图论与广度优先/深度优先算法
图形共有两种:一种是无向图形,一是有向图形。五香图形以(V1, V2)表示边线,有线图形以<V1,V2>表示边线
图形由顶点和边所组成,以G=(V, E)来表示:其中V为所有顶点的集合,E为所有边的集合
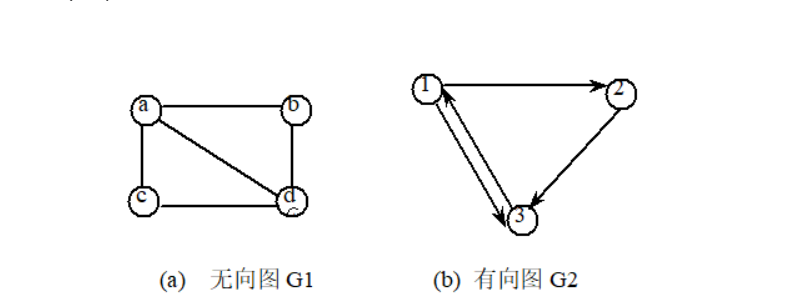
他们的数据结构可以表示为:
G1=(V1,E1), 其中 V1={a,b,c,d},E1={(a,b),(a,c),(a,d),(b,d),(c,d)},
G2=(V2,E2),其中 V2={1,2,3}, E2={<1,2>,<1,3>,<2,3>,<3,1>}
完全图:在无向图形中,N个定点正好有N(N-1)/2条边,则称为完全图。但是在有向图形中,若要成为完全图,则必须有N(N-1)条边
-
路径:两个不同顶点间所经过的边称为路径
-
回路:起始顶点及终止顶点为同一个点的简单路径称为回路
-
相连:在无向图形中,若顶点Vi到顶点Vj间存在路径,则Vi和Vj是相连的
-
相连图形:如果图形G中,任两个顶点均相连,则次图形称为相连图形,否则称为非相连图形
-
路径长度:路径上所包含边的总数为路径长度
-
相连单元:图形中相连在一起的最大子图总数
-
强相连:在有向图形中,若两顶点间有两条方向相反的边称为强相连
-
度:在无向图形中,一个顶点所拥有边的总数为度
-
入/出度: 在有向图形中,以顶点V为箭头终点的边之个数为入度,反之则由V出发的箭头总数为出度
图形表示法
相邻矩阵法
相关特性:
-
对无向图形而言,相邻矩阵一定是对称的,而且对角线一定为0,有向图形则不一定如此
-
在无向图形中,任一节点i的度为第i行所有元素的和。在有向图中,节点i的出度为第i行所有元素的和,而入度为j列所有元素的和
-
用相邻矩阵法表示图形共需要n**2空间,由于无向图形的相邻矩阵一定具有堆成关系,所以出去对角线全部为零外,仅需要存储上三角形或下三角形的数据即可,因此仅需n(n-1)/2空间
相邻表法
相关特性:
-
每一个顶点使用一个表
-
在无向图中,n个顶点e个边工序n个表头节点及2*e个节点:有向图则需n个表头节点及e个节点。在相邻表中,计算所有顶点的度所需的时间复杂度为O(n+e)
相邻多元列表法
结构:M----V1----V2----LINK1----LINK2
-
M:记录改边是否被找过的一个字段
-
V1及V2:所记录的边的起点与终点
-
LINK1:在尚有其他顶点与V1相连的情况下,此字段会指向下一个与V1相连的边节点,如果已经没有任何顶点与V1相连时,则指向null
-
LINK2:在尚有其他顶点与V2相连的情况下,此字段会指向下一个与V2相连的边节点,如果已经没有任何顶点与V2相连时,则指向null
图形的遍历
一个图形G=(V,E),存在某一顶点v∈V,我们希望从v开始,通过此节点相邻的节点而去访问G中其他节点,这成为图形的遍历
先深后广法
先深后广遍历的方式有点类似于前序遍历。从图形的某一顶点开始遍历,被访问过的顶点就做上访问的记号,接着遍历此顶点的所有相邻且未访问过的顶点中的任意一个顶点,并做上已访问的记号。在以改点为新的起点继续进行先深后广的搜索。由于此方法会造成无限循环,所以必须加入一个变量,判断改点是否已经遍历完毕
Node类
package DFS算法;
/**
* @author YanAemons
* @date 2021/10/16 16:11
*/
public class Node {
int x;
Node next;
public Node(int x)
{
this.x = x;
this.next = null;
}
}
GrapLink类
package DFS算法;
/**
* @author YanAemons
* @date 2021/10/16 16:11
*/
public class GraphLink {
public Node first;
public Node last;
public boolean isEmpty()
{
return first == null;
}
public void print()
{
Node current = first;
while (current != null)
{
System.out.print("["+ current.x+"]");
current = current.next;
}
System.out.println();
}
public void insert(int x)
{
Node newNode = new Node(x);
if (this.isEmpty())
{
first = newNode;
last = newNode;
}
else
{
last.next = newNode;
last = newNode;
}
}
}
Main类
package DFS算法;
/**
* @author YanAemons
* @date 2021/10/16 16:15
*/
public class Main {
public static int run[] = new int[9];
public static GraphLink Head[] = new GraphLink[9];
public static void dfs(int current)
{
run[current] = 1;
System.out.print("["+current+"]");
while (Head[current].first != null)
{
if (run[Head[current].first.x] == 0)
dfs(Head[current].first.x);
Head[current].first = Head[current].first.next;
}
}
public static void main(String[] args) {
int[][] Data = {{1,2},{2,1},{1,3},{3,1},{2,4},{4,2},{2,5},{5,2},{3,6},{6,3},{3,7},{7,3},{4,5},{5,4},{6,7},{7,6},{5,8},{8,5},{6,8},{8,6}};
int DataNum;
int i, j;
System.out.println("图形的邻接表内容");
for (i = 1; i < 9; i++)
{
run[i] = 0;
Head[i] = new GraphLink();
System.out.print("顶点"+i+"=>");
for (j = 0; j < 20; j++)
{
if (Data[j][0] == i)
{
DataNum = Data[j][1];
Head[i].insert(DataNum);
}
}
Head[i].print();
}
System.out.println("深度优先遍历顶点:");
dfs(1);
System.out.println("");
}
}