
告别关键词搜索:向量数据库如何实现“懂你”的语义检索?
大家好,我是你们的AI技术朋友maoku。今天我们来聊聊一个在AI领域越来越火,但很多人又觉得神秘的技术——向量数据库。它被称为AI应用的“记忆中枢”,是让大模型真正“落地”的关键基础设施。
引言:当AI需要“记忆”和“理解”
想象一下,你问ChatGPT:“推荐几部类似《星际穿越》的科幻电影。”传统的搜索引擎只能匹配关键词,而ChatGPT却能理解“类似”的语义——烧脑、硬核、父女情深、时间悖论。这背后,除了大模型自身的推理能力,还依赖于一种能够快速查找“语义相似”内容的技术:向量检索,而向量数据库正是为此而生。
简单来说,向量数据库是专门为存储、检索高维向量(一种数学表示)而优化的数据库。它能让计算机像人一样,根据“意思”而非“字面”去查找信息,是构建智能推荐、AI问答、跨模态搜索等前沿应用的基石。
第一部分:技术原理——不懂数学也能看懂
1. 万物皆可“向量化”:从文本、图片到世界
一切数据(文本、图片、音频、视频)都可以通过AI模型(如BERT、CLIP、ResNet)转化为一串有意义的数字序列,这就是向量(或称“嵌入向量”)。
- 例子:句子“我爱北京天安门”通过模型转换后,可能变成
[0.12, -0.98, 0.56, ..., 0.23]这样一个768维的数组。 - 关键:语义相似的句子,其向量在数学空间中的距离也更近。比如,“我喜欢北京故宫”的向量就会和上面那个向量非常“靠近”。
![截屏2026-01-20 13.29.47]()
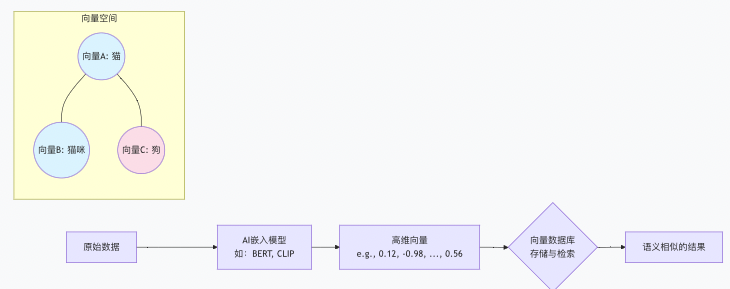
2. 核心任务:大海捞针,眨眼即得
向量数据库的核心挑战是:如何在数亿甚至数十亿的向量中,快速找到与目标向量最相似的Top K个结果?这被称为最近邻搜索(NN)。当数据量巨大时,精确计算会非常慢,因此通常采用近似最近邻搜索(ANN),在精度和速度间取得完美平衡。
主要ANN算法简介:
| 算法 | 核心思想 | 特点 | 好比…… |
|---|---|---|---|
| HNSW | 将向量组织成多层图结构,像高速公路网,快速导航。 | 检索速度快、精度高,适合对精度要求高的场景。内存消耗相对较大。 | 用多级交通枢纽(省际高速、市内高架、地面道路)快速定位目的地。 |
| IVF | 先将所有向量聚类成若干“小团体”(倒排列表),搜索时只在最相关的几个团体里找。 | 检索速度极快,适合超大规模数据集。精度略低于HNSW。 | 先确定你要找的人是“华东地区”的,再在“江浙沪”这个圈子里细找,而不是全国瞎找。 |
| PQ | 将高维向量压缩成紧凑的编码,大大减少内存占用和计算量。 | 内存利用率高,适合内存敏感或十亿级以上的超大规模场景。 | 用邮政编码代替详细地址进行初步筛选,虽然损失一些精度,但效率极高。 |
3. 与传统数据库的根本区别
| 对比维度 | 传统数据库 (MySQL, MongoDB) | 向量数据库 (Milvus, Pinecone) |
|---|---|---|
| 存储核心 | 结构化数据(表、文档) | 高维向量 + 元数据 |
| 检索方式 | 精确匹配 (WHERE name = ‘张三’) |
相似度匹配 (找到和某个向量最“像”的) |
| 查询目标 | “给我叫‘张三’的记录” | “给我和这张图片/这段话意思最接近的内容” |
| 核心优化 | B树、哈希索引 | ANN向量索引 (HNSW, IVF-PQ) |
| 典型场景 | 电商交易、用户管理 | AI语义搜索、智能推荐、RAG问答 |
第二部分:实践步骤——30分钟上手Milvus
理论说千遍,不如跑一遍。我们以目前最流行的开源向量数据库 Milvus 为例,带你快速搭建一个语义搜索Demo。
步骤一:环境搭建(最快的方式)
使用 Docker Compose 一键部署(推荐):
这是最简单的入门方式,一条命令启动所有依赖。
# 1. 下载官方docker-compose文件
wget https://github.com/milvus-io/milvus/releases/download/v2.3.12/milvus-standalone-docker-compose.yml -O docker-compose.yml
# 2. 启动所有服务(包括Milvus、元数据存储Etcd、对象存储MinIO)
docker-compose up -d
# 3. 查看运行状态
docker-compose ps
看到所有服务状态为 Up 就成功了!Milvus服务默认运行在 19530 端口。
步骤二:连接与数据准备(Python示例)
-
安装Python客户端:
pip install pymilvus -
连接数据库:
from pymilvus import connections connections.connect("default", host="localhost", port="19530") print("连接成功!") -
准备你的数据和向量:
我们需要一些文本和对应的向量。假设我们有一个简单的文章片段集合。# 模拟:3个文本片段及其ID texts = [ "向量数据库是AI应用的重要基础设施。", "机器学习模型可以将文本转换为高维向量。", "今天的天气晴朗,适合户外运动。" ] ids = [1, 2, 3] # 关键步骤:将文本转为向量。 # 这里需要调用一个嵌入模型(Embedding Model)。 # 为简化,我们使用随机向量模拟。实际中应使用BERT、OpenAI API等。 import numpy as np dim = 768 # 假设我们的向量维度是768 vectors = np.random.randn(len(texts), dim).tolist() # 生成随机向量 # 在实际项目中,请替换为真实的向量生成代码,例如: # from sentence_transformers import SentenceTransformer # model = SentenceTransformer(‘BAAI/bge-small-zh’) # vectors = model.encode(texts).tolist()
步骤三:创建集合(表)并插入数据
在Milvus中,“集合(Collection)”类似传统数据库的表。
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
# 1. 定义字段:一个主键ID,一个向量字段
fields = [
FieldSchema(name=“id”, dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name=“embedding”, dtype=DataType.FLOAT_VECTOR, dim=dim), # dim必须与你生成的向量维度一致
FieldSchema(name=“text”, dtype=DataType.VARCHAR, max_length=500) # 额外存储原文
]
schema = CollectionSchema(fields, description=“测试语义搜索”)
collection_name = “demo_articles”
# 2. 创建集合
collection = Collection(name=collection_name, schema=schema)
print(f“集合 ‘{collection_name}‘ 创建成功!”)
# 3. 插入数据
# 注意:插入的数据顺序要与字段定义顺序对应 [id, embedding, text]
data = [ids, vectors, texts]
collection.insert(data)
collection.flush() # 将数据持久化
print(f“插入了 {collection.num_entities} 条数据。”)
步骤四:构建索引与进行搜索
不建索引也能搜,但速度慢。为向量字段建立索引是生产环境的必经步骤。
# 1. 创建索引(以HNSW为例)
index_params = {
“index_type”: “HNSW”,
“metric_type”: “IP”, # 相似度度量方式:IP(内积,越大越相似),也常用L2(欧氏距离,越小越相似)
“params”: {“M”: 16, “efConstruction”: 200} # HNSW参数
}
collection.create_index(field_name=“embedding”, index_params=index_params)
print(“索引构建完成。”)
# 2. 将集合加载到内存(搜索前必需步骤)
collection.load()
# 3. 执行语义搜索!
query_text = [“什么是AI的基础设施?”] # 用户的问题
# 同样,需要将问题转换为向量 (此处用随机向量模拟)
query_vector = np.random.randn(1, dim).tolist()
search_params = {“metric_type”: “IP”, “params”: {“ef”: 50}} # HNSW搜索参数
results = collection.search(
data=query_vector, # 查询向量
anns_field=“embedding”, # 在哪个字段上搜索
param=search_params,
limit=3, # 返回最相似的3条
output_fields=[“text”, “id”] # 同时返回这些字段的内容
)
# 4. 展示结果
print(“\n=== 语义搜索结果 ===“)
for i, hits in enumerate(results):
print(f“对于查询 ‘{query_text[0]}’:“)
for hit in hits:
print(f” ID: {hit.id}, 相关性分数: {hit.score:.4f}, 内容: {hit.entity.get(‘text’)}”)
运行这段代码,你就能看到系统返回了与“AI基础设施”语义上最相关的文章片段(尽管我们用的是随机向量,实际效果会非常精准)。
对于希望在可视化界面中轻松管理向量数据、进行RAG应用原型设计的开发者,可以关注【LLaMA-Factory Online】平台。它不仅集成了大模型微调,也正在积极融合向量数据库管理功能,未来有望提供一站式的AI应用开发体验。
第三部分:效果评估——如何衡量一个向量数据库的好坏?
部署了向量数据库后,如何验证它的效果和性能?
1. 功能性评估:查得“准”吗?
- 召回率(Recall):在Top K个结果中,有多少是真正相关的?这是衡量“找得全”的核心指标。
- 准确率(Precision):返回的Top K个结果中,相关的结果占多少?这是衡量“找得对”的核心指标。
- 人工评测:对于搜索、推荐等场景,组织人力对搜索结果进行相关性打分(如1-5分),是最可靠的评估方式。
2. 性能评估:查得“快”吗?
- 查询延迟(QPS & Latency):每秒能处理多少查询(QPS)?单个查询的平均响应时间(Latency)是多少?这直接决定用户体验。
- 索引构建时间与内存占用:为十亿数据建索引要多久?运行时需要多少内存?这关系到成本和运维复杂度。
- 吞吐量:批量写入和查询的速率如何?
3. 系统评估:稳定可靠吗?
- 可用性与扩展性:是否支持分布式集群?能否轻松水平扩展以应对数据增长?
- 数据持久化与一致性:断电会不会丢数据?能否保证数据的强一致性?
- 运维友好性:监控、告警、备份恢复工具是否完善?
第四部分:主流产品选型指南
面对众多选择,该如何挑选?下表为你梳理:
| 产品 | 核心特点 | 适合场景 |
|---|---|---|
| Milvus | 开源、功能全面、性能强悍、生态丰富。支持多种索引和混合查询。 | 通用首选,尤其适合需要自建、定制化高、数据规模大的企业级应用。 |
| Pinecone | 全托管云服务,极致易用,开箱即用,无需运维。 | 初创团队或云原生应用,追求快速上线,无运维负担。 |
| Qdrant | 开源,API设计友好,用Rust编写性能好,支持过滤丰富。 | 需要精细过滤条件的检索场景,开发者体验好。 |
| Weaviate | 开源,更像一个“智能数据湖”,内置向量生成模块,支持图关联。 | 希望将向量检索与知识图谱结合的多关系查询场景。 |
| Elasticsearch | 传统搜索引擎巨头,其向量检索插件让其能同时进行全文检索+向量检索。 | 已有ES生态,需要将关键词搜索和语义搜索结合的场景。 |
| Faiss | Facebook开源的向量检索库,严格来说不是数据库,但效率极高。 | 需要将检索能力嵌入到现有应用或服务中,进行深度定制。 |
选型建议:
- 刚入门,想快速验证想法:从 Milvus (Docker) 或 Pinecone (免费额度) 开始。
- 大规模生产环境,需要自主可控:Milvus 集群版是不二之选。
- 已有Elasticsearch,想增强语义能力:使用 ES的向量插件。
- 研发实力强,需要极致定制:考虑 Faiss 自研封装。
总结与展望
向量数据库的本质,是为AI时代非结构化数据的“理解”和“检索”提供了原生支持。它填补了传统数据库与AI应用之间的鸿沟。
- 当前价值:已成为RAG检索增强生成、AI Agent记忆、内容推荐、多模态搜索等核心场景的标配。
- 未来趋势:
- 多模态融合:统一处理文本、图像、音频、视频的跨模态检索将成为常态。
- 与LLM深度集成:向量数据库将不仅是“外挂记忆”,而可能与推理过程更紧密耦合,成为“思考过程”的一部分。
- 实时性与流处理:支持对动态变化的数据(如实时对话、传感器数据)进行实时向量化与检索。
- 开发体验简化:更多像【LLaMA-Factory Online】这样的一体化平台出现,降低AI应用开发的全链路门槛。
无论你是算法工程师、后端开发者还是产品经理,理解并善用向量数据库,都将成为构建下一代智能应用的必备技能。希望这篇近5000字的指南,能成为你探索这个精彩世界的可靠地图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号