


显示计划(Showplan)是表示由查询优化器生成的文本、图形或XML格式的查询计划的术语。他包含了有关SQL Server如何处理查询的信息,对查询计划中的每个表,显示计划可以告诉你是否使用了索引,或者是否有必要执行表扫描,以及不同操作的执行顺序。
在本系列随笔的2.1中对一个显示计划做了初步的分析。
SQL Server2005可以生成三种不同格式的显示计划:图形、文本和XML。
在计划内容方面,SQL Server可以生成只包含运算符的计划,包含估计成本的计划,以及包含运行时信息的计划。下表列出了生成不同格式计划的命令:
| 内容 | 格式 | ||
| 文本 | XML | 图形 | |
| 运算符 | SET SHOWPLAN_TEXT ON | N/A | N/A |
| 运算符和估计成本 | SET SHOWPLAN_ALL ON | SET SHOWPLAN_XML ON | 在企业管理器中“显示估计的执行计划” |
| 运行时信息 | SET STATISTICS PROFILE ON | SET STATISTICS XML ON | 在企业管理器中“包含实际的执行计划” |
首先看一个简单的查询:
SET NOCOUNT ON;
USE Northwind;
GO
SET SHOWPLAN_TEXT ON;
GO
SELECT ProductName, Products.ProductID
FROM dbo.[Order Details]
JOIN dbo.Products
ON [Order Details].ProductID = Products.ProductID
WHERE Products.UnitPrice > 100;
GO
SET SHOWPLAN_TEXT OFF;
GO
运行结果:
StmtText
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SELECT ProductName, Products.ProductID
FROM dbo.[Order Details]
JOIN dbo.Products
ON [Order Details].ProductID = Products.ProductID
WHERE Products.UnitPrice > 100;
StmtText
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
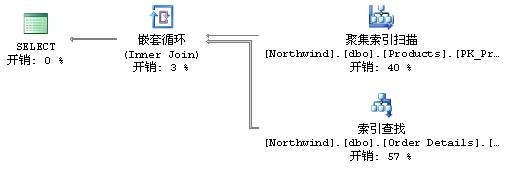
|--Nested Loops(Inner Join, OUTER REFERENCES:([Northwind].[dbo].[Products].[ProductID]))
|--Clustered Index Scan(OBJECT:([Northwind].[dbo].[Products].[PK_Products]), WHERE:([Northwind].[dbo].[Products].[UnitPrice]>($100.0000)))
|--Index Seek(OBJECT:([Northwind].[dbo].[Order Details].[ProductID]), SEEK:([Northwind].[dbo].[Order Details].[ProductID]=[Northwind].[dbo].[Products].[ProductID]) ORDERED FORWARD)
输出结果表明:该查询由三个运算符组成:Nested Loops、Clustered Index Scan、Index Seek。
首先看第一句:
|--Nested Loops(Inner Join, OUTER REFERENCES:([Northwind].[dbo].[Products].[ProductID]))
Nested Loops对两个表进行内部联接,且外部表为Products表。
然后是:
|--Clustered Index Scan(OBJECT:([Northwind].[dbo].[Products].[PK_Products]), WHERE:([Northwind].[dbo].[Products].[UnitPrice]>($100.0000)))
SQL Server使用Clustered Index Scan访问物理数据,这里扫描聚集索引相当于描述整个表。
最后是:
|--Index Seek(OBJECT:([Northwind].[dbo].[Order Details].[ProductID]), SEEK:([Northwind].[dbo].[Order Details].[ProductID]=[Northwind].[dbo].[Products].[ProductID]) ORDERED FORWARD)
SQL Server使用Index Seek访问索引行,其中的Object显示了索引的完整名称。Seek是查找谓词,这里是要根据外部表的ProductID来进行索引查找。
当执行计划时,数据的传递通常是从右到左,从上到下的。缩进多的运算符生成行供缩进少的运算符使用。在这里,Clustered Index Scan运算符和Index Seek运算符是缩进最多的,且Clustered Index Scan在Index Seek的上面,所以先运算Clustered Index Scan,然后是Index Seek,最后是Nested Loops。
运行示例还可以注意到,当使用了SET SHOWPLAN_TEXT ON后,会阻止执行查询。
XML格式的显示计划
有两种格式的显示计划。一个是SET SHOWPLAN_XML ON,他将包括估计的执行计划。另一个是SET STATISTICS XML ON,他包含运行时的信息。
生成XML格式的显示计划可以通过以下方法:
1. 上面写的这两个指令,其中SET SHOWPLAN_XML ON在编译批处理时生成,它为整个批处理生成一个XML文档;而SET STATISTICS XML ON在运行时产生输出,他为批处理中的每个语句生成单独的XML文档。
2. 使用企业管理器的“显示图形化显示计划”。
3. 使用SQL Server Profiler。
名为Showplanxml.xsd的XML Schema描述了包括编译时估计、运行时的XML显示计划。在运行时,XML显示计划提供了一些额外的信息。这个文件在安装完SQL Server 2005后,被放置在Microsoft SQL Server"90"tools"Binn"schemas"sqlserver"2004"07"showplan目录下。
XML格式的显示计划的内容最详细,包含了计划大小(CachePlanSize属性),和优化该计划是用到的参数值(ParameterList元素),而且只有运行时XML显示计划才包含并行计划中不同线程所处理的行数(RunTimeCountersPerThread元素的ActualRows属性),以及执行查询时的实际平行度(DegreeOfParallelism属性)。
图形化的显示计划
在企业管理器中,有“显示估计的执行计划”和“包括实际的执行计划”两种图形化的显示方法。
显示估计的执行计划:点选后,在结果窗口会立刻显示图形化执行计划。
包含实际的执行计划:点选后,不会立刻显示计划,而是在点击执行后,将实际的计划结果显示出来。
无论使用上面哪种方式图形显示计划,都会显示下面的图形:
但可以想到他们之间存在的区别,当查看运算符的详细信息时:
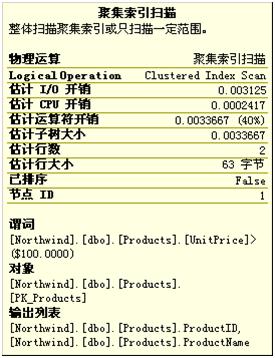
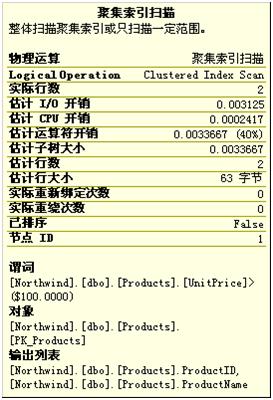
因为“包含实际的执行计划”,所以会给出实际运行时的一些信息。
右键->计划另存为,还可以将显示计划保存为XML显示计划。扩展名为sqlplan。
显示计划中的运行时信息
SET STATISTICS XML ON|OFF
XML显示计划包含两种运行时信息:每个SQL语句的信息和每个线程的信息。如果语句有参数,它的计划将包含ParameterRuntimeValue属性,表示该语句被执行时每个参数的值。它可能不同于编译该语句时用到的值(ParameterCompiledValue属性),但只有优化器在优化并知道该参数值时,该属性才会出现在计划中,且只与传递到存储过程的参数有关。
DegreeOfParallelism属性表示此次执行的实际平行度(或DOP,它是单个查询的并发线程数)。它可能与编译时计算的值不同,在编译期间,查询优化器假设为当时的工作负荷为CPU的一半。在执行时,DOP的值会根据执行时开始的工作负荷被调整。如果执行并行计划时DOP=1,当创建执行上下文时,SQL Server将从查询计划中移除Exchange运算符。MemoryGrant属性表示以KB为单位的用于执行该查询的实际内存。SQL Server使用这些内存为哈希联接(hash Join)生成哈希表或在内存中执行排序。
RunTimeCountersPerThread元素包含5个属性,每个线程都有相应的值:ActualRebinds、ActualRewinds、ActualRows、ActualEndofScans、ActualExecutions。ActualExecutions值告诉我们该运算符在每个线程中被初始化的次数。如果运算符是一个扫描运算符,ActualEndofScans表示扫描到达数据集结尾的次数。所以用ActualExecutions-ActualEndofScans就可以得到运算符没有扫描的次数。如:如果SELECT中使用TOP限定了返回的行数,则输出集合将在扫描到达表的结尾之前被收集。
SET STATISTICS PROFILE ON
这个指令返回的计划与SET SHOWPLAN_ALL ON相比有两个区别。他在输出中包含了另外的两列:Rows和Executes。
Rows :是所有线程的RunTimeCountersPerThread元素RowCount属性的合计,他告诉我们每个运算符实际返回的行数。
Executes:是该元素中ActualExecutions属性的合计,他告诉我们SQL Server为处理一行或多行而初始化该运算符的次数。

当检查某个查询计划时,可以找到查询优化器的估计行数与实际行数之间的最大差异。EstimateRows列是每次执行所估计的输出行数,而Rows是运算符所有执行返回的累积行数。因此我们可以先把EstimateRows乘以EstimateExcutions,在把它与SET STATISTICS PROFILE输出的Roes列中返回的实际总行数做比较。
用SQL跟踪捕获显示计划
使用跟踪来捕获显示计划是非常精确的,这样可以避免在企业管理器中观察到的计划和在应用程序执行起来使用的实际计划之间产生的差异。最常见的,如:用不同的参数调用同一个存储过程、统计信息被自动更新、在编译和运行之间的可用资源(CPU或内存)发生变化。
使用跟踪进行监视非常消耗资源,监视的事件越多,影响越严重。
下表显示了9类性能事件:
| 跟踪事件类 | 编译或运行 | 是否包含运行时信息 | 是否包含XML显示计划 | 是否为SQL Server 2000生成跟踪 |
| Showplan ALL | 运行 | 否 | 否 | 是 |
| Showplan All for Query Compile | 编译 | 否 | 否 | 否 |
| Showplan Statistics Profile | 运行 | 是 | 否 | 是 |
| Showplan Text | 运行 | 否 | 否 | 是 |
| Showplan Text(未编码) | 运行 | 否 | 否 | 是 |
| Showplan XML | 运行 | 否 | 是 | 否 |
| Showplan XML for Query Compile | 编译 | 否 | 是 | 否 |
| Showplan XML Statistics Profile | 运行 | 是 | 是 | 否 |
| Performance Statistics | 编译和运行 | 是 | 是 | 否 |
如果在开发或调试中,应该使用Showplan XML Statistics Profile事件。它生成所有的查询计划和运行时信息。
即使你的服务器很忙,如果设计了有良好的计划重用率的查询,因为编译率较低,也可以使用Showplan XML For Query Compile事件。他只在有存储过程或语句被编译或重新编译时才生成跟踪记录,但不包括运行时信息。
通过为各个列设置筛选值可以减少跟踪的大小。在设置跟踪筛选器时,只有ApplicationName、ClientProcessID、HostName、LogionName、LogionSid、NTDomainName、NTUserName和SPID这些列上应用筛选器会抑制时间的生成。其他筛选器只有在时间被生成并到达客户端后才会应用,所以并不能减少服务器的开销,事实上会造成更多的开销。
另外,相对于在企业管理器中使用显示计划,显示计划跟踪事件进一步扩大了SQL Server所能捕获计划的语句集合。如:CREATE、INSERT INTO … EXEC语句等。
从过程缓存中提取显示计划
上面已经介绍,SQL Server当生成计划后,会把它保存到过程缓存之中。我们可以用几个动态管理视图和函数、DBCC PROCCACHE、以及目录视图sys.syscacheobjects来检查过程缓存。
Sys.dm_exec_query_plan (DMF)以XML格式返回位于过程缓存的计划。DMF要求一个计划句柄作为唯一的参数。计划句柄是一个VARBINARY(64)类型的查询计划标识符,DMV为当前过程缓存中每个查询都可以返回该标识符。
看一个示例:
SELECT qplan.query_plan AS [Query Plan]
FROM sys.dm_exec_query_stats AS qstats
CROSS APPLY sys.dm_exec_query_plan(qstats.plan_handle) AS qplan;
这个查询为所有缓存的查询计划返回XML显示计划。
但是想这样找到某个查询计划非常困难,因为查询文本被包含在XML显示计划内部。下面的查询使用Xquery value方法从显示计划中提取出序列号(No列)和查询文本(Statement Text列)。因为每个批处理都有sql_handle,所以用ORDER BY sql_handle可以按这些语句在批处理中的顺序进行排序显示。
WITH XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sql)
SELECT
C.value('@StatementId', 'INT') AS [No],
C.value('(./@StatementText)', 'NVARCHAR(MAX)') AS [Statement Text],
qplan.query_plan AS [Query Plan]
FROM (SELECT DISTINCT plan_handle FROM sys.dm_exec_query_stats) AS qstats
CROSS APPLY sys.dm_exec_query_plan(qstats.plan_handle) AS qplan
CROSS APPLY query_plan.nodes('/sql:ShowPlanXML/sql:BatchSequence/sql:Batch/ sql:Statements/ descendant::*[attribute::StatementText]') AS T(C)
ORDER BY plan_handle, [No];
运行结果:
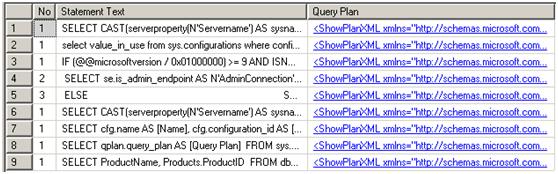
更新计划
当优化INSERT、UPDATE、DELETE这些数据修改语句时,优化器必须要处理几个特殊的问题。IUD计划(INSERT、UPDATE、DELETE)包括两个阶段。
第一个阶段:通过生成用于描述数据更改的数据流来确定哪些行将被IUD。对于INSERT,数据流包含列值,对于DELETE,它包含表键,对于UPDATE,他既包含表键也包含被修改的列的值。
第二个阶段,把数据流中的描述的更改应用到表,通过执行约束验证保证数据完整性,它维护非聚集索引和索引视图,如果存在触发器则引发触发器。
UPDATE和DELETE查询计划通常还包含两个对目标表的引用:第一个引用用于标识受影响的行,第二个引用执行更改的地方。INSERT计划只包含一个对目标表的引用。
在一些简单的情况是,SQL Server把IUD计划的两个阶段合并在一起。如:把值直接插入表,成为标量插入,或者更新/删除由目标表主键标识的行。
如果SQL Server需要执行约束验证,则在第二个阶段会自动包含Assert运算符。SQL Server通过在受影响的行和列上计算一个通常成本较低的标量表达式为INSERT和UPDATE验证CHECK约束。
对包含外键约束的表执行INSERT和UPDATE会强制验证CHKECK约束,而且对包含被引用的表所执行的INSERT和UPDATE也会强制验证外键约束。为验证约束,即使不是IUD操作目标的相关表也被扫描。声明主键将自动地在该列创建唯一的索引,但外键不一样,对被引用的外键列执行UPDATE和DELETE必须为每个被更新或删除的主键值访问外键表。如果这个约束是一个级联引用完整性约束,那么将会执行更改,否则将验证被删除的键是否存在。因此,要对键值执行UPDATE或对主表执行DELETE,那么应该确保外键上存在索引。
在处理INSERT和DELETE语句时,除了在聚集索引或堆上执行IUD操作,还会维护所有非聚集索引,UPDATE查询还维护包含被修改列的索引。因为非聚集索引包含聚集索引键和分区键以允许高效地访问数据行,所以更新那些参与聚集索引键或分区键的列成本很高,因为它会修改或重建所有索引。更新分区键还会导致行在分区之间的移动。因此,如果可能的话,应该选择不更新的列作为聚集键或分区键。
总的来说,IUD语句的性能与包含目标列的索引数量密切相关,因为他们将会被重建或修改。对索引执行单行INSERT和DELETE操作要求遍历一次索引树。SQL Server更新索引键和分区键的方法是先执行DELETE再执行INSERT,所以在索引操作上,UPDATE的成本比INSERT和DELETE要多一倍。
查询优化器执行IUD语句时有两种不同的策略:每行维护和每索引维护。
首先使用这个文件准备参考数据:3.rar
然后来看两个查询
查询1:
DELETE FROM dbo.Orders WHERE OrderDate = '2002-01-01'
更新计划:

这就是一个每行查询的例子,SQL Server为该查询所影响的每一行同时维护索引和基表(基表=堆或聚集索引),并且对所有非聚集索引的更新将与对基表中每一行的更新同时执行。这个查询计划没有对第2个索引执行任何删除操作,因为这些工作在聚集索引删除运算符的计算是同时完成。
查询2:
DELETE FROM dbo.Orders WHERE OrderDate < '2006-01-01'
更新计划:
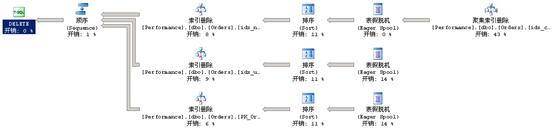
这个查询2与查询1的更新计划完全不同,因为它执行的是每索引维护。
首先,该计划从聚集索引中删除符合条件的行,同时构建一个临时的假脱机表(spool table),其中包含必须进行维护的三个非聚集索引的键值。SQL Server为每个索引读取一次假脱机数据。在读取假脱机数据和从非聚集索引中删除行之间,SQL Server按被维护索引的顺序排序假脱机数据,以确保对索引页的最佳访问。
Sequence运算符强制其分支的执行顺序,在这里索引的按从上倒下的顺序进行删除。
每行更新策略在CPU方面是高效的,因为同时更新表和所有索引只需很短的代码路径。每索引维护的代码稍微有些复杂,但这样更节省I/O。如果对键排序后再单独更新非聚集索引,即使同一页中有许多行都被更新,我们也只须访问索引页一次。这也就是为什么SQL Server查询优化器认为每行策略需要多次读取被维护索引的同一页才能完成维护,这时它通常选择每索引维护策略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号