
面向对象第二单元总结
面向对象第二单元总结
1. 同步块和锁的设置与选择
第一次作业
第一次作业我程序的架构相对简单,整个程序由输入线程,等候队列,电梯线程和电梯控制器构成。具体结构如下图所示:
出入线程把数据放入waitingList,而后电梯控制器控制电梯从waitingList中取出对象并放入电梯的乘客队列,同时电梯控制器还需要控制电梯的开关门、上下移动。
注意,这里的输入线程和waitingList实际上是合在了一起写的,这个写法可扩展性很差,所以在第二次作业中最这个地方进行了重构。
从图中可以看出,作业一的两个线程通过waitingList这个共享对象进行信息共享,其中inputThread对waitingList进行只写操作,电梯线程从waitingList中进行读写操作。因此我使用了synchronized锁对如下的位置进行了加锁:
- waitingList中的addPersonRequest和romovepersonRequest方法对自身加锁。则两个方法作为同步块。
- 电梯控制器中对等候队列的请求进行遍历操作对waitingList加锁,所有遍历操作都需要在同步块中进行。
- 电梯对等候队列中的请求遍历加锁
当等候队列中没有请求,电梯内部也没有请求时,电梯检测waitingList的end位,如果输入还没有结束,电梯线程等待。每当输入线程向waitingList中输入请求时,waitingList中的addPersonRequest方法最后会notifyAll,唤醒等待的电梯。如果检测到输入结束,则把waitingList中的boolean变量end置位,同时唤醒电梯。
第二次作业
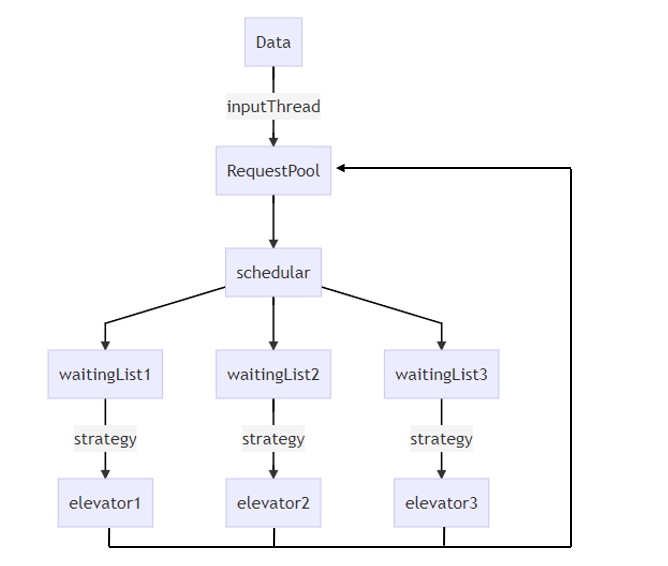
第二次作业架构比第一次作业更加复杂,增加了两个共享对象,因此加锁和同步块也更加复杂。架构如图所示
从中可以看出,相比于第一次作业,增加了personrequestPool和elevatorRequest两个共享对象,但由于这是典型的生产者消费者模式,输入线程写入数据,调度器读出数据,并且每次读取队首的数据即可,所以我使用了ArrayBlockingQueue来解决加锁的问题。这样简化了我的代码。对于waittingList这个共享对象,直接使用了作业一的代码,加锁方式同上。
第三次作业
第三次作业的架构和第二次作业仅增加了由电梯把请求写回personRequestPool,而personRequestPool由ArrayBlockingQueue实现,本身就是线程安全的,因此没有增加额外的锁与同步块
总结
对于很多同学都遇到的死锁问题,我通过分段式的设置结构,保证两个进程之间最多只有一个共享对象,并且存在共享数据的进程没有形成环,另外尽可能使用java已有的线程安全的类。避免了死锁的发生。
对共享对象的读写操作一般来说是一定要加锁的。但是为了能够减少临界区代码,提升运行效率,我在共享对象内部动态维护了很多指标,使得调用者不需要在临界区内计算这些指标,提升了效率。
2.三次作业中的调度器设置
第一次作业
第一次作业因为之有一个电梯,所以我只写了电梯的控制器,而没有写请求的调度器。
电梯的调度器我主要采用了look算法,下面我分模式介绍:
morning:
该模式下,一层的所有请求进行排序,每次选取最高的几个请求运送。进行的小优化有:
- 如果电梯在一层并且电梯内有人未满,等候队列中那个无请求,但是输入还没有结束,进行如下操作:如果电梯内的请求最高运输楼层大于等于4并且电梯内的人数小于等于3人,就不等候,否则等待新的请求。
- 如果电梯内和等候队列无人,电梯停留在1层并开门
night
电梯运行到有等待请求的最高层,无条件尽可能多的接人,然后从这层开始向下运行。
之后的除了一层之外的每一层,如果当前楼层等候人数是电梯容量的整数倍,就不开门直接向下;否则尽可能多的接人,让这层的等待人数达到原等待人数按照电梯容量向下对其的人数或电梯满人停止进人。
电梯到达一层开门,所有人出去,关门
random
采用look算法,每次电梯尽可能到达自身运行方向上的最远地点,而后如果仍有人需要接送,则改变电梯运送方向。其中,最远地点指的是电梯内请求目的地的最远楼层和所有请求的最远楼层,两者取最远的。
look算法的捎带策略为:对于每一楼层,只要电梯内不满,这层等候队列中存在与电梯运行方向相同的请求,就捎带。
进行的一点小优化为:如果当前所有请求已经处理完毕但是输入还没有结束,就让电梯停留在10层。
第二次作业
第二次作业增加了调度器用于把输入的请求分配给每个电梯的等候队列。在电梯的控制器方面,我直接使用了上一次的代码,控制电梯如何从自身唯一对应的等候队列中去取出请求并运行。下面主要叙述作业二的调度器算法。
调度器采用了三级评估的方法,逐级决定把请求分配给哪个电梯。
-
首先判断在每个电梯的等候队列中是否有与当前请求起点终点都相同的请求,若存在,并且该电梯存在多余的运力,不会因为这个请求的加入而导致电梯多跑一趟,就把这个请求分配给它。若没有分配,就看二级分配策略
-
如果每个电梯的等候人数明显少于其他所有电梯,这里我认为电梯等候人数少于所有电梯等候人数平均值的0.5倍就是明显少于。这种情况下直接把请求分配给他,否则进入下一级评估。
-
把请求加入预估完成所有已有的运输请求时间最少的电梯。估计运输所需时间的方法如下:统计经过每个运输区间的请求次数,按照区间把请求数量除以6向上取整,变为电梯经过每个区间的最少次数。把这些次数根据look算法的特点,变换为单调不降然后紧接着单调不增的队列。随后对于每一位,取向上运输次数和向下运输次数的最大值。这样,数组元素之和乘以每层运输时间就等于了运输所需时间。再加上估计的开关门时间,就得到了总的运输等候队列中的人的时间。而对于已经在电梯内的人,运输他们的时间是很好估计的,只需要动态维护乘客的目的地集合就可以。
通过以上方法,我们估计除了每个电梯的完成运输的时间,只需要把这个请求分配给用时最短的就可以了
其实第三种预测方案就足以解决所有的预测需求,但考虑到第三个方案计算量很大,所以我就在一些相对显然的情况下使用了计算量较小的贪心方法,直接指定分配对象。
第三次作业
第三次作业沿用了第二次作业的调度方法,但进行改进,使之支持换乘。
同时,处于支持换成的考虑,在电梯的控制方面,沿用了第一次的random模式,无论哪个模式的电梯控制都采取该方法。
我使用myPersonRequest代替助教给出的personRequest类,新增加了当前的起点和终点,方便换乘。调度器需要分配请求的时候需要指定该请求在当前电梯运行的起点与终点,这个终点不一定和最终的终点一致。
在调度策略选择上,我依然是按照作业二的三级评估方法。对于前两级评估,如果找到的电梯不满足于当前请求(例如人数最少的是C电梯,但是请求楼层4-16),就进入第三级判断。在第三级评估中,把所有人电梯按照他们的时间从小到大进行排序,从小到大进行遍历,寻找到第一个符合条件的电梯就把请求放进去,然后结束评估。其中,对于符合条件的定义:如果电梯能够运输到最终目的地楼层,则一定符合;若C电梯可以运输1-5和15-20之间的移动的人,B电梯可以把终点为偶数的人放在最终目的地的旁边。
3. 第三次作业架构设计
UML类图

UML顺序图
架构简述与分析
从功能性角度来说,第三次作业还是比较完善的,很好的完成了需要完成的任务。第三次作业以”生产者-消费者“模型为基础搭建,支持对请求的电梯分配,目的分配。再分配过程中,无论是对电梯等候队列的查询、统计、插入、删除,还是对电梯乘客队列的查询、统计都是被允许的。
从可扩展性角度来说,我认为程序架构十分合理,能够在一定程度上支持更复杂的电梯。我们不妨设想一下还可能有什么新的任务:例如需要支持请求发出后突然撤销,或者请求更改楼层,这些在当前架构下都是可以实现的。但是当前架构的问题在于waitingList类的功能已经远远超过一个只用于装请求信息的类,而变成了一边支持写入读出删除请求信息,一遍对这些请求信息做大量的统计,把很多scheduler和strategy的工作抢了过来。这样固然能够提高效率,在电梯运行的时候异步计算,但是无意中提升了这些类之间的耦合度。所以如果要对当前架构进行扩展,可能需要对waitingList进行一下改动。
4. bug分析
第一次作业
第一次作业的问题主要在于我第一次使用状态模式,没有很好的界定好每个状态之间的功能。在random模式下,如果电梯已满,电梯到达某一楼层,尚且处于关门状态。关门状态下,电梯控制器检测到门外有需要进入的请求(条件是和电梯同向运动),就直接开门,进入开门状态。开门状态下,调用elevator的personIn方法,让请求进入。但由于此时电梯已满,实际上没有人能够进来,之后电梯关门,外面的等候请求不变,进入关门状态。由此电梯陷入了死循环。
解决方案很简答,只需要在电梯开门接人之前判断电梯是否满员即可。如果电梯满员并且没有人下去,则无论外面有没有人都不开门。
else if (this.elevator.getPassengerNumber() < 6 && waitingPeople //第一次忘记加了这个判断条件
.getRequestList()[currentFlour].stream().anyMatch(personRequest ->
personRequest.getToFloor() > personRequest.getFromFloor())) {
open = true;
第二次作业
无bug
第三次作业
在morning模式中的scheduler调度器中,分情况讨论了在每种情况下如何分配请求,但由于分类情况过于复杂,所有分类的并集没有覆盖全集,缺少“兜底”的分配策列,导致两个点对空指针进行了引用,挂掉了。所以说,当面对很多情况分类讨论时,一定要在纸上列出来,最好用逻辑的方式形式验证,确保能够覆盖所有情况。
else {
if (!elevator.getType().equals("A")) {
elevator = elevatorArrayList.stream().filter(elevator1 -> elevator1.getType()
.equals("A"))
.findFirst().orElse(null);
}
elevator.getWaitingPeople().add(myPersonRequest);
}
第一次提交的时候缺少这里的”兜底“分配情况。
bug总结
从上面可以看出,bug的产生主要产生在相对陌生的知识点中。例如第一次作业中我第一次使用状态模式,测率与状态相互叠加,非但代码发咋读高,还把这复杂的控制电梯的代码拆分到了两个状态内,要求这两个状态相互配合,实在不是一个好的写法。后来反思,越是复杂的,耦合度高的代码,就应当把他们写在一个类里。如果要使用状态模式的话,可以考虑把电梯控制的代码写好封装到一个方法类里,而后每个状态去调用方法类的方法,实现控制。
第二次作业之所以不出bug,可能是因为第二次对第一次的重构其实不多,最多的是在前面增加了分配器。而分配器的代码虽然复杂,但每个方法里的决策判断也就是按照面向过程的方法来写的,所以出bug的概率并不大。
第三次作业的bug原因,分类讨论没有覆盖全集,如果在没有评测的情况下单凭人眼很难看出来。即便是使用评测机,如果测试数据不够充分呢,也难以发现问题。这就对写之前的构思提出了很高的要求,一定要想好再写,不可写到哪算哪,那样很容易缺少情况。
5.找出别人的bug的策略
这次给我的感觉就是很你能找到别人的bug。首先我三次都进入了A房间,同房间的人基本正确性存在的问题不大。我在第一次作业尝试使用手动构造的样例hack别人,在本地由一组数据hack中了,但提交之后显示通过。于是之后考虑到我其他的事情太多了,于是乎后两次直接放弃了互测debug。
6. 心得体会
-
这次作业明显感觉自己的架构设计能力提升了很多。从始至终都没有经历过重构,只是在上一次的基础上进行适当的增删。
-
优化可以,但是不要过分牺牲代码的简洁度。我两次都挂在了过分优化上,这导致代码十分庞大,并且只有一点小地方没有考虑周全,自己测试找bug的难度也陡然增加。
-
这次作业感觉自己越来越熟练了,对面向对象的感觉更好了
-
一定要课下充分测试啊,实在是太亏了,辛辛苦苦写的代码,因为几个字母,扣了几十分,啊啊啊啊啊啊~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号