
《给AI模型做“微创手术”:从理论到实践,手把手教你掌握LoRA/QLoRA》
大家好,我是maoku。今天,我们聊一个让所有AI开发者又爱又恨的话题:大模型微调。
爱的是,微调能让千亿参数的“通才”模型,变成专属于你的“领域专家”。恨的是,这个过程通常意味着天价的算力账单和令人绝望的“显存不足(OOM)”报错。
但今天,我要告诉你一个好消息:全量微调(Full Fine-Tuning)的“烧卡”时代,正在成为过去式。 一种名为 LoRA/QLoRA 的参数高效微调技术,已经可以让普通开发者在24GB显存的消费级显卡上,对700亿参数的巨型模型进行高效定制!
下面,就让我带你彻底看懂这场技术革命。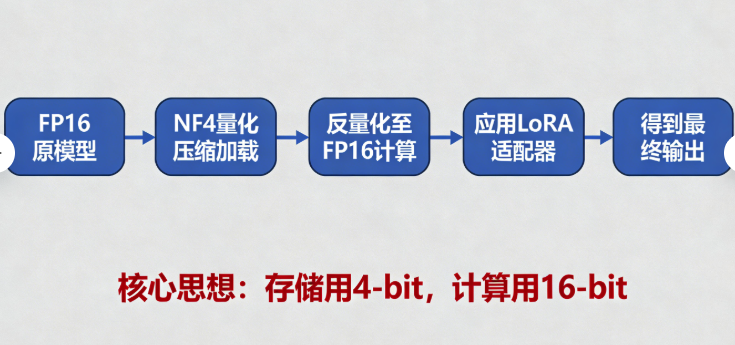
引言:我们为什么需要LoRA/QLoRA?
想象一下这个场景:你的公司拿到了一份珍贵的医疗数据集,希望微调一个700亿参数的 Llama 3 模型,让它成为顶级的AI医生助理。
如果采用传统的全量微调,意味着你需要同时加载这个巨无霸模型的所有参数(约140GB),并计算、存储每一个参数的梯度(又是140GB)。总计近300GB的显存需求,直接宣判了绝大多数GPU的“死刑”——即便是顶级的A100 80GB显卡,也会频繁爆显存。
LoRA(Low-Rank Adaptation,低秩自适应) 的出现,彻底改变了游戏规则。它基于一个深刻的洞察:大模型在适应新任务时,其权重更新矩阵本质上是“低秩”的。 也就是说,不需要改变模型的“全身骨骼”,只需要在关键位置添加一个轻巧的“可调节支架”。
QLoRA 则在LoRA的基础上更进一步,将基础模型用量化技术(如4-bit)压缩后再进行LoRA微调,实现了“内存压缩”和“高效适配”的双重魔法。
带来的结果是革命性的:微调一个700亿参数的模型,显存需求从780GB暴降至24GB以下,可训练参数量减少99.9%,却能保留95%以上的任务性能。这意味着,一块RTX 4090消费级显卡,就能承载起训练“行业大模型”的梦想。
技术原理:给AI动一场“微创手术”(深入浅出版)
核心思想:低秩更新——不是重塑骨骼,而是装上“义肢”
想象一下预训练大模型是一个已经学富五车的博士。全量微调相当于让他把过去所有的知识(模型权重)全部打碎重学,成本极高且容易“学伤”(灾难性遗忘)。
而LoRA的思路是:博士的知识骨架(预训练权重 W0)非常完美,我们完全冻结它。我们只需要为他定制几套轻便的“知识扩展卡”(低秩矩阵 A 和 B),插在关键的大脑区域(Transformer的特定层)。当他需要处理新任务时,就同时调用原有知识和扩展卡。
数学上的优雅表达:
新权重 W = 原始权重 W0 + 低秩更新 BA
这里的 B 和 A 是两个又矮又胖的矩阵,它们的乘积 BA 构成了一个与 W0 同尺寸的更新量,但 B 和 A 内部的可训练参数总量极少。这个“低秩”的秩(r)就是扩展卡的“信息容量”,通常设为8、16、32等很小的值。
maoku小贴士:你可以把 W0 想象成一张完整的 4K 高清原图,而 BA 就像一张仅为 512x512 像素的修改蒙版。虽然蒙版很小,但叠加到原图上,足以精确地改变画面中特定区域(对应任务相关特征)的色调和细节,让整幅画的主题焕然一新。我们训练的就是这个小蒙版,原图始终不变。
QLoRA:给“原图”做个无损压缩
LoRA解决了“更新参数多”的问题,但加载基础模型 W0 本身仍然需要海量显存。QLoRA的妙招是:在加载模型时,就把它从FP16精度(2字节/参数)压缩到4-bit精度(0.5字节/参数)。
- NF4量化:一种针对神经网络权重正态分布优化的4-bit数据类型,比普通INT4精度损失小得多。
- 双重量化:对量化参数本身再进行一次量化,额外节省一点显存。
- 核心保障:在计算时,将4-bit权重实时反量化回FP16精度,确保前向传播和反向传播的计算精度几乎无损。
这样,我们既享受了量化带来的 ~75% 模型加载内存节省,又在计算时保持了高精度。QLoRA = 量化(Quantization) + LoRA,是当前个人开发者微调大模型的最强利器。
实践步骤:手把手完成你的第一次QLoRA微调
我们以在医疗问答数据集上微调一个 Llama-2-7B 模型为例,展示完整流程。
环境配置:打好地基
# 1. 创建并进入虚拟环境(良好的习惯)
conda create -n qlora_tuning python=3.10
conda activate qlora_tuning
# 2. 安装核心依赖(注意版本兼容性)
pip install torch==2.1.0
pip install transformers==4.36.2 peft==0.7.1 accelerate==0.25.0
pip install bitsandbytes==0.41.1 # 量化核心库
pip install datasets trl wandb # 数据集、训练循环和可视化工具
数据准备:质量决定天花板
数据格式是关键!必须组织成模型认识的对话格式。以Alpaca格式为例:
[
{
"instruction": "根据以下症状,推断可能患有的疾病。",
"input": "患者持续性干咳超过三周,伴有低热和夜间盗汗。",
"output": "这些症状可能与肺结核有关,建议尽快进行胸部X光检查和痰涂片检测。"
}
]
from datasets import load_dataset
from transformers import AutoTokenizer
# 1. 加载并格式化数据集
dataset = load_dataset("json", data_files="medical_qa.json")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
tokenizer.pad_token = tokenizer.eos_token # 设置填充token
# 2. 构建提示词模板并分词
def format_func(example):
text = f"### 指令:{example['instruction']}\n### 输入:{example['input']}\n### 回答:{example['output']}"
return {"text": text}
def tokenize_func(example):
return tokenizer(example["text"], truncation=True, max_length=512, padding="max_length")
dataset = dataset.map(format_func).map(tokenize_func, batched=True)
train_dataset = dataset["train"].train_test_split(test_size=0.1)["train"]
eval_dataset = dataset["train"].train_test_split(test_size=0.1)["test"]
模型与参数配置:注入LoRA的“灵魂”
这是最核心的一步,我们配置QLoRA。
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# 1. 配置4-bit量化加载
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用4-bit加载
bnb_4bit_quant_type="nf4", # 使用NF4量化,精度更高
bnb_4bit_compute_dtype=torch.float16, # 计算时使用FP16
bnb_4bit_use_double_quant=True, # 使用双重量化,再省一点显存
)
# 2. 加载量化后的基础模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
quantization_config=bnb_config,
device_map="auto", # 让accelerate自动分配设备(多卡或CPU卸载)
trust_remote_code=True
)
model.gradient_checkpointing_enable() # 启用梯度检查点,用时间换空间
# 3. 为k-bit训练准备模型
model = prepare_model_for_kbit_training(model)
# 4. 注入LoRA配置!
lora_config = LoraConfig(
r=16, # 秩,低秩矩阵的维度。越大能力越强,但参数越多。8/16/32是常用值。
lora_alpha=32, # 缩放因子,通常设为 r 的2倍,直接影响更新强度。
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"], # 对哪些层应用LoRA。Llama通常选择注意力层的投影矩阵。
lora_dropout=0.05, # LoRA层的Dropout率,防止过拟合。
bias="none", # 不训练偏置项。
task_type="CAUSAL_LM", # 因果语言模型任务
)
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters() # 打印可训练参数量,你会惊喜地发现只占原模型的0.1%!
对于想要快速实验、避免复杂环境配置和代码调试的同学,也可以考虑使用一些集成化的平台。例如,【LLaMA-Factory Online】提供了一个可视化的界面,支持上述所有LoRA/QLoRA配置选项,并能一键启动训练和监控,非常适合初学者快速验证想法和进行对比实验。
训练循环:启动“微创手术”
from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModeling
# 1. 数据整理器
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# 2. 训练参数
training_args = TrainingArguments(
output_dir="./llama2-med-qlora",
per_device_train_batch_size=4, # 根据显存调整
per_device_eval_batch_size=4,
gradient_accumulation_steps=4, # 梯度累积,模拟更大batch size
num_train_epochs=3,
logging_steps=10,
save_steps=100,
evaluation_strategy="steps",
eval_steps=100,
learning_rate=2e-4, # LoRA学习率通常比全量微调大
fp16=True,
save_total_limit=2,
load_best_model_at_end=True,
report_to="wandb", # 可选,使用wandb监控训练
)
# 3. 创建Trainer并开始训练
trainer = Trainer(
model=peft_model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()
推理与合并:拔出“支架”,得到完整新模型
训练完成后,我们得到的是独立的LoRA适配器权重(很小,几MB到几十MB)。推理时有两种方式:
-
动态加载(推荐用于测试/多任务切换):保持基础模型不变,动态加载不同的LoRA适配器。
from peft import PeftModel base_model = AutoModelForCausalLM.from_pretrained(...) # 加载原模型 peft_model = PeftModel.from_pretrained(base_model, "./llama2-med-qlora/checkpoint-xxx") # 使用peft_model进行推理,它包含了基础模型+LoRA适配器 -
永久合并(用于最终部署):将LoRA权重合并到基础模型中,得到一个独立的、与原始模型结构完全一致的新模型文件,推理速度无任何损失。
# 合并并保存完整模型 merged_model = peft_model.merge_and_unload() merged_model.save_pretrained("./llama2-medical-merged") tokenizer.save_pretrained("./llama2-medical-merged") # 之后就可以像使用任何原生模型一样加载它了
效果评估:如何判断你的“手术”成功了?
训练日志里损失下降并不代表一切。你需要系统性地评估:
-
定量指标:
- 验证集损失(Loss):是否平稳下降并收敛?
- 任务特定指标:如果是问答,用 ROUGE、BLEU 分数;如果是分类,用准确率、F1值。与基础模型(零样本)对比,看提升幅度。
- 综合评估框架:使用像 MT-Bench(对话)或 MMLU(知识)等基准测试,评估模型能力的保留和增强情况。
-
定性分析(至关重要!):
- 生成样例检查:手动输入一些典型和边缘的测试问题,观察生成结果的准确性、相关性和流畅性。
- 对比测试:将微调后的模型、原始基础模型、甚至全量微调模型(如果有)对同一组问题的回答进行盲评,让人来判断哪个更好。
-
效率与资源评估(LoRA的核心优势):
- 显存占用:训练全程是否稳定?峰值显存是否符合预期(应远小于全量微调)?
- 训练时长:相比全量微调,节省了多少时间?
- 模型存储:最终的LoRA适配器文件有多大?(应该是MB级别)
总结与展望
让我们回顾一下 LoRA/QLoRA 带来的范式转移:
- 民主化AI:让个人开发者和中小企业也能参与到超大模型的定制化中。
- 低成本试错:可以快速、低成本地尝试在不同的数据、任务上微调模型,寻找最佳方向。
- 模型管理革命:一个基础模型可以搭配无数个轻量级LoRA适配器,实现“一个底座,多种能力”,极大简化了模型部署和版本管理。
展望未来,LoRA技术本身也在进化:
- 更高效的参数注入:如 DoRA(权重分解的LoRA)试图取得更好的效果。
- 动态LoRA:让模型在推理时能根据输入自动选择或组合不同的LoRA模块。
- 与更多技术结合:如与模型剪枝、知识蒸馏等结合,进一步压缩和加速。
掌握LoRA/QLoRA,就如同掌握了开启大模型宝藏的一把轻巧而万能的钥匙。希望这篇详尽的指南,能帮助你顺利踏上高效微调的实践之路。
我是maoku,我们下次技术深潜再见!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号