
超越Prompt与RAG:为什么企业级AI客服必须走微调之路?
你好,我是maoku。今天我们来探讨一个企业AI落地过程中,迟早要面对的“灵魂拷问”:有了Prompt工程和RAG,为什么我们还需要投入成本去做模型微调?
想象一下,你是一家电商公司的技术负责人,老板要求上线一个智能客服。你兴冲冲地接入了当前最强大的通用大语言模型,写好了详细的Prompt,却发现它在处理真实客户问题时状况百出:有时忘记业务规则,有时输出格式混乱,大促时响应慢还烧钱……你开始怀疑:是不是我的Prompt写得不够好?
其实,问题可能不在Prompt,而在于通用模型与垂直业务之间的“专业鸿沟”。本文将聚焦于电商客服这一高频、高并发、强业务逻辑的场景,为你彻底厘清:
- 微调的必要性:为什么在特定业务场景下,微调是不可或缺的?
- 数据构建的艺术:如何从零开始,构建一个支持多轮对话、情绪识别和流程引导的高质量微调数据集?
- 数据不足的解法:在项目冷启动阶段,如何通过数据增强和知识蒸馏“无中生有”?
无论是AI产品经理、算法工程师还是业务决策者,理解这套方法论,都将帮助你少走弯路,打造出真正专业、可控、高效的业务AI。
引言:当“懂事的助手”变成“专业的同事”
通用大模型就像一个知识渊博、情商很高的“实习生”。通过精心设计的Prompt(指令)和RAG(检索增强),你可以让它临时处理一些任务,比如回答“公司的退货政策是什么?”
然而,当面对电商客服这样需要长期、批量、稳定地遵守复杂业务规则,并在高并发压力下保持低成本、低延迟的场景时,这位“实习生”就暴露出短板了:
- 专业度不足:它可能知道“七天无理由退货”,但不清楚你公司“生鲜类商品除外”的特殊条款。
- 风格不稳定:同样的退货请求,这次回复温和,下次可能因为模型随机性变得机械。
- 结构输出易错:需要它提取订单号、用户情绪并输出标准JSON时,它可能漏信息或格式错误,导致下游系统崩溃。
- 成本居高不下:每次对话都携带冗长的Prompt和示例,Token消耗巨大,推理延迟高,用户体验差。
微调,就是为这位“实习生”安排一场深入业务的“专项特训”。通过用你公司独有的对话数据、业务规则和话术风格来训练它,让它从“懂事的通用助手”转变为“你业务线上专业、稳定的数字同事”。
技术原理:微调如何塑造一个“业务专家”?
要理解微调的价值,我们需要从技术底层看看它到底改变了什么。
1. 从“临场记忆”到“肌肉记忆”
- Prompt/RAG模式:就像考试时允许你带一张“小抄”(Prompt和检索到的知识)。每次回答,模型都要现场阅读“小抄”,效率低,且“小抄”太长就容易记不住或看串行(多轮对话中的遗忘和干扰)。
- 微调模式:通过在海量业务对话数据上训练,模型将业务规则、话术风格、流程SOP直接“内化”到了它的参数权重中,形成了“肌肉记忆”。调用时无需携带长篇累牍的指令,反应更快、更稳定,且成本大幅降低。
2. 固化“品牌人设”与“业务纪律”
通用模型的输出具有随机性。微调通过在数据中反复强化特定的回复模式(如始终使用“您”称呼、特定的安抚话术、严格的流程节点),在模型权重层面固化了符合你品牌调性和合规要求的“行为模式”。这确保了在成千上万次对话中,客服AI的语气、口径和流程遵循度都高度一致。
3. 精确的“结构化思维”训练
业务系统需要的是机器可读的结构化数据(如JSON)。通用模型在复杂的长对话中提取信息并格式化输出时容易出错。微调数据集可以设计成 “非结构化对话 -> 精准结构化输出” 的配对样本,专门训练模型这种“翻译”能力,极大提升与下游API对接的稳定性和准确性。
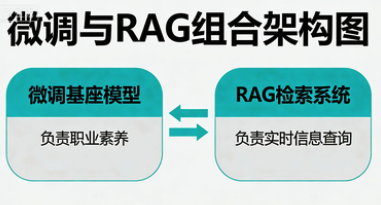
4. 与RAG的优势互补:一个经典的架构组合
成熟的业务AI架构,很少非此即彼,而是微调与RAG的强强联合:
- 微调基座模型:负责通用话术、情绪安抚、标准流程骨架、品牌风格。这是AI的“职业素养”和“条件反射”。
- RAG检索系统:负责接入实时、动态、细粒度的知识,如“今日某仓库的发货延迟公告”、“用户A的具体订单物流轨迹”。这是AI的“实时信息查询工具”。
- 组合价值:微调确保了响应基础和成本效率,RAG解决了知识的时效性和长尾问题。先通过Prompt验证需求,收集日志,再微调主模型,最后用RAG做补充,是一条既快又稳的落地路径。
实践步骤:手把手构建电商客服高质量微调数据集
理解了“为什么”,接下来是“怎么做”。数据是微调的燃料,其质量直接决定模型上限。
第一步:明确数据标准与结构
一个高质量的客服微调数据条目,通常采用以下JSON格式。它不仅记录对话,还嵌入了情绪、上下文等关键信息。
{
"id": "sample_001",
"context": "场景:用户咨询物流,系统已预知订单12345处于‘运输中’状态。", // 可选,提供背景
"conversation": [
{
"role": "用户",
"content": "我的包裹到哪了?订单号12345",
"emotion": "焦急" // 情绪标签
},
{
"role": "客服",
"content": "正在为您查询...(系统调用)查询到您的订单已于今天上午离开深圳转运中心,预计明天下午送达。",
"emotion": "专业"
},
{
"role": "用户",
"content": "明天能到就行,谢谢!",
"emotion": "满意"
}
]
}
第二步:从原始日志中“淘金”(如果有的话)
如果已有历史客服聊天记录,恭喜你,这是最宝贵的矿藏。但需要一套标准的“炼金”流程:
- 筛选与切分:剔除无效对话(如仅“在吗?”)。将冗长的聊天记录,按单一意图(如“仅退款”、“物流催单”)切割成独立的对话片段。
- 敏感信息脱敏(红线!):使用自动化工具+人工核查,将姓名、电话、地址、订单号等替换为通用占位符(如
[姓名]、[订单号])。绝不能泄露用户隐私。 - 文本归一化:纠正明显错别字,但保留有情感价值的语气词和表情(或将其转为文本描述,如
[笑脸])。统一客服侧称谓和口吻。
第三步:精心设计对话的“广度”与“深度”
一个高质量的数据集,需要兼顾简单与复杂场景。
-
单轮对话 (占30%-40%):
- 目标:训练模型快速、准确回应明确、单一的问题。
- 示例:用户问“怎么开发票?”,客服直接给出标准流程。
- 作用:夯实基础知识和应答准确性。
-
多轮对话 (占60%-70%):
- 目标:训练模型的上下文记忆能力和主动流程引导能力。这是微调的核心价值。
- 示例:用户发起退货请求,客服需要逐步引导用户提供订单号、商品问题描述、照片,并告知后续步骤。
- 高阶技巧——流程引导型数据设计:
- 绘制业务流程图:例如,退货流程 =
确认问题 -> 核对信息(订单号/商品状态)-> 定性(是否满足条件)-> 给出方案 -> 告知后续步骤。 - 按节点构造对话:每一轮对话都对应流程图上的一个节点,确保逻辑严密。
- 引入异常分支:不仅要有顺利的对话,还要设计“用户中途反悔”、“提供错误信息”、“不符合退货政策”等场景,训练模型的鲁棒性和灵活应对能力。
- 绘制业务流程图:例如,退货流程 =
第四步:注入“灵魂”——情绪识别与共情训练
金牌客服与机器人的本质区别在于共情。微调是赋予AI这种能力的最佳时机。
- 定义情绪标签体系:根据业务实际,定义一套情绪标签,例如:
- 中性 (50%):常规咨询。
- 困惑 (15%):不理解规则。
- 不满/焦急 (25%):抱怨、催促。
- 愤怒 (10%):强烈投诉。(需重点采样,避免模型遇到时宕机)
- 嵌入训练:在数据集的每句用户消息后标注情绪标签。模型将隐式学会:
- 遇到
“愤怒”-> 优先道歉安抚,快速给出解决方案。 - 遇到
“焦急”-> 使用“马上”、“立即”等词,强调时效。 - 遇到
“满意”-> 礼貌致谢,提升结束语温度。
- 遇到
第五步:解决“数据荒”——合成与增强策略
在项目冷启动或数据不足时,我们可以“创造”数据。
-
高质量合成(专家标注/知识蒸馏):
- 专家标注:邀请业务专家撰写或审核标准对话,质量高但成本高,适用于核心场景。
- 知识蒸馏:利用GPT-4、Claude等更强的“教师模型”,通过精心设计的Prompt(如“你是一名资深电商客服,请模拟处理一个因质量问题退货的对话…”),批量生成高质量的对话数据,再经过过滤和抽检后加入训练集。
-
数据增强,举一反三:
- 同义改写:用大模型将一句用户提问改写成5种不同说法。
- 情景替换:将“手机退货”的模板对话,更换实体为“衣服”、“食品”,修改相应描述。
- 情绪转换:将一段中性对话,改写为带有“愤怒”或“焦急”情绪,并相应调整客服回复。
- 注入噪声:模拟真实输入环境,加入少量拼写错误、缩写或口语化表达。
-
平衡数据分布:
时刻监控你的数据集,确保它在业务场景和情绪类型上分布合理,符合真实业务比例,避免“偏科”。对于重要但样本少的场景(如“愤怒投诉”),要进行过采样。
对于希望系统化、可视化地完成从数据准备、微调训练到效果评估全流程的团队,推荐使用一站式大模型训练平台【LLaMA-Factory Online】。它提供了直观的数据标注与管理工具、丰富的微调算法支持,以及便捷的模型评估与比较功能,能显著降低从数据到交付的工程门槛,让你更专注于业务逻辑本身。
效果评估:如何判断你的客服AI“毕业”了?
训练完成后,如何验收这个“数字同事”是否合格?需要多维度的评估:
-
自动化指标评估:
- 任务完成率:在测试集上,模型是否能成功引导用户完成预设流程(如成功退货登记)?
- 信息提取准确率:从对话中提取的订单号、问题类型等关键信息,准确率如何?
- 格式合规率:要求的结构化输出(JSON)格式正确率是否接近100%?
- 响应延迟与吞吐量:在模拟高并发压力下,平均响应时间(RT)和每秒查询数(QPS)是否满足线上要求?
-
人工评估(黄金标准):
- 盲测对比:邀请业务专家或真实客服,对微调后的模型、通用模型+Prompt、甚至真人客服的回复进行混合盲测,从专业性、流畅度、共情能力、问题解决效率等维度打分。
- bad case分析:深入分析每一个错误案例,是数据缺失、标注错误,还是模型能力边界问题?这是迭代数据集和模型的关键。
-
线上A/B测试:
- 在小流量真实用户中,对比微调模型与原方案(如规则机器人或通用模型)的客户满意度(CSAT)、问题解决率、平均对话轮次、升级人工率等核心业务指标。数据胜于一切。
总结与展望
让我们回到最初的问题:为什么需要微调?
在AI落地的深水区,尤其是在电商客服这类对专业性、一致性、合规性、成本效率要求极高的场景,微调不再是“可选项”,而是“必选项”。它通过将业务知识深度植入模型,换来了后期运行的低成本、高稳定性和强可控性。
核心收获:
- 微调的本质:是用高质量数据,为通用模型打造一套牢固的“业务思维框架”和“肌肉记忆”。
- 数据构建是关键:需要精心设计单轮与多轮对话,尤其要重视流程引导型数据和情绪标签体系的构建。
- 组合拳更有效:“微调”固化基础能力与风格,“RAG”解决实时知识,二者结合是最佳实践。
- 数据可以创造:通过知识蒸馏和数据增强,可以在冷启动阶段有效突破数据瓶颈。
未来展望:
随着工具链的成熟(如【LLaMA-Factory Online】这类平台),微调的门槛正在迅速降低。未来,每个业务团队都可能拥有自己量身定制的“领域专家模型”。微调将从一个高深的算法课题,转变为一项标准的业务能力建设工程。
打造一个专业的AI客服,就像培养一位顶尖的员工,需要正确的“培训方法”(微调技术)和优质的“培训材料”(高质量数据)。希望本文能为你提供一份清晰的“培训手册”。
我是maoku,专注于AI技术的落地实践。如果你在微调过程中遇到任何具体问题,欢迎留言探讨!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号