
Linux系统编程
一、一些生活中遇到的知识
1、a进程存在内存泄露,会对b进程造成什么影响?
背景知识:
(1)swap分区的含义
swap分区是一块特殊的磁盘空间,用于扩展系统的物理内存。当物理内存不足时,会将系统部分暂时不使用的数据移动到swap分区中,从而释放物理内存空间(RAM),以供其他进程使用。
(2)swap分区的作用
a) 扩展虚拟内存:当物理内存(RAM)不够时,swap做为后备存储,放置系统因为内存不足而出现的崩溃问题;大小一般为2倍的物理内存大小。。
b) 支持休眠:系统休眠时,可以将物理内存中的数据拷贝到swap分区中,此时需要保证swap空间至少等于物理内存大小;
c) 内存管理优化:内核可以将长时间未使用的内存页移到swap中,以提高内存的利用率。
(3)swap分区的类型
a) swap分区:独立的磁盘分区,专门用于swap。可使用shell命令,如fdisk或parted创建一个swap分区,使用mkswap /dev/sda3 格式化分区,使用swapon /dev/sda3 启用swap。注:会有安全问题,要及时的清空swap分区中的数据;可以禁用swap分区,但会触发OOM。
b) swap文件:普通文件,如/swapfile,更加的灵活,无需调整分区,直接删除文件来扩大swap文件的大小。
解答:由于a进程存在内存泄露,虽然进程间是独立的虚拟内存空间,a进程内存不会影响到b进程的内存空间,但是会通过物理内存耗尽来间接的影响到b进程。当物理内存不够的时候,就会使用swap空间,由于swap空间位于磁盘,频繁的读写磁盘会出现性能问题,使b进程运行卡顿,如果是对实时性要求比较高的系统,如支付系统,会造成比较大的影响。
解决方法:使用top、htop、vmstat实时监控内存使用情况、使用cgroups或容器技术(如Docker)限制a进程最大内存使用量、使用ssd作为swap存储(而不是机械硬盘)
推荐书籍:鸟哥的linux私房菜:基础学习篇、linux内核的设计与实现、深入理解linux内核、Unix/Linux系统编程手册、性能之巅、Linux系统编程。
Q1:如何将swap分区添加到/etc/fstab?


1 #1、确定swap分区的UUID或设备名字(如/dav/sda2) 2 sudo blkid 3 #显示结果如下: 4 /dev/sda2: UUID="1234-5678" TYPE="swap" 5 6 #2 编辑/etc/fstab文件 7 vi /etc/fstab #或使用其他文件编辑器:vim、nano 8 #在该文件的末尾追加下面的一行: 9 UUID=1234-5678 none swap sw 0 0 10 或者使用设备名字: 11 /dev/sda2 none swap sw 0 0 12 解析如下: 13 UID=1234-5678 或 /dev/sda2: 分区的标识符。 14 15 none: 挂载点,对于 swap 分区通常留空。 16 17 swap: 文件系统类型。 18 19 sw: 挂载选项,通常为 sw 表示启用 swap。 20 21 0: dump 备份操作的控制标志(通常为 0)。 22 23 0: fsck 检查的顺序(在启动时检查文件系统时的顺序,对于 swap 通常为 0)。 24 25 #3 启用swap分区 26 swapon -a 27 #4 验证swap分区是否启用 28 swapon -s 29 #或者查看文件 30 cat /proc/swaps
11
二、进程间通信
1、管道
为什么要引入管道?
不同进程间通过加锁和解锁操作同一个文件,也可以实现进程间同步,但是这种方式需要访问磁盘文件系统,代价很高。管道使用系统调用,可以不与文件系统打交道就可以支持进程通信。
适用场景
生产者消费者场景。
1.1、无名管道pipe
单向通信,只适用于具有亲缘关系的进程间通信,如父子进程。
存储在内核内存中,不占用磁盘空间,创建的管道文件随进程销毁而销毁。
创建方法:使用pipe()创建,返回两个文件描述符fd[0]读、fd[1]写。注:半双工通信方式体现在进程0只可以操作fd[0]、另一个文件描述符fd[1]需要close,此时进程1可以操作写操作符fd[1]、不可以操作读操作符fd[0],此时需要将进程0的fd【0】关闭。
实例:
1 #include <unistd.h> 2 #include <stdio.h> 3 void main() 4 { 5 int fildes[2]; 6 pid_t pid; 7 int i, j; 8 char buf[256]; 9 if ( pipe( fildes ) < 0 ) 10 { 11 fprintf( stderr, "pipe error!/n" ); 12 return; 13 } 14 if ( (pid = fork() ) < 0 ) 15 { 16 printf( stderr, "fork error!/n" ); 17 return; 18 } 19 if ( pid == 0 ) //子进程的进程id为0 20 { 21 close( fildes[0] ); 22 memset( buf, o, sizeof(buf) ); 23 j = read( fildes[0], buf, sizeof(buf) ); 24 fprintf( stderr, "[child] buf =[%s] len [%d] /n", buf, j ); 25 return; 26 } 27 28 close( fildes[0] ); 29 write( fildes[1], "Hello!", strlen( "Hello!" ) ); 30 write( fildes[1], "World!", strlen( "World!" ) ); 31 }
实例2:
1 #include <stdio.h> 2 #include <unistd.h> 3 #include <string.h> 4 #include <sys/wait.h> 5 6 int main() 7 { 8 int pipefd[2]; // pipefd[0]读端, pipefd[1]写端 9 pid_t pid; 10 char buf[100]; 11 12 // 创建无名管道---使用pipe创建的管道文件随进程的结束而销毁 13 if (pipe(pipefd) == -1) 14 { 15 perror("pipe"); 16 return 1; 17 } 18 19 pid = fork(); // 创建子进程 20 if (pid < 0) { 21 perror("fork"); 22 return -1; 23 } 24 25 if (pid == 0) 26 { 27 // 子进程(读数据) 28 close(pipefd[1]); // 关闭写端 29 read(pipefd[0], buf, sizeof(buf)); 30 printf("Child received: %s\n", buf); 31 close(pipefd[0]); 32 } 33 else 34 { 35 // 父进程(写数据) 36 close(pipefd[0]); // 关闭读端 37 const char *msg = "Hello from parent via unnamed pipe!"; 38 write(pipefd[1], msg, strlen(msg) + 1); 39 close(pipefd[1]); 40 wait(NULL); // 等待子进程结束 41 } 42 return 0; 43 }
gcc unnamed_pipe.c -o unnamed_pipe && ./unnamed_pipe
1.2、有名管道fifo
单向或双向(需要创建两个fifo)通信,不具有亲缘关系的进程也可以进程通信。以特殊文件的形式存储在文件系统中(如/tmp/myfifo),有磁盘索引节点,故任何进程都可以访问fifo文件,fifo文件可以手动删除。
创建方法:mkfifo()或mkfifo命令,可以使用unlink()删除。
实例1:
写进程代码:
1 #include <stdio.h> 2 #include <sys/types.h> 3 #include <sys/stat.h> 4 #include <sys/errno.h> 5 extern int errno; 6 void main() 7 { 8 FILE *fp; 9 char buf[255]; 10 /*创建管道,如果已存在则跳过*/ 11 if ( mkfifo( "myfifo", S_IFIFO | 0666 ) < 0 && errno != EEXIST ) 12 return; 13 while ( 1 ) 14 { 15 if ( (fp = fopen( "myfifo", "w" ) ) == NULL ) 16 return; /*打开管道*/ 17 printf( "please input:" ); 18 gets( buf ); 19 fputs( buf, fp ); 20 fputs( "/n", fp ); 21 if ( strncmp( buf, "quit", 4 ) == 0 ) 22 || strncmp( buf, "exit", 4 ) == 0) 23 break; 24 fclose( fp ); 25 } 26 }
读进程代码:
1 #include <stdio.h> 2 #include <fcntl.h> 3 #include <stdio.h> 4 void main() 5 { 6 FILE *fp; 7 char buf[255]; 8 while ( 1 ) 9 { 10 if ( (fp = fopen( "myfifo", "r" ) ) == NULL ) 11 return; 12 fgets( buf, sizeof(buf), fp ); 13 printf( "gets:[%s]", buf ); 14 if ( strncmp( buf, "quit", 4 ) == 0 || strncmp( buf, "exit", 4 ) == 0 ) 15 break; 16 fclose( fp ); 17 } 18 }
注:使用read()和write()操作myfifo文件也可以。
实例2:
写进程(write.c):
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <unistd.h> 4 #include <sys/stat.h> 5 #include <fcntl.h> 6 #include <string.h> 7 8 #define FIFO_PATH "/tmp/my_fifo" 9 10 int main() 11 { 12 int fd; 13 char *msg = "Hello from writer via named pipe!"; 14 15 // 创建FIFO(若已存在则忽略) 16 mkfifo(FIFO_PATH, 0666); 17 18 // 打开FIFO(写入模式) 19 fd = open(FIFO_PATH, O_WRONLY); 20 if (fd == -1) 21 { 22 perror("open"); 23 return -1; 24 } 25 26 // 写入数据 27 write(fd, msg, strlen(msg) + 1); 28 close(fd); 29 return 0; 30 }
读进程(read.c):
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <unistd.h> 4 #include <fcntl.h> 5 #include <sys/stat.h> 6 7 #define FIFO_PATH "/tmp/my_fifo" 8 9 int main() 10 { 11 int fd; 12 char buf[100]; 13 14 // 打开FIFO(读取模式) 15 fd = open(FIFO_PATH, O_RDONLY); 16 if (fd == -1) 17 { 18 perror("open"); 19 return -1; 20 } 21 22 // 读取数据 23 read(fd, buf, sizeof(buf)); 24 printf("Reader received: %s\n", buf); 25 close(fd); 26 27 // 可选:删除FIFO文件 28 unlink(FIFO_PATH); 29 return 0; 30 }
gcc reader.c -o reader && ./reader
gcc writer.c -o writer && ./writer
n、一些代码题
1、识别正确的字符串
正确的字符串规则:1)只包含如下字符(、)、[、]、{、};2)必须是成对出现的且以左边的括号为开始且是闭合的。
如str="()"、str=“”([])”、str="()[]{}"都是正确的字符串,如str="(]"时不正确的字符串
代码:
1 #include <iostream> 2 #include <string> 3 #include <stack> 4 #include <unordered_map> 5 using namespace std; 6 7 bool is_valid(string str) 8 { 9 stack<char> par; 10 unordered_map<char,char> name = { {')','('}, {']', '['}, {'}','{'}}; 11 for(char c:str) 12 { 13 if(c == '(' || c == '[' || c == '{') 14 { 15 par.push(c); 16 } 17 else 18 { 19 if(par.empty() || par.top() != name[c]) 20 { 21 return false; 22 } 23 par.pop(); 24 } 25 } 26 return par.empty(); 27 28 } 29 30 int main() 31 { 32 string str = "()"; 33 string str_2 = "([])"; 34 string str_3 = "(]"; 35 string str_4 = "()[]{}"; 36 37 bool value = is_valid(str_4); 38 cout << str_4 << ":" << value << endl; 39 return 0; 40 }
2、soret使用方法
3、归并排序
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并
其实就是分为归和并两个过程:
归: 不断将原数组拆分为子数组(一分为二),直到每个子数组只剩下一个元素 = 》 归过程结束
并:不断合并相邻的两个子数组为一个大的子数组,合并的过程就是将两个已经有序的子数组合并为一
举个栗子:
如下图所示的待排序序列,经过不断的归过程变成了一个个的小数组:


当每个子数组都只剩下一个元素时,每个子数组都是一个有序数组,然后开始两两合并。
如下是并过程:
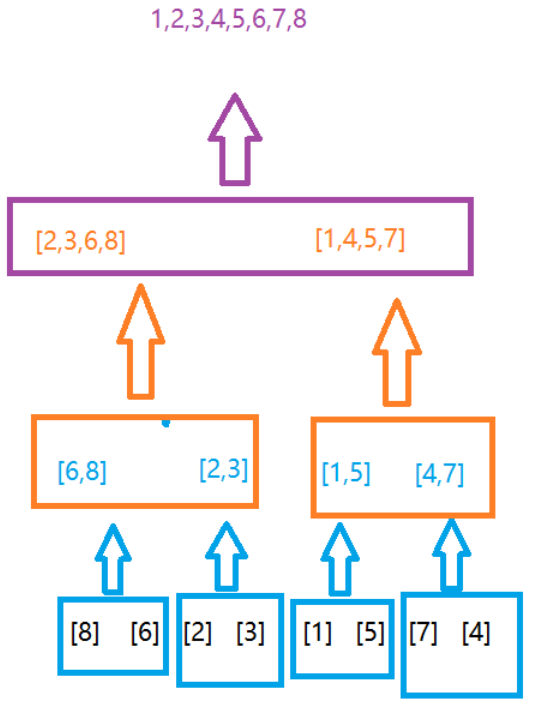
代码实现如下:
1 #include <iostream> 2 #include <thread> 3 #include <vector> 4 5 using namespace std; 6 7 //l、m、r均代表的时vec数组的下标 8 void merge(vector<int> & vec, int l, int m, int r) 9 { 10 //比如最后时,l=0,m=1,r=2则让L中存两个vec中的元素,让R中存一个vec中的元素 11 int n1 = m - l + 1; 12 int n3 = r - m; 13 14 cout << "n1:" << n1 << ",n3:" << n3 << endl; 15 16 //额外的申请内存,保存vec[m]元素左右的子数组,因为接下来会修改vec数组 17 int *L = new int[n1]; 18 int *R = new int[n3]; 19 20 //将vec[l...m]拷贝到L[],其中包括vec[l]和vec[m] 21 for(int i = 0; i < n1; i++) 22 { 23 L[i] = vec[l + i]; 24 } 25 26 //将vec[m+1...r]拷贝到R[] 27 for(int j = 0; j < n3; j++) 28 { 29 R[j] = vec[m + 1 + j]; 30 } 31 //注意k时用来指示vec的新索引,需初始化为l 32 int i = 0, j = 0, k = l; 33 while(i < n1 && j < n3) 34 { 35 //开始比较大小,将小的放在vec的左边 36 if(L[i] <= R[j]) 37 { 38 vec[k] = L[i]; 39 i++; 40 } 41 else 42 { 43 vec[k] = R[j]; 44 j++; 45 } 46 k++; 47 } 48 49 //拷贝L[]剩余元素,如果有 50 while(i < n1) 51 { 52 vec[k] = L[i]; 53 k++; 54 i++; 55 } 56 57 //拷贝R[]剩余元素,如果有 58 while(j < n3) 59 { 60 vec[k] = R[j]; 61 k++; 62 j++; 63 } 64 65 delete [] L; 66 delete [] R; 67 68 } 69 70 void mergeSort(vector<int> & vec, int l, int r) 71 { 72 if(l < r) 73 { 74 int m = l + (r - l) / 2; 75 mergeSort(vec, l, m); 76 mergeSort(vec, m + 1, r); 77 78 merge(vec, l, m, r); 79 } 80 } 81 82 int main() 83 { 84 vector<int> vec = {10,1,30,66,33,0,1}; 85 86 for(auto v : vec) 87 { 88 cout << v << ","; 89 } 90 cout << endl; 91 92 mergeSort(vec, 0, vec.size() - 1); 93 94 for(auto v : vec) 95 { 96 cout << v << ","; 97 } 98 cout << endl; 99 100 101 return 0; 102 }
运行结果:

内存只有1G,待排序的数据有100G,该如何对这100G的数据进行排序?
a. 先把这个100G的数据分成200份
b. 分别将0.5G的数据读入内存,进行内部排序(归并,快排,堆排)
c. 进行200个文件的merge操作即可
4、找出一个数组中小于等于给定数值的最长子串
服务器之间交换的接口成功率作为服务器调用关键特质,某个时间段内的接口失败率使用一个数组表示,数组中的每个元素都是单位时间内失败率数值,数组中的数值为0-100的整数,给定一个数值(minAverageLost)表示某个时间段内平均失败容忍值,即平均失败率小雨等于minAverageLost,找出数组中最长时间段,如果未找到则返回null。
输入描述:输入有两行内容,第一行为(minAverageLost),第二行为数组,数组元素通过空格分割,minAverageLost
和数组中的元素取值范围为0-100,数组元素个数不会超过100。
输出描述:找出数组中平均值小于等于minAverageLost的最长时间段,输出数组下标,格式为begin-end,下标从0开始,如果存在多个最长时间段,则输出多个下标对,且下标对之间使用空格连接,多个下标按照从小到大排序。
示例1:
输入:
2
0 0 100 2 2 99 0 2
输出:
0-1 3-4 6-7
请使用c++实现
1 #include <iostream> 2 #include <sstream> 3 #include <vector> 4 #include <string> 5 #include <sstream> 6 #include <algorithm> 7 using namespace std; 8 9 int main() { 10 int minAverageLost = 0; 11 string str; 12 13 cin >> minAverageLost; 14 cin.ignore(); //忽略换行符 15 16 //第二行 17 getline(cin, str); 18 stringstream ss(str); 19 vector<int> nums; 20 int num = 0; 21 while(ss >> num) 22 { 23 nums.push_back(num); 24 } 25 26 vector<pair<int, int>> valid; 27 28 int len = nums.size(); 29 //计算出数组中前i个元素的和并保存到pre中 30 //其中pre[i]表示num[0...i]的和 31 vector<int> pre(len+1, 0); 32 for(int i = 0; i < len; i++) 33 { 34 pre[i+1] = pre[i] + nums[i]; 35 } 36 37 for(int i=0; i < len; i++) 38 { 39 for(int j = i; j < len; j++) 40 { 41 //此时sum[i...j]的值就等于pre[j+1]-pre[i] 42 int sum = pre[j + 1] - pre[i]; 43 int length = j - i + 1; 44 if(sum <= minAverageLost * length) 45 { 46 valid.emplace_back(i, j); 47 } 48 } 49 } 50 51 if(valid.empty()) 52 { 53 cout << "NULL" << endl; 54 return 0; 55 } 56 57 int max_len = 0; 58 for(auto & p : valid) 59 { 60 int length = p.second - p.first + 1; 61 if(max_len < length) 62 { 63 max_len = length; 64 } 65 } 66 67 vector<pair<int, int>> result; 68 for(auto & p : valid) 69 { 70 if((p.second - p.first + 1) == max_len) 71 { 72 result.push_back(p); 73 } 74 } 75 76 sort(result.begin(), result.end()); 77 78 vector<string> outputs; 79 for(auto & p : result) 80 { 81 outputs.push_back(to_string(p.first) + "-" + to_string(p.second)); 82 } 83 84 for(int i =0; i < outputs.size(); i++) 85 { 86 if(i > 0) 87 { 88 cout << " "; 89 } 90 cout << outputs[i]; 91 } 92 cout << endl; 93 94 return 0; 95 96 } 97 // 64 位输出请用 printf("%lld")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号