为什么 PDF 文本能看到,却提取不到?从开发者角度解析与解决方案
在 PDF 文档的处理过程中,很多人都遇到过这样的情况:PDF 打开完全正常,文字清晰可选,鼠标可以复制,但用代码提取文本时,却只能得到空字符串或零散乱码。这时,你可能会怀疑是代码出现了错误,或者使用的库无法处理这种任务。然而,事实往往并非如此,这类问题更多是 PDF 本身的类型和结构决定的,而非代码或库的问题。
视觉层与逻辑层:看得到不等于程序能读到
一些开发者可能会混淆视觉效果和数据结构的区别。人眼看到的是渲染结果,包括字体样式、字符位置和排版效果,这属于视觉层面。程序读取的,是 PDF 的逻辑结构:页面中是否存在文本对象、字符映射是否完整,以及内容流中记录的是文字还是绘图指令。
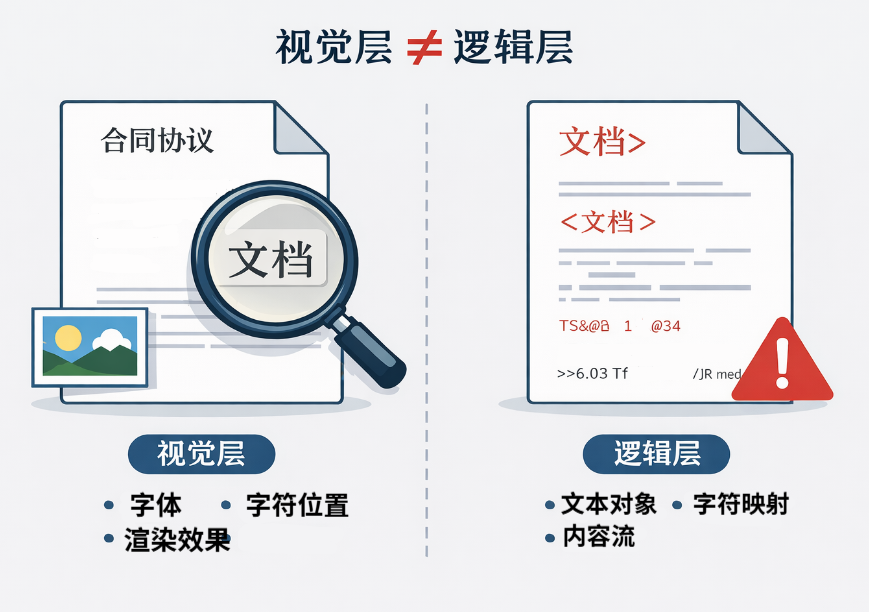
因此,即使你能看到文字,程序也可能无法提取。理解这一点,是排查 PDF 文本提取问题的第一步。
三类容易“看得到,却提取不到”的 PDF
在开发实践中,看得到却无法通过程序提取的问题主要集中在三种 PDF 类型上:
-
扫描件 PDF
这是最典型的案例。文件看起来是正常文档,每页文字清晰可见,但实际上每一页都只是图片,PDF 中并没有任何文本对象。使用任何 PDF 库直接提取文本,结果只能为空。 -
字体嵌入但映射不完整的 PDF
这种 PDF 外观正常,字体也嵌入,但 ToUnicode 或字符映射不完整。程序无法还原字符,提取结果是乱码或零散字符,即使使用 Spire.PDF 等强大库,也只能得到技术上存在但实际语义不可用的文本。 -
混合型 PDF
当 PDF 页面上既有文本对象,又有图片时。表面上似乎可以成功提取到内容,但关键内容可能缺失严重,因为一部分内容存在于图片中。这类 PDF 最容易让开发者误认为是使用的库不能处理高级任务,其实问题在于 PDF 自身的结构。

通过这个分类,开发者可以快速判断自己遇到的 PDF 属于哪一类,从而选择合适的处理策略。
不过,需要明确的是换库并不能解决根本问题。当我们遇到提取失败时,很多人本能地选择换库或者调整参数,但这通常解决不了问题。无论是 Spire.PDF、iText 还是 PDFBox,它们本质上都使用同样的方法读取同一份 PDF 的逻辑结构。如果文本对象不存在或字体映射损坏,换库也只能得到同样不可用的数据。
解决方案示例:扫描件 PDF
当我们遇到上述的三类 PDF 时,究竟应该怎样去解决无法准确提取文本信息的问题呢?
对于扫描件 PDF 或逻辑层缺失的文档,传统文本提取几乎无效。这时候,我们可以通过将 PDF 转成图片,再使用 OCR 识别的方式获取可用文本。本文以扫描件 PDF 为示例说明可行的工程方案,字体映射缺失和混合型 PDF 也可以参考类似思路进行处理。
1. 将 PDF 页面转换为图片
首先我们需要将 PDF 页面转换为可被 OCR 识别的图片格式。使用 Spire PDF 提供的 PdfDocument.SaveAsImage() 方法,可以将每一页 PDF 导出为高分辨率图片,保证页面内容完整可见,同时保留排版效果。这样,即使 PDF 本身没有文本对象,也能为后续 OCR 做准备。

2. 使用 OCR 识别图片文字
在成功得到图片后,我们再使用 Spire.OCR 对生成的图片进行文字识别,提取文本。OCR 可以识别扫描文字和图片中的文字,绕开 PDF 结构的限制。示例 Python 代码如下:
from spire.ocr import *
# 创建 OCR 扫描器实例
scanner = OcrScanner()
# 配置 OCR 模型路径和语言
configureOptions = ConfigureOptions()
configureOptions.ModelPath = r'E:/DownloadsNew/win-x64/'
configureOptions.Language = 'Chinese'
scanner.ConfigureDependencies(configureOptions)
# 使用 OCR 扫描图片
scanner.Scan(r'E:/Administrator/Python1/output/pdftoimage/ToImage_0.png')
# 将提取的文本保存为文本文件
text = scanner.Text.ToString()
with open('E:/Administrator/Python1/output/扫描件PDF文本提取.txt', 'a', encoding='utf-8') as file:
file.write(text + '\n')
详细教程可以参考主页文章:如何使用 OCR 提取扫描件 PDF 的文本(Python 实现)>>
3. 处理其他类型 PDF
-
字体嵌入但映射不完整的 PDF:可以先尝试使用专业 PDF 修复工具或库进行字体嵌入/映射修复;如果修复失败,也可以用 OCR 获取文本。
-
混合型 PDF:对于文本对象部分可直接提取,图片部分用 OCR 识别,最后将两部分结果合并。
总的来说,OCR 是退而求其次的工程方案,但在扫描件或逻辑缺失的 PDF 中,它通常是最稳定、最可落地的选择。
实践建议
在写代码,或使用代码提取 PDF 的文本前,先判断 PDF 类型非常重要。对于扫描件或逻辑层缺失的文档,无需浪费时间在参数调试或库更换上。PDF 自动化的上限,由 PDF 本身决定。
在自动化流程中,建议先分析 PDF,判断其逻辑层结构;对扫描件或结构缺失文档,使用 OCR 获取文本;再对结果进行结构化处理,以保证数据可用性。
结语
当 PDF 文本看得到,却提取不到时,并不意味着写错了代码,也不代表库不行。核心原因在于 PDF 类型和内部结构。把问题理解为文档工程问题而非单纯 API 问题,你会发现很多重复尝试和调参都是可以避免的。
正确的认知和工程实践,才是应对 PDF 自动化挑战的关键。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号