【第3篇】python爬虫实战-CSDN个人主页文章列表获取
本文教程利用 Scrapy 框架实现一个网络爬虫,本文代码实现CSDN个人主页文章列表爬取,已实现自动翻页,爬取的数据集最终保存为json文件,代码仅供参考学习交流。开始本教程前,请确保你的本机环境中已经正确安装了python环境以及scrapy框架,如若没有安装,请先自行百度相关安装教程后,再来阅读本文。
目录
1、创建Scrapy项目
scrapy startproject csdnSpider2、创建一个爬虫
# 进入目录
cd csdnSpider
#创建爬虫
scrapy genspider csdn csdn.net
3、文件目录
csdnSpider
│ scrapy.cfg # 内容为scrapy的基础配置
│
└─csdnSpider
│ items.py # 定义爬虫程序的数据模型
│ middlewares.py # 定义数据模型中的中间件
│ pipelines.py # 管道文件,负责对爬虫返回数据的处理
│ settings.py # 爬虫程序设置,主要是一些优先级设置,优先级越高,值越小
│ __init__.py
│
├─spiders
│ │ csdn.py # 自定义爬虫引擎
│ │ __init__.py
│ │
│ └─__pycache__
│ __init__.cpython-37.pyc
│
└─__pycache__
settings.cpython-37.pyc
__init__.cpython-37.pyc4、代码实现
小提示: scrapy目录中未改动过的代码,就没有贴出来了。
4.1、items.py
import scrapy
class CsdnspiderItem(scrapy.Item):
# ID
id = scrapy.Field()
# 类型
type = scrapy.Field()
# 标题
title = scrapy.Field()
# 创建时间
createTime = scrapy.Field()
# 阅读量
views = scrapy.Field()
# 文章地址
url = scrapy.Field()
pass4.2、settings.py
BOT_NAME = 'csdnSpider'
SPIDER_MODULES = ['csdnSpider.spiders']
NEWSPIDER_MODULE = 'csdnSpider.spiders'
# UA认证
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
# robots协议
ROBOTSTXT_OBEY = False
# 优先级设置,值越小越先执行
ITEM_PIPELINES = {
'csdnSpider.pipelines.CsdnspiderPipeline': 300,
}
4.3、csdn.py
import scrapy
from csdnSpider.items import CsdnspiderItem
from scrapy import Request
import re
from urllib.parse import urlparse
class CsdnSpider(scrapy.Spider):
# 爬虫名称
name = 'csdn'
# 爬取域名范围
allowed_domains = ['csdn.net']
# 博客主页地址
url = 'https://blog.csdn.net/qq_19309473'
# 从这个页面开始
start_urls = [url]
# 初始化函数
def __init__(self):
# 开始页数
self.page = 1
# 记录条数
self.count = 0
# 解析器
def parse(self, response):
# 构建对象列表
item = CsdnspiderItem()
post_list = response.xpath('//*[@id="articleMeList-blog"]/div[2]/div')
# 获取文章总条数
blog_str = response.xpath('//*[@id="container-header-blog"]/span/text()').get()
total_str = re.findall("博客\((.+?)\)", blog_str)[0]
total = int(total_str)
for post in post_list:
# 记录条数加1
self.count += 1
item['id'] = self.count
item['type'] = post.xpath('./h4//span/text()').get()
item['title'] = post.xpath('./h4/a/text()')[1].extract().strip()
item['createTime'] = post.xpath('.//span[@class="date"]/text()').get()
item['views'] = post.xpath('.//span[@class="read-num"]/text()').get()
item['url'] = post.xpath('./h4/a/@href').get()
yield item
# 循环换页爬取
self.page += 1
# 请求URL
request_url = response.request.url
# 协议
protocol = urlparse(request_url).scheme
# 域名
domain = urlparse(request_url).netloc
# author
home = urlparse(request_url).path.split('/')[1]
# 下一页地址
next_url = "{}://{}/{}/article/list/{}".format(protocol, domain, home, self.page)
# 最大页数
maxPage = total // 40 if total % 40 == 0 else (total // 40 + 1)
if self.page < maxPage + 1:
yield Request(url=next_url, callback=self.parse, dont_filter=False)
4.4、pipelines.py
from scrapy.exporters import JsonLinesItemExporter
class CsdnspiderPipeline:
# 初始化
def __init__(self):
# 新建并打开一个blog.json文件
self.fp = open('blog.json', 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
#文本处理
def process_item(self, item, spider):
# 写入数据
self.exporter.export_item(item)
return item
# 关闭
def close_spider(self):
# 关闭文件流
self.fp.close()
5、启动爬虫
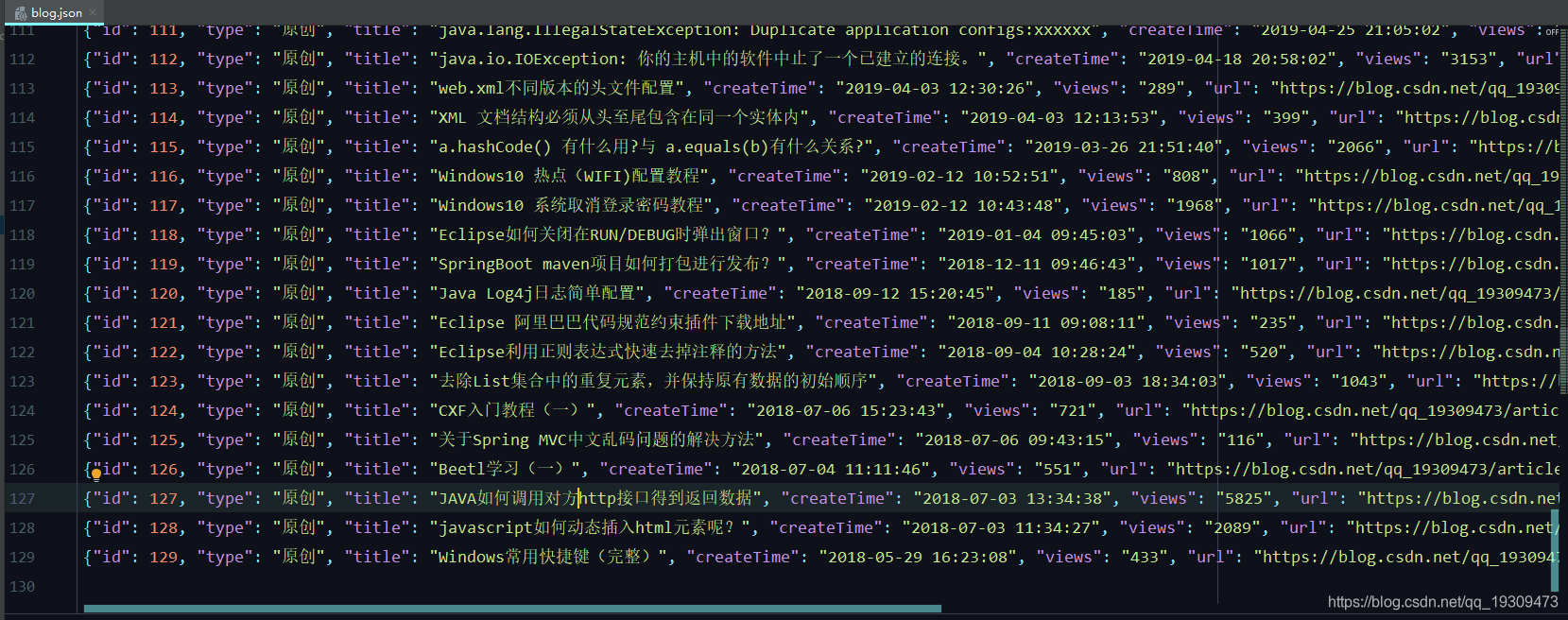
scrapy crawl csdn6、爬取结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号