

MySQL 并行复制(MTS) 从库发生异常crash分析
背景
半同步复制从库在晚上凌晨2点半发生异常crash,另一个异步复制从库在第二天凌晨3点也发生了异常crash。
版本
mysql 5.7.16
redhat 6.8
mysql> show variables like '%slave_para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 16 |
+------------------------+---------------+
分析
-
mysqld服务在以mysqld_safe守护进程启动的情况下,在发生mysqld异常情况(比如OOM)会自动拉起mysqld服务,但已确认两个从库实例messages中无与OOM相关的日志。
-
从监控中发现,两个从库与Seconds_Behind_Master没有很高的异常上升。
-
参数slave_pending_jobs_size_max 在多线程复制时,在队列中Pending的事件所占用的最大内存,默认为16M,如果内存富余,或者延迟较大时,可以适当调大;注意这个值要比主库的max_allowed_packet大。
参考官方文档:slave_pending_jobs_size_max -
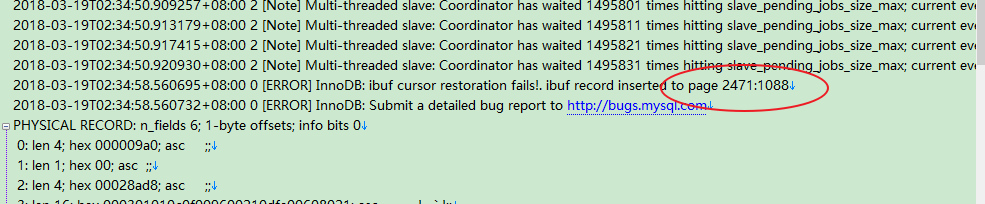
两个发生异常crash的从库日志中都出现了ibuf record inserted to page x:x ,通过查看space_id发现都是对应的同一张表(a_xxx.join_acct_flow),疑是晚上的定时任务对这张表做了大事务的操作。从库的并行复制只有对并发提交的事务才会进行并行应用,对一个大事务,只有一个线程进行应用。
![]()
![]()
-
分析在从库发生异常crash的时间段里发现,产生了大事务

mysqlbinlog -v -v --base64-output=decode-rows
--start-datetime='2018-04-03 02:47:22' --stop-datetime='2018-04-03 02:48:26' /data/mysql/mysql-bin.003446 | awk
'/###/{if($0~/UPDATE|INSERT|DELETE/)count[$2""$NF]++}END{for(i in
count)print i,"\t",count[i]}' | column -t | sort -k3nr | more
DELETE`a_xxx`.`xxx_acct_flow` 565330
DELETE`a_xxx`.`xxx_bfj_flow` 23595
DELETE`a_xxx`.`xxx_loan_detail` 24156
DELETE`a_xxx`.`xxx_pay_log` 18475
INSERT`a_xxx`.`xxx_acct_flow_his` 576265
INSERT`a_xxx`.`xxx_bfj_flow_his` 23829
INSERT`a_xxx`.`xxx_loan_detail_his` 24539
INSERT`a_xxx`.`xxx_pay_log_his` 18709
- 向看源码的朋友请教了下,得到了MySQL异常crash的Stack Trace
获取内存地址放入/tmp/err.log 中
[0xf1dff5]
[0x79d3b4]
[0x358c00f7e0]
[0x358bc325e5]
[0x358bc33dc5]
[0x1159d65]
[0x115e8b3]
[0x102b4d1]
[0x102f531]
[0x1033b29]
[0x11a59a1]
[0x1200afb]
[0x110db48]
[0x358c007aa1]
[0x358bce8aad]
nm -D -n /usr/local/mysql/bin/mysqld>/tmp/mysqld.sym
resolve_stack_dump -s /tmp/mysqld.sym -n /tmp/err.log |c++filt | less
0xf1dff5 my_print_stacktrace + 53
0x79d3b4 handle_fatal_signal + 1188
0x358c00f7e0 _end + -1978652160
0x358bc325e5 _end + -1982703611
0x358bc33dc5 _end + -1982697499
0x1159d65 ut_dbg_assertion_failed(char const*, char const*, unsigned long) + 170
0x115e8b3 ib::fatal::~fatal() + 179
0x102b4d1 ibuf_print(_IO_FILE*) + 881
0x102f531 ibuf_update_free_bits_low(buf_block_t const*, unsigned long, mtr_t*) + 3905
0x1033b29 ibuf_merge_or_delete_for_page(buf_block_t*, page_id_t const&, page_size_t const*, unsigned long) + 2825
0x11a59a1 buf_page_io_complete(buf_page_t*, bool) + 1249
0x1200afb fil_aio_wait(unsigned long) + 347
0x110db48 io_handler_thread + 200
0x358c007aa1 _end + -1978684223
0x358bce8aad _end + -1981956915
- 可见,在mysqld发生异常crash时的内部函数是ibuf_update_free_bits_low,ibuf_merge_or_delete_for_page(在做change buffer的merge操作
- 貌似是由于主实例执行了delete大事务,从实例多线程进行apply(change buffer merge)出现的问题导致mysqld发生crash?
测试
主库模拟一个大事务,看从库是否有异常出现
环境
centos 7.4
mysql5.7.19
从库并行复制线程 8
从库slave_pending_jobs_size_max 设置比主库 max_allowed_packet大
主库
mysql> desc sbtest1;
+-----+-----------+-----+-----+------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| k | int(11) | NO | MUL | 0 | |
| c | char(120) | NO | | | |
| pad | char(60) | NO | | | |
| id3 | int(11) | YES | | NULL | |
| id5 | int(11) | YES | | NULL | |
+-----+-----------+-----+-----+------+----------------+
select count(*) from sbtest1;
mysql> show variables like 'max_allowed_packet%';
+--------------------+----------+
| max_allowed_packet | 16777216 | 16M
+--------------------+----------+
从库
mysql> show variables like '%slave_para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 8 |
+------------------------+---------------+
mysql> show variables like '%slave_pending_jobs%';
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| slave_pending_jobs_size_max | 67108864 | 64M
+-----------------------------+----------+
主库执行
UPDATE sbtest1 SET c=REPEAT(UUID(),2) where id<100000;
从库出现大量类似生产环境中的日志,但没有模拟出从库异常crash的情况
Note] Multi-threaded slave: Coordinator has waited 208341 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208351 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208361 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208371 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208381 times hitting slave_pending_jobs_size_max; current event
结论
从库开启并行复制,主库执行大事务,从库日志会出现大量中 Coordinator has waited。但没有复现出从库发生异常crash的情况。
建议:
- 尽量减少大事务的执行,拆分为小事务
- 从库slave_pending_jobs_size_max 变量设置比主库max_allowed_packet大些
- 可设置binlog_rows_query_log_events = 1(可以动态开启),DDL,DML会以语句形式在binlog中记录,方便分析binlog
- crash问题后续可以多保留一些日志,再次复现时好分析些
- 已给官方提了bug了,链接地址为 http://bugs.mysql.com/90342


 浙公网安备 33010602011771号
浙公网安备 33010602011771号