
基于最大一致性上下文的广域车辆跟踪
基于最大一致性上下文的广域车辆跟踪
读"X. Shi, P. Li, H. Li, W. Hu, E. Blasch, Using Maximum Consistence Context for Multiple Target Association in Wide Area Traffic Scenes[J], ICASSP, 2013." 笔记。
首先该论文中提出了最大一致性上下文信息,主要用于wide area traffic scene。
wide area traffic scene 面临的难点:
much more moving targets
hard to distinguish from each other due similar appearance and small size in images
the low frame rate
应对策略:
先验知识
场景结构
目标上下文
wide area surveillance的基本框架

Preprocess
一般这种wide area scene数据都是通过航拍得到,所以首先要对图像进行registration,在这个过程中使用了图像的surf的特征点,寻找匹配点,通过RANSAC找到映射模型,对齐图像。然后为了目标检测采用了背景差分的方法,这里背景模型的建立采用的是时域上的中值滤波方法。
Detection
利用建立的背景模型使用背景差分法获得前景区域,但得到的这些前景区域并不全都是目标,也有可能是图像对齐产生的噪声或者是由于光照等原因导致的噪声。这个时候采用的是双层SVM进行目标的筛选。文中给出了两层SVM分别使用的特征,第一层使用的简单的形状特征,第二层使用的是梯度方向直方图特征(HoG)
Association
该框架中追踪过程依然使用的是data association方法,首先进行相邻帧间的数据关联获得较短的tracklet,然后对这些tracklet进行进一步的association获得更长的tracklet,最终得到trajectory。
多目标的关联
首先构建优化目标式,假设相邻帧间响应数都为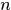 (不满足的话,引入虚拟响应,使相等,这个可以借鉴匈牙利算法中对于workers和tasks数目不同时的处理办法),那么多目标关联可以formulated as
(不满足的话,引入虚拟响应,使相等,这个可以借鉴匈牙利算法中对于workers和tasks数目不同时的处理办法),那么多目标关联可以formulated as
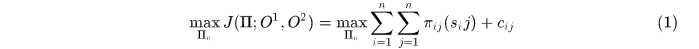
其中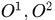 分别是相邻帧中响应的集合,
分别是相邻帧中响应的集合,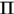 是assigmentation矩阵,
是assigmentation矩阵,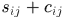 是前一帧的第i个响应和后一帧的第j个响应关联的依据,依据越大越好。
是前一帧的第i个响应和后一帧的第j个响应关联的依据,依据越大越好。
最简单的关联依据可能就是响应间的表观相似度,但是由于wide area scene中表观可区分性不强,所以综合了许多特征。
由于是traffic scenes,所以目标应该是刚体,其大小应该是渐变甚至不变的。
车辆行进过程中车体的方向应该是渐变的,毕竟得沿着路线嘛
虽然表观区别性不大,还是有鉴别性的。
note:由于运动目标很密集,所以使用位置坐标相似性是不甚合理的。
这样就可以定义
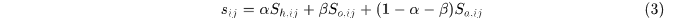
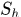 指表观相似性appearance histogram,
指表观相似性appearance histogram, 表示方向的相似性,
表示方向的相似性,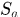 表示目标大小的相似性(area),
表示目标大小的相似性(area), 是权重参数
是权重参数
除了刻画单个目标特征外,由于traffic运动具有一致性,比如沿着道路,所以还可以利用响应之间的相关性作为关联的依据,这个相互之间的关系称之为上下文
文中为了对比,介绍了V. Reilly[1]提出的一种基于近邻分布的spatial context,然后提出了一种基于最大一致性上下文maximum consistency context
spatial context
对于某一帧中的某一个响应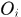 ,将它邻域划分成
,将它邻域划分成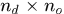 的distance-orientation bins
的distance-orientation bins
,该响应的spatial context定义为距离方向直方图

其中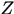 是归一化因子,
是归一化因子,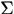 是协方差矩阵,
是协方差矩阵,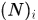 表示响应的邻域
表示响应的邻域
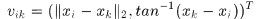
而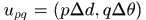 表示直方图(p,q)格的相对于响应的中心位置坐标,
表示直方图(p,q)格的相对于响应的中心位置坐标,
那么(2)式就可以认为是将邻域内的窗格和其他响应都化为相对于该响应的相对距离和角度,然后使用马氏距离计算相邻响应在不同网格中的作用,统计二维直方图。
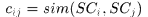
表示前后两帧中对应相应由spatial context产生的匹配度,可以通过直方图的交计算得到。
Maximum consistency context
spatial context 对同一方向的运动目标能够很好的刻画,但是对于邻域内出现相反方向的运动目标就会发现同一目标不同响应的距离方向直方图变化很大,因此这时候作为响应匹配的依据并不合理。
所以论文提出来一种基于最大一致性的上下文度量方法,这个度量方法涉及到了时域信息。
假设有两个关联对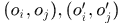 ,其中
,其中 分别属于前一帧响应,
分别属于前一帧响应, 则属于后一帧的响应,那么这两个关联对之间的一致性定义为:
则属于后一帧的响应,那么这两个关联对之间的一致性定义为:
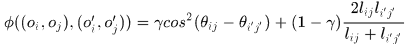
其中第一项是关联线方向的近似性,第二项是关联线长度的近似性(长度的调和平均数)。
那么就可以定义任一个关联的最大一致性上下文了
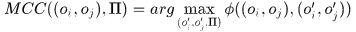
其中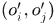 显然是前后帧之间的关联对。
显然是前后帧之间的关联对。
那么目标关联的目标式(1)可以重写为
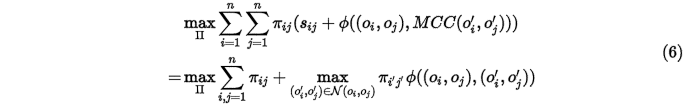
但是这里存在一个问题,我在再求关联对的目标式中出现了关联对。。。也就是所谓的interlock,所以只能采用迭代的方法求解。(虽然该目标式也可以使用模拟退火等智能优化方法得到近似最优解,但是时间消耗实在消耗不起)
具体的算法步骤如下图

tracklet association
首先对多目标关联得到的tracklets进行检验,看是否都是有效的
有效条件为
&\theta_{t-1,t}^k-\theta_{t,t+1}^k <\theta_0\\
&min\Big{\frac{l_{t-1,t}^k}{l_{t,t+1}^k},\frac{l_{t,t+1}^k}{l_{t-1,t}^k}\Big}
然后对不同的tracklet,计算相似度,包括表观相似度(表观模型可以通过tracklet上的所有响应ransac方法得到一个相对具代表性的模型),运动相似度(可以通过前面tracklet的最后一个相应和后面tracklet的第一个响应的相似性判断),以及时间相似度(判断时间差)
最后将较短的tracklet作为噪声剔除。
结论
论文主要提出了一种上下文信息的度量:最大一致性上下文。这个量使用到了spatial-temporal的相关信息,更加具有鉴别性。
论文中的实验表明该上下文信息能够很好的处理航拍数据集中的车辆检测。
个人想法
对于航拍数据集中的车辆检测,使用spatial context会导致运动方向相反的情形难以处理,使用maximu consistency context,算法过程中存在interlock,导致算法速度必然下降。
那我们是否可以在追踪框架的检测模块中,检测车辆的同时检测出车辆的方向,这样就可以使用spatial context,这时仅计算方向一致的响应。速度和精度应该都能得到提升。
V. Reilly, H. Idrees, and M. Shah, Detection and tracking of large number of targets in wide area surveillance[J], ECCV, 2010. ↩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号