

naiveBayes(朴素贝叶斯)算法及案例分析
naiveBayes(朴素贝叶斯)算法的R语言实现
贝叶斯:在已知类条件概率密度参数表达式和先验概率前提下,利用贝叶斯公式转换成后验概率,最后根据后验概率大小进行决策分类。然而我们要学习的是朴素贝叶斯,朴素贝叶斯一个重要的假设就是变量独立,换句话说就是各个变量间互不影响,a变量的取值不会影响b变量取值。
#步骤1 加载e1071包
library(e1071) library(printr)
#步骤2 iris数据集分为训练集和测试集
index<-sample(1:nrow(iris),nrow(iris)*3/4) iris.train<-iris[index,] iris.test<-iris[-index,]
#步骤3 使用拉普拉斯平滑预测
model<-naiveBayes(Species~.,data=iris.train,laplace=3)
#步骤4 用模型对测试集做测试
pred<-predict(model,iris.test[,1:dim(iris)[2]-1]) dim(iris)
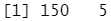
dim(iris)[2]
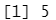
#步骤5 结果显示
table(pred,iris.test$Species) #混淆矩阵

Navie Bayes算法案例分析
library(klaR) data(miete) library(sampling) n<-round(2/3*nrow(miete)/5) #按照训练集占数据总量2/3计算每一等级应抽取的样本数 sub_train<-strata(miete,stratanames="nmkat",size=rep(n,5),method="srswor") #以nmkat变量的5个等级划分层级,进行分层抽样 miete_train<-miete[,c(-1,-3,-12)][sub_train$ID_unit,] #获取如上ID_unit所对应的样本构成训练集,并剔除第1、3、12个变量 miete_test<-miete[,c(-1,-3,-12)][-sub_train$ID_unit,] #获取如上ID_unit所对应的样本构成测试集,并剔除第1、3、12个变量 m_Bayes<-naiveBayes(nmkat~.,miete_train) #建立Navie Bayes模型 m_Bayes$apriori #得到miete数据集的分布情况(先验概率) m_Bayes$tables #tables项中存储了所有变量在各类被下的条件概率
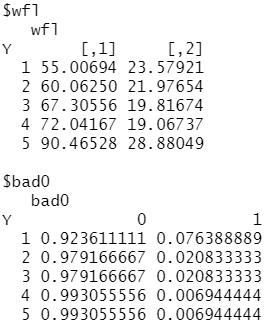
......
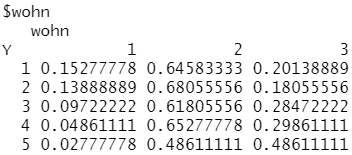
m_Bayes2<-NaiveBayes(miete_train[,-12],miete_train[,12]) #建立NaiveBayes模型 Bayes2_pre<-predict(m_Bayes2,miete_test) #对miete_test数据集进行预测 Bayes2_pre

table(miete_test$nmkat,Bayes2_pre$class) #预测结果的混淆矩阵

E_Bayes2<-sum(as.numeric(as.numeric(Bayes2_pre$class)!=as.numeric(miete_test$nmkat)))/nrow(miete_test) E_Bayes2
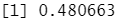
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15990949.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号