数据库(索引)
数据库的索引
索引的原理
SQLServer:索引中的原理是一种中(B+Tree)
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
1聚集索引
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚集码)上具有相同值的元组集中存放在连续的物理块称为聚集。
select * from [dbo].[User] where [CompanyId]=3 --
在SQL SERVER中,聚集索引的存储是以B树存储,B树的叶子直接存储聚集索引的数据:实在Tree(树叶末中直接存储的数据)直接存储的数据,所以在他的速度上会比非聚集索引快一点
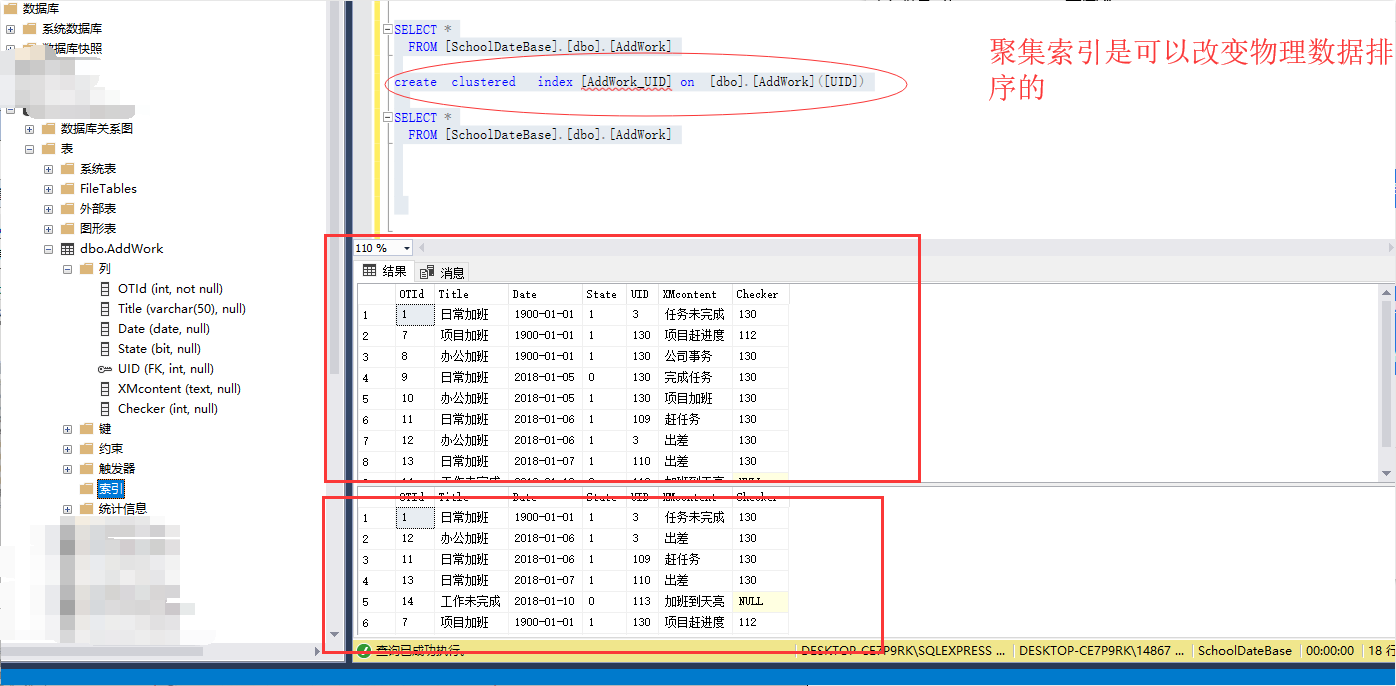
聚集索引是一种会改变查询方式的索引方式(在创建表的时候创建自增主键SQL会自动创建为剧集主键)
使用聚集索引查询实在SQL中比较快的一种查询方式
2非聚集索引
因为每个表只能有一个聚集索引,如果我们对一个表的查询不仅仅限于在聚集索引上的字段。我们又对聚集索引列之外还有索引的要求,那么就需要非聚集索引了.
非聚集索引,本质上来说也是聚集索引的一种.非聚集索引并不改变其所在表的物理结构,而是额外生成一个聚集索引的B树结构,但叶子节点是对于其所在表的引用,这个引用分为两种,如果其所在表上没有聚集索引,则引用行号。如果其所在表上已经有了聚 集索引,则引用聚集索引的页.
非聚集索引在B树上存的是地址指针在查找的时候痛过指针在去查找数据所以这种查询的方式比聚集索引查询会慢一点
非聚集索引
1,不影响数据的物理排序,但是重复存储一个数据和位置
2,找数据:先找索引--快速定位--拿到数据
3,查找快,但是有维护索引的成本,不是越多越好
4,非聚集索引,可以多个,每个索引也可以多个字段
5,适合经常查询的字段,名称/账号
6,非聚集索引不能运算,不能like'% %',索引条件在前
建立索引的原则/建议
1,主键是必须简历索引(推荐数值主键,性能最高)
2,外键里也要索引
3,经常查询的建立索引
4,经常在Where里面
5, Order by / group by /distinct
6,聚合运算/where条件时,先索引字段
不推荐的缘由
1,基本不怎么查询
2,重复值比较多的不要索引(sex/state)
3,text/image 不要索引
4,索引不要太多了
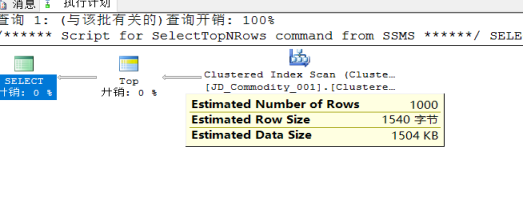
执行计划:
执行计划的5种 执行计划

|
|
Estimated Number of Rows 受影响行数
|
| Estimated Row Size 受影响的字节数 | |
| Estimated Data Size 影响的数据大小 |
常规的SQL优化建议:
对列的计算要避免,任何形式都要避免
in查询 or查询,索引会失效,可能是拆分
in 换exists
not in 不要用,不走索引
is null和is not null 都不走索引
<> 也不走索引 可以拆分成> 和<
join时,链接越少性能越高 左链接,以左边的结果为准 右链接反过来, 连接字段要求带索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号