【第5篇】Python爬虫实战-读取临时邮箱内容

目录
一、明确目标
目标明确,根据指定临时邮箱地址,读取邮件最新内容。
二、分析网页
在使用这个问网站的临时邮箱前,需要先申请使用,然后才能接受到邮件信息。
首先打开控制台,监听页面交互请求,先点随机生成一个邮箱,然后点击申请邮箱按钮。
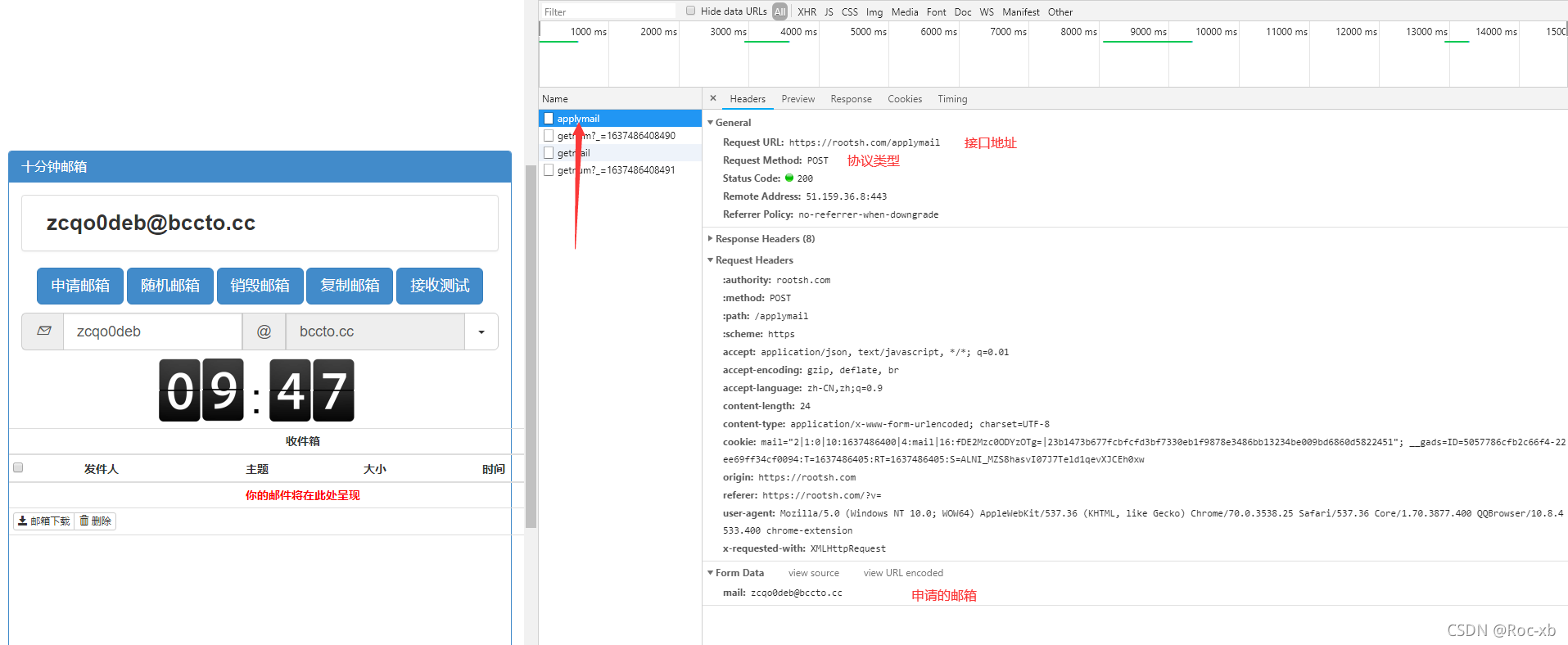
可以发现接口没有加密,这个我们可以直接用python来进行模拟请求申请邮箱。
其次我们注意到,下面有一个轮询请求,应该就是再获取该邮箱是否有接收到新邮件,以便于实时更新到网页上。

这是还没有收到新邮件的response响应结果:

这是已经有新邮件的response响应结果:
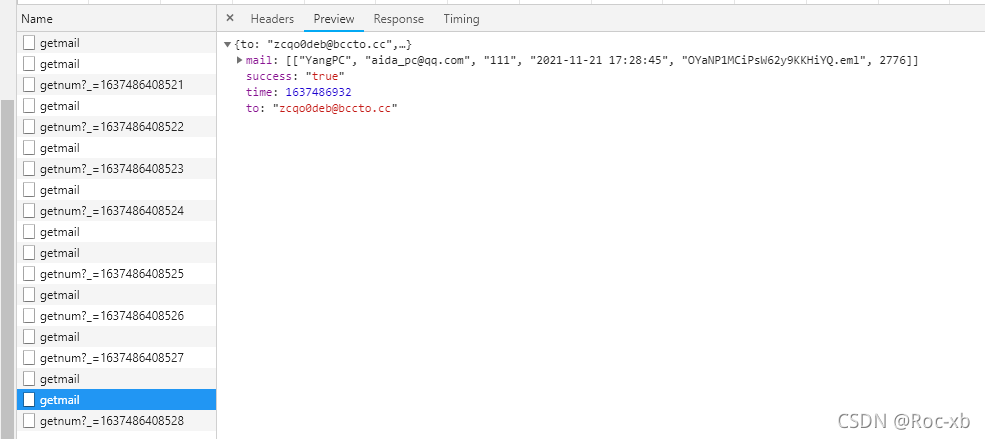
可以里面有一个OYaNP1MCiPsW62y9KKHiYQ.eml,感觉上很奇怪,其实并没有,我们在页面上点击已经接收到邮件进去。

可以发现,该参数是获取内容的关键参数,只需要将该参数拼接到该url后面,即可看到邮件内容。 https://rootsh.com/win/zcqo0deb(a)bccto-_-cc/
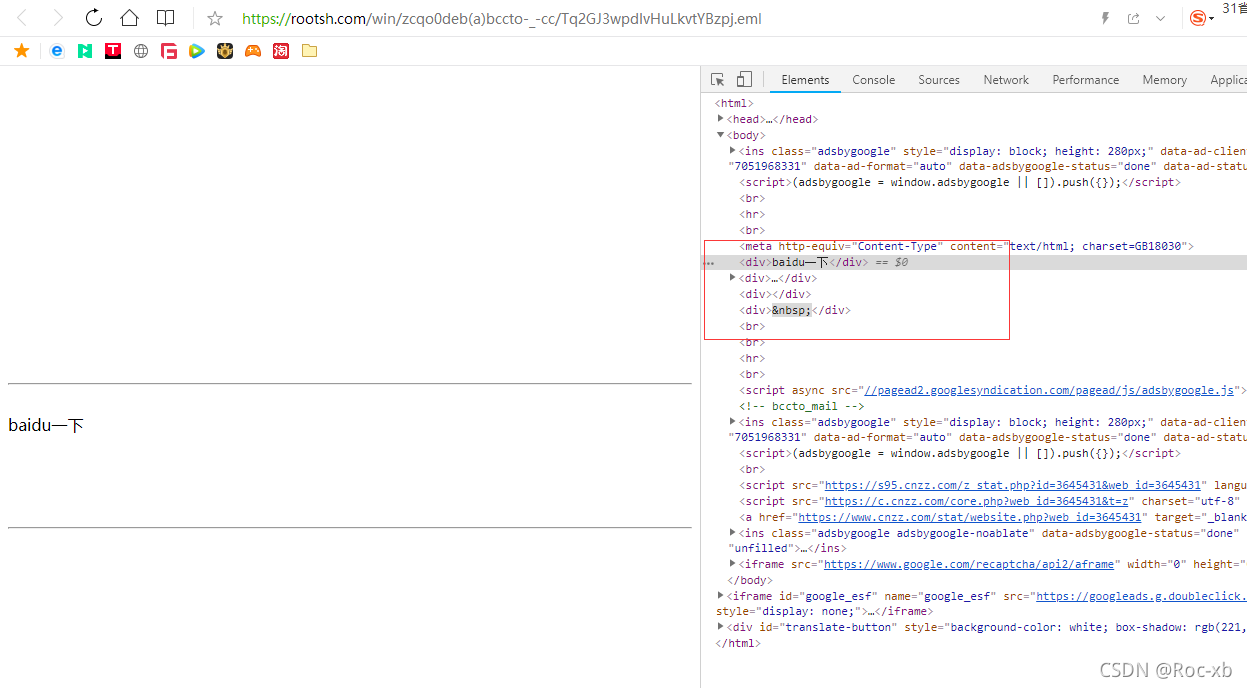
分析网页结构,我们可以看到邮件内容是被一个div里,我们可以利用html解析到具体的内容。
我们程序分两步来完成整个操作,先编写申请邮箱,然后在编写读取邮件内容
三、编写代码
(1)申请临时邮箱
# 由于网站规则:@bccto.cc 邮箱名只支持字母和数字
def apply_email(email):
url = "https://rootsh.com/applymail"
payload = "mail={}%40bccto.cc".format(email)
headers = {
'cookie': '__gads=ID=5057786cfb2c66f4-22ee69ff34cf0094:T=1637486405:RT=1637486405:S=ALNI_MZS8hasvI07J7Teld1qevXJCEh0xw; UM_distinctid=17d41d57d367ab-0d02c53f45975b-3354417a-1fa400-17d41d57d37cdb; CNZZDATA3645431=cnzz_eid%3D360129947-1637481214-https%253A%252F%252Frootsh.com%252F%26ntime%3D1637481214; mail="2|1:0|10:1637487469|4:mail|40:emNxbzBkZWJAYmNjdG8uY2N8MTYzNzQ4NzQ2OQ==|62c43aa0a54d521203d369274b62eba2c730bd23b27fe60eb51a802660f21627"; time="2|1:0|10:1637487744|4:time|4:MA==|8194e1de83b3bb8b481eb938676423a82aa4e3da47192827061e5cd488c5d6b9"; mail="2|1:0|10:1637487791|4:mail|40:dmsyeHY5OTdAYmNjdG8uY2N8MTYzNzQ4Nzc5MQ==|bef8ce72e198df89190399718d828ad37d720ef595e0d0b08e3b077deda76f74"; time="2|1:0|10:1637487791|4:time|16:MTYzNzQ4Nzc5MQ==|6d8df9d0d7eaea212eb808c3e68325727969c5223ae8b551256bc8cb57574ad1"',
'origin': 'https://rootsh.com',
'accept-language': 'zh-CN,zh;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4533.400 chrome-extension',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
}
try:
response = requests.post(url, headers=headers, data=payload).json()
if response['success'] == 'true':
print("临时邮箱:{}@bccto.cc,申请成功!".format(email))
except:
print("临时邮箱:{}@bccto.cc,申请失败!".format(email))(2)读取邮件内容
# 获取邮件
def get_email(email):
url = "https://rootsh.com/getmail"
payload = "mail={}%40bccto.cc".format(email)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
}
try:
response = requests.post(url, headers=headers, data=payload).json()
uid = response["mail"][0][-2]
return pase_html(email, uid)
except:
pass
# 解析html
def pase_html(email, uid):
url = "https://rootsh.com/win/{}(a)bccto-_-cc/{}".format(email, uid)
print(url)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9'
}
html = requests.get(url, headers=headers).text
dom = etree.HTML(html)
div1 = dom.xpath("/html/body/div[1]/text()")
div2 = dom.xpath("/html/body/div[2]/text()")
return "".join(div1) + "".join(div2)
四、运行测试


 浙公网安备 33010602011771号
浙公网安备 33010602011771号