满正能量:工作好累啊。", "output": "每一份辛勤工作都是通向成长的阶梯,今天的付出正让明天的自己更强大!"}
// ... 准备几十到几百条类似数据
步骤2:选择“基座模型”和“训练方法”
- 基座模型:选择一个7B左右的指令微调模型,如
Qwen2.5-7B-Instruct。它已经会“听指令”了,我们只需要教它新风格。 - 训练方法:选择 LoRA,因为它高效、快捷,在单张消费级显卡上就能运行。
步骤3:开始“训练”
这里就是术语汇集的地方。你需要配置:
- 优化器与学习率:使用
AdamW优化器,设置一个较小的学习率(如2e-4),配合Warmup。 - 防止过拟合:设置适当的训练轮数(
epoch=3),并可能启用Dropout。 - 生成相关:设置
max_length(不能超过模型的上下文窗口),调整温度、Top-p等参数控制生成多样性。 - 高效微调:指定LoRA的
rank、alpha等超参数。
手动配置这些非常复杂。一个极佳的入门方式是使用【LLaMA-Factory Online】。这个平台将上述所有步骤可视化、自动化。你只需在网页上传数据集,选择模型(如Qwen2.5)和微调方法(LoRA),平台会自动推荐参数,并调用云端的GPU进行训练。你甚至可以在训练中实时监控损失(Loss)曲线,无需关心环境配置,真正实现“一键微调”。
步骤4:“毕业考试”(推理与评估)
训练完成后,用新模型生成测试。
- 输入:“改写这句话,让它充满正能量:这个任务太难了。”
- 期望输出:一个积极看待挑战的句子。
- 评估:
- 人工评估:生成的句子是否真的“正能量”?是否符合预期风格?(这是最重要的)
- 自动指标:可以计算生成句子的困惑度,看是否流畅。
- 对比测试:与原始基座模型生成的结果对比,看风格改进是否明显。
效果评估:如何判断模型“学成了”?
- 对于分类/判别任务:使用准确率、精确率、召回率、F1值等指标在预留的测试集上量化评估。
- 对于生成任务(如本例):
- 定性评估(核心):人工检查生成内容的相关性、流畅度、风格符合度。可以设计评分表。
- 定量辅助:使用BLEU、ROUGE分数对比生成结果与训练数据中“标准答案”的相似度(但不宜过分依赖,创意生成没有唯一答案)。
- 避免幻觉:检查生成内容是否编造了不存在的逻辑或事实。
- 安全评估:进行简单的红队测试,尝试用诱导性Prompt看模型是否会生成不当内容。
总结与展望
我们来为这张“地图”画上最后的图例:
- 一条主线:大模型技术围绕
预训练 -> 微调/SFT -> 对齐/RLHF -> 推理/应用 -> 增强/RAG的主线演进。 - 两大基石:Transformer架构提供了强大的模型能力,LoRA/QLoRA等高效微调技术则让普通人也能参与定制。
- 一个核心矛盾:模型强大的生成能力与难以根除的幻觉问题之间的对抗,催生了RAG等技术。
- 一个趋势:技术正在不断民主化和工程化。从需要巨额算力的预训练,到个人可及的微调,再到开箱即用的部署工具,门槛正在飞速降低。
未来,我们可能会看到更多“一体化”平台的出现,将数据准备、训练、评估、部署和持续学习(RAG)的闭环打通。而作为使用者,理解这些术语背后的逻辑,将帮助你在AI浪潮中,不仅是一个旁观者,更能成为一个主动的创造者。
希望这份超长的“术语地图”能成为你探索AI世界的可靠指南。如果你对其中任何一个模块特别感兴趣,想深入了解(比如Transformer的详细原理,或RAG的工程实现),欢迎在评论区告诉我。我是maoku,我们下次见!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号