Netty 框架学习 —— ByteBuf
概述
网络数据的基本单位总是字节,Java NIO 提供了 ByteBuffer 作为它的字节容器,但这个类的使用过于复杂。Netty 的 ByteBuf 具有卓越的功能性和灵活性,可以作为 ByteBuffer 的替代品
Netty 的数据处理 API 通过两个组件暴露 —— abstract class ByteBuf 和 interface ByteBufHolder,下面是 ByteBuf API 的优点:
- 可以被用户自定义的缓冲区类型扩展
- 通过内置的复合缓冲区类型实现透明的零拷贝
- 容量可以按需增长
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip() 方法
- 在读和写使用了不同的索引
- 支持方法的链式调用
- 支持引用计数
- 支持池化
ByteBuf
1. 工作原理
ByteBuf 维护了两个不同的索引:一个用于读取,一个用于写入,当你从 ByteBuf 读取时,readIndex 会递增已经被读取的字节数。同样的,当你写入 ByteBuf 时,它的 writeIndex 也会递增。readIndex 和 writeIndex 的起始位置都为 0
如果 readIndex 和 writeIndex 的值相等,也即此时已经到了可读取数据的末尾,就如同达到数组末尾一样,试图读取超出该点的数据将触发一个 IndexOutOfBoundsException
名称以 read 或 write 开头的 ByteBuf 方法,将会推进其对应的索引,而名称以 set 或 get 开头的操作则不会
2. ByteBuf 的使用模式
2.1 堆缓冲区
最常用的 ByteBuf 模式是将数据存储在 JVM 的堆空间中,这种模式被称为支撑数组(backing array)它能在没有使用池化的情况下提供快速的分配和释放,适合于有遗留的数据需要处理的情况
ByteBuf heapBuf = ...;
// 检查 ByteBuf 是否有一个支撑数组
if(heapBuf.hasArray()) {
// 获取对该数组的引用
byte[] array = heapBuf.array();
// 计算第一个字节的偏移量
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
// 获得可读字节数
int length = heapBuf.readableBytes();
// 使用数组、偏移量和长度作为参数调用你的方法
handleArray(array, offset, length);
}
2.2 直接缓冲区
直接缓冲区使用本地内存存储数据,更适合用于网络传输,但相对于堆缓冲区,其分配和释放都较为昂贵。另外,如果你正在处理遗留代码,处理直接缓冲区内容时,你必须将其内容进行一次复制
ByteBuf directBuf = ...;
// 不是支撑数组就是直接缓冲区
if(!directBuf.hasArray()) {
// 获取可读字节数
int length = directBuf.readableBytes();
// 分配一个新的数组来保存具有该长度的字节数组
byte[] array = new byte[length];
// 将字节复制到该数组
directBuf.getBytes(directBuf.readerIndex(), array);
// 使用数组、偏移量和长度作为参数调用你的方法
handleArray(array, 0, length);
}
2.3 复合缓冲区
复合缓冲区为多个 ByteBuf 提供了一个聚合视图,可以根据需要添加或删除 ByteBuf 实例。Netty 通过一个 ByteBuf 子类 —— CompositeByteBuf 实现这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示
CompositeByteBuf 中的 ByteBuf 实例可能同时包含直接内存和非直接内存分配,如果其中只有一个实例,那么对 CompositeByteBuf 上的 hasArray() 方法的调用将返回该数组上的 hasArray() 方法的值,否则返回 false
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = ...;
ByteBuf bodyBuf = ...;
// 将 ByteBuf 实例追加到 CompositeByteBuf
messageBuf.addComponents(headerBuf, bodyBuf);
...
// 删除第位于索引位置为 0 的 ByteBuf
messageBuf.removeComponent(0);
// 循环遍历所有的 ByteBuf 实例
for(ByteBuf buf : messageBuf) {
System.out.println(buf.toString());
}
字节级操作
1. 随机访问索引
如同普通的 Java 字节数组一样,ByteBuf 的索引是从零开始的:第一个字节的索引是 0,最后一个字节的索引总是 capacity() - 1
ByteBuf buffer = ...;
for(int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i);
System.out.println((char) b)
}
这种需要一个索引值参数的方法访问数据不会改变 readerIndex 也不会改变 writerIndex。如果需要改变,也可以通过调用 readerIndex(index) 或者 writerIndex(index) 来手动移动这两者
2. 顺序访问索引
虽然 ByteBuf 同时具有读索引和写索引,但是 JDK 的 ByteBuf 却只有一个索引,这也就是为什么必须调用 flip() 方法来在读模式和写模式之间进行切换的原因
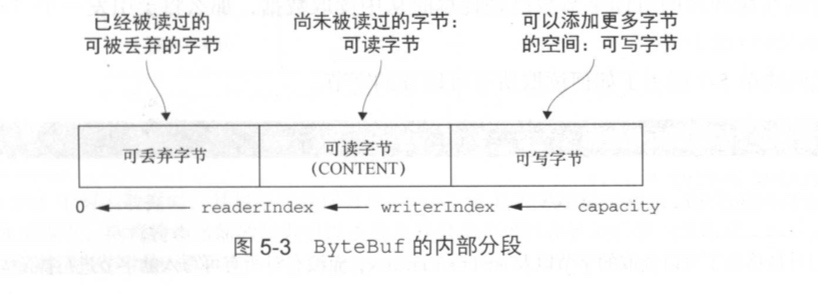
3. 可丢弃字节
可丢弃字节的分段包含了已经被读过的字节,通过调用 discardReadBytes() 方法,可以丢弃它们并回收空间。这个分段的初始大小为 0,存储在 readerIndex 中,会随着 read 操作的执行而增加
可能你会想到频繁调用 discardReadBytes() 方法以确保可写分段的最大化,但这极有可能会导致内存复制,因为可读字段必须被移动到缓冲区的开始位置
4. 可读字节
ByteBuf 的可读字节分段存储了实际数据,新分配的、包装的或者复制的缓冲区的默认的 readerIndex 值为 0。任何名称以 read 或者 skip 开头的操作都将检索或者跳过位于当前 readerIndex 的数据,并且将它增加已读字节数
如果尝试在缓冲区的可读字节数已经耗尽时从中读取数据,那么将会引发一个 IndexOutOfBoundsException
ByteBuf buffer = ...;
while(buffer.isReadable()) {
System.out.println(buffer.readByte());
}
5. 可写字节
可写字节分段是指一个拥有未定义内容、写入就绪的内存区域。新分配的缓冲区的 writerIndex 的默认值为 0.任何名称以 write 开头的操作都将从当前的 writerIndex 处开始写数据,并将它增加已经写入的字节数。如果写操作的目标是 ByteBuf,并且没有指定源索引的值,则缓冲区的 readerIndex 也同样会被增加相同的大小
writeBytes(ByteBuf dest)
如果尝试往目标写入超过目标容量的数据,将会引发一个 IndexOutOfBoundException
ByteBuf buffer = ...;
while(buffer.writableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
6. 索引管理
JDK 的 InputStream 定义了 mark(int readlimit) 和 reset() 方法,这些方法分别被用来将流中的当前位置标记为指定的值,以及将流重置到该位置
同样,可以通过 markReaderIndex()、markWriterIndex()、resetWriterIndex() 和 resetReaderIndex() 来标记和重置 ByteBuf 的 readerIndex 和 writerIndex
也可以通过 readerIndex(int) 或者 writerIndex(int) 来将索引移动到指定位置。任何试图将索引设置到无效位置都将导致 IndexOutOfBoundsException
可以通过调用 clear() 方法来将 readerIndex 和 writerIndex 都设置为 0,这样并不会清除内存中的内容。调用 clear() 比调用 discardReadBytes() 轻量得多,因为它只是重置索引
7. 查找操作
在 ByteBuf 中有多种可以用来确定指定值的索引的方法,最简单的是 indexOf() 方法。较为复杂的查找可以通过那些需要一个 ByteBufProcessor 作为参数的方法达成,这个接口只定义了一个方法
boolean process(byte value);
它将检查输入值是否是正在查找的值,ByteBufProcessor 针对一些常见的值定义了许多便利方法
ByteBuf buffer = ...;
// 查找回车符 \r
int index = buffer.forEachByte(ByteBufProcessor.FIND_CR);
8. 派生缓冲区
派生缓冲区为 ByteBuf 提供了以专门的方式来呈现其内容的视图,这些视图通过以下方法被创建
- duplicate()
- slice()
- slice(int, int)
- Unpooled.unmodifiableBuffer(...)
- order(ByteOrder)
- readSlice(int)
这些方法都将返回一个新的 ByteBuf 实例,其内部存储和 JDK 的 ByteBuffer 共享,这也意味着,如果你修改了它的内容,也即同时修改了其对应的源实例。如果需要一个现有缓冲区的真实副本,请使用 copy() 或 copy(int, int) 方法
// 对 ByteBuf 进行切片
Charset utf8 = Charset.forName(StandardCharsets.UTF_8);
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", urf8);
// 创建该 ByteBuf 从索引 0 到 15 结束的一个新切片
ByteBuf sliced = buf.slice(0, 15);
// 更新索引 0 处的字节
buf.setByte(0, (byte) 'J');
// 成功,因为数据是共享的
assert buf.getByte(0) == sliced.getByte(0);
// 对 ByteBuf 进行切片
Charset utf8 = Charset.forName(StandardCharsets.UTF_8);
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", urf8);
// 创建该 ByteBuf 从索引 0 到 15 结束的一个新副本
ByteBuf sliced = buf.copy(0, 15);
// 更新索引 0 处的字节
buf.setByte(0, (byte) 'J');
// 成功,因为数据不是共享的
assert buf.getByte(0) != sliced.getByte(0);
9. 读/写操作
有两种类别的读/写操作:
- get() / set() 操作,从给定的索引开始,并且索引不会改变
- read() / write() 操作,从给定的索引开始,并且会根据已经访问过的字节数对索引进行调整
| 方法 | 描述 |
|---|---|
| setBoolean (int , boolean) | 设定给定索引处的 Boolean 值 |
| getBoolean(int) | 返回给定索引处的 Boolean 值 |
| setByte(int index, int value) | 设定给定索引处的字节值 |
| getByte(int) | 返回给定索引处的字节 |
| getUnsignedByte(int ) | 将给定索引处的无符号字节值作为 short 返回 |
| setMedium(int index , int value) | 设定给定索引处的 24 位的中等 int值 |
| getMedium(int) | 返回给定索引处的 24 位的中等 int 值 |
| getUnsignedMedium (int) | 返回给定索引处的无符号的 24 位的中等 int 值 |
| setint(int index , int value) | 设定给定索引处的 int 值 |
| getint (int) | 返回给定索引处的 int 值 |
| getUnsignedint(int) | 将给定索引处的无符号 int 值作为 long 返回 |
| setLong(int index, long value) | 设定给定索引处的 long 值 |
| getLong(int) | 返回给定索引处的 long 值 |
| setShort(int index, int value) | 设定给定索引处的 short 值 |
| getShort(int) | 返回给定索引处的 short 值 |
| getUnsignedShort(int) | 将给定索引处的无符号 short 值作为 int 返回 |
| getBytes (int, …) | 将该缓冲区中从给定索引开始的数据传送到指定的目的地 |
read/write 操作的 API 和 set/get 大同小异,只不过会增加索引值
ByteBuf 还提供了其他有用的操作
| 方法 | 描述 |
|---|---|
| isReadable () | 如果至少有一个字节可供读取,则返回 true |
| isWritable () | 如果至少有一个字节可被写入,则返回 true |
| readableBytes() | 返回可被读取的字节数 |
| writableBytes() | 返回可被写入的字节数 |
| capacity() | 返回 ByteBuf 可容纳的字节数 。在此之后,它会尝试再次扩展直到达到maxCapacity () |
| maxCapacity() | 返问 ByteBuf 可以容纳的最大字节数 |
| hasArray() | 如果 ByteBuf 由一个字节数组支撑,则返回 true |
| array () | 如果 ByteBuf 由一个字节数组支撑则返问该数组;否则,它将抛出 一个 UnsupportedOperat工onException 异常 |
ByteBuf 分配
1. 按需分配
为了降低分配和释放内存的开销,Netty 通过 interface ByteBufAllocator 实现了 ByteBuf 的池化,用于分配 ByteBuf 实例
下面是 ByteBufAllocator 的一些 API
| 方法 | 描述 |
|---|---|
| buffer()buffer(int initialCapacity);buffer(int initialCapacity, int maxCapacity); | 返回一个基于堆或者直接内存存储的 ByteBuf |
| heapBuffer ()heapBuffer(int initialCapacity)heapBuffer(int initialCapacity, int maxCapacity) | 返回一个基于堆内存存储的 ByteBuf |
| directBuffer()directBuffer(int initialCapacity)directBuffer(int initialCapacity , int maxCapacity) | 返回一个基于直接内存存储的 ByteBuf |
| compositeBuffer()compositeBuffer(int maxNumComponents) compositeDirectBuffer()compositeDirectBuffer (int maxNumComponents); compositeHeapBuffer()compositeHeapBuffer(int maxNumComponents); | 返回一个可以通过添加最大到指定数目的基于堆的或者直接内存存储的缓冲区来扩展的 CompositeByteBuf |
| ioBuffer() | 返回一个用于套接字的 I/O 操作的 ByteBuf。默认地, 当所运行的环境具有 sun.misc.Unsafe支持时,返回基于直接内存存储的 ByteBuf,否则返回基于堆内存存储的 ByteBuf;当指定使用 PreferHeapByteBufAllocator 时,则只会返回基于堆内存存储的 ByteBuf |
可以通过 Channel 或者绑定到 ChannelHandler 的 ChannelHandlerContext 获取一个 ByteBufAllocator 的引用
Channel channel = ...;
ByteBufAllocator allocator = channel.alloc();
...
ChannelHandlerContext ctx = ...;
ByteBufAllocator allocator = ctx.alloc();
Netty 提供了两种 ByteBufAllocator 的实现:PooledByteBufAllocator 和 UnpooledByteBufAllocator ,前者池化了 ByteBuf 实例以提供性能,最大限度减少内存碎片。后者不池化 ByteBuf 实例,每次调用都会返回一个新的实例
2. Unpooled 缓冲区
如果你未能获取 ByteBufAllocator 实例,Netty 也提供了名为 Unpooled 的工具类,它提供了静态的辅助方法来创建未池化的 ByteBuf 实例
| 方法 | 描述 |
|---|---|
| buffer()buffer(int 工nitialCapacity)buffer(int initialCapacity, int maxCapacity) | 返回一个未池化的基于堆内存存储的ByteBuf |
| directBuffer()directBuffer(int initialCapacity)directBuffer(int initialCapacity, int maxCapacity) | 返回一个未池化的基于直接内存存储ByteBuf |
| wrappedBuffer() | 返回一个包装了给定数据的ByteBuf |
| copiedBuffer() | 返回一个复制了给定数据的 ByteBuf |
3. ByteBufUtil 类
ByteBufUtil 提供了用于操作 ByteBuf 的静态的辅助方法。因为这个 API 是通用的,并且和池化无关,所以这些方法已然在分配类的外部实现
这些静态方法中最有价值的可能就是 hexdump() 方法,它以十六进制的表示形式打印 ByteBuf 的内容。 这在各种情况下都很有用,例如,出于调试 的目的记录 ByteBuf 的内容。十六进制的表示通常会提供一个比字节值的直接表示形式更加有用的日志条目,此外,十六进制的版本还可以很容易地转换回实际的字节表示
另一个有用的方法是 boolean equals(ByteBuf , ByteBuf),它被用来判断两个 ByteBuf 实例的相等性。 如果你实现自己的 ByteBuf 子类,你可能会发现 ByteBufUtil 的其他有用方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号