


pyhton机器学习入门基础(机器学习与决策树)
//2019.07.26
#scikit-learn数据挖掘工具包
1、Scikit learn是基于python的数据挖掘和机器学习的工具包,方便实现数据的数据分析与高级操作,是数据分析里面非常重要的工具包。
2、Scikit Learn是数据挖掘重要的工具包,其官网为http://scikit-learn.org,可以方便地进行进行相关用法的查询。
3、scikit-learn是一种开源的工具包,其开源网址为http://github.com//scikit-learn/scikit-learn.
#机器学习和决策树(Machine Learning and Decision Tree)
4、机器学习实质是一种函数映射,它是基于人类学习的习惯和模式进行相关的学习、总结和预测的,其输出结果取决于以往的经验,而这里的经验就是指以往的数据,它是机器学习的基础,而具体结果的准确度主要取决于两个方面:一个是以往的数据,另外一个则是指机器学习算法的准确性,其中机器学习的算法是核心的部分。
5、机器学习是一种函数关系,因此它必定含有相应的输入因子和输出结果,根据输出结果的类别可以分为以下几类:
(1)对结果不打标记,则称之为聚类算法,比如对于植物的分类算法,这个机器学习就是无监督学习;
(2)对结果打标记的算法则称之为监督学习,比如对于邮件是否为垃圾邮件的判断和决定。而对于监督机器学习算法,也可以根据其结果的离散与连续将其分为分类(结果有限离散)和回归(结果是连续的)
6、决策树是一种机器学习算法,它属于机器学习算法中的监督学习算法,是一类对于结果有标记的机器学习算法;
7、决策树是一种树状结构的算法,它是根据结果的不同进行多层多属性分类决策,而对于每一层的数据属性和优先级的决定定义原则与算法原理则是不同决策树算法的不同之处,比较典型的算法决策因素有信息熵、信息增益等
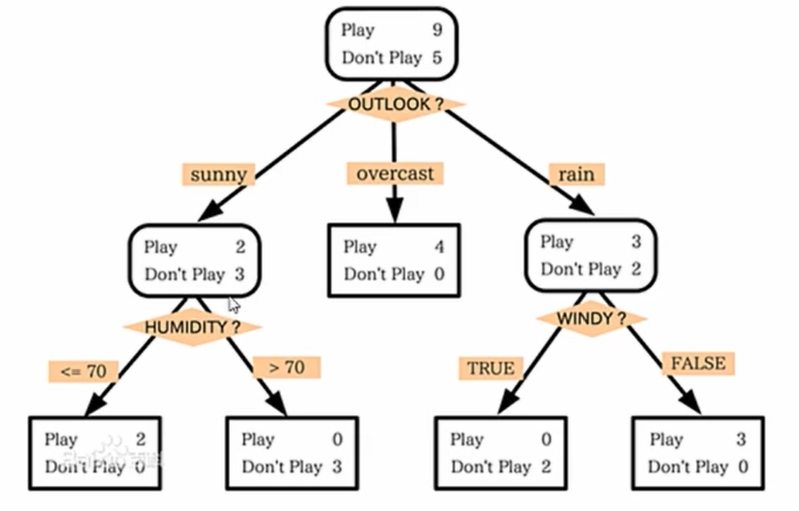
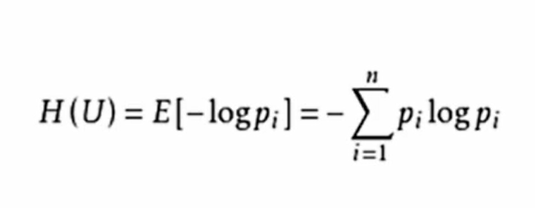
该函数是指决策树算法的分层依据为信息熵函数定义(越小越好)
8、机器学习算法的过程实现整体的框架主要分为三个步骤:数据预处理、数据建模以及结果验证。
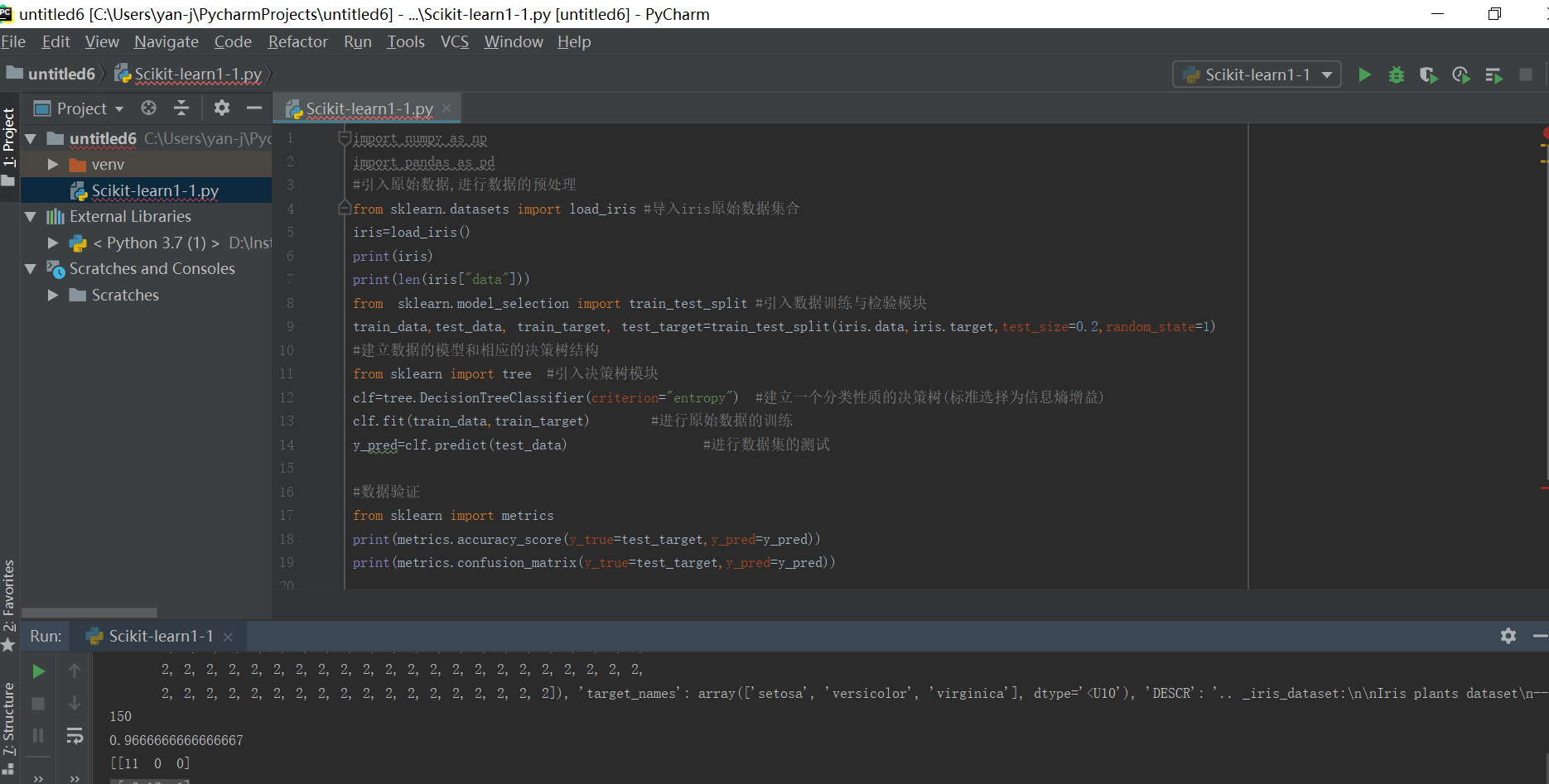
9、简单决策树的实现:
import numpy as np
import pandas as pd
#引入原始数据,进行数据的预处理
from sklearn.datasets import load_iris #导入iris原始数据集合
iris=load_iris()
print(iris)
print(len(iris["data"]))
from sklearn.model_selection import train_test_split #引入数据训练与检验模块
train_data,test_data, train_target, test_target=train_test_split(iris.data,iris.target,test_size=0.2,random_state=1)
#建立数据的模型和相应的决策树结构
from sklearn import tree #引入决策树模块
clf=tree.DecisionTreeClassifier(criterion="entropy") #建立一个分类性质的决策树(标准选择为信息熵增益)
clf.fit(train_data,train_target) #进行原始数据的训练
y_pred=clf.predict(test_data) #进行数据集的测试
#数据验证
from sklearn import metrics #引入机器学习的验证模块
print(metrics.accuracy_score(y_true=test_target,y_pred=y_pred)) #输出整体预测结果的准确率,其中第三个参数normalize=False表示输出结果预测正确的个数
print(metrics.confusion_matrix(y_true=test_target,y_pred=y_pred)) #输出混淆矩阵,如果为对角阵,则表示预测结果是正确的,准确度越大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号